|
Автореферат
1. Введение
Возможности применения технологии RFID ограничены только воображением человека. Хотя существует мнение, что RFID лучше всего подходит для управления сетью сбыта или для отраслей, использующих товары в потребительской упаковке [1], диапазон прикладных RFID систем выходит далеко за границы этих областей применения.
Системы RFID позволяют считывать информацию, находящуюся вне пределов видимости. Идентификационный код хранится в метке, состоящей из микрочипа, прикрепленного к антенне. Приемопередатчик, часто называемый интеррогатором или считывателем, имеет связь с меткой c помощью телекоммуникации.
По функциональности RFID-метки, как метод сбора информации, очень близки к штрих-кодам, наиболее широко применяемым сегодня для маркировки товаров, однако по функциональности значительно превосходят их.
2. Цели и задачи работы
При использовании технологии возникает ряд проблем, на решение которых направлена магистерская работа.
По мере увеличения числа объектов, которые маркируются, вероятность одновременно считываемых меток увеличивается. Соответственно растет вероятность коллизий сигналов. Надежность связи и быстродействие в системе RFID тесно связаны с антиколлизионными алгоритмами. Так же, для построения надёжной RFID-системы следует учитывать ряд ограничений на её технические параметры. Основными техническими характеристиками систем RFID являются дальность, быстродействие, надежность связи и электромагнитная совместимость.
Таким образом, в моей магистерской работе будут решаться следующие задачи:
- Анализ возникновения коллизий при одновременном считывании нескольких меток
- Обзор существующих антиколлизионных алгоритмов
- Анализ влияния ограничений на технические параметры аппаратуры
- Анализ влияния шумов и интерференции на работу системы
- Создание имитационной модели системы
3. Предполагаемая научная новизна
В ходе магистерской работы будут получены следующие результаты:
1) Создана радиочастотная модель системы
2) Разработаны методы по увеличению надёжности и дальности действия системы
4. Анализ существующих решений
Вопреки распространённому заблуждению RFID-ридер может одновременно вести информационный обмен только с одной меткой [2]. Поскольку метка является простым носителем идентификационного номера, появляется задача точного чтения этого номера. Если в рабочей зоне считывателя находится единственная метка, не требуется никаких команд. При достаточной энергетике метка просто передает свои содержащиеся в ней данные. Однако, если в рабочей зоне считывателя находится множество меток, отвечающих одновременно, их сигналы интерферируют. Такое наложение сигналов называется коллизией, а результаты считывания чаще всего оказываются потерянными. Для избегания коллизий система RFID требует формирования команд, основанных на некоторых протоколах. Такие протоколы обычно называют антиколлизионными протоколами или алгоритмами.
Антиколлизионные алгоритмы, используемые в системах RFID, сходны со способами разрешения конфликтных ситуаций множественного коммуникационного доступа и с различными сетевыми протоколами, включая протоколы Aloha и семейство протоколов CSMA (Carrier Sense Multiple Access) [3]. Реализация антиколлизионных алгоритмов в технологии RFID, однако, ограничена низкой потребляемой мощностью и малым объемом, а иногда и полным отсутствием памяти метки. Кроме того, алгоритмы должны быть оптимизированы с учетом малого энергопотребления меток, чтобы не снижать дальность в случае пассивных, или увеличивать срок службы элемента питания в случае активных меток. К тому же из-за того, что метки способны взаимодействовать только со считывателем, использование методов CSMA невозможно. Более того, вариации параметров канала распространения сигнала в беспроводных каналах связи значительно больше аналогичных вариаций в проводных каналах — импульсные шумы крайне неблагоприятно влияют на относительно кратковременные сеансы связи между считывателем и меткой. Сложность алгоритмов также должна быть минимизирована, так как это приводит к увеличению стоимости аппаратуры.
4.1 Классификация антиколлизионных алгоритмов
Существует большое разнообразие антиколлизионных методов, которые могут классифицироваться различными способами. Наиболее общими классификационными признаками являются: пространство, частота и время (рис.1).

