




Brief resume
- Introduction
- Background
- Analysis approaches to the design of optical reading of texts
- Types of classifiers
- Optimization methods of recognition
- Conclusion
- References
Introduction
Handwriting recognition – the ability to receive and interpret the computer's intelligent handwriting. OCR can be performed "offline" method of the paper is written in the text or "online" by reading the movements of the tip of the pen, for example on the surface of a special computer screen [1]
Off-line kind of recognition has been used successfully in areas where you need to handle a large number of handwritten documents, for example, in insurance companies. Recognition quality can be improved by using structured documents (forms). In addition, it is possible to improve the quality by reducing the range of possible input characters. Off-line recognition is more complex than online.
Accurate recognition of Latin characters in the printed text is currently only possible if the available clear images such as scanned paper documents. The accuracy of this formulation of the problem with more than 99%, absolute accuracy can only be achieved by editing a person. The problems of handwriting recognition "printing" and a standard handwriting, as well as printed texts of other formats (especially with a very large number of characters) are currently the subject of active research [2].
Background
The widely studied problem is the handwriting recognition [3]. At the moment, the achieved accuracy is even lower than handwriting "printing" of text. Higher rates can only be achieved with the use of contextual and grammatical information. For example, in the process of discernment to search whole words in the dictionary is easier than trying to parse individual characters from the text. Knowledge of the grammar of a language can also help determine whether a verb or a noun the word. The forms of individual handwriting can sometimes not contain enough information to accurately (98%) recognize the entire handwriting.
Methods for automatic recognition of images and their implementation in optical systems read text (OCR-systems – Optical Character Recognition) – one of the most productive technologies of AI [3].
The table OCR interpretation is understood as automatic detection by means of special programs, images of characters printed or handwritten text (for example, entered into a computer using a scanner) and convert it into a format suitable for processing of word processors, text editors, etc.
An analysis of approaches to the design of optical reading of texts
Reducing OCR sometimes interpret as Optical Character Reader [4]. In this case, under the OCR to understand the device optical character recognition or automatic reading of the text (look Figure 1). Currently, such devices are used in industrial process up to 100 thousand documents a day. Industrial use of documents involves the input of good and average quality. This corresponds to the tasks of processing the census forms, tax returns, etc.
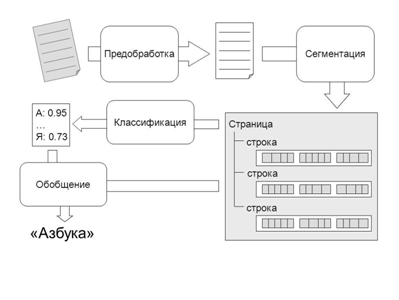
Figure 1 – Strutura OCR systems
Note the following features of the domain, the essential terms of OCR-systems:
- font and dimensional diversity of characters;
- distortion in the images of characters (character breaks the images, for example, when an image is enlarged; coalescence of adjacent characters, etc.);
- biases when scanning;
- foreign matter in the images;
- a wide variety of character classes that can be recognized only if there is additional contextual information.
Automatic reading of printed and handwritten text is a special case of automatic visual perception of complex images. Numerous studies have shown that for a complete solution of this problem must be an intelligent recognition, ie, the "recognition of the understanding." However, at present technically feasible OCR-systems considered problem is greatly simplified and reduced to the problem of classification on the grounds of simple objects. This problem is described by a well developed mathematical apparatus of the threshold traps – separating the planes [5].
The best systems use OCR-recognition technology inherent in man. The man is a multi-pattern recognition.
There are three principle on which all of OCR-based system.
The principle of the integrity of the image: in the test object is always a significant part, between which there are relationships. The results of local operations with parts of the image are interpreted only together in coherent interpretation of the fragments and the whole image as a whole.
The principle focus: the recognition of a purposeful process of nomination and hypothesis testing (search for what is expected from the object).
The principle of adaptability: the recognition system must be capable of self-learning [6].
Graphic image of the symbol at the output of the scanner is given shape is defined, which is a matrix of pixels, which you can edit the element by element. The figure shows an example of Shape of the letter "л" or "п" (look Figure 2). He is closer to the letter "л", but without the context of processing a claim with 100% certainty is impossible [9].

Figure 1 – Shape Example
If the content processing for recognition of "questionable" Shape is drawn about the results of recognition of adjacent elements of the text. In the simplest case, the context is the word.
Information about a particular word is not always sufficient for a decision. For example, the word 'hundred * "in the position of stars can be positioned as the" L "and" n ". In such cases, the analyzed context includes a proposal or a few sentences (of text). The implementation of the relevant mechanisms associated with the problem of understanding natural language.
Types of classifiers
We have previously determined that the recognition system is implemented as a classifier. There are three types of classifiers:
- template (raster);
- indicative;
- structural.
In the first type classifier using the criterion of comparison is determined by which of the templates to select from the database (look Figure 3 ). The simplest criterion – at least the points that distinguish the pattern from the test image.

