




Біография
- Вступ
- Актуальність
- Аналіз підходів до проектування систем оптичного читання текстів
- Види класифікаторів
- Методи оптимізації розпізнавання
- Висновок
- Список літератури
Вступ
Розпізнавання рукописного введення – це здатність комп’ютера отримувати та інтерпретувати інтелектуальний рукописний ввід. Розпізнавання тексту може проводитися "оффлайновим" методом з уже написаного на папері тексту або "онлайновим" методом зчитуванням рухів кінчика ручки, наприклад по поверхні спеціального комп’ютерного екрану [1].
Офлайновий вид розпізнавання успішно застосовується в сферах діяльності, де необхідно обробляти велику кількість рукописних документів, наприклад, в страхових компаніях. Якість розпізнавання можна підвищити, використовуючи структуровані документи (форми). Крім того, можна поліпшити якість, зменшивши діапазон можливих символів. Оффлайнові розпізнавання вважається більш складним у порівнянні з онлайновим.
Точне розпізнавання латинських символів в друкованому тексті в даний час можливо тільки якщо доступні чіткі зображення, такі як скановані друковані документи. Точність при такій постановці завдання перевищує 99%, абсолютна точність може бути досягнута тільки шляхом наступного редагування людиною. Проблеми розпізнавання рукописного "друкарського" і стандартного рукописного тексту, а також друкованих текстів інших форматів (особливо з дуже великим числом символів) в даний час є предметом активних досліджень [2].
Актуальність
Широко досліджуваною проблемою є розпізнавання рукописного тексту [3]. На даний момент досягнута точність навіть нижче, ніж для рукописного "друкарського" тексту. Більш високі показники можуть бути досягнуті тільки з використанням контекстної і граматичної інформації. Наприклад, в процесі розпізнання шукати цілі слова в словнику легше, ніж намагатися проаналізувати окремі символи з тексту. Знання граматики мови може також допомогти визначити, чи є слово дієсловом або іменником. Форми окремих рукописних символів іноді можуть не містити достатньо інформації, щоб точно (більше 98%) розпізнати весь рукописний текст.
Методи автоматичного розпізнавання образів та їх реалізація в системах оптичного читання текстів (OCR-системах – Optical Character Recognition) – одна з найбільш плідних технологій ШІ [3].
У наведеній трактувці OCR розуміється як автоматичне розпізнавання за допомогою спеціальних програм зображень символів друкованого або рукописного тексту (наприклад, введеного в комп’ютер за допомогою сканера) і перетворення його в формат, придатний для обробки текстовими процесорами, редакторами текстів і т. д.
Аналіз підходів до проектування систем оптичного читання текстів
Скорочення OCR іноді розшифровують як Optical Character Reader [4]. В цьому випадку під OCR розуміють пристрій оптичного розпізнавання символів або автоматичного читання тексту (див. Рисунок 1). В даний час такі пристрої при промисловому використанні обробляють до 100 тис. документів на добу. Промислове використання передбачає введення документів хорошої і середньої якості. Це відповідає завданням обробки бланків перепису населення, податкових декларацій і т. п.
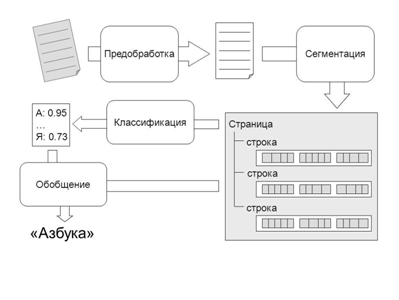
Рисунок 1 – Струтура OCR систем
Відзначимо наступні особливості предметної області, суттєві з точки зору OCR-систем:
- шрифтова і розмірна різноманітність символів;
- дефекти в зображеннях символів (розриви образів символів, наприклад, при збільшенні зображення; злипання сусідніх символів тощо);
- перекоси при скануванні;
- сторонні включення в зображеннях;
- велика різноманітність класів символів, які можуть бути розпізнані тільки при наявності додаткової контекстної інформації.