Рис. 1. Семейства антиколлизионных алгоритмов. Анимированный рисунок, состоящий из 8 кадров, повторяющихся 10 раз, раззмером 17,1kb. Выполнено при помощи программы GifAnimator.
В случае пространственных алгоритмов метки обычно локализуются в пространстве таким образом, чтобы обеспечить их последовательное считывание. Это достигается изменением зоны считывания или, в случае пассивных меток, вариацией мощности, излучаемой считывателем. Известен способ, использующий обе эти возможности на основе определения максимального отклика меток на различных расстояниях. Другой способ использует ряд считывателей с малой дальностью действия, такой, которая обеспечивает считывание только одной метки в поле каждого считывателя в данное время. Еще в одном способе разделения меток и их последовательного считывания предлагается триангуляционное использование сверхширокополосной связи с определением местоположения. Основной проблемой пространственных методов является сложность достижения высокой точности определения дальности. Требования к точности определения дальности еще более возрастают с увеличением числа меток в зоне действия считывателя и, соответственно, уменьшением расстояния между ними. В настоящее время считается, что наилучшим является использование пространственных методов в сочетании с частотными и временными методами.
Для обеспечения уверенной беспроводной связи обычно используются частотные методы. Системы FDMA (Frequency Domain Multiple Access) используют разделение общей полосы частот на фиксированное число каналов. В системах RFID низкой стоимости такое решение не применимо, так как при этом потребуются высокостабильные генераторы и селективные полосовые фильтры. Технология Magellan использует комбинацию FDMA и TDMA (Time Domain Multiple Access) методов [4]. Поскольку достоинства такой системы недостаточно обоснованы, не очевидно как это повлияет на технические характеристики и стоимость системы RFID.
Системы CDMA (Code Domain Multiple Access) имеют много преимуществ перед FDMA системами, так как они лучше адаптированы к изменению трафика, имеют большую емкость и простое управление процессом. Системы, основанные на применении CDMA и SS (Spread Spectrum) методов достаточно сложны и дороги. К тому же их использование может ограничиваться частотными ресурсами, предусмотренными в регламентах. Поэтому SS методы, включая FH (Frequency Hopping) и DS (Direct Sequence), могут быть реализованы только в UHF или микроволновом диапазонах, где имеются соответствующие частотные ресурсы.
Подавляющее число антиколлизионных алгоритмов в технологии RFID основано на использовании временных методов, в которых момент передачи сигнала изменяется во времени. Эти алгоритмы подразделяются на детерминистические и вероятностные.
Детерминистический алгоритм реализуется, когда считыватель генерирует запрос или команду, которая возбуждает определенную метку с уникальным идентификационным номером UID (Unique Identification Number) [5]. На основании этого номера считыватель или перебирает список известных номеров, или выполняет определенные действия по поиску бинарным способом. Переборные методы особенно эффективны, когда в зоне действия считывателя находится небольшое количество меток. При этом также требуется предварительное знание всех номеров меток.
В настоящее время наиболее широкое применение находят бинарные алгоритмы. Существуют различные варианты такого алгоритма. Некоторые из них могут быть достаточно быстродействующими, однако все же они работают достаточно корректно, если в течение поиска в поле считывания не появляются дополнительные метки.
Вероятностные алгоритмы — это такие методы разрешения коллизий, когда метки в поле считывателя генерируют сигналы в случайные моменты времени. Существует большое число решений, когда считыватель различным образом управляет метками. Значительное число способов основывается на протоколе Aloha, предназначенном для множественного сетевого доступа. По этой схеме узел передает пакет после приема пакета. В случае возникновения коллизии узел входит в насыщение и передает пакет снова после случайной задержки. В стробированном варианте протокола Aloha (slotted Aloha) передача пакета производится в течение фиксированного периода, большего некоторого известного постоянного времени. В патенте Furuta описывается вариант такого протокола для бесконтактных персональных карт. Международный стандарт ISO 15693 поддерживает метод, аналогичный стробированному варианту протокола Aloha.
