Вступ
Соціальні мережі в даний час стали основним засобом спілкування, підтримки та розвитку соціальних контактів, пошуку, зберігання, редагування та класифікації інформації, творчої діяльності та виконання безлічі інших завдань. Не дивлячись на різноманітність поглядів та уподобань людей, у мережі виникає повторення опублікованого матеріалу. Це пов'язано в першу чергу з таксономічним і фолксономічним підходами класифікації даних.
Недолік таксономічного підходу в тому, що об'єкт в такому можна прив'язати тільки до одного вузла, тобто стає неможливим за допомогою такої структури описати всі необхідні якості цього об'єкта. У зв'язку з цим очевидно копіювання цього ж об'єкта в інший вузол з описом інших якостей.
Фолксономічний підхід позбавлений цього недоліку - можна прив'язати об'єкт до будь-яких вузлів. Проте, в останньому підході відсутній всіляка структура, тобто немає елементарних відносин (рід-вид) між вузлами. Таким чином, не можна виявити об'єкти, які мають більш загальний або більш приватний характер. Це також є значним недоліком для сервісів відеохостингу з величезними обсягами інформації, що знижує ефективність пошуку і призводить до створення копій файлів.
Слід зазначити, що кількість копій відеоматеріалів, розміщених на одному відеосервісі або соціальної мережі, безпосередньо залежить від популярності відеоролика і тенденцій моди. З особистих досліджень було виявлено, що «популярний» відеоматеріал розміщений на одному відеосервісі від 5 до 20 разів, і лише 1-2 відеоролика з них відрізняються якістю відеозображення, при обсягах відеоматеріалів великих мережевих сервісів це значний обсяг дискового простору, вимірюваний в терабайт. Також збільшує обсяг збережених даних використання технології RAID 10 на серверах, і CDN-мережі доставки контенту. [5]Мета і завдання дослідження
Метою роботи є зменшення вартості зберігання і збільшення швидкодії роботи серверів відеосервісів, шляхом виявлення схожого відеоматеріалу. Для досягнення поставленої мети в процесі досліджень необхідно:
-
Розглянути і вивчити існуючі методи пошуку ідентичних відеофайлів;
-
Виконати аналіз роботи алгоритмів стиснення відеоматеріалу;
- Розробити алгоритм захоплення і перетворення відеоматеріалу в деяку послідовність кадрів;
- Розробити алгоритм розпізнавання і класифікації отриманих послідовностей.
- Оцінити складність реалізації розробленої системи, і визначити області її ефективного застосування
Актуальність
Актуальність роботи визначається популярністю соціальних мереж і відеохостингів. Розроблена система дозволить у багато разів скоротити обсяг неефективності використання пристроїв зберігання. А видалення повторюваних відеороликів є однією з найактуальніших завдачь оптимізації розміщення відеофайлів.
Передбачувана наукова новизна
Для пошуку ідентичних відеофайлів на відеохостингах застосовують хешування або розрахунок контрольної суми. Дані процеси займають тривалий час тому одного разу вирахувана хеш - сума фіксується в базі даних для подальшого використання. Даний метод не дозволяє аналізувати відеоряд даних і нездатний визначити рівні по вмісту, але різні за розміром, кодеку стиснення файли.
Система, що розробляється, дозволяє на підставі даних отриманих з відеоряду порівнювати між собою відеоролики використовуючи системи розпізнавання образів, і робити припущення про ступінь схожості даного відеоматеріалу. Дана система має абсолютно новий алгоритм виявлення відеоматеріалу, що не має на даний момент аналогів, як в СНД так і в світовому співтоваристві.
Плановані практичні результати
В ході магістерської роботи планується розробка автоматизованої системи розпізнавання образів. Її основними задачами буде:
- Формування набору вихідних даних
- Представлення отриманого набору вихідних даних, як результат вимірювань для підлягающего розпізнаванню об'єкта
- Класифікація та ідентифікація об'єкта з використанням оптимальної вирішальної процедури
- Пошук і видалення відеофайлів, ідентифікованих як рівнозначні або дуже схожі
У результаті планується отримати web-додаток який буде реалізовано з використанням декількох технологій:
- PHP - ця технологія використовується для побудови серверних сторінок з динамічно формованою інформацією, яка зберігається в БД.