Автоматичне читання друкованих та рукописних текстів є окремим випадком автоматичного візуального сприйняття складних зображень. Численні дослідження показали, що для повного вирішення цього завдання необхідно інтелектуальне розпізнавання, тобто "розпізнавання з розумінням". Проте в даний час в технічно реалізованих OCR-системах розглянута проблема значно спрощена і зведена до задачі класифікації за ознаками простих об’єктів. Це завдання описується добре розробленим математичним апаратом порогових відокремлювачів – розділяючими площинами [5].
У кращих OCR-системах використовується технологія розпізнавання, властива людині. У людини розпізнавання образу є багатоступеневим.
Виділяються три принципи, на яких засновані всі OCR-системи.
Принцип цілісності образу: в досліджуваному об’єкті завжди є значущі частини, між якими існують відносини. Результати локальних операцій з частинами образу інтерпретуються тільки спільно в процесі інтерпретації цілісних фрагментів і всього образу в цілому.
Принцип цілеспрямованості: розпізнавання є цілеспрямованим процесом висування і перевірки гіпотез (пошуку того, що очікується від об’єкта).
Принцип адаптивності: розпізнає система повинна бути здатна до самонавчання [6].
Графічний образ символу на виході сканера має вигляд шейпу, що представляє собою матрицю з точок, яку можна редагувати поелементно. На малюнку наведено приклад шейпу букви "л" або "п" (див. Рисунок 2). Він ближче до букви "л", але без контекстної обробки стверджувати це зі 100%-ою впевненістю можна сказати при контекснiй оброцi [9].

Рисунок 2 – Приклад шейп
При контекстної обробці для розпізнавання "сумнівного" шейпу залучається інформація про результати розпізнавання сусідніх елементів тексту. У простому випадку контекстом служить слово.
Інформація про окреме слово не завжди достатня для прийняття рішення. Наприклад, в слові "сто *" в позиції зірочки може розташовуватися як "л", так і "п". У таких випадках аналізований контекст включає пропозицію або декілька пропозицій (фрагмент тексту). Реалізація відповідних механізмів пов’язана з вирішенням проблеми розуміння тексту на природній мові.
Види класифікаторів
Раніше ми визначили, що система розпізнавання реалізується як класифікатор. Існують три типи класифікаторів:
- шаблонні (растрові);
- ознакові;
- структурні.
У класифікаторі першого типу за допомогою критерію порівняння визначається, який з шаблонів вибрати з бази (див. Рисунок 3). Найпростіший критерій – мінімум точок, що відрізняють шаблон від досліджуваного зображення.

Рисунок 3 – Шаблонний класифікатор
Найбільш поширені ознакові класифікатори. Аналіз в них проводиться тільки по набору чисел або ознак, що обчислюються по зображенню. Таким чином, відбувається розпізнавання не самого символу, а набору його ознак, тобто похідних даних від досліджуваного символу. Це неминуче викликає деяку втрату інформації.
Структурні класифікатори переводять шейп символу в його топологічний уявлення, що відображає інформацію про взаємне розташування структурних елементів символу. Ці дані можуть бути представлені в графовой формі. Такий спосіб забезпечує інваріантність щодо типів і розмірів шрифтів. Недоліками є важкість розпізнавання дефектних символів і повільна робота.
В сучасних OCR-системах зазвичай використовуються всі три типи класифікаторів, але основним є структурний. Для прискорення і підвищення якості розпізнавання застосовуються растровий і ознакових класифікатори [7].
Також застосовується так званий структурно-плямовий еталон і його фонтанне (від англ. Font – шрифт) подання. Воно має вигляд набору плям з попарними відносинами між ними (див. Рисунок 4). Подібну структуру можна порівняти з безліччю куль, нанизаних на гумові шнури, які можна розтягувати. Це подання невідчутно до різних накресленням і дефектих символів [8].

Рисунок 4 – Структурно-плямовий еталон.
(анiмацiя: 7 кадрiв, 6 циклiв повторення, 12 кiлобайт)
Алгоритм заснований на поєднанні шаблонного і структурного методів розпізнавання образів. При аналізі зразка виділяються ключові точки об’єкта – так звані "плями".
