
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження, заплановані результати
- 3. Огляд досліджень і розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Конвеєрні пристрої на FPGA
- Висновки
- Перелік посилань
Вступ
В даний час відбувається бурхливий розвиток обчислювальної техніки. Але із зростанням продуктивності обчислювальних засобів зростають і обчислювальна складність алгоритмів, а також вимоги щодо швидкодії з боку користувача. Реалізувати обробку даних на даний момент можна на основі двох базових апаратних технологій: мікропроцесорної техніки і програмованих логічних інтегральних схемах (ПЛІС). Обидві технології мають як переваги, так і недоліки. До переваг мікропроцесорів можна віднести простоту розробки пристроїв на їх базі, яка, по суті, зводитися до написання програмного забезпечення. Все більшої популярності набуває проектування пристроїв на базі останньої технології, а саме FPGA (Field-programmable gate array). При цьому витрати на розробку і складність значно зростає, так як потрібно спеціалізоване середовище розробки та відлагоджувальна плата. Чому ж FPGA технологія більш приваблива у порівнянні з мікропроцесорною технологією? Регулярна структура ПЛІС дозволяє будувати на основі однієї мікросхеми комплекси з декількох пристроїв і навіть кілька незалежних пристроїв. Основною перевагою ПЛІС є можливість реалізації на їх базі принципів паралелізму і конвейеризації [6]. Перший принцип полягає у можливості одночасного виконання декількох однотипних дій і реалізується в основному у вигляді дублювання пристроїв. Другий принцип дозволяє розбити виконання складного завдання на ряд простих послідовних дій з одночасним поєднанням їх виконання у часі. Даний принцип давно зарекомендував себе і використовується не тільки в обчислювальній техніці, але і в промисловості. Розглянемо принцип конвеєризації на основі роботи конвеєра команд процесора, схема якого зображена на рисунку 1.
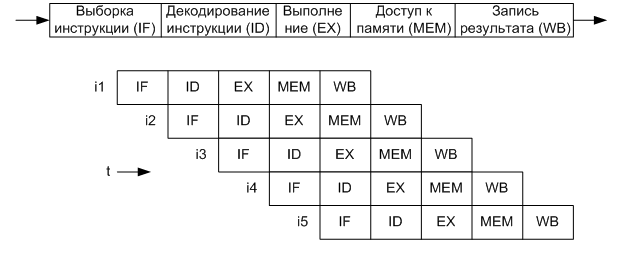
Рисунок 1 – Схема конвеєра команд
Розглянутий конвеєр складається з п'яти ступенів, кожна з яких виконує певну дію над командою. Після завершення обробки поточної команди на поточному етапі, виконання команди переходить на наступний етап, а на даний етап обробки надходить наступна команда. Припустимо, що кожен ступінь конвеєра виконує обробку за один такт, тоді після завантаження конвеєра (5 тактів), виконання команд проводитиметься з періодом в один такт. вважаючи, що звичайне (не конвеєрне) виконання команди займає 5 тактів, то маємо прискорення виконання команд в 5 разів. Є, звичайно ж, обмеження і недоліки даного методу, але всі вони також можуть бути вирішені у тому або іншому ступені. Описаний принцип можна використовувати і для прискорення виконання інших алгоритмів. Анімація роботи конвеєра команд процесора наведена на рисунку 2.