- MYSQL - база даних, яка буде зберігати як результати роботи, так і результати класифікації об'єктів.
- JavaScript - буде використовуватися для підвищення зручності призначеного для користувача інтерфейсу системи.
- С + + - бібліотека, що розробляється, яка буде виконуватися на веб-сервері Appache з використанням бібліотек FastCGI. Використання скомпільованого коду дозволить у багато разів прискорити роботу системи.
Огляд досліджень і розробок за темою
За результатами пошуку серед матеріалів порталу магістрів ДонНТУ були знайдені роботи схожі за вирішуваними задачами, проте, серед них, як вибрані методи рішення, так і області застосування з даною роботою істотно відрізняються. Їх розробили: Ісаєнко А. П.,
Дрига К. В.,
Сова А. А..
Хоча в Україні і в даний момент не були розроблені виробничі системи розпізнавання образів. У Російській федерації є даний ринок IT рішень. Багато фахівців і різні компанії розробляють системи розпізнавання образів для вирішення різних завдань, особливу увагу заслужили: Вахитов А. з розробкою системи відеоспостереження, компанія "Малленом" з розробкою системи "Відеоспостереження на транспорті"
За кордоном розробкою системи розпізнавання образів займаються великі компанії, такі як: Philips, Sony, Samsung, Lexus, Toyota, Siemens.В розроблюваних системах істотно відрізняються області застосування, головна мета систем - зниження помилок пов'язаних з людським фактором і вирішення задач раніше вирішуваних тільки людиною.
Рішення задач дослідження
Завдання Формування набору вихідних даних
Дане завдання представляє початковий етап роботи системи. На даному етапі відбувається захоплення серії кадрів відеофільму в заданих тимчасових інтервалах в кінці сцен. (рис. 1)
 Рисунок 1 - Захоплення кадрів відеоматеріалу
Рисунок 1 - Захоплення кадрів відеоматеріалу
Потім, захоплені зображення, приводиться до єдиного дозволу, наприклад 700x400 (рис. 2а). Це необхідно, оскільки різні
відеоролики можуть бути обрізані, зменшені або збільшені третіми особами або їх дозвіл може не відповідати робочому.
Далі кадр переводиться в градації сірого (рис. 2б) необхідність перетворення до сірого полягає в економії місця зберігання результатів вимірювання (один піксель зображення може кодуватися 1 байт інформації, значення сірого від 0 .. 255), так
і у виключенні можливості використання різних колірних просторів кодування відеоматеріалу. Потім,
кадр нормалізується (рис. 2в) і розмивається алгоритмом розмиття за Гауссу (рис. 2г) дані дії
виправляють як артефакти стиску, так і вирівнювання нерівномірно розподілених рівнів зображення.