У якості плям, наприклад, можуть виступати:
- кінці ліній;
- вузли, де сходяться декілька ліній;
- місця зламів ліній;
- місця перетину ліній;
- крайні точки.
Після виділення "плям" визначаються зв’язки між ними – відрізок, дуга. Таким чином, підсумковий опис являє собою граф, який і є об’єктом пошуку в бібліотеці "структурно-плямових еталонів" [8]
При пошуку встановлюється відповідність між ключовими точками зразка і еталону, після чого визначається ступінь деформації зв’язків, необхідна щоб привести шуканий об’єкт до порівнюваному еталонному зразку. Менша ступінь необхідної деформації передбачає велику ймовірність правильного розпізнавання символу.
Методи оптимізації розпізнавання
Для підвищення якості розпізнавання застосовуються різні методи передобробки зображень з текстом, наприклад шумозаглушення [10]. Джерелами шумів на зображенні можуть бути:
-
аналоговий шум:
- бруд, пил;
- подряпини;
-
цифровий шум:
- тепловий шум матриці;
- шум переносу заряду;
- шум квантування АЦП.
При цифровій обробці зображень застосовується просторове шумозаглушення. Виділяють наступні методи:
- адаптивна фільтрація – лінійне усереднення пікселів по сусідніх;
- медіанна фільтрація;
- математична морфологія;
- розмиття по Гауссу;
- методи на основі дискретного вейвлет-перетворення;
- метод головних компонент;
- анізотропна дифузія;
- фільтри Вінера.
Після розпізнавання може виконуватися додаткова корекція, що дозволяє збільшити якість розпізнавання суперечних символів (тобто символів у яких є кілька кандидатів з приблизно однаковою оцінкою ступеня відповідності декільком еталонам) на основі:
- аналізу буквосполучень, характерних для мови;
- словника мови;
- граматичного аналізу;
- та інших методів.
Висновок
Автоматичне зорове сприйняття на сьогоднішній день не досягає досконалості людського сприйняття тексту. Головна причина цього полягає у невмінні будувати досить повні і семантично виразні комп’ютерні моделі предметної області.
Проаналізувавши існуючі методи розпізнавання текстів, можна зробити висновок, що краще всього використовувати метод струтурно-плямового шаблону, так як він об’єднує в собі переваги багатьох методів і завдяки цьому є достатньо гнучким щоб застосувати його при розпізнаванні рукописного тексту.
Список літератури
- Абраменко А. Принципы распознавания / А. Абраменко – K:.Компьютер–пресс, 1997 – 123 с.
- Research Library – статья по искусственному интеллекту.
- Шамис А.Л. Принципы интеллектуализации автоматического распознавания / А.Л. Шамис – K:.2000 – 312 с.
- StatSoft – сайт, посвященный нейронным сетям.
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознавани / М. Шлезингер, В. Главач – М.:2004 – 112 c.
- Гаврилов Г.П. Логический подход к искусственному интеллекту / Г.П. Гаврилов – М.: Мир, 1998 – 256 с.
- Кучуганов А.В. , Лапинская Г.В. Распознавание рукописных текстов / А.В. Кучуганов, Г.В. Лапинская – Ижевск:.Мир, 2006 – 514 с.
- G.A.Carpenter and S. Grossberg Pattern Recognition by SelfOrganizing Neural Networks / G.A.Carpenter and S. Grossberg N.Y.:MIT Press, 1991 – 541 c.
- The First Census Optical Character Recognition System Conference / Wilkinsonet R.A. – Gaithersburg:Commerse, NIST, 1992 – 242 c.
- Шлезингер М., Главач В. Структурное распознавание / М. Шлезингер , В. Главач – Киев: Наукова думка, 2006 – 300 с.
Важливо
На момент написання даного реферату магістерська робота ще є не завершеною. Передбачувана дата завершення: грудень 2012 р., через що повний текст роботи, а також матеріали по темі можуть бути отримані у автора або його керівника тільки після зазначеної дати.