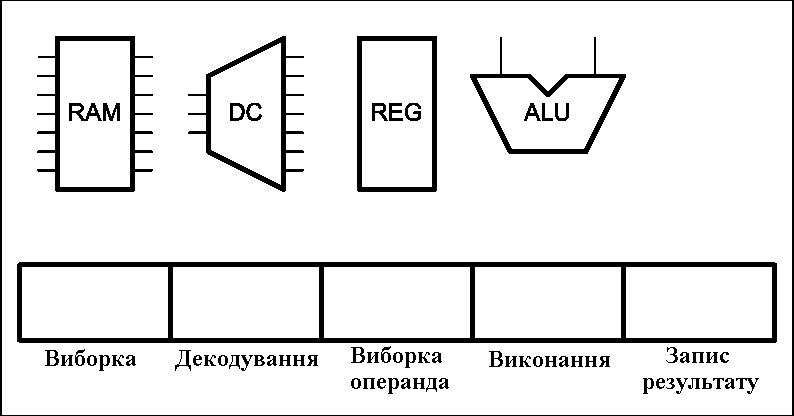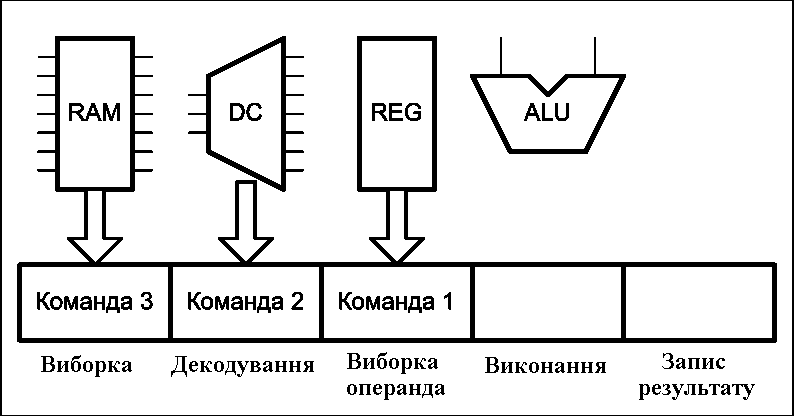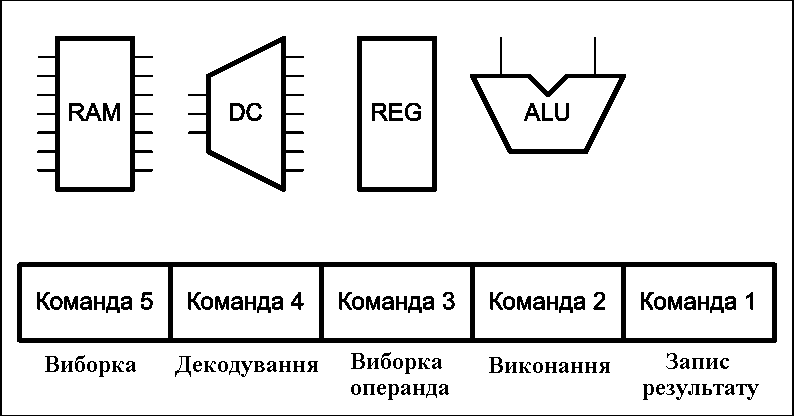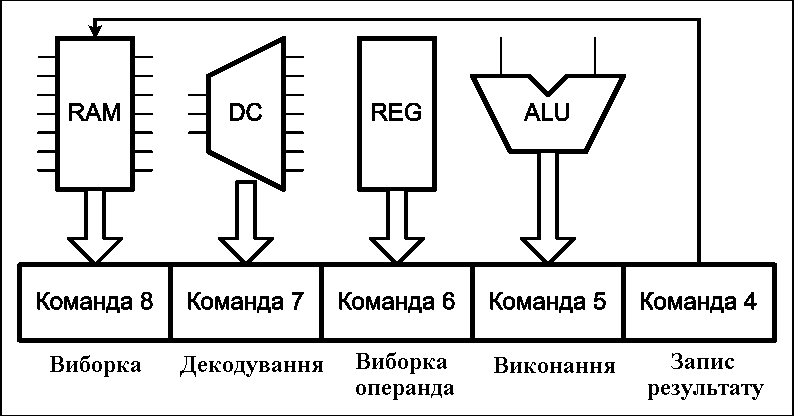
Рисунок 2 – Работа конвеєра команд процесора (анимація: 16 кадрів, 5 циклів повторення, 127 кілобайт) (RAM – оперативна пам’ять, DC – дешифратор команд, REG – блок регістрів, ALU – арифметико-логічний пристрій)
1. Актуальність теми
Реалізація конвеєрного принципу обробки даних на FPGA цікава і актуальна тим, що структура базового логічного елемента даного типу ПЛІС дуже добре підходить для реалізації пристроїв саме такого типу [1]. Для з'ясування ситуації розглянемо спрощену структуру базової логічної комірки, що наведена на рисунку3.
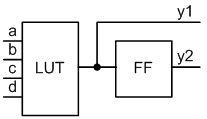
Рисунок 3 – Спрощена структура базової логічної комірки FPGA
Розглянута комірка складається з двох елементів: комбінаційного функціонального генератора 4 входи на 1 вихід і тригерного елемента. При використанні тільки комбінаційної частини, тригерна частина не може бути використана в будь-яких інших ланцюгах, тому використання обох частин осередку не призводить до додаткових витрат устаткування, хоча вносить значну затримку в схему. Наприклад, для FPGA Virtex6 затримка сигналу на LUT у вигляді схеми AND на 4 входи складає 61 ps., затримкою сигналу між LUT і FF можна знехтувати, час спрацьовування FF склало 317 ps. Різниця в 5 разів вельми значна, але при таких абсолютних значеннях затримок елементів різко встає проблема затримок ліній зв'язку між ними. Наприклад, для тієї ж мікросхеми, розповсюдження сигналу від ніжок кристала до LUT склало 566 ps., А час поширення сигналу від виходів схеми до ніжок кристала склало близько 344 ps. З цього можна зробити висновок, що в деяких випадках використання FF не вносить значну затримку і може бути використаний між комбінаційними схемами для реалізації конвейеризації.