 Рисунок 2 - А-Обрізка 700x400, Б-Переклад в градації сірого, В-Нормалізація зображення, Г-розмиття по Гауcсу
Рисунок 2 - А-Обрізка 700x400, Б-Переклад в градації сірого, В-Нормалізація зображення, Г-розмиття по Гауcсу
Задача представлення вихідних даних
Задача представлення вихідних даних, передбачає отримання результатів вимірювань підлягають розпізнаванню об'єкта. Кожна виміряна величина є деякою "характеристикою" образу або об'єкта. У даній системі 1 кадр складається з 64 образів. Кожен образ це 1 / 64 частина рівномірно розділеного зображення. Процес поділу зображення представлений на. (рис 3)[1][2][3]
 Рисунок 3 - Процес отримання зразка
Рисунок 3 - Процес отримання зразка
Анімація: обсяг - 100 КБ; розмір - 216х173; кількість кадрів - 50;
кількість циклів повторення - нескінченне
У такому випадку, в датчику може бути успішно використана вимірювальна сітківка, подібно наведеної на рис 4. Якщо сітківка складається з матриці (m, n) елементів, то результати вимірів можна представити у вигляді матриці образу. [1]
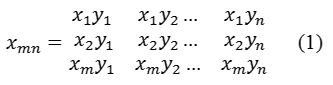 Рисунок 4-Представлення результатів вимірювань
Рисунок 4-Представлення результатів вимірювань
де кожен елемент Xmn, приймає, наприклад, значення [0,255] (1 byte). Як вже згадувалося, перетворення в градацію сірого дозволило кодувати піксель зображення 1 байтом. [6][7]
Класифікація та ідентифікація об'єкта з використанням оптимальної вирішальною процедури
Після того як всі дані у всіх класах зібрані і представлені зібрані про підлягають розпізнаванню образах, представлені точками. Виконаємо алгоритм відповідності кадрів (рис. 5). Якщо в результаті порівняння коефіцієнт відповідність склав більше 0.7 можна стверджувати що дані відеозапису однакові. [10][12]
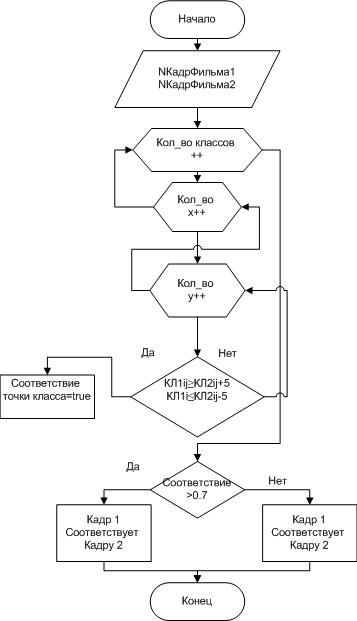 Рисунок 5 - Алгоритм відповідності кадрів.
Рисунок 5 - Алгоритм відповідності кадрів.
Висновки
Високий ступінь дублювання відеоматеріалів, розміщених на серверах, призводить до їх надмірної завантаженості. Т.ч., завдання визначення і видалення схожих відеоматеріалів є актуальною. Зроблено припущення, що порівняння відеоматеріалів на схожість найбільш логічно проводити на підставі порівняння кадрів, взятих з цих відеоматеріалів перетворених особливим чином таким як: перекладом до градаціях сірого, нормалізації та фільтрації зображення, для того щоб збільшити точність розпізнавання. Виділено групи методів, здатних вирішувати це завдання. Пропонується використовувати метод, що використовує теорію розпізнавання образів, заснований на дослідженні властивостей розділеного на частини зображення. Запропонований алгоритм вирішення задачі дозволить, значно скоротити обсяги дискового простору, тим самим дозволивши зменшити витрати компаній, що надають послуги відеохостингу, що підвищить ефективність їх роботи.
Список використаної літератури
-
Распознавание образов - применение на практике.
-
Сайт о распознавании образов
-
Распознавание образов и анализ сцен
-
Архитектура YouTube
-
Википедия. Краткая информация об многих технологиях
-
Pattern Recognition. Finding and Recognizing Patterns in Data
-
Системы распознавания образов
-
Image-Based Face Recognition Algorithms
-
Лапонина О.Р. Криптографические основы безопасности. Лаборатория знаний, Интернет-университет информационных технологий. М.: Бином, 2009. — 536 c.
-
Рутковская Д., Пилиньский М., Рутковский Л.
Нейронные сети, генетические алгоритмы и нечеткие системы.
М.: Горячая линия -Телеком, 2006. - 452 с
-
Колерс П., Мюррей Д. Распознавание образов. М.: Мир, 1970. - 288 с.
-
Эдвард А. Патрик
Основы теории распознавания образов. М. : "Советское радио", 1980.- 864 с.
При написанні даного автореферату магістерська робота ще не завершена. Дата остаточного завершення роботи: грудень 2011 Повний текст роботи та матеріали за темі можуть бути отримані у автора або його наукового керівника після зазначеної дати.