Figure 3 – Template classifier
The most common are indicative of the classifiers. The analysis is carried out in them only on a set of numbers or characters that are calculated on the image. Thus, there is no recognition of the symbol and set its attributes, ie, derived from the test data symbol. This inevitably causes some loss of information.
The structural shape of a symbol classifications translate into a topological representation that reflects information about the relative positions of the structural elements of the character. These data can be presented in graph form. This method ensures invariance with respect to types and sizes of fonts. The disadvantages are the difficulty of detection of defective characters and slow work.
In today's OCR-systems are commonly used all three types of classifiers, but the basic structure is. In order to accelerate and improve the quality of recognition used raster and indicative of the classifiers [7].
Also, the so called structural-spot model and its fountain (from the English. Font – font) view. It looks like a set of spots with pairwise relationships between them (look Figure 4). Such a structure can be compared with a lot of balls, strung on rubber cord, which can be stretched. This representation is insensitive to different shapes and defects of character [8].

Figure 4 – Structure-spots model.
(animation: 7 frames, 6 loops, 12 kbytes)
The algorithm is based on a combination of pattern and structural methods of pattern recognition. In the analysis of the sample allocated key points of the object – the so called "spots".
As the spots, for example, may be:
- ends of the lines;
- nodes, where several lines converge;
- place breaks lines;
- the intersection of lines;
- endpoints.
After separation, "spots" are defined by the relationship between them – the segment arc. Thus, the final description of a graph, which serves as the object of search in the library of "structural-spots of standards" [8].
When looking for a correspondence between the key points of the sample and reference, and then determined the degree of deformation of the bonds needed to bring the desired object to the compared reference sample. The smaller degree of deformation required suggests a high probability of correct recognition of the character.
How to optimize detection
To improve the quality of recognition are different methods for preprocessing images with text, such as noise reduction [10] The sources of noise in the image can be:
-
analog noise:
- dirt, dust;
- scratches;
-
digital Noise:
- thermal noise of the matrix;
- noise charge transfer;
- quantization noise.
In digital image processing is applied spatial noise reduction. There are the following methods:
- adaptive Filtering – linear averaging neighboring pixels
- median filtering;
- mathematical Morphology;
- gaussian Blur;
- methods based on discrete wavelet transform;
- principal component;
- anisotropic diffusion;
- wiener filters.
After the recognition can be done to alter that improves the quality of recognition of controversial characters (ie characters that have multiple candidates with approximately the same estimate of the extent to which several models) based on:
- analysis of combinations of letters, characteristic of the language;
- language dictionary;
- grammatical analysis;
- and other methods.
Output
Automatic seeing today is less than perfect human perception of the text. The main reason for this lies in the inability to build a fairly complete and semantically expressive computer models of the domain.
After analyzing the existing methods of text recognition, we can conclude that it is best to use a method struturno-spot pattern, as it combines the advantages of many methods and thus is flexible enough to apply it with the recognition of handwriting.
References
- Абраменко А. Принципы распознавания / А. Абраменко – K:.Компьютер–пресс, 1997 – 123 с.
- Research Library – статья по искусственному интеллекту.
- Шамис А.Л. Принципы интеллектуализации автоматического распознавания / А.Л. Шамис – K:.2000 – 312 с.
- StatSoft – сайт, посвященный нейронным сетям.
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознавани / М. Шлезингер, В. Главач – М.:2004 – 112 c.
- Гаврилов Г.П. Логический подход к искусственному интеллекту / Г.П. Гаврилов – М.: Мир, 1998 – 256 с.
- Кучуганов А.В. , Лапинская Г.В. Распознавание рукописных текстов / А.В. Кучуганов, Г.В. Лапинская – Ижевск:.Мир, 2006 – 514 с.
- G.A.Carpenter and S. Grossberg Pattern Recognition by SelfOrganizing Neural Networks / G.A.Carpenter and S. Grossberg N.Y.:MIT Press, 1991 – 541 c.
- The First Census Optical Character Recognition System Conference / Wilkinsonet R.A. – Gaithersburg:Commerse, NIST, 1992 – 242 c.
- Шлезингер М., Главач В. Структурное распознавание / М. Шлезингер , В. Главач – Киев: Наукова думка, 2006 – 300 с.
Important
At the time of writing this essay is to master the job is not complete. Estimated date of completion: December 2012, as a consequence of the full text, as well as materials on the subject may be obtained from the author or his head only after the specified date.