
Abstract
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Description of themed literature and researches
- 4. Pipelined devices on FPGA
- Conclusion
- References
Introduction
The regular structure of FPGAs lets us to base on it a single device or system of several devices, and even some independent units. The main advantage of FPGAs is the ability to implement on their base principles of parallelism and pipelining.[6]. The first principle is the possibility of simultaneous execution of several similar actions and is implemented mainly in the form of duplication devices. The second principle allows to split the implementation of complex tasks on a number of simple consistent with the simultaneous combination of actions to perform in time. This principle has long established itself and is not used only in computing, but also in industry. Animation of the instruction pipeline of processor is shown in Figure 1.
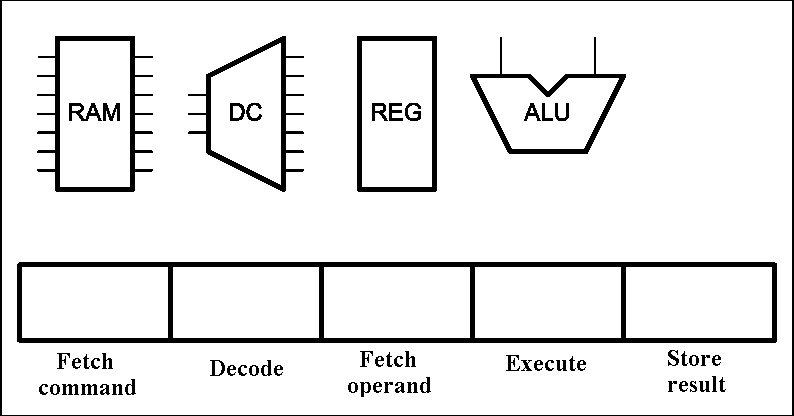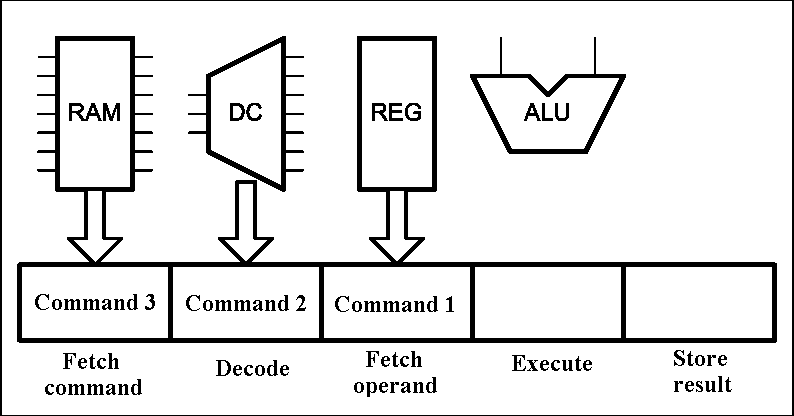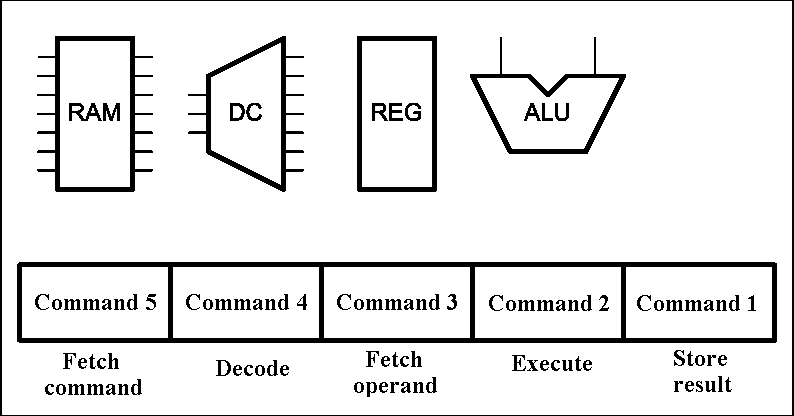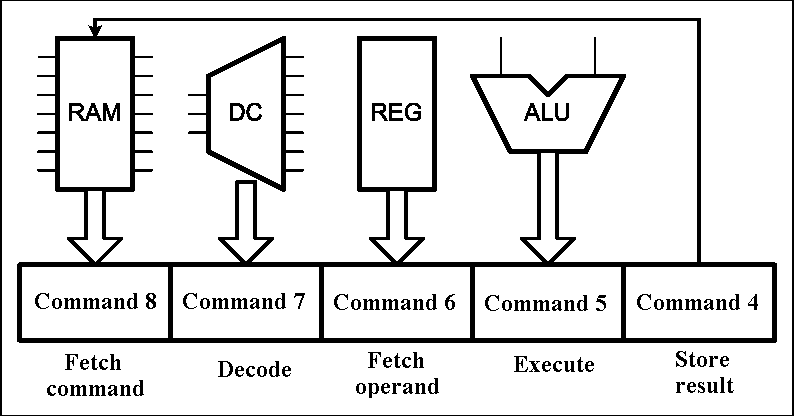
Figure 1 – instruction pipeline of processor (animation: 16 frames, 5 repeat loops, 116 kbytes) (RAM – random access memory, DC – command decoder, REG – register block, ALU – arithmetical-logical unit)
1. Theme urgency
The implementation of the principle of pipelined data processing on the FPGA is interesting and urgent by the fact that the basic structure of this type of logic element FPGAs are very well suited to implement this type of devices [1]. To clarify the situation, consider a simplified structure of the base logic cell. The considered cell consists of two elements: the function generator 4 inputs to 1 output and the trigger element. When using only combinational part, the trigger can not be used in any other circuits, so useing both parts of the cells does not required additional costs of equipment, while making a significant delay in the scheme. For example, for FPGA Virtex6 signal delay in the LUT as a scheme for 4 input AND is 61 ps., signal delay between the LUT and FF can be neglected, response time of FF id 317 ps. The difference of 5 times is quite significant, but the absolute values of these elements dramatically small comparing to delay in communication links between them. For example, for the same chip signal propagation from the input of LUT to the pins was 566 ps., And the signal propagation time from the output of LOT to the pins crystal was about 344 ps. From this we can conclude that in some cases, the using of FF does not introduce significant delay and can be used between the combinational circuits to implement pipelining.
2. Goal and tasks of the research
The main purpose of the study is to develop efficient methods for construction pipelined devices on FPGA chips. For achieve this goal it is necessary to solve several problems:
- Consider internal architecture of the FPGA chip;
- Implement pipelining of the basic circuit of summation and multiplication by embedded multipliers;
- Pipeline a combinational multiplier and a divider;
- Consider implementation of pipelined processing in more complex schemes (encoders, decoders, hardware circuits for hardware sorting and unzipping the archive, digital signal processing circuits and their use in devices of compression and decompression audio, video and graphics);
- Develop effective method of synthesis of pipelined devices based on the FPGA;
- Synthesize one of the above considered devices to debug and test on the development board;
- Draw conclusions about the effectiveness of the developed method;
As the technique is planned to develop specific recommendations for behavioral and structural, synthesized VHDL-description of primitive functional blocks, as well as complete devices, taking into account architectural features of the FPGA-technology (the structure of the base logic cell, embedded functional units, switching matrix, etc.).
3. Description of themed literature and researches
FPGA technology is rapidly developing, so it works a significant number of people. However, due to the fact that the FPGA possible to implement almost any device, and the internal structure crystal is constantly being improved, the methods and implementation of individual modules are also being improved. It is therefore necessary to continuously monitor the development, both hardware and methodological framework. In Ukraine FPGA has not yet been properly developed, but this trend are available.
Before proceeding directly to the implementation of specific devices in VHDL,we must be familiar with the internal structure of chips of this type. The largest manufacturers of FPGA-chip firms are Xilinx and Altera, technical documentation of these chips, and of other firms can be found on their official websites. Documentation of the total structure of the chip from Xilinx Virtex6 shown in [2], and structure of combinational logic block is described in [1]. Similar literature for Altera Stratix V is shown in [8]. In addition to understand the structure of the hardware, you need to know how VHDL design patterns are being transformed into various hardware primitives for a particular tool and the target platform. This information is available in the sources [3] and [9] respectively.
After reviewing the above literature the study of specific techniques and applications circuits can be proceed. One of the promising uses of FPGA chips is to build on their base digital signal processing devices. A good source for this theme is [6]. In the third section of this book techniques and parallelization pipelining digital signal processing algorithms are described, especially important for their implementation on FPGA. In [11] and [17] fast Fourier transform implementation is investigated. It is also possible implementation in this type of programmable logic devices, schemes encryption and decryption. An example implementation of a cryptographic algorithm is shown in [10]. One application of FPGA chips is the realization on their base arithmetic units. In [19] the example of the implementation of the algorithm for finding the square root is described. In [4] and [7] the features of the implementation of pipelined multipliers on the FPGA are shown. An important role in the development of pipelined FPGA devices is optimization the hardware costs and speed. This issues are discussed in the literature [5] and [18].
Despite the small consideration of technologies in Ukraine and Russia research in this area are carried out. In [13] implementation of digital signal processing units on FPGA are described. In [12] the example of implementation of fast Furier transform are leaded and in [14] – variant of discrete cosinus transform is shown. Othes devices implementation causes interest to their too. For example digital frequency synthesyzer in [16]. One of the main spheres of pipelining is a construction of pipelined microprocessor [15].
In addition to scientific articles on this topic is also protected by the candidate and doctoral dissertation. Methods and tools for creating effective parallel-pipelined computer software systems that are based on FPGA technology are discussed in [20]. In [21] the development of modeling techniques parallel-pipelined neural network structures for high-speed digital signal processing is considered. Research and development of methods for solving high resolution problems on computing systems with variable bit-width is described in [22]. Research and development of methods for the behavioral synthesis of pipelined circuits for digital processing of video images is provided in [23]. In [24] research of methods to implement algorithms of processing of large data amounts with help of the pipeline parallelism is conducted. In [25] parallelization of computer algebra algorithms based on the arithmetic of polynomials is considered.
In the Donetsk National Technical University the researches in the FPGA technology sphere are also taken place. So in [27] is described how to implement a hardware sorting, in [28] – construction of communication systems on FPGA. In [29] review of the implementation of digital signal processing on FPGA is being continued. In [32] an implementation of MPEG2 video processors is show. he development of network cryptographic systems is considered in [31]. The development of multiprocessor systems for solving ordinary differential equations based on FPGA-technology is considered in [30], And a computer-aided design of a high-speed digital devices on FPGA – in [26].
4. Pipelined devices on FPGA
As example of pipelining in devices based on FPGA technology, implementations of adder and multiplier was sythesized and investigated. Result of this is showm on figures 2, 3, 4, 5.
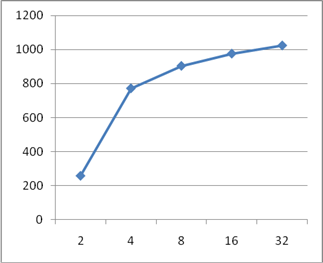
Figure 2 – A plot of the hardware cost dependency of pipelined adder from number of pipeline stages
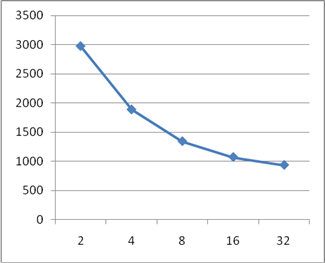
Figure 3 – A plot of the delay dependency of pipelined adder from number of pipeline stages
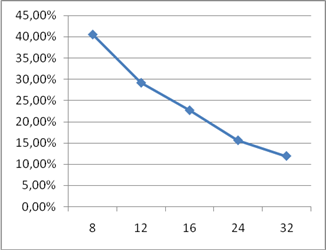
Figure 4 – A plot of the hardware cost increasing dependency of pipelined multiplier from number of pipeline stages
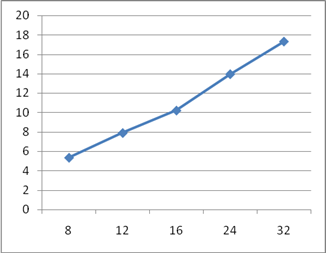
Figure 5 – A plot of the performance increasing dependency of pipelined multiplier from number of pipeline stages
Conclusion
In this paper structural features of the logical FPGA cell and using it effectively to build devices with pipelined architecture were examined [5]. As a result of the developing previous schemes synthesized VHDL-description have been obtained. On this results the following conclusions are based:
- Increasing speed of pipelined circuits depends on the number of pipeline stages and balance of performance between registered and combinational parts of circuit, and seeks to value t / m, where t - time of the original scheme, m - the number of pipeline stages. That is, pipelining devices with a large response time step, will larger increase in speed;
- The increase of hardware cost implementation of the pipelined processing method depends on the ratio of registered and combinational costs and tend to zero, that is, when pipelining devices have expensive LUT stage, additional hardware costs are reduced, becouse triggers of the combinational parts of logic cells will be used;
- Pipelining of summation requires a much larger costs of storage elements and gives a smaller increase in speed compared to the pipelined multiplier.
The principles discussed in this paper can also be used for build more complex devices in the following spheres:
- Encoding;
- Decoding;
- Hardware sorting and archiving;
- Digital signal processing;
Writing of this Master work is not finished yet. Final completion: December 2012. Full text of the work and materials on the subject may be obtained from the author or his leader after that date.
References
- Virtex-6 FPGA Configurable Logic Block. User Guide. UG364(v1.2) February 3, 2012. – p. 50
- Virtex-6 Family Overview. Product Specification. DS150(v2.4) January 19, 2012. – p. 11
- XST User Guide for Virtex-6, Spartan-6, and 7 Series Devices. UG687(v13.4) January 18,2012. – p. 489
- Alex Panato, Sandro Silva, Flavio Wagner, Marcelo Johan, Ricardo Reis, Sergio Bampi. Design of Very Deep Pipelined Multiplier for FPGAs. Proceedings of the conference on Design, automation and test in Europe - Volume 3. IEEE Computer Society Washington, DC, USA ©2004. – p. 6
- Oswaldo Cadenas, Graham Megson. Journal of System Architecture 50 (2004) 687-696. A clocking technique for FPGA pipelined designs. – p. 10
- Keshab K. Parhi. VLSI Digita Signal Processing Systems: Design and Implementation. John Wiley & Sons, 1999. Chapter 3: Pipelining and Parallel Processing. – p. 32
- Mathew Wojko. Pipelined Multipliers and FPGA Architecture. FPL '99 Proceedings of the 9th International Workshop on Field-Programmable Logic and Applications. Springer-Verlag London, UK ©1999. – p. 7
- Stratix V Device Handbook. – p. 580
- Quartus II Handbook Version 11.1. – p. 1686
- Sounak Samanta B.E. III Yr, Electronics & Communication Engg, Sardar Vallabhbhai National Institute of Technology, Surat. FPGA Implementation of AES Encryption and Decryption [Электронный ресурс]. – Режим доступа: http://www.design-reuse.com/articles/13981/fpga-implementation-of-aes-encryption-and-decryption.html
- Bin Zhou, Yingning Peng and David Hwang. Pipeline FFT Architectures Optimized for FPGAs [Электронный ресурс]. – Режим доступа: http://www.hindawi.com/journals/ijrc/2009/219140/
- Мистюков В., Володин П., Капитанов В.. Однокристальная реализация алгоритма БПФ на ПЛИС фирмы Xilinx [Электронный ресурс]. – Режим доступа: http://www.compitech.ru/html.cgi/arhiv/00_05/stat_70.htm
- Стешенко В.Б. ПЛИС фирмы Altera: проектирование устройств обработки сигналов. [Электронный ресурс]. – Режим доступа: http://www.dsol.ru/stud/book7/chapter7/page7_01.html
- Сергієнко А.М., Лепеха В.Л., Лесик Т.М. Спецпроцесори для двовимірного дискретного косинусного перетворення. Журнал “Вісник” НТУ КПИ. “Інформатика, управління і обчислювальна техника”. Випуск №47. Київ “Вік+”. – с. 230–233
- Строгонов А. Проектирование микропроцессорных ядер с конвейерной архитектурой для реализации в базисе ПЛИС фирмы Altera. Журнал Компоненты и технологии. №8, 2009 г. – с. 86–89
- Стахів Р. І. Цифрові синтезатори частоти на основі число-імпульсних перетворювачів кодів. Поліграфічний центр Видавництва Національного університету "Львівська політехніка" 79000, м. Львів, вул. Ф. Колесси, 2. – с. 24
- Shousheng He and Mats Torkelson. Department of Applied Electronics, Lund University S-22100 Lund, SWEDEN. A New Approach to Pipeline FFT Processor. – p. 5
- Ling Zhuo, Student Member, IEEE, Gerald R. Morris, and Viktor K. Prasanna, Fellow, IEEE. High-Performance Reduction Circuits Using Deeply Pipelined Operators on FPGAs. – p. 1377–1392.
- Brian J. Shelburne. Dept of Math and Comp Sci Wittenberg University. Zuse's Z3 Square Root Algorithm. – p. 11
- Иванов А. И. Методы и средства создания эффективного параллельно-конвейерного программного обеспечения вычислительных систем, построенных на основе плис-технологии [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/metody-i-sredstva-sozdaniya-effektivnogo-parallelno-konveiernogo-programmnogo-obespecheniya-
- Стрекалов Ю. А. Разработка методов моделирования параллельно-конвейерных нейросетевых структур для высокоскоростной цифровой обработки сигналов [Электронный ресурс]. – Режим доступа: http://www.lib.ua-ru.net/diss/cont/199480.html
- Гильванов М. Ф. Разработка и исследование методов решения задачи высокого разрешения на вычислительных системах с переменной разрядностью [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/razrabotka-i-issledovanie-metodov-resheniya-zadachi-vysokogo-razresheniya-na-vychislitelnykh
- Анисимов И. Ю. Исследование и разработка методов поведенческого синтеза конвейерных схем для цифровой обработки видеоизображений [Электронный ресурс]. – Режим доступа: http://www.dissland.com/catalog/issledovanie_i_razrabotka_metodov_povedencheskogo_sinteza_konveyernih_shem_dlya_tsifrovoy_obrabotki_.html
- Лысаков К. Ф. Исследование методов реализации алгоритмов обработки больших потоков данных за счет конвейерного распараллеливания [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/issledovanie-metodov-realizatsii-algoritmov-obrabotki-bolshikh-potokov-dannykh-za-schet-kon-0
- Валеев Ю. Д. Система распараллеливания алгоритмов компьютерной алгебры на основе арифметики полиномов [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/sistema-rasparallelivaniya-algoritmov-kompyuternoi-algebry-na-osnove-arifmetiki-polinomov
- Кузьменко В. О.. Автоматизация проектирования быстродействующих цифровых устройств на FPGA [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2008/fvti/kuzmenko/diss/index.htm
- Садыкбаев А. В. Разработка реконфигурированной системы для реализации сортировщиков [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2009/fvti/sadykbaiev/diss/index.htm
- Зинченко Е. Ю. Разработка и исследование структур устройства передачи данных на базе HDL и FPGA технологий [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2011/fknt/zinchenko/diss/index.htm
- Войтов Г. В. Анализ аналоговых сигналов на базе ЦОС в FPGA [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2009/fvti/voitovg/diss/index.htm
- Дружинин А. И. Разработка многопроцессорных систем решения обыкновенных дифференциальных уравнений на базе FPGA-технологий [Электронный ресурс]. – Режим доступа: http://www.masters.donntu.ru/2006/fvti/druzhynin/diss/index.htm
- Ульянов Ю. В. Разработка структуры сетевых криптографических устройств на снове HDL и FPGA технологий [Электронный ресурс]. – Режим доступа: http://www.masters.donntu.ru/2006/fvti/ulyanov/diss/referat.htm
- Муха Е. М. Исследование реализаций MPEG2 видеопроцессоров на FPGA и PRUS [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2005/fvti/mukha/diss/index.htm