2. Мета і задачі дослідження, заплановані результати
Основною метою дослідження є розробка ефективної методики побудови пристроїв конвеєрного типу на FPGA мікросхемах. Для досягнення поставленої мети необхідно вирішити ряд задач:
- Розглянути внутрішню архітектуру FPGA мікросхеми;
- Реалізувати конвеєризацію базової схеми додавання та схеми множення на вбудованих помножувачах;
- Побудувати конвеєрні варіанти комбінаційного помножувача та дільника;
- Розглянути реалізацію конвеєрної обробки в більш складних схемах (кодери-декодери, шифратори-дешифратори, схеми апаратного сортування, схеми апаратної архівації та розархівації, схеми цифрової обробки сигналів та їх використання в пристроях компресії і декомпресії звукової, відео-та графічної інформації);
- Розробити методику синтезу ефективних конвеєрних схем на FPGA;
- Синтезувати одне із розроблених вище пристроїв та протестувати його на відлагоджувальній платі;
- Зробити висновки об ефективності розробленої методики;
В якості методики планується розробити конкретні рекомендації щодо поведінкового і структурному VHDL-синтезу, як примітивних функціональних блоків, так і закінчених пристроїв з урахуванням архітектурних особливостей FPGA-технології (структура базової логічної комірки, вбудовані функціональні вузли, комутаційна матриця і т. д.).
3. Огляд досліджень та розробок
FPGA технологія швидко розвивається, тому з нею працює значна кількість людей. Однак, у зв'язку з тим, що на FPGA можлива реалізація практично будь-яких пристроїв, а внутрішня структура кристала постійно вдосконалюється, то удосконалюються і методи реалізації окремих модулів. Саме тому необхідно постійно стежити за розвитком, як апаратної, так і методологічної бази. В Україна FPGA ще не отримала належного розвитку, однак тенденції до цього є.
3.1 Огляд міжнародних джерел
Перш ніж переходити безпосередньо до реалізації конкретних пристроїв на VHDL, необхідно ознайомиться з внутрішньою структурою мікросхем даного типу, щоб результати синтезу були більш-менш передбачуваними. Найбільшими виробниками FPGA-мікросхем є фірми Xilinx і Altera, технічну документацію по мікросхемам цих та інших фірм можна подивитися на їх офіційних сайтах. Документація по загальній структурі мікросхем Virtex6 від Xilinx приведена в [2], а за структурою комбінаційного логічного блоку в [1]. А аналогічна література з Stratix V від Altera приведена в [8]. Крім розуміння структури апаратних засобів, необхідно також знати закономірності перетворення VHDL конструкція в ті чи інші апаратні примітиви для конкретного засобу та цільової платформи. Дана інформація є в джерелах [3] і [9] відповідно.
Після розгляду наведеної вище літератури можна переходити до вивчення конкретних прикладних методів і схем. Одним з перспективних напрямів використання FPGA мікросхем є побудова на їх базі пристроїв цифрової обробки сигналів. Хорошим джерелом з даної темі є [6]. У третьому розділі даної книги наведені методики розпаралелювання і конвейеризації алгоритмів цифрової обробки сигналів, що особливо важливо при їх реалізації на FPGA. В [11] і [17] досліджена реалізація швидкого перетворення Фур'є. Також можлива реалізація на даному типі програмованих логічних схем пристроїв шифрування і дешифрування. Приклад реалізації криптографічного алгоритму наведено в [10]. Одним із застосувань мікросхем FPGA є реалізація на їх базі арифметичних пристроїв. В [19] розглянуто приклад реалізації алгоритму знаходження квадратного кореня. В [4] і [7] розглядаються особливості реалізації конвеєрних помножувачів на FPGA. Важливу роль при розробці конвеєрних пристроїв на FPGA грає оптимізація як по апаратним витратам, так і за швидкодією. Дані питання розглядаються в літературі [5] і [18].
3.2 Огляд національних джерел
Незважаючи на незначну поширеність даної технології в Україні та Росії ведуться дослідження в даній сфері. Так наприклад в [13] розглядається реалізація пристроїв цифрової обробки сигналів на FPGA. Зокрема в [12] наводиться приклад реалізації швидкого перетворення Фур'є, а в [14] - варіант дискретного косинусного перетворення. Викликає інтерес реалізації на FPGA інших пристроїв, як наприклад, цифровий синтезатор частоти [16]. Однією з найважливіших сфер застосування конвеєризації є побудова конвеєрних мікропроцесорів [15].
Крім наукових статей, з даної теми також захищаються кандидатські та докторські дисертації. Методи і засоби створення ефективного паралельно-конвеєрного програмного забезпечення обчислювальних систем, побудованих на основі ПЛІС-технології розглядаються в [20]. В [21] розглядається розробка методів моделювання паралельно-конвеєрних нейромережевих структур для високошвидкісної цифрової обробки сигналів. Розробка і дослідження методів вирішення завдання високого дозволу на обчислювальних системах зі змінною розрядністю описана в [22]. Дослідження і розробка методів поведінкового синтезу конвеєрних схем для цифрової обробки відеозображень наводиться в [23]. В [24] проводилося дослідження методів реалізації алгоритмів обробки великих потоків даних за рахунок конвеєрного розпаралелювання. В [25] розглядається розпаралелювання алгоритмів комп'ютерної алгебри на основі арифметики поліномів.
3.3 Огляд локальних джерел
У Донецькому національному технічному університеті також ведуться роботи в області FPGA технологій. Так в [27] розглядаються методи реалізації апаратного сортування, а в [28] - побудова на FPGA систем зв'язку. В [29] продовжується розгляд реалізації цифрою обробки сигналів на FPGA. Зокрема в [32] розглядається реалізація MPEG2 відеопроцесорів. Розробка мережевих криптографічних систем розглядається в [31]. Розробка багатопроцесорних систем рішення звичайних диференціальних рівнянь на базі FPGA-технологій розглянута в [30], а автоматизація проектування швидкодіючих цифрових пристроїв на FPGA - в [26].
4. Конвеєрні пристрої на FPGA
В якості найпростішого прикладу конвеєризації на ПЛІС розглянемо побудова арифметичного беззнакового суматора. В якості результатів реалізації для цього і всіх наступних пристроїв використовуються результати синтезу середовища Xilinx 12.4 для сімейства мікросхем Virtex6 [2]. Для того щоб зробити висновок про ефективність конвеєрної схеми, спочатку синтезуємо типову схему комбінаційного суматора з вхідним і вихідним переносами. Схема такого суматора приведена на рисунку 4.

Рисунок 4 - Схема найпростішого суматора
Слід зазначити, що при синтезі даного суматора середовище розробки використовує оптимізований алгоритм підсумовування, що дозволяє збільшити швидкодію при використанні більшого числа входів LUT. Для оцінки ефективності схеми складемо таблицю залежності швидкодії від розрядності суматора. Результати наведені в таблиці 1.
| Розрядність суматора, біт | Час спрацьовування, ps | Ставлення ps/біт |
| 32 | 1029 | 32 |
| 64 | 1573 | 25 |
| 128 | 2661 | 21 |
| 256 | 4837 | 19 |
| 512 | 9189 | 18 |
У даній таблиці не враховувалася затримка поширення сигналу між входами/виходами схеми і ніжками мікросхеми. Як видно з таблиці, питома затримка сигналу на біт з ростом розрядності скорочується. При цьому витрати LUT дорівнюють розрядності суматора. Конвеєрний варіант даного суматора буде мати вигляд, показаний на рисунку 5.
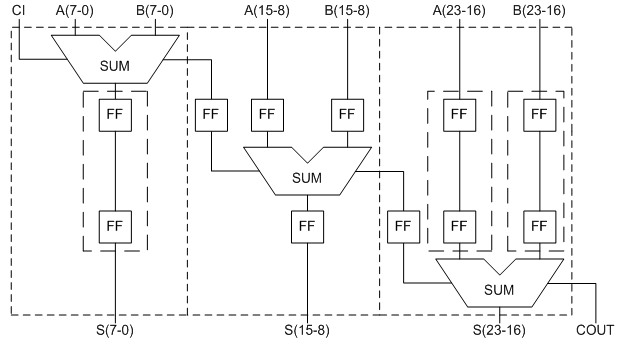
Рисунок 5 - Схема конвеєрного суматора
На перший погляд схема значно ускладнилася. Тепер, для реалізації суматора на n розрядів при m ступенях конвеєра необхідно ті ж n LUT і додаткові регістри. Розрахуємо необхідну кількість тригерів. Для реалізації ланцюжка регістрів для зберігання операндів необхідно 2n/m * (0 +1 +2 + ... + (m-1)) = n * (m-1) тригерів. Для реалізації ланцюжка регістрів для зберігання результату необхідно n/m * ((m-1) + (m-2) + ... +1 +0) = n * (m-1)/2 тригерів. Для реалізації ланцюжка регістрів для зберігання перенесення необхідно m-1 тригерів. Сумарна кількість необхідних для реалізації тригерів одно (M-1) * (3/2 * n +1). Розглянута схема є типовою схемою конвейеризації і замість суматорів може бути використана будь-яка комбінаційна схема. З отриманої формули можна зробити висновок, що результуючі витрати тригерів значніше залежать від розрядності суматора, ніж від кількості ступенів конвеєра. Реалізуємо розглянуту схему в структурному стилі, на основі параметризованих компонентів, у вигляді суматора з ланцюжками регістрів на вході і виході [3]. Слід зазначити, що при довжині ланцюжка 2 і більше, засіб синтезу автоматично реалізує ланцюжок на основі вбудованого сдвигового регістра, що значно зменшує апаратні витрати. Також необхідно пам'ятати, що тригера, що входять до складу базової комірки також можуть бути використані в даній схемі. Результати синтезу розглянутого конвеєрного суматора в порівнянні з комбінаційною суматором наведені в таблиці 2.
| Розрядність, n | Число ступенів, m | Витрати, LUTs (комбінаційний) | Затримка, ps (комбінаційний) | Витрати, LUTs (конвеєрний) | Затримка, ps (конвеєрний) |
| 512 | 2 | 512 | 9189 | 513 | 5151 |
| 4 | 1539 | 2975 | |||
| 8 | 1799 | 1887 | |||
| 256 | 2 | 256 | 4837 | 257 | 2975 |
| 4 | 771 | 1887 | |||
| 8 | 903 | 1343 | |||
| 16 | 975 | 1071 | |||
| 32 | 1023 | 935 |
З отриманої таблиці можна зробити деякі важливі висновки. При двох ступенях конвеєра, регістри практично повністю реалізуються на тих самих логічних осередках, на яких реалізовано суматори. Потім використання ресурсів різко зростає, а при кількості ступенів 8, 16, 32 змінюється незначно, це пов'язано з використанням вбудованих зсувних регістрів. При синтезі арифметичних пристроїв на FPGA, засіб синтезу дозволяє оптимізувати реалізацію операцій підсумовування і віднімання та виконати їх на одних і тих же фізичних апаратних ресурсах. При цьому витрати на реалізацію схеми знижуються. Синтезуємо пристрій, схема якого зображена на рисунку 6.
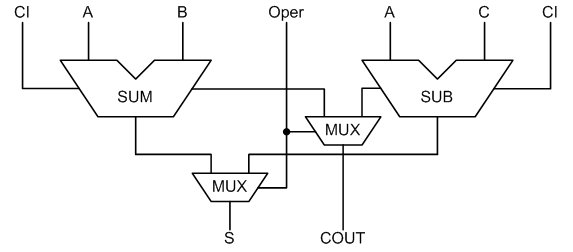
Рисунок 6 - Схема об’єднаного суматора/віднімача"
Маємо схему, яка в залежності від сигналу Oper виконує або складання сигналів A і B, або віднімання сигналів A і C. Схеми мають вхідний і вихідний перенос. Результати VHDL синтезу даного пристрою в порівнянні з розглянутим вище комбінаційною суматором наведені в таблиці 3.
| Розрядність, біт | Час спрацьовування SUM, ps | Час спрацьовування SUM/SUB ps |
| 32 | 1029 | 1046 |
| 64 | 1573 | 1590 |
| 127 | 2644 | 2661 |
Витрати на побудову комбінованої арифметичної схеми на 2 LUT більше звичайного суматора і ця різниця не залежить від розрядності. Невелику різницю у часі спрацьовування можна пояснити двома додатковими елементами у схемі. З усього вище сказаного можна зробити висновок, що подібна оптимізація не позначається на швидкодії. Слід також зазначити, що при синтезі подібного пристрої на розрядність 128 і більше, засіб синтезу витрачало в 3 рази більше ресурсов.Окрім операцій додавання і віднімання, на FPGA можлива також реалізація пристроїв, що виконують множення і ділення. Схема комбінаційного помножувача приведена на рисунку 7.

Рисунок 7 - Схема комбінаційного помножувача
Принцип роботи схеми заснований на послідовному аналізі біт першого множника. Якщо біт, дорівнює одиниці, то до часткового результату множення додається другий множник. Результати синтезу даної схеми наведені в таблиці 4.
| Розрядність, біт | Час спрацьовування, ps | Витрати, LUTs |
| 8 | 7750 | 64 |
| 16 | 16144 | 256 |
| 32 | 32824 | 1024 |
З таблиці можна зробити висновок, що швидкодія даної схеми лінійно пропорційна розрядності помножувача, а витрати дорівнюють квадрату розрядності. Час спрацювання і продуктивність даної схеми можна значно збільшити, якщо забезпечити конвейеризації обчислень [4], [7]. Схема удосконаленого пристрою показана на рисунку 8.
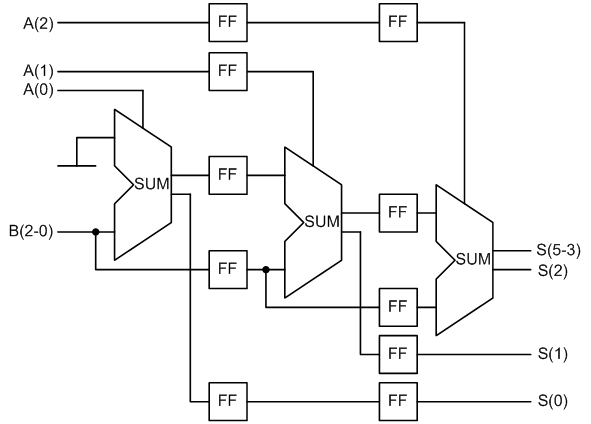
Рисунок 8 - Схема конвеєрного помножувача
Розрахуємо додаткові витрати, пов'язані з конвеєризацією для n-розрядного помножувача. Для реалізації тригерів ланцюгів управління суматорами необхідно наступна кількість тригерів: (0 +1 + ... + (n-1)) = n * (n-1)/2. Реалізація ланцюгів результату вимагає ((n-1) + (n-2) + ... +1 +0) = n * (n-1)/2 тригерів. Для реалізації ланцюгів другого множника і часткового твору необхідно 2 * n * (n-1). Разом сумарні витрати 3 * n * (n-1) = 3n2-3n. З даної формули можна зробити висновок, що додаткові витрати на конвейеризації, так само як і основні витрати на побудову суматорів, ростуть пропорційно квадрату розрядності помножувача. Синтезуємо розглянуту схему, результати синтезу наведені в таблиці 5.
| Розрядність, n | Комбінаційний | Конвеєрний | Приріст апаратних затрат | Приріст апаратних затрат | ||
| Швидкодія, ps | Витрати, LUTs | Швидкодія, ps | Витрати, LUTs | |||
| 8 | 7755 | 64 | 1444 | 90 | 40,6% | 5,37 |
| 12 | 11965 | 144 | 1512 | 186 | 29,2% | 7,91 |
| 16 | 16144 | 256 | 1580 | 314 | 22,7% | 10,22 |
| 24 | 24484 | 576 | 1754 | 666 | 15,6% | 13,96 |
| 32 | 32824 | 1024 | 1896 | 1146 | 11,9% | 17,31 |
З отриманої таблиці можна зробити висновок, що швидкодія отриманої схеми незначно залежить від розрядності, а додаткові апаратні витрати на конвейеризацію з ростом розрядності прагнуть до нуля. Це можна пояснити використанням в схемі елементів, що входять до складу логічної комірки (тригерів і регістрів зсуву).
Висновки
У даній роботі були розглянуті основні принципи конвеєризації та їх використання. Слід зазначити, що використання даного методу обробки можливо не тільки при побудові конвеєрної обробки команд в мікропроцесорних пристроях, а й при розробці практично будь-яких пристроїв. Головним завданням, при реалізації конвеєрного варіанта пристрою, є забезпечення незалежності роботи поточного ступеня конвеєра на даному такті від результатів роботи попереднього ступеня на цьому ж такті. Для реалізації цієї вимоги найчастіше можна використовувати регістрові схеми. Були розроблені конвеєрні схеми суматора і помножувача, розраховані додаткові витрати регістрових елементів при реалізації цих схем в базисі дискретних елементів. На рисунках 9, 10, 11, 12 наведені графіки залежностей апаратних витрат і швидкодії розроблених конвеєрних схем від числа ступенів конвеєра. За ними можна зробити висновок про найбільш ефективну довжину конвеєра.
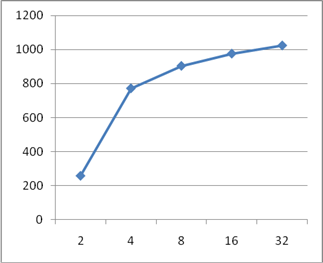
Рисунок 9 - Графік залежності апаратних витрат на конвеєрний суматор від кількості ступенів конвеєра
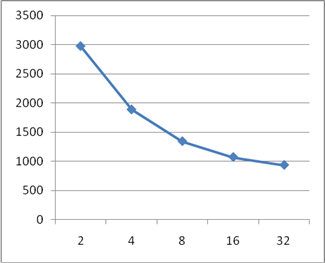
Рисунок 10 - Графік залежності затримки конвеєрного суматора від кількості ступенів конвеєра
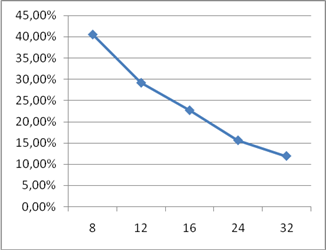
Рисунок 11 - Графік залежності приросту апаратних витрат на реалізацію конвеєрного помножувача від кількості ступенів конвеєра
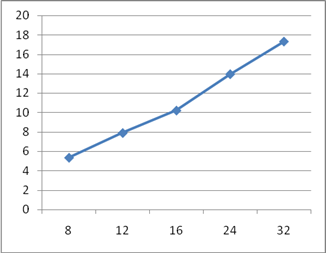
Рисунок 12 - Графік залежності приросту швидкодії конвеєрного помножувача від кількості ступенів конвеєра
Також, в роботі були розглянуті особливості структури логічної осередку FPGA та її ефективного використання для побудови пристроїв з конвеєрної архітектурою [5]. В результаті реалізації розроблених раніше схем на FPGA були отримані їх синтезовані VHDL-опису. На основі результатів синтезу можна зробити наступні висновки:
- Зростання швидкодії схеми при конвейеризації залежить від числа ступенів конвеєра й співвідношення швидкодія комбінаційної і реєстрової частини і прагнути до значення t/m, де t - час роботи вихідної схеми, m - число ступенів конвеєра. Тобто, конвеєризація пристроїв з великим часом спрацьовування ступені, дасть більший приріст за швидкодією;
- Приріст апаратних витрат на реалізацію конвеєрного методу обробки залежить від співвідношення витрат на реалізацію комбінаційної частини і реєстрової частини і прагнути до нуля, тобто, при конвейеризації пристроїв з великими витратами LUT на реалізацію ступені конвеєра, додаткові апаратні витрати знижуються, так як використовуються тригера з логічних комірок комбінаційної частини;
- конвейеризація операції підсумовування вимагає значно більших витрат запам'ятовуючих елементів і дає менший приріст за швидкодією в порівнянні з конвеєрним варіантом множення.
Розглянуті у цій роботі принципи можуть бути також використані при побудові більш складних пристроїв у наступних напрямках:
- Кодування;
- Шифрування;
- Апаратне сортування і архівація;
- Цифрова обробка сигналів;
При написанні даного автореферату магістерська робота ще не закінчена. Остаточне завершення: грудень 2012. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- Virtex-6 FPGA Configurable Logic Block. User Guide. UG364(v1.2) February 3, 2012. – p. 50
- Virtex-6 Family Overview. Product Specification. DS150(v2.4) January 19, 2012. – p. 11
- XST User Guide for Virtex-6, Spartan-6, and 7 Series Devices. UG687(v13.4) January 18,2012. – p. 489
- Alex Panato, Sandro Silva, Flavio Wagner, Marcelo Johan, Ricardo Reis, Sergio Bampi. Design of Very Deep Pipelined Multiplier for FPGAs. Proceedings of the conference on Design, automation and test in Europe - Volume 3. IEEE Computer Society Washington, DC, USA ©2004. – p. 6
- Oswaldo Cadenas, Graham Megson. Journal of System Architecture 50 (2004) 687-696. A clocking technique for FPGA pipelined designs. – p. 10
- Keshab K. Parhi. VLSI Digita Signal Processing Systems: Design and Implementation. John Wiley & Sons, 1999. Chapter 3: Pipelining and Parallel Processing. – p. 32
- Mathew Wojko. Pipelined Multipliers and FPGA Architecture. FPL '99 Proceedings of the 9th International Workshop on Field-Programmable Logic and Applications. Springer-Verlag London, UK ©1999. – p. 7
- Stratix V Device Handbook. – p. 580
- Quartus II Handbook Version 11.1. – p. 1686
- Sounak Samanta B.E. III Yr, Electronics & Communication Engg, Sardar Vallabhbhai National Institute of Technology, Surat. FPGA Implementation of AES Encryption and Decryption [Электронный ресурс]. – Режим доступа: http://www.design-reuse.com/articles/13981/fpga-implementation-of-aes-encryption-and-decryption.html
- Bin Zhou, Yingning Peng and David Hwang. Pipeline FFT Architectures Optimized for FPGAs [Электронный ресурс]. – Режим доступа: http://www.hindawi.com/journals/ijrc/2009/219140/
- Мистюков В., Володин П., Капитанов В.. Однокристальная реализация алгоритма БПФ на ПЛИС фирмы Xilinx [Электронный ресурс]. – Режим доступа: http://www.compitech.ru/html.cgi/arhiv/00_05/stat_70.htm
- Стешенко В.Б. ПЛИС фирмы Altera: проектирование устройств обработки сигналов. [Электронный ресурс]. – Режим доступа: http://www.dsol.ru/stud/book7/chapter7/page7_01.html
- Сергієнко А.М., Лепеха В.Л., Лесик Т.М. Спецпроцесори для двовимірного дискретного косинусного перетворення. Журнал “Вісник” НТУ КПИ. “Інформатика, управління і обчислювальна техника”. Випуск №47. Київ “Вік+”. – с. 230–233
- Строгонов А. Проектирование микропроцессорных ядер с конвейерной архитектурой для реализации в базисе ПЛИС фирмы Altera. Журнал Компоненты и технологии. №8, 2009 г. – с. 86–89
- Стахів Р. І. Цифрові синтезатори частоти на основі число-імпульсних перетворювачів кодів. Поліграфічний центр Видавництва Національного університету "Львівська політехніка" 79000, м. Львів, вул. Ф. Колесси, 2. – с. 24
- Shousheng He and Mats Torkelson. Department of Applied Electronics, Lund University S-22100 Lund, SWEDEN. A New Approach to Pipeline FFT Processor. – p. 5
- Ling Zhuo, Student Member, IEEE, Gerald R. Morris, and Viktor K. Prasanna, Fellow, IEEE. High-Performance Reduction Circuits Using Deeply Pipelined Operators on FPGAs. – p. 1377–1392.
- Brian J. Shelburne. Dept of Math and Comp Sci Wittenberg University. Zuse's Z3 Square Root Algorithm. – p. 11
- Иванов А. И. Методы и средства создания эффективного параллельно-конвейерного программного обеспечения вычислительных систем, построенных на основе плис-технологии [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/metody-i-sredstva-sozdaniya-effektivnogo-parallelno-konveiernogo-programmnogo-obespecheniya-
- Стрекалов Ю. А. Разработка методов моделирования параллельно-конвейерных нейросетевых структур для высокоскоростной цифровой обработки сигналов [Электронный ресурс]. – Режим доступа: http://www.lib.ua-ru.net/diss/cont/199480.html
- Гильванов М. Ф. Разработка и исследование методов решения задачи высокого разрешения на вычислительных системах с переменной разрядностью [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/razrabotka-i-issledovanie-metodov-resheniya-zadachi-vysokogo-razresheniya-na-vychislitelnykh
- Анисимов И. Ю. Исследование и разработка методов поведенческого синтеза конвейерных схем для цифровой обработки видеоизображений [Электронный ресурс]. – Режим доступа: http://www.dissland.com/catalog/issledovanie_i_razrabotka_metodov_povedencheskogo_sinteza_konveyernih_shem_dlya_tsifrovoy_obrabotki_.html
- Лысаков К. Ф. Исследование методов реализации алгоритмов обработки больших потоков данных за счет конвейерного распараллеливания [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/issledovanie-metodov-realizatsii-algoritmov-obrabotki-bolshikh-potokov-dannykh-za-schet-kon-0
- Валеев Ю. Д. Система распараллеливания алгоритмов компьютерной алгебры на основе арифметики полиномов [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/sistema-rasparallelivaniya-algoritmov-kompyuternoi-algebry-na-osnove-arifmetiki-polinomov
- Кузьменко В. О.. Автоматизация проектирования быстродействующих цифровых устройств на FPGA [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2008/fvti/kuzmenko/diss/index.htm
- Садыкбаев А. В. Разработка реконфигурированной системы для реализации сортировщиков [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2009/fvti/sadykbaiev/diss/index.htm
- Зинченко Е. Ю. Разработка и исследование структур устройства передачи данных на базе HDL и FPGA технологий [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2011/fknt/zinchenko/diss/index.htm
- Войтов Г. В. Анализ аналоговых сигналов на базе ЦОС в FPGA [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2009/fvti/voitovg/diss/index.htm
- Дружинин А. И. Разработка многопроцессорных систем решения обыкновенных дифференциальных уравнений на базе FPGA-технологий [Электронный ресурс]. – Режим доступа: http://www.masters.donntu.ru/2006/fvti/druzhynin/diss/index.htm
- Ульянов Ю. В. Разработка структуры сетевых криптографических устройств на снове HDL и FPGA технологий [Электронный ресурс]. – Режим доступа: http://www.masters.donntu.ru/2006/fvti/ulyanov/diss/referat.htm
- Муха Е. М. Исследование реализаций MPEG2 видеопроцессоров на FPGA и PRUS [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2005/fvti/mukha/diss/index.htm