Алгоритм SuperTag компании BTG функционирует по принципу дополненного стробированного варианта алгоритма Aloha. После приема данных метки могут прекратить работу или передавать данные с пониженной частотой повторения. В то время, когда метки не работают, алгоритм SuperTag пересчитывает идентично кодированные объекты. Для того чтобы быть уверенным, что при передаче данных не случится коллизия, другой вариант протокола SuperTag предписывает выключение всех меток, кроме одной. После определенного периода времени метки активизируются и цикл повторяется. По другим предложенным способам считыватель работает с перерывами – в импульсном режиме, предписывая работу меток после случайной задержки. После того как метка передаст данные, она перестает работать, чтобы уменьшить вероятность будущих коллизий. Некоторые алгоритмы предписывают, чтобы по стартовой команде считывателя метки после случайной задержки отвечали не полным, а укороченным сигналом. После этого считыватель предписывает меткам с большей задержкой замолчать, а одной метке передавать полный пакет данных. В качестве типичного представителя таких протоколов проанализируем семейство алгоритмов SuperTag.
Многие антиколлизионные алгоритмы требуют обнаружения факта возникновения коллизии сигналов. Наиболее общепринятый метод обнаружения коллизий основан на использовании свойств кодирующих сигналов. Код NRZ и другие коды , связанные лишь с уровнем сигнала, принципиально не пригодны для обнаружения коллизий (рис. 2а). В то же время код Манчестера и другие коды, в которых информация связана с переходом сигнала от одного уровня к другому (рис. 2b), обладают такой возможностью.
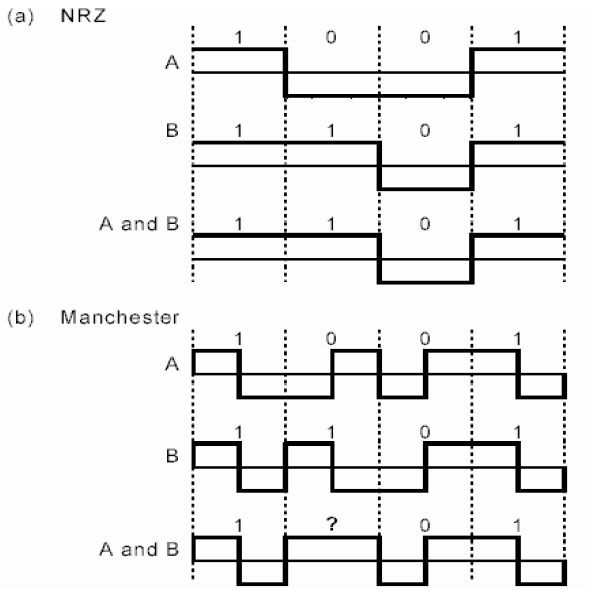
Рис. 2. Обнаружение коллизий с использованием различных способов кодирования сигналов
Известны и другие методы обнаружения коллизий, которые основаны на использовании модуляционных схем. Считыватель по «дрожанию» (wobbling) сигнала способен обнаружить одновременный прием нескольких меток, которые используют FSK модуляцию своих сигналов.
4.2 Анализ антиколлизионных алгоритмов
Несмотря на то, что все антиколлизионные алгоритмы уникальны и имеют свои достоинства и недостатки, достаточно рассмотреть два семейства алгоритмов — SuperТag и QT, которые, в определенном смысле, являются их типичными представителями. Оба алгоритма реализуются во временной области. Однако алгоритм SuperТag является вероятностным, а QT — детерминистическим.
4.2.1 Алгоритм SuperТag
Алгоритм SuperТag был разработан южноафриканской компанией SCIR и в настоящее время лицензирован компанией BTG. Он представляет собой семейство алгоритмов, основанных на сетевом протоколе Aloha. Для того чтобы обеспечить идентификацию множества меток, как упоминалось ранее, семейство алгоритмов SuperТag использует вероятностный подход. Известны четыре варианта алгоритма (рис. 3). Каждый вариант подразумевает использование стартовой команды считывателя.

Рис. 3. Четыре варианта алгоритма SuperТag. Черный цвет соответствует успешному, а серый – неуспешному разрешению коллизий
В простейшем варианте после приема стартовой команды метки со случайной задержкой отвечают полным идентификационным номером. В соответствии с этой случайной задержкой метки продолжают отвечать даже после идентификации. Это соответствует варианту ST.std.free (standard free-running) алгоритма SuperTag.
В несколько более сложном варианте алгоритма ST.std.off (standard shut-off) считыватель после приема полного номера метки генерирует команду на прекращение ее ответа.
В варианте алгоритма ST.std.free метки могут начать ответ во время ответа других меток, а это вызывает коллизии. От этого недостатка свободен другой вариант, который при помощи генерируемой считывателем команды запрещает ответы всех меток, кроме первой ответившей. Этот вариант соответствует алгоритму ST.fast.free.
Последний вариант алгоритма SuperТag наиболее сложен. Как и в предыдущем варианте — ST.fast.free, считыватель запрещает ответы всех меток, кроме первой ответившей. Однако, в дополнение, считыватель выключает метку сразу после ее идентификации. Этот вариант соответствует алгоритму ST.fast.off.
4.2.2 Бинарные алгоритмы с запросом
Другой широкий класс антиколлизионных алгоритмов во временной области представляет собой детерминистические протоколы, которые для определения уникального номера UID используют бинарный поиск. Эти протоколы классифицируют в зависимости от того, какая информация требуется при передаче сигнала метки. Некоторые алгоритмы требуют, чтобы метки в течение поиска отвечали полным или почти полным номером UID. Другие алгоритмы заставляют считыватель достраивать UID бит за битом, при этом метки просто отвечают при совпадении запроса. Мы остановимся на этом позже, так как ситуация может упрощаться исходя из требований к метке. Многие особенности предложенных методов мы рассмотрим на основе анализа алгоритмов QT (рис. 4).
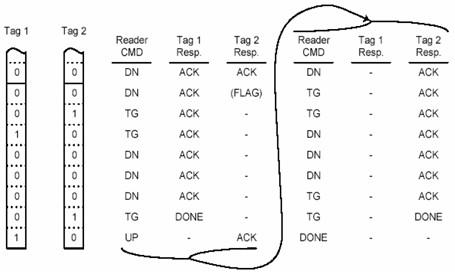
Рис. 4. Последние девять бит выборки QT.ds цикла в присутствии двух отвечающих меток. Tag — Метка, Reader Считыватель, Resp. — Ответ.
По этой схеме считыватель может генерировать две команды поиска: одна — DN, инструктирует метку двигаться по дереву, другая — TG (toggle), инструктирует метку перейти на другую ветвь дерева и двигаться по ней. Если последний идентифицируемый бит был равен 0, команда DN инструктирует метку двигаться дальше по ветви 0. Если последний бит равен 1, считыватель инструктирует метку далее двигаться по ветви 1. Команда перехода TG инструктирует метку перейти на ветвь, которая противоположна значению последнего бита. Если в следующей битовой позиции метка имеют совпадение с 0 или 1, она отвечает подтверждением. В случае несовпадения битовых значений метка перестает отвечать и битовый указатель останавливается на последнем бите, который был удачно идентифицирован.
После генерации стартовой команды в битовом указателе метки устанавливается 0 и считыватель может генерировать DN или TG команду. Считыватель в зависимости от конкретного алгоритма может генерировать последовательность DN или TG команд. После генерации каждой команды считыватель анализирует подтверждения меток о битовом совпадении. Это продолжается до тех пор, пока в результате анализа будет получен полный 64-битный UID и одна метка будет идентифицирована. После совпадения номера метка генерирует подтверждение и выключается.
Как отмечалось ранее, если в метке нет совпадения с 0 или 1 в текущей битовой позиции, она прекращает отвечать и битовый указатель останавливается на последнем идентифицированном бите. Кроме того, метка устанавливает флаг, обозначая ошибку. После того, как путь по дереву завершен и одна метка идентифицирована, считыватель может инициировать UP команду. Эта команда предписывает меткам снять флажки и установить их указатели на ближайшие 8 бит, привязанные к полным 64 битам UID. Если на данной ветви дерева метки отсутствуют, может быть инициирована еще одна команда UP. Такой алгоритм называется QT.ds [6].
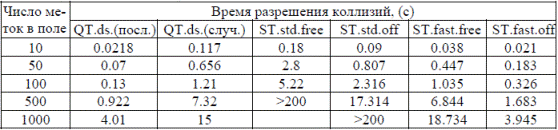
В рассмотренных алгоритмах, основанных на бинарном поиске, распределение номеров UID влияет на характеристики аппаратуры. Наилучшие характеристики обеспечиваются при последовательном распределении номеров. Наихудшие характеристики обеспечиваются при случайном распределении номеров. Мы рассмотрим оба случая. Время, необходимое для считывания различного количества меток в поле считывания, приведено в таблице 1.
Таблица 1 — Время, необходимое для считывания различного количества меток в поле считывания
5. Анализ полученных результатов
Два типа рассмотренных алгоритмов могут сравниваться по двум критериям: технические характеристики и практическая реализация. Что касается технических характеристик, необходимо обратить особенное внимание на два фактора — скорость идентификации и поведение аппаратуры при изменении числа меток в процессе считывания. Также следует учитывать характеристики в присутствии шума и другие специфические достоинства и недостатки. Что касается практической реализации, то особенно важной является аппаратурная реализация и вопросы программного обеспечения (команды).
При рассмотрении алгоритмов SuperTag можно заметить, что при переходе от варианта ST.std.free к варианту ST.std.off, наблюдается близкое к линейному возрастание времени разрешения коллизий в зависимости от числа меток. Это обусловлено дополнительными функциями варианта ST.std.free, которые выключают метки после их идентификации и/или выключают метки, когда одна из них отвечает. Обе эти функции приводят к уменьшению числа отвечающих в поле меток и, следовательно, имеют линейную тенденцию. Видно также, что быстродействие алгоритма ST.fast.off в зависимости от числа меток в поле близко к линейному.
Обращаясь к алгоритму QT.ds мы видим существенные различия в характеристиках при последовательном и случайном распределении номеров меток. В определенных применениях — на производстве или в дистрибьюторских центрах, например, номера UID могут быть распределены последовательно. В других применениях, таких как розничные магазины, номера распределяются случайно.
Сравнивая характеристики двух алгоритмов, заметим, что они близки при малом числе меток в поле. При увеличении числа меток в поле проявляются нелинейности.
Теперь оценим количество команд, которое требуется передавать считывателю для разрешения коллизий. Из всех рассмотренных алгоритмов, вероятно, алгоритм ST.fast.free требует наименьшего числа команд от
считывателя. Это может быть очень полезным в тех частотных диапазонах, где действуют жесткие регламентные ограничения. Прямой поиск алгоритма QT.ds, как и в случае ST.fast.off, требует передачи значительного числа команд. В общем случае, чем больше объем передаваемых команд, тем шире требуемая полоса частот и тем выше вероятность возникновения ошибок.
Кроме технических характеристик и команд, важна практическая аппаратная реализация. Алгоритмы SuperTag требуют генерации случайных задержек перед ответами. А это требует соответствующих схемных решений. Сложность реализации вариантов различна. Некоторые решения для генерации случайных чисел предполагают использование собственных свойств электронных схем. В других решениях используют специальные генераторные схемы случайных чисел. Усовершенствованные алгоритмы SuperTag должны также обладать способностью распознавания команд выключения и прекращения ответа. Алгоритмы QT.ds. требуют наличия нескольких компараторов для сравнения передаваемых бит с битами, хранящимися в памяти. Они также должны устанавливать флаги битам и некоторым состояниям информации. В любом случае избыточность в схемных решениях требует дополнительной площади и, соответственно, приводит к большей стоимости чипа.
Каждый из алгоритмов — SuperTag и QT.ds, имеет свои уникальные достоинства и недостатки. Так алгоритм QT.ds имеет присущую ему способность селектировать метки с определенными номерами. Это может быть удобным в применениях, когда должны распознаваться или наоборот, не распознаваться, определенные, специфические метки или группы меток.
В свою очередь алгоритмы SuperTag, по крайней мере, ST.std.off, требуют меньшего числа команд считывателя, более узкой полосы частот и, следовательно, можно предположить наименьшую вероятность ошибок.
Уникальным недостатком алгоритма QT.ds и других протоколов с бинарным поиском является их неспособность во время поиска идентифицировать метки, которые вновь поступают в поле считывания. Эта особенность может быть важной или не важной в зависимости от конкретного применения аппаратуры RFID.
Проблема алгоритмов SuperTag и других, связанных со случайным временем ответа, состоит в необходимости назначать максимальное время задержки ответа метки. Это время может передаваться метке или быть заложенным в производстве.
6. Влияние ограничений на дальность связи системы RFID.
Дальность действия системы RFID [7] в основном ограничивается напряженностью излучаемого электромагнитного поля и электродинамическими свойствами распространения сигнала в окружающей среде. Напряженность излучаемого поля непосредственно ограничена административными нормами (регламентами) [8], а также косвенно, через административные нормы и ограничения по ширине спектра сигнала, определяется закономерностями процесса связи. Напряженность поля находится в большой зависимости от взаимной ориентации и расположения метки и считывателя, вида антенны. Административное регулирование ограничивает напряженность поля и плотность мощности в определенных областях пространства, даже если эти параметры могут обеспечиваться техническими средствами в широких пределах.
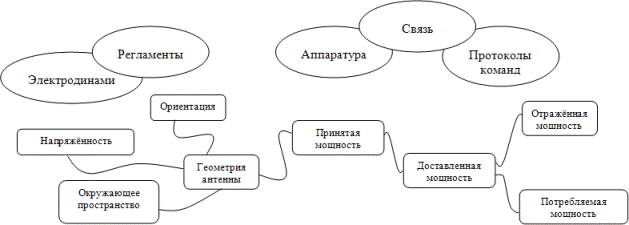
Рис. 5. Основные факторы влияющие на дальность связи RFID-систем
После того как определена напряженность поля или плотность мощности в некоторой точке пространства, следующей проблемой является прием мощности. Для того чтобы достичь максимального индуцируемого напряжения или доступной мощности, необходимо оптимально ориентировать антенну метки по отношению к излучаемому полю. На практике это может быть очень сложной задачей. Напряженность поля или плотность мощности воспринимается антенной метки с учетом ее геометрии и ориентации. При фиксированной геометрии и ориентации антенны функционирование метки зависит от параметров ее электронной схемы. Особенно важны импедансы антенны, согласующей цепи и нагрузки.
В обратной линии связи, от метки к считывателю, производится модуляция сигнала информацией, хранящейся в памяти метки. Уровень модулированного таким образом сигнала значительно ниже уровня сигнала считывателя. Однако, благодаря сложной обработке сигнала в считывателе, это обычно не ограничивает дальность действия системы.
7. Выводы
Так как целью пассивных систем RFID является простое считывание идентификационных кодов, которые хранятся в метке, а в поле считывания присутствует множество меток, протоколы команд должны оптимизироваться по отношению к антиколлизионными алгоритмам. При рассмотрении антиколлизионных алгоритмов важной характеристикой является не только скорость идентификации, но также требуемый набор команд, функционирование в присутствии шума и аппаратная реализация. Кроме того, с точки зрения команд и антиколлизионных алгоритмов очень важным оказывается влияние ширины спектра.
Технические характеристики аппаратуры прямо или косвенно зависят от фундаментальных ограничений. При проектировании меток и разработке стандартов очевидна высокая степень взаимосвязи между техническими характеристиками аппаратуры, ограничениями, конфигурацией системы и ее конкретным применением[10].
При разработке и реализации RFID-систем следует учитывать характеристики многих переменных. К таким переменным относятся: рабочая частота, метки, ридеры, антенны, маркируемые объекты, условия эксплуатации.
Следует отметить, что результаты, описанные в автореферате являются предварительными. Исследования и эксперименты в рамках данной магистерской работы продолжаются, поэтому результаты могут быть уточнены.
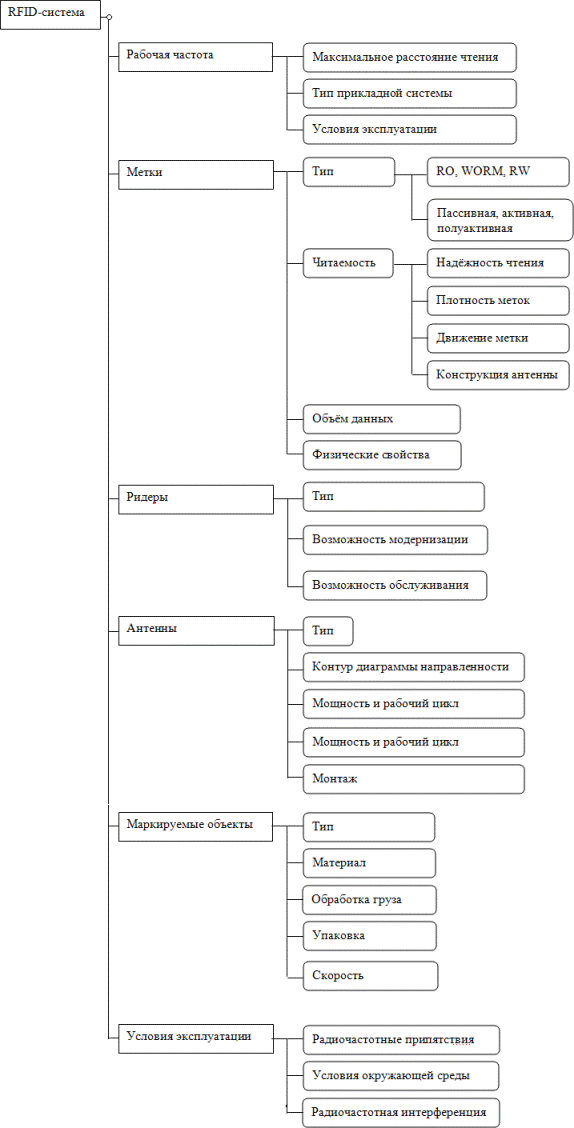
Рис. 6. Параметры влияющие на выбор оборудования систем RFID
Перечень ссылок
1. Лахири. С. RFID. Руководство по внедрению. М.:КУДИЦ-ПРЕСС. – 2007. – 312с.
2. Шарфельд.Т. Системы RFID низкой стоимости. Москва. – 2006. – 197с.
3. Науменко И.А. Аналіз антиколізійних алгоритмів систем RFID./Проблеми телекомунікацій. К.: НТТУ «КПІ», 2009.
4. http://www.doaj.org/doaj?func=abstract&id=416603&q1=RFID&f1=all&b1=and&q2=&f2=all&recNo=5 — анализ внедрения технологии RFID в цепочке доставки в Китае.
5. http://ru.wikipedia.org/wiki/RFID — обзорная статья по тематике технологий радиочастотной идентификации. Полезна для тех, кто впервые сталкивается с RFID.
6. http://www.autoidlabs.org/single-view/dir/article/1/323/page.html — статья о новейших исследованиях в области антиколлизионных алгоритмов.
7.http://publik.tuwien.ac.at/files/pub-et_12594.pdf — в статье затрагиваются вопросы проектирования RFID-систем, работающих в диапазоне 13.56MHz и 868MHz.
8. EPC Radio-Frequency Identity Protocols Generation 2Identity Tag (Class 1): Protocol for Communications at 860MHz-960MHz. EPC Global Hardware Action Group (HAG), EPC Identity Tag (Class 1) Generation 2, Last-Call Working Draft Version 1.0.2, 2003-11-24
9. Efficient Novel Anti-collision Protocols for Passive RFID tags. Okkyeong Bang, Ji Hwan Choi, Dongwook Lee. Auto-Id Labs, March 2009.
10. http://books.google.com/books?id=q4aCyZnq0cwC&printsec=frontcover&dq=rfid+low+cost&hl=ru — книга о применении технологии радиочастотной идентификации, её безопасности и конфиденциальности.
|
