
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, научная новизна
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Способы представления предложений русского языка
- 4.1 Проблемы, возникающие при обработке текста
- 4.2 Способы синтаксического представления
- Выводы
- Список источников
Введение
Взаимодействие между лингвистикой и computer science началось еще полвека назад с возникновением теории Н. Хомского, развитием генеративизма и появлением электронно-вычислительных машин. Многие лингвистические идеи и концепции на протяжении последних десятилетий были заимствованы и воплощены в программировании, теоретической информатике и информационных системах. Наиболее яркими примерами такого заимствования могут служить базисный компонент порождающей грамматики Н. Хомского, который стал прототипом первых компиляторов искусственных языков, или выдвинутая М. Мински, исследователем в области ИИ, теория фреймов для представления реальных объектов в системах распознавания образов и естественных языков, которая сыграла свою роль как в становлении объектно-ориентированного подхода в программировании, так и в семантических исследованиях языка, а наследование и полиморфизм – фундаментальные принципы объектно-ориентированного программирования – стали применяться в проектировании лексиконов [3].
На сегодня создание полноценного лингвистического процессора (ЛП) является одной из самых актуальных задач в компьютерной лингвистике, решение которой позволило бы достичь высокого уровня формализации языковых структур в разнообразных прикладных целях: от создания систем автоматического распознавания речи до поисковых систем в Интернет [5].
Со стороны своего внутреннего устройства ЛП представляет собой многоуровневый преобразователь. В нем различаются три уровня пофразного представления текста, которые соответствуют уровням языка – морфологический, синтаксический и семантический. Каждый из уровней обслуживается соответствующим компонентом модели – массивом правил и определенным словарем. Стадия морфологического анализа является наиболее проработанным лингвистическим этапом процесса обработки естественного текста, чего нельзя сказать о синтаксическом анализе.
При разработке алгоритмов сегментационного, полного синтаксического анализа, особенно для языков с относительно свободным порядком слов, каким являются русский и украинский, существует ряд трудностей, поскольку формальные математические модели и их программные динамические реализации не способны охватить всю сложность и многообразие языковой системы. Кроме того, применение формализма для структурирования предложения естественного языка, учитывающего типы синтаксических связей, зачастую приводит к потере правильного синтаксического представления или комбинаторному взрыву, когда программа оказывается не в состоянии просчитать все возможные варианты структур. Упрощение алгоритмов и отказ от перебора омонимичных вариантов – компромисс, который приводит к низкой точности синтаксического анализа предложения. Задача автоматизированного анализа синтаксиса естественного языка сводится к двум параметрам: качеству, определяемому парой «точность (уровень ошибок в построенных синтаксических структурах предложений), полнота (степень покрытия текста синтаксическими связями, или связность графа предложения)», и скорости, пока что недостаточной для ряда прикладных задач [8].
1. Актуальность темы
Синтаксический анализ является одним из наиболее сложных и актуальных направлений в теории компьютерной лингвистики. Синтаксические анализаторы широко применяются в таких областях как создание компиляторов, проектирование интерфейсов баз данных, искусственный интеллект (ИИ), автоматическая обработка текстов (АОТ), в том числе, для автоматизированных информационно-поисковых систем (АИПС, или «поисковых машин»), машинный перевод (МП), анализ химических формул и распознавание хромосом.
Ввиду большого роста объемов текстовой информации и сложной структурированности естественно-языковых (ЕЯ) текстов, анализ текстов представляет собой актуальную проблему, особенно в последние 15–20 лет, когда наметилась тенденция к информатизации общества.
2. Цель и задