
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Конвейерные устройства на FPGA
- Выводы
- Список источников
Введение
В настоящее время происходит бурное развитие вычислительной техники. Но с ростом производительности вычислительных средств растут и вычислительная сложность алгоритмов, а также требования по быстродействию со стороны пользователя. Реализовать обработку данных на данный момент можно на основе двух базовых аппаратных технологий: микропроцессорной технике и программируемых логических интегральных схемах (ПЛИС). Обе технологии имеют как преимущества, так и недостатки. К преимуществам микропроцессоров можно отнести простоту разработки устройств на их базе, которая, в сущности, сводиться к написанию программного обеспечения. Всё большую популярность приобретает проектирование устройств на базе последней технологии, а именно FPGA (field-programmable gate array). При этом затраты на разработку и сложность значительно возрастает, так как требуется специализированная среда разработки и отладочная плата.Почему же FPGA технология более привлекательна по сравнению с микропроцессорной технологией? Регулярная структура ПЛИС позволяет строить на основе одной микросхемы комплексы из нескольких устройств и даже несколько независимых устройств. Основным преимуществом ПЛИС является возможность реализации на их базе принципов параллелизма и конвейеризации [6]. Первый принцип заключается в возможности одновременного выполнения нескольких однотипных действий и реализуется в основном в виде дублирования устройств. Второй принцип позволяет разбить выполнение сложной задачи на ряд простых последовательных действий с одновременным совмещением их выполнения во времени. Данный принцип давно зарекомендовал себя и используется не только в вычислительной технике, но и в промышленности. Рассмотрим принцип конвейеризации на основе работы конвейера команд процессора, схема которого изображена на рисунке 1.
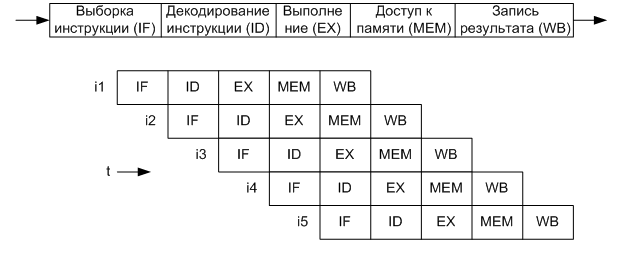
Рисунок 1 – Схема конвейера команд
Рассматриваемый конвейер состоит из пяти ступеней, каждая из которых выполняет определённое действие над командой. После завершения обработки текущей команды на текущем этапе, выполнение команды переходит на следующий этап, а на данный этап обработки поступает следующая команда. Допустим, что каждая ступень конвейера выполняет обработку за один такт, тогда после загрузки конвейера (5 тактов), выполнение команд будет производиться с периодом в один такт. Считая, что обычное (не конвейерное) выполнение команды занимает 5 тактов, то есть, имеем ускорение выполнения команд в 5 раз. Имеются, конечно же, ограничения и недостатки данного метода, но все они также решаемы в той или иной степени. Описанный принцип можно использовать и для ускорения выполнения других алгоритмов. Анимация работы конвейера команд процессора приведена на рисунке 2.
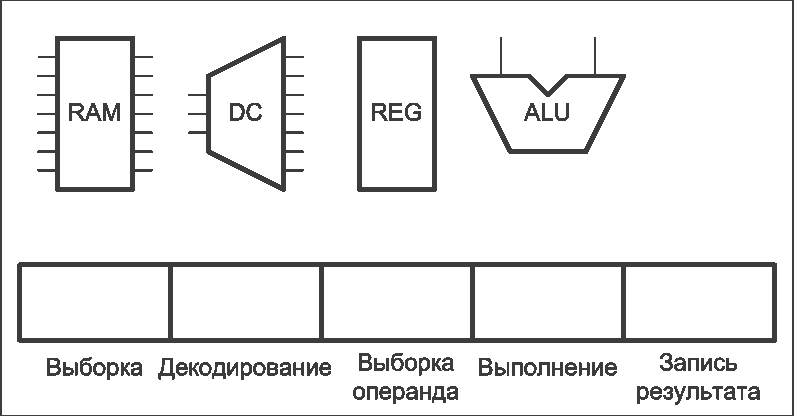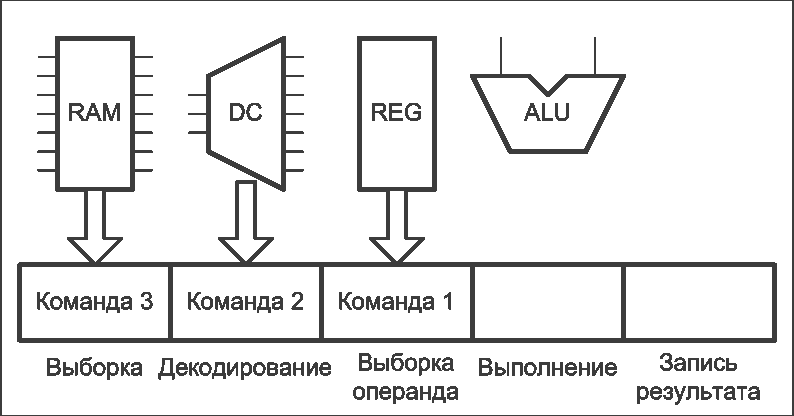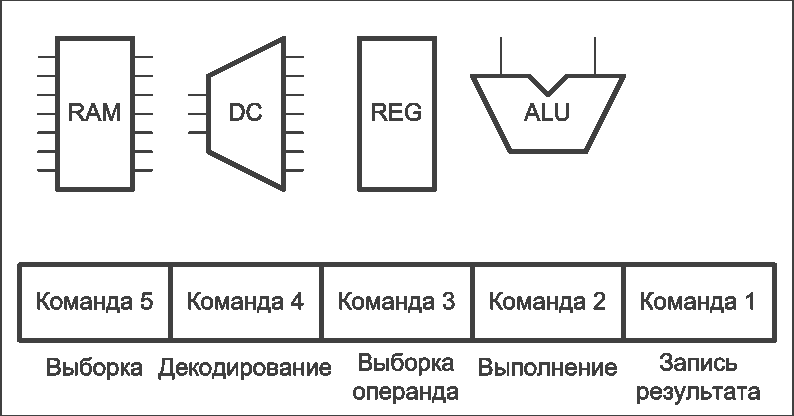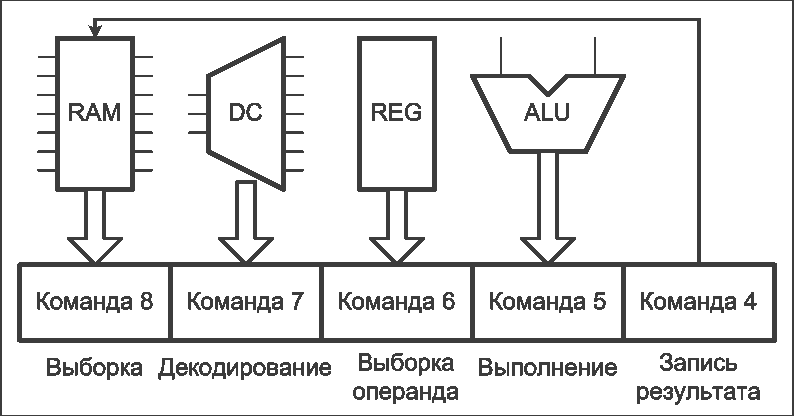
Рисунок 2 – Работа конвейера команд процессора (анимация: 16 кадров, 5 циклов повторения, 127 килобайт) (RAM – оперативная память, DC – дешифратор команд, REG – блок регистров, ALU – арифметико-логическое устройство)
1. Актуальность темы
Реализация конвейерного принципа обработки данных на FPGA интересна и актуальна тем, что структура базового логического элемента данного типа ПЛИС очень хорошо подходит для реализации устройств именно такого типа [1]. Для уяснения ситуации рассмотрим упрощённую структуру базовой логической ячейки, которая приведена на рисунке 3.
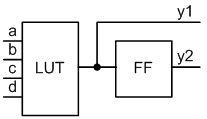
Рисунок 3 – Упрощённая структура базовой логической ячейки FPGA
Рассматриваемая ячейка состоит из двух элементов: комбинационного функционального генератора 4 входа на 1 выход и триггерного элемента. При использовании только комбинационной части, триггерная часть не может быть использована в каких либо других цепях, поэтому использование обеих частей ячейки не приводит к дополнительным затратам оборудования, хотя вносит значительную задержку в схему. Например, для FPGA Virtex6 задержка сигнала на LUT в виде схемы AND на 4 входа составляет 61 ps., задержкой сигнала между LUT и FF можно пренебречь, время срабатывания FF составило 317 ps. Разница в 5 раз весьма значительна, но при таких абсолютных значениях задержек элементов резко встаёт проблема задержек линий связи между ними. Например, для той же микросхемы, распространение сигнала от ножек кристалла до LUT составило 566 ps., а время распространения сигнала от выходов схемы до ножек кристалла составило порядка 344 ps. Из этого можно сделать вывод, что в некоторых случаях использование FF не вносит значительную задержку и может быть использован между комбинационными схемами для реализации конвейеризации.
2. Цель и задачи исследования, планируемые результаты
Основной целью исследования является разработка эффективной методики построения устройств конвейерного типа на FPGA микросхемах. Для достижения поставленной цели необходимо решить ряд задач:
- Рассмотреть внутреннюю архитектуру FPGA микросхемы;
- Реализовать конвейеризацию базовой схемы суммирования и схемы умножения на встроенных умножителях;
- Построить конвейерные варианты комбинационного умножителя и делителя;
- Рассмотреть реализацию конвейерной обработки в более сложных схемах (кодеры-декодеры, шифраторы-дешифраторы, схемы аппаратной сортировки, схемы аппаратной архивации и разархивирования, схемы цифровой обработки сигналов и их использование в устройствах компрессии и декомпрессии звуковой, видео- и графической информации);
- Разработать методику синтеза эффективных конвейерных устройств на базе FPGA;
- Синтезировать одно из рассмотренных выше устройств и протестировать на отладочной плате;
- Сделать выводы об эффективности разработанной методики;
В качестве методики планируется разработать конкретные рекомендации по поведенческому и структурному, синтезируемому VHDL-описанию, как примитивных функциональных блоков, так и законченных устройств с учётом архитектурных особенностей FPGA-технологии (структура базовой логической ячейки, встроенные функциональные узлы, коммутационная матрица и т. д.).
3. Обзор исследований и разработок
FPGA технология является быстроразвивающейся, поэтому с ней работает значительное количество людей. Однако, в связи с тем, что на FPGA возможна реализация практически любых устройств, а внутренняя структура кристалла постоянно совершенствуется, то совершенствуются и методы реализации отдельных модулей. Именно поэтому необходимо постоянно следить за развитием, как аппаратной, так и методологической базы. В Украине FPGA еще не получила должного развития, однако тенденции к этому имеются.
3.1 Обзор международных источников
Прежде чем переходить непосредственно к реализации конкретных устройств на VHDL, необходимо ознакомится с внутренней структурой микросхем данного типа, чтобы результаты синтеза были более-менее предсказуемыми. Крупнейшими производителями FPGA-микросхем являются фирмы Xilinx и Altera, техническую документацию по микросхемам этих и других фирм можно посмотреть на их официальных сайтах. Документация по общей структуре микросхем Virtex6 от Xilinx приведена в [2], а по структуре комбинационного логического блока в [1]. А аналогичная литература по Stratix V от Altera приведена в [8]. Кроме понимания структуры аппаратных средств, необходимо также знать закономерности преобразования VHDL конструкция в те или иные аппаратные примитивы для конкретного средства и целевой платформы. Данная информация имеется в источниках [3] и [9] соответственно.
После рассмотрения приведенной выше литературы можно переходить к изучению конкретных прикладных методов и схем. Одним из перспективных направлений использования FPGA микросхем является построение на их базе устройств цифровой обработке сигналов. Хорошим источником по данной теме является [6]. В третьем разделе данной книги приведены методики распараллеливания и конвейеризации алгоритмов цифровой обработки сигналов, что особенно важно при их реализации на FPGA. В [11] и [17] исследована реализация быстрого преобразования Фурье. Также возможна реализация на данном типе программируемых логических схем устройств шифрования и дешифрования. Пример реализации криптографического алгоритма приведен в [10]. Одним из применений микросхем FPGA является реализация на их базе арифметических устройств. В [19] рассмотрен пример реализации алгоритма нахождения квадратного корня. В [4] и [7] рассматриваются особенности реализации конвейерных умножителей на FPGA. Важную роль при разработке конвейерных устройств на FPGA играет оптимизация как по аппаратным затратам, так и по быстродействию. Данные вопросы рассматриваются в литературе [5] и [18].
3.2 Обзор национальных источников
Несмотря на незначительную распространённость рассматриваемой технологии в Украине и России ведутся исследования в данной сфере. Так например в [13] рассматривается реализация устройств цифровой обработки сигналов на FPGA. В частности в [12] приводится пример реализации быстрого преобразования Фурье, а в [14] – вариант дискретного косинусного преобразования. Вызывает интерес реализации на FPGA и других устройств, как например, цифровой синтезатор частоты [16]. Одной из важнейших сфер применения конвейеризации является построение конвейерных микропроцессоров [15].
Кроме научных статей, по данной теме также защищаются кандидатские и докторские диссертации. Методы и средства создания эффективного параллельно-конвейерного программного обеспечения вычислительных систем, построенных на основе плис-технологии рассматриваются в [20]. В [21] рассматривается разработка методов моделирования параллельно-конвейерных нейросетевых структур для высокоскоростной цифровой обработки сигналов. Разработка и исследование методов решения задачи высокого разрешения на вычислительных системах с переменной разрядностью описана в [22]. Исследование и разработка методов поведенческого синтеза конвейерных схем для цифровой обработки видеоизображений приводится в [23]. В [24] проводилось исследование методов реализации алгоритмов обработки больших потоков данных за счет конвейерного распараллеливания. В [25] рассматривается распараллеливание алгоритмов компьютерной алгебры на основе арифметики полиномов.
3.3 Обзор локальных источников
В Донецком национальном техническом университете также ведутся работы в области FPGA технологий. Так в [27] рассматриваются методы реализации аппаратной сортировки, а в [28] – построение на FPGA систем связи. В [29] продолжается рассмотрение реализации цифрой обработки сигналов на FPGA. В частности в [32] рассматривается реализация MPEG2 видеопроцессоров. Разработка сетевых криптографических систем рассматривается в [31]. Разработка многопроцессорных систем решения обыкновенных дифференциальных уравнений на базе FPGA-технологий рассмотрена в [30], а Автоматизация проектирования быстродействующих цифровых устройств на FPGA – в [26].
4. Конвейерные устройства на FPGA
В качестве простейшего примера конвейеризации на ПЛИС рассмотрим построение арифметического беззнакового сумматора. В качестве результатов реализации для этого и всех последующих устройств используются результаты синтеза среды Xilinx 12.4 для семейства микросхем Virtex6 [2]. Для того чтобы сделать вывод об эффективности конвейерной схемы, сначала синтезируем типовую схему комбинационного сумматора с входным и выходным переносами. Схема такого сумматора приведена на рисунке 4.

Рисунок 4 – Схема простейшего сумматора
Следует отметить, что при синтезе данного сумматора среда разработки использует оптимизированный алгоритм суммирования, позволяющий увеличить быстродействие при использовании большего числа входов LUT. Для оценки эффективности схемы составим таблицу зависимости быстродействия от разрядности сумматора. Результаты приведены в таблице 1.
| Разрядность сумматора, бит | Время срабатывания, ps | Отношение ps/бит |
| 32 | 1029 | 32 |
| 64 | 1573 | 25 |
| 128 | 2661 | 21 |
| 256 | 4837 | 19 |
| 512 | 9189 | 18 |
В данной таблице не учитывалась задержка распространения сигнала между входами/выходами схемы и ножками микросхемы. Как видно из таблицы, удельная задержка сигнала на бит с ростом разрядности сокращается. При этом затраты LUT равны разрядности сумматора. Конвейерный вариант данного сумматора будет иметь вид, показанный на рисунке 5.
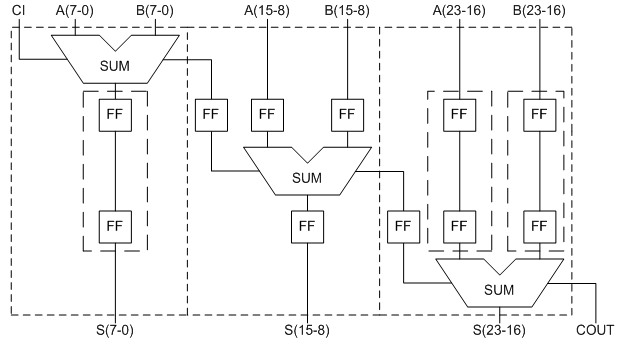
Рисунок 5 – Схема конвейерного сумматора
На первый взгляд схема значительно усложнилась. Теперь, для реализации сумматора на n разрядов при m ступенях конвейера необходимо те же n LUT и дополнительные регистры. Рассчитаем необходимое количество триггеров. Для реализации цепочки регистров для хранения операндов необходимо 2n/m*(0+1+2+…+(m-1)) = n*(m-1) триггеров. Для реализации цепочки регистров для хранения результата необходимо n/m*((m-1)+(m-2)+…+1+0) = n*(m-1)/2 триггеров. Для реализации цепочки регистров для хранения переноса необходимо m-1 триггеров. Суммарное количество необходимых для реализации триггеров равно (m-1)*(3/2*n+1). Рассмотренная схема является типовой схемой конвейеризации и вместо сумматоров может быть использована любая комбинационная схема. Из полученной формулы можно сделать вывод, что результирующие затраты триггеров значительнее зависят от разрядности сумматора, чем от количества ступеней конвейера. Реализуем рассмотренную схему в структурном стиле, на основе параметризированных компонентов, в виде сумматора с цепочками регистров на входе и выходе [3]. Следует отметить, что при длине цепочки 2 и более, средство синтеза автоматически реализует цепочку на основе встроенного сдвигового регистра, что значительно уменьшает аппаратные затраты. Также необходимо помнить, что триггера, входящие в состав базовой ячейки также могут быть использованы в данной схеме. Результаты синтеза рассмотренного конвейерного сумматора в сравнении с комбинационным сумматором приведены в таблице 2.
| Разрядность, n | Число ступеней, m | Затраты, LUTs (комбинационный) | Задержка, ps (комбинационный) | Затраты, LUTs (конвейерный) | Задержка, ps (конвейерный) |
| 512 | 2 | 512 | 9189 | 513 | 5151 |
| 4 | 1539 | 2975 | |||
| 8 | 1799 | 1887 | |||
| 256 | 2 | 256 | 4837 | 257 | 2975 |
| 4 | 771 | 1887 | |||
| 8 | 903 | 1343 | |||
| 16 | 975 | 1071 | |||
| 32 | 1023 | 935 |
Из полученной таблицы можно сделать некоторые важные выводы. При двух ступенях конвейера, регистры практически полностью реализуются на тех же логических ячейках, на которых реализованы сумматоры. Затем использование ресурсов резко возрастает, а при количестве ступеней 8, 16, 32 изменяется незначительно, это связано с использованием встроенных сдвиговых регистров. При синтезе арифметических устройств на FPGA, средство синтеза позволяет оптимизировать реализацию операций суммирования и вычитания и выполнить их на одних и тех же физических аппаратных ресурсах. При этом затраты на реализацию схемы снижаются. Синтезируем устройство, схема которого изображена на рисунке 6.
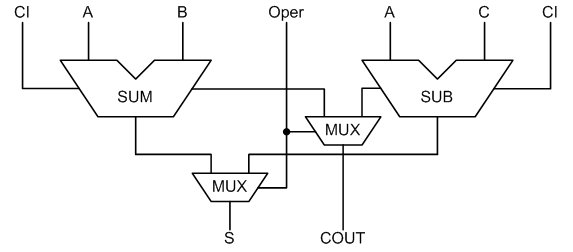
Рисунок 6 – Схема совмещённого сумматора/вычитателя
Имеем схему, которая в зависимости от сигнала Oper выполняет либо сложение сигналов A и B, либо вычитание сигналов A и C. Схемы имеют входной и выходной перенос. Результаты VHDL синтеза данного устройства в сравнении с рассмотренным выше комбинационным сумматором приведены в таблице 3.
| Разрядность, бит | Время срабатывания SUM, ps | Время срабатывания SUM/SUB ps |
| 32 | 1029 | 1046 |
| 64 | 1573 | 1590 |
| 127 | 2644 | 2661 |
Затраты на построение комбинированной арифметической схемы на 2 LUT больше обычного сумматора и эта разница не зависит от разрядности. Небольшую разницу во времени срабатывания можно объяснить двумя дополнительными элементами в схеме. Из всего выше сказанного можно сделать вывод, что подобная оптимизация не сказывается на быстродействии. Следует также отметить, что при синтезе подобного устройства на разрядность 128 и более, средство синтеза расходовало в 3 раза больше ресурсов.Помимо операций сложения и вычитания, на FPGA возможна также реализация устройств, выполняющих умножение и деление. Схема комбинационного умножителя приведена на рисунке 7.

Рисунок 7 – Схема комбинационного умножителя
Принцип работы схемы основан на последовательном анализе бит первого множителя. Если бит, равен единице, то к частичному произведению прибавляется второй множитель. Результаты синтеза данной схемы приведены в таблице 4.
| Разрядность, бит | Время срабатывания, ps | Затраты, LUTs |
| 8 | 7750 | 64 |
| 16 | 16144 | 256 |
| 32 | 32824 | 1024 |
Из таблицы можно сделать вывод, что быстродействие данной схемы линейно пропорционально разрядности умножителя, а затраты равны квадрату разрядности. Время срабатывания и производительность данной схемы можно значительно увеличить, если обеспечить конвейеризацию вычислений [4],[7]. Схема усовершенствованного устройства показана на рисунке 8.
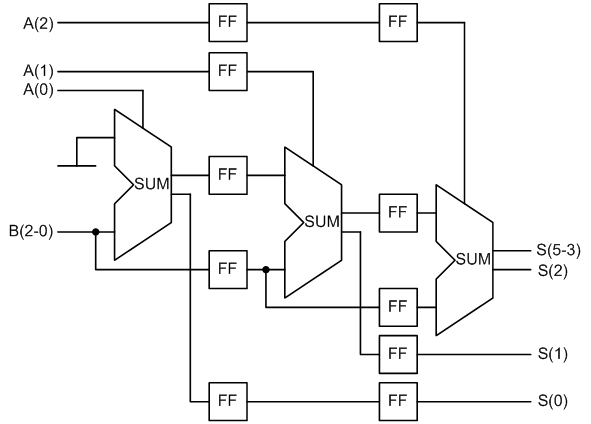
Рисунок 8 – Схема конвейерного умножителя
Рассчитаем дополнительные затраты, связанные с конвейеризацией для n-разрядного умножителя. Для реализации цепочек триггеров цепей управления сумматорами необходимо следующее количество триггеров: (0+1+…+(n-1))=n*(n-1)/2. Реализация цепей произведения требует ((n-1)+(n-2)+…+1+0)=n*(n-1)/2 триггеров. Для реализации цепей второго множителя и частичного произведения необходимо 2*n*(n-1). Итого суммарные затраты 3*n*(n-1)=3n2-3n. Из данной формулы можно сделать вывод, что дополнительные затраты на конвейеризацию, так же как и основные затраты на построение сумматоров, растут пропорционально квадрату разрядности умножителя. Синтезируем рассмотренную схему, результаты синтеза приведены в таблице 5.
| Разрядность, n | Комбинационный | Конвейерный | Прирост аппаратных затрат | Прирост аппаратных затрат | ||
| Быстродействие, ps | Затраты, LUTs | Быстродействие, ps | Затраты, LUTs | |||
| 8 | 7755 | 64 | 1444 | 90 | 40,6% | 5,37 |
| 12 | 11965 | 144 | 1512 | 186 | 29,2% | 7,91 |
| 16 | 16144 | 256 | 1580 | 314 | 22,7% | 10,22 |
| 24 | 24484 | 576 | 1754 | 666 | 15,6% | 13,96 |
| 32 | 32824 | 1024 | 1896 | 1146 | 11,9% | 17,31 |
Из полученной таблицы можно сделать вывод, что быстродействие полученной схемы незначительно зависит от разрядности, а дополнительные аппаратные расходы на конвейеризацию с ростом разрядности стремятся к нулю. Это можно объяснить использованием в схеме входящих в состав логической ячейки триггеров и сдвигового регистра.
Выводы
В данной работе были рассмотрены основные принципы конвейеризации и их использование. Следует отметить, что использование данного метода обработки возможно не только при построении конвейерной обработки команд в микропроцессорных устройствах, но и при разработке практически любых устройств. Главной задачей, при реализации конвейерного варианта устройства, является обеспечение независимости работы текущей ступени конвейера на данном такте от результатов работы предыдущей ступени на этом же такте. Для реализации этого требования чаще всего можно использовать регистровые схемы. Были разработаны конвейерные схемы сумматора и умножителя, рассчитаны дополнительные затраты регистровых элементов при реализации этих схем в базисе дискретных элементов. На рисунках 9, 10, 11, 12 приведены графики зависимостей аппаратных затрат и быстродействия разработанных конвейерных схем от числа ступеней конвейера. По ним можно сделать вывод о наиболее эффективной длине конвейера.
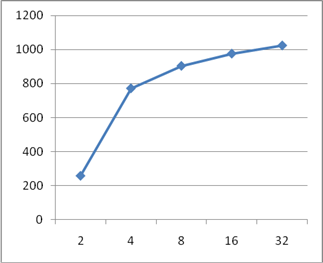
Рисунок 9 – График зависимости аппаратных затрат на конвейерный сумматор от количества ступеней конвейера
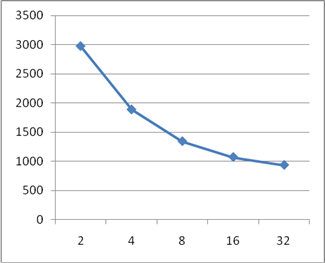
Рисунок 10 – График зависимости задержки конвейерного сумматора от количества ступеней конвейера
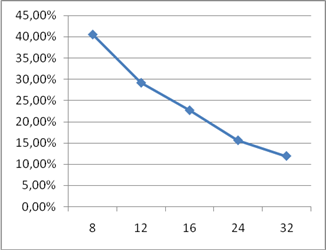
Рисунок 11 – График зависимости прироста аппаратных затрат на реализацию конвейерного умножителя от количества ступеней конвейера
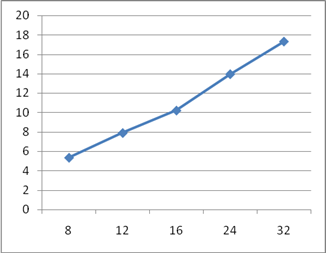
Рисунок 12 – График зависимости прироста быстродействия конвейерного умножителя от количества ступеней конвейера
Также, в работе были рассмотрены особенности структуры логической ячейки FPGA и её эффективного использования для построения устройств с конвейерной архитектурой [5]. В результате реализации разработанных ранее схем на FPGA были получены их синтезируемые VHDL-описания. На основе результатов синтеза можно сделать следующие выводы:
- Прирост быстродействия схемы при конвейеризации зависит от числа ступеней конвейера и соотношения быстродействий комбинационной и регистровой части и стремиться к значению t/m, где t – время работы исходной схемы, m – число ступеней конвейера. То есть, конвейеризация устройств с большим временем срабатывания ступени, даст больший прирост по быстродействию;
- Прирост аппаратных затрат на реализацию конвейерного метода обработки зависит от соотношения затрат на реализацию комбинационной части и регистровой части и стремиться к нулю, то есть, при конвейеризации устройств с большими затратами LUT на реализацию ступени конвейера, дополнительные аппаратные затраты снижаются, так как используются триггера из логических ячеек комбинационной части;
- Конвейеризация операции суммирования требует значительно больших затрат запоминающих элементов и даёт меньший прирост по быстродействию по сравнению с конвейерным вариантом умножения.
Рассмотренные в этой работе принципы могут быть также использованы при построении более сложных устройств в следующих направлениях:
- Кодирование;
- Шифрование;
- Аппаратная сортировка и архивация;
- Цифровая обработка сигналов;
При написании данного автореферата магистерская работа ещё не закончена. Окончательное завершение: декабрь 2012 г. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Virtex-6 FPGA Configurable Logic Block. User Guide. UG364(v1.2) February 3, 2012. – p. 50
- Virtex-6 Family Overview. Product Specification. DS150(v2.4) January 19, 2012. – p. 11
- XST User Guide for Virtex-6, Spartan-6, and 7 Series Devices. UG687(v13.4) January 18,2012. – p. 489
- Alex Panato, Sandro Silva, Flavio Wagner, Marcelo Johan, Ricardo Reis, Sergio Bampi. Design of Very Deep Pipelined Multiplier for FPGAs. Proceedings of the conference on Design, automation and test in Europe - Volume 3. IEEE Computer Society Washington, DC, USA ©2004. – p. 6
- Oswaldo Cadenas, Graham Megson. Journal of System Architecture 50 (2004) 687-696. A clocking technique for FPGA pipelined designs. – p. 10
- Keshab K. Parhi. VLSI Digita Signal Processing Systems: Design and Implementation. John Wiley & Sons, 1999. Chapter 3: Pipelining and Parallel Processing. – p. 32
- Mathew Wojko. Pipelined Multipliers and FPGA Architecture. FPL '99 Proceedings of the 9th International Workshop on Field-Programmable Logic and Applications. Springer-Verlag London, UK ©1999. – p. 7
- Stratix V Device Handbook. – p. 580
- Quartus II Handbook Version 11.1. – p. 1686
- Sounak Samanta B.E. III Yr, Electronics & Communication Engg, Sardar Vallabhbhai National Institute of Technology, Surat. FPGA Implementation of AES Encryption and Decryption [Электронный ресурс]. – Режим доступа: http://www.design-reuse.com/articles/13981/fpga-implementation-of-aes-encryption-and-decryption.html
- Bin Zhou, Yingning Peng and David Hwang. Pipeline FFT Architectures Optimized for FPGAs [Электронный ресурс]. – Режим доступа: http://www.hindawi.com/journals/ijrc/2009/219140/
- Мистюков В., Володин П., Капитанов В.. Однокристальная реализация алгоритма БПФ на ПЛИС фирмы Xilinx [Электронный ресурс]. – Режим доступа: http://www.compitech.ru/html.cgi/arhiv/00_05/stat_70.htm
- Стешенко В.Б. ПЛИС фирмы Altera: проектирование устройств обработки сигналов. [Электронный ресурс]. – Режим доступа: http://www.dsol.ru/stud/book7/chapter7/page7_01.html
- Сергієнко А.М., Лепеха В.Л., Лесик Т.М. Спецпроцесори для двовимірного дискретного косинусного перетворення. Журнал “Вісник” НТУ КПИ. “Інформатика, управління і обчислювальна техника”. Випуск №47. Київ “Вік+”. – с. 230–233
- Строгонов А. Проектирование микропроцессорных ядер с конвейерной архитектурой для реализации в базисе ПЛИС фирмы Altera. Журнал Компоненты и технологии. №8, 2009 г. – с. 86–89
- Стахів Р. І. Цифрові синтезатори частоти на основі число-імпульсних перетворювачів кодів. Поліграфічний центр Видавництва Національного університету "Львівська політехніка" 79000, м. Львів, вул. Ф. Колесси, 2. – с. 24
- Shousheng He and Mats Torkelson. Department of Applied Electronics, Lund University S-22100 Lund, SWEDEN. A New Approach to Pipeline FFT Processor. – p. 5
- Ling Zhuo, Student Member, IEEE, Gerald R. Morris, and Viktor K. Prasanna, Fellow, IEEE. High-Performance Reduction Circuits Using Deeply Pipelined Operators on FPGAs. – p. 1377–1392.
- Brian J. Shelburne. Dept of Math and Comp Sci Wittenberg University. Zuse's Z3 Square Root Algorithm. – p. 11
- Иванов А. И. Методы и средства создания эффективного параллельно-конвейерного программного обеспечения вычислительных систем, построенных на основе плис-технологии [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/metody-i-sredstva-sozdaniya-effektivnogo-parallelno-konveiernogo-programmnogo-obespecheniya-
- Стрекалов Ю. А. Разработка методов моделирования параллельно-конвейерных нейросетевых структур для высокоскоростной цифровой обработки сигналов [Электронный ресурс]. – Режим доступа: http://www.lib.ua-ru.net/diss/cont/199480.html
- Гильванов М. Ф. Разработка и исследование методов решения задачи высокого разрешения на вычислительных системах с переменной разрядностью [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/razrabotka-i-issledovanie-metodov-resheniya-zadachi-vysokogo-razresheniya-na-vychislitelnykh
- Анисимов И. Ю. Исследование и разработка методов поведенческого синтеза конвейерных схем для цифровой обработки видеоизображений [Электронный ресурс]. – Режим доступа: http://www.dissland.com/catalog/issledovanie_i_razrabotka_metodov_povedencheskogo_sinteza_konveyernih_shem_dlya_tsifrovoy_obrabotki_.html
- Лысаков К. Ф. Исследование методов реализации алгоритмов обработки больших потоков данных за счет конвейерного распараллеливания [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/issledovanie-metodov-realizatsii-algoritmov-obrabotki-bolshikh-potokov-dannykh-za-schet-kon-0
- Валеев Ю. Д. Система распараллеливания алгоритмов компьютерной алгебры на основе арифметики полиномов [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/sistema-rasparallelivaniya-algoritmov-kompyuternoi-algebry-na-osnove-arifmetiki-polinomov
- Кузьменко В. О.. Автоматизация проектирования быстродействующих цифровых устройств на FPGA [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2008/fvti/kuzmenko/diss/index.htm
- Садыкбаев А. В. Разработка реконфигурированной системы для реализации сортировщиков [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2009/fvti/sadykbaiev/diss/index.htm
- Зинченко Е. Ю. Разработка и исследование структур устройства передачи данных на базе HDL и FPGA технологий [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2011/fknt/zinchenko/diss/index.htm
- Войтов Г. В. Анализ аналоговых сигналов на базе ЦОС в FPGA [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2009/fvti/voitovg/diss/index.htm
- Дружинин А. И. Разработка многопроцессорных систем решения обыкновенных дифференциальных уравнений на базе FPGA-технологий [Электронный ресурс]. – Режим доступа: http://www.masters.donntu.ru/2006/fvti/druzhynin/diss/index.htm
- Ульянов Ю. В. Разработка структуры сетевых криптографических устройств на снове HDL и FPGA технологий [Электронный ресурс]. – Режим доступа: http://www.masters.donntu.ru/2006/fvti/ulyanov/diss/referat.htm
- Муха Е. М. Исследование реализаций MPEG2 видеопроцессоров на FPGA и PRUS [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2005/fvti/mukha/diss/index.htm