
|
|
Бажанова Алена Игоревна
Факультет: Компьютерных наук и технологий (ФКНТ) |
- Актуальность темы
- Цели работы
- Предполагаемая научная новизна
- Планируемые практические результаты
- Исследование применения онтологических моделей для семантического поиска
- Анализ методов семантической обработки текста
- Заключение
- Список использованной литературы
Современные средства поиска, каталогизации, описания текстов не удовлетворяют нарастающим потребностям пользователей. Требуется их развитие в направлении повышения эффективности поиска информации и упрощения взаимодействия с пользователем.
Возможным путем решения проблемы является создание технико-информационных средств описания смысла имеющихся текстов с возможностью дальнейшего осмысленного поиска в массиве текстовой информации. Причем большие и постоянно увеличивающиеся объемы текстовой информации требуют, чтобы такие средства работали в автоматическом режиме.
Смысл традиционно является субъективной характеристикой текста. Трудно выявить какие-либо математические методы описания смысловой нагруженности текста и отдельных его понятий. Поэтому выделение смысловых характеристик из реального текста на естественном языке является сложной задачей. Тем не менее исследования в этом направлении активно ведутся. Над решением названных проблемам работают многочисленные коллективы ученых и специалистов во всем мире, в частности, консорциум W3C, где реализуется концепция Семантического Web. Создается множество интеллектуальных поисковых систем таких как RetrievalWare, Nigma, Exactus, Sirius и др.
Не смотря на обилие поисковых интеллектуальных систем многие проблемы, связанные с поиском информации, остаются не решенными.
Целью данной работы является повышение эффективности поиска неструктурированной текстовой информации по запросу пользователя на естественном языке.
Для достижения поставленной цели необходимо решить следующие задачи:
- Провести анализ применения онтологических моделей для семантического поиска информации и методов семантической обработки текста.
- Разработать онтологическую модель для поиска информации в области компьютерной литературы.
- Разработать алгоритм для автоматизированного расширения онтологий семантическими образами текстов, хранящихся в библиотеке.
- Создать компьютеризированную систему с возможностью автоматизированного расширения онтологий и корректировки автоматически добавляемых утверждений.
- Предложена онтологическая модель для поиска неструктурированной текстовой информации в компьютерной литературе, которая позволит получить полноценную базу знаний в предолженной предметной области.
- Разработана компьютеризированная подсистема с возможностью автоматизированного расширения онтологий и корректировки автоматически добавляемых утверждений.
Разработан алгоритм для автоматизированного расширения онтологий семантическими образами текстов, позволяющий получать данные релевантные запросу пользователя.
Результаты работы будут использованы в электронной научной библиотеке кафедры АСУ.
Задача семантического поиска в электронной библиотеке является упрощенным аналогом поиска информации в Интернет, т. к. предполагается, что поиск будет осуществляться по запросу пользователя на естественном языке в аналогичной строке поиска.
На рис. 1 показана схема семантического поиска информации. Пользователь вводит запрос, который подвергается лингвистическому анализу, расширяется за счет использования синонимов, затем преобразовывается в ключевые слова и отправляется поисковой машине. Поисковая машина возвращает найденные документы, они также подвергаются лингвистическому разбору и формируются семантические образы документов. Образы документов сравниваются с образом запроса, делается вывод о релевантности каждого из документов и результаты анализа (документы, которые были признаны релевантными) предоставляются пользователю. Схема лингвистического анализа приведена на рисунке 1 [12].
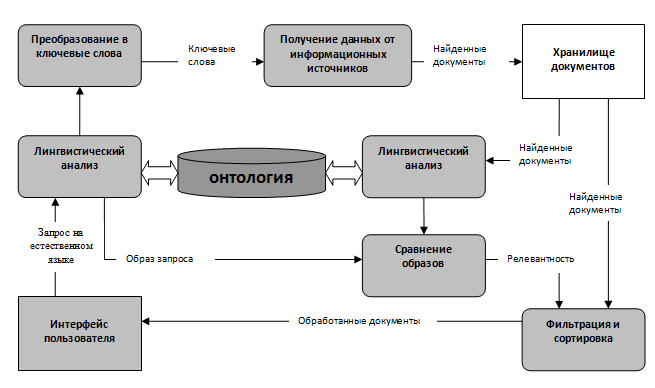
Рис. 1 – Диаграмма потоков данных при поиске.
Как видно из рисунка центральное место при такой модели поиска информации занимают онтологии. Однако, процесс создания онтологий сложный прцесс. Информационные онтологии состоят из экземпляров, понятий, атрибутов и отношений между ними. Для создания онтолгогии необходимо создать словарь терминов - глассарий, обеъдинить термины общими связями и затем наложить ограничения на эти связи, что показано на рисунке 2.

Рис. 2 – Процесс создания онтологии (анимация: объем 47Кб, размер 534×321, количество кадров 4, задержка между кадрами 50мс, задержка между первым и последним кадром 100мс, количество циклов повторния 7)
Для построения онтологий, необходимо разработать языки их представления. При этом могут быть использованы такие специализированные языки как Resource Description Framework (RDF), Web Ontology Language (OWL) и т. д. Онтологии могут использовать различные модели представления знаний, такие как логика предикатов (First order logics - FOL), дескриптивная логика, фреймовые модели (Frames), концептуальные графы и т.п. Для создания онтологий могут использоваться различные редакторы (Protégé, Ontolingua, WebOnto и др.), которые в свою очередь могут поддерживать различные форматы представления данных (языки), основанные на различных формализмах (логиках, моделях представления данных). Ключевым моментом в проектировании онтологии является выбор соответствующего языка спецификации онтологий (Ontology specification language) и редактора для работы с ней.
Онтологические модели за время исследований в этой области претерпели значительное развитие. В настоящее время для создания и поддержки онтологий существует целый ряд инструментов, которые помимо общих функций редактирования и просмотра выполняют поддержку документирования онтологий, импорт и экспорт онтологий разных форматов и языков, поддержку графического редактирования, управление библиотеками онтологий и т.д [4].
Наиболее известные инструменты инженерии онтологий, их основные характеристики представлены в таблице 1 [3].
Таблица 1 – Инструменты инженерии онтологий
| Название параметра | OilEd | OntoEdit | Ontolingua | OntoSaurus | Protégé | WebODE | WebOnto |
| Архитектура приложения | 3–х уровневая | 3–х уровневая | Клиент/сервер | Клиент/сервер | 3–х уровневая | n-уровневая | Клиент/сервер |
| Хранение онтологий | файлы | файлы | файлы | файлы | файлы, CУБД | CУБД | файлы |
| Язык ПО | Java | Java | Lisp | Lisp | Java | Java | Java + Lisp |
| Осн. язык представления знания | DAML+OIL | OXML | Ontolingua | LOOM | OKBC | - | OCML |
| Интерфейс пользователя | Локк-ое приложение | Локк-ое приложение | HTML | HTML | Локк-ое приложение | HTML и апплеты | Апплеты |
Как уже говорилось выше, инструменты инженерии онтологий используют специализированные языки. Сегодня выделяют три основных класса языков описания онтологии, что показано на рис. 3:
- Традиционные языки спецификации онтологии: Ontolingua, CycL и языки, основанные на дескрипционной логике (такие как LOOM), также языки, основанные на фреймах (OKBC, OCML, Flogic);
- Более поздние языки, основанные на Web -стандартах (XOL, SHOE, UPML);
- Специальные языки для обмена онтологией через Web: RDF(S), DAML, OIL, OWL [2].
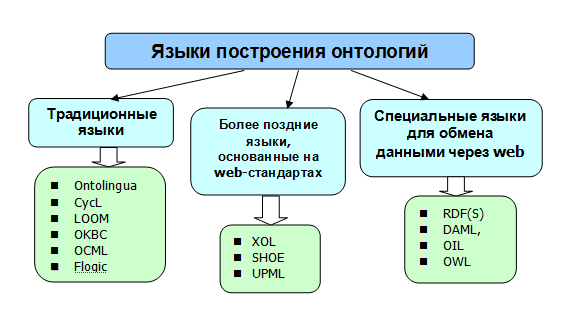
Рис. 3 – Классификация форматов представления данных
На сегодняшний день редакторы онтологий, кроме своего языка, поддерживают импорт и экспорт данных различных форматов исходя из анализа их применения, следует, что наиболее часто используемым форматом представления данных является RDF(S). Язык RDF обладает рядом преимуществ: представляет данные в виде rdf-триплетов (сущность-объект-предикат), а rdf-схема представляется в виде ориентированного графа, что является удобной для восприятия формой представления данных [1].
Исходя из анализа основных параметров различных редакторов онтологий, наиболее приемлемым является редактор Protégé, именно он будет взят за основу в дальнейшей работе. Среди форматов представления данных, лидирующие позиции занял RDF(S), который будет использован для построения онтологии предметной области электронной библиотеки кафедры АСУ [1].
Семантическая обработка текста выполняется в три этапа: морфологический, синтаксический и собственно семантический анализ (рис. 4). Каждый этап выполняет отдельный анализатор со своими входными и выходными данными и собственными настройками.
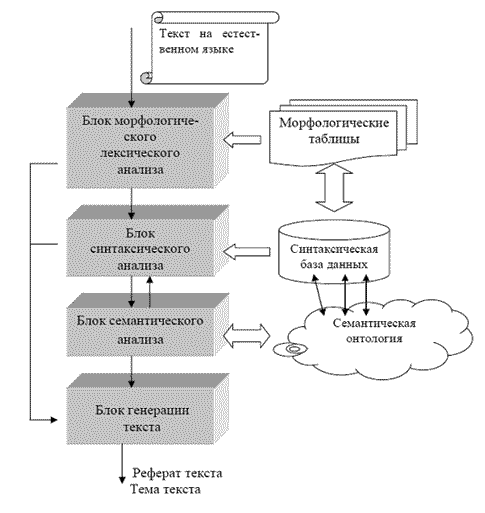
Рисунок 4 – Схема лингвистического анализа
Ввиду сложности выполнения всех этапов в работе рассматриваться будет только блок морфологического анализа. Среди методов морфологического анализа, использующихся в лингвистических процессорах, можно выделить методы с декларативной и с процедурной ориентацией.
Основным недостатком декларативных методов является чрезмерно большой объем словаря. Достоинствами метода является простота (и, как следствие, высокая скорость) анализа, а также универсальность по отношению ко множеству всех возможных словоформ русского языка.
Для процедурных методов время анализа одного слова может быть существенно выше, но объем используемых словарей в небольших системах позволяет загружать словари целиком в оперативную память. Существенным недостатком процедурных методов является отсутствие универсальности. Каждый из данных подходов имеет свои преимущества и недостатки, поэтому в дальнейшей работе будет использоваться комбинация этих методов для сочетания преимуществ каждого из них.
В общем виде схема морфологической обработки текста показана на рисунке 5. Предварительно необходимо провести лексический анализ, т. е. проверить на допустимые символы. На вход лексического анализа подаются предложения из текста поочередно, а на выходе проверенный набор слов и знаков препинания.
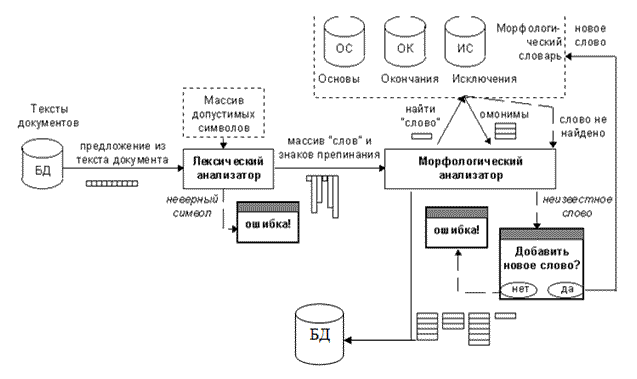
Рисунок 5 – Морфологический разбор текста.
Описание алгоритма работы морфологического анализатора:
- На вход поступает массив “слов”, знаков препинания и чисел, выделенных из входного текста на этапе лексического анализа.
- Для каждого “слова” анализатор выполняет процедуру поиска в словаре основ, загруженном в память. При этом ищутся все основы, с которых может начинаться анализируемое слово.
- Если очередная основа удовлетворяет этому условию, то из словаря аффиксов извлекается строка, содержащая все возможные аффиксы для данной основы.
- Каждый аффикс из этой строки поочередно присоединяется к основе, и результат сравнивается с анализируемым словом.
- В случае их точного совпадения формируется очередная запись в список результатов поиска: по порядковому номеру аффикса в строке аффиксов определяются переменные морфологические параметры слова (например, для существительного - число и падеж), а по словарной информации данной основы - его постоянные параметры (для существительного — род и одушевленность).
- Если в результате такого поиска не найдено ни одного успешного варианта, то проводится поиск среди исключений. При поиске среди исключений приходится просматривать все словоформы всех присутствующих в словаре исключений. Это занимает много времени, поэтому поиск среди исключений проводится только в том случае, когда не найдено ни одного варианта среди обычных основ.
- Если некоторая словоформа некоторого исключения точно совпадает с анализируемым словом, то по номеру словоформы определяются переменные морфологические параметры слова, а по словарной информации самого исключения — постоянные параметры слова.
- Если после поиска среди исключений все равно не найдено ни одного варианта, то проверяется наличие у анализируемого слова возвратного суффикса "-СЯ", "-СЬ", или приставок "НЕ-", "НИ-".
- Если они есть, то они отсекаются от анализируемого слова, и процедура поиска повторяется сначала. При этом морфологические параметры находимых основ модифицируются специальной процедурой
- В случае, когда все этапы поиска дали отрицательный результат (не найдено ни одного варианта), пользователю выдается запрос на ввод новой основы в словарь.
- Несколько записей составляется для тех слов, для которых поиск в словаре дал неоднозначный результат, т. е. было найдено несколько омонимов.
- 12. Для каждой лексической единицы (вне зависимости от того, одна или несколько записей было для нее сформировано) создается так называемый “массив омонимов”, в который включаются все сформированные записи.
Потребность в онтологиях связана с невозможностью адекватной автоматической обработки естественно-языковых текстов существующими средствами. Поэтому, для качественной обработки текстов и поиска релевантной информации, необходимо иметь детальное описание проблемной области, с множеством логических связей, которые показывают соотношения между терминами области. Использование онтологий позволяет представить естественно-языковый текст в таком виде, что он становится пригодным для автоматической обработки.
В работе был проведен анализ существующих средств и методов построения онтологий. В ходе анализа было установлено, что существует множество инструментальных средств, для построения онтологий, однако не одно из них не позволяет автоматизировать этот процесс. Для построения онтологий существуют различные специализированные языки, которые в свою очередь используют различные модели представления знаний и основаны на различных логиках. В результате проведенного анализа были сформулированы задачи для дальнейшей работы, выбраны методы и алгоритмы для их реализации.
- Исследование применения онтологических моделей для семантического поиска.
- ОНТОЛОГИИ И ТЕЗАУРУСЫ: [Учебное пособие] / Соловьев В.Д., Добров Б.В., Иванов В.В., Лукашевич Н.В. – Москва: 2006. – 157c.
- Обзор инструментов инженерии онтологий/ О.М. Овдей, Г.Ю. Проскудина // Журнал ЭБ. – 2004 – №4
- Никоненко А.А. Обзор баз знаний онтологического типа// Искусственный интеллект.–2002.–№ 4. – C. 157–163.
- Семантический веб и микроформаты [Електронний ресурс] : Интуит. Лекция — Режим доступу http://www.intuit.ru/department/internet/mwebtech/20/
- Алексей Николаевич Бевзов. Разработка методов автоматического индексирования текстов на естественном языке для информационно-поисковых систем. – М.: ИСО РАН – c. 401- 404
- ИНТЕРАКТИВНЫЕ МЕТОДЫ ФОКУСИРОВКИ И РАСШИРЕНИЯ ПОИСКА В ИНТЕЛЛЕКТУАЛЬНОЙ ПОИСКОВОЙ МАШИНЕ/В. Н. Поляков, Д. А. Бодров, А. В. Точин – М.: Московский Государственный институт стали и сплавов
- Королёв А.Н. Лингвистическое обеспечение информационно-поисковой системы Excalibur RetrievalWare: Аналитический аспект
- Семантический анализ текста на основе лексикосинтаксических шаблонов для информационного поиска. Рабчевский Евгений, Крупов Сергей, Рожков Михаил, Булатова Гульнара – Пермь: Государственный Университет
- Андреев А.М., Березкин Д.В., Брик А.В. Лингвистический процессор для информационно-поисковой системы – М: МГУ
- Анисимов А.В., Марченко А.А. Система обработки текстов на естественном языке.// Искусственный интеллект.–2002.–№ 4. – C. 157–163.
- Марченко О.О. Моделювання семантичного контексту при аналізі текстів на природній мові. Вісник Київського університету. Сер. фіз.-мат. Науки.– 2006. – № 3. – C. 230–235.

ДонНТУ - Портал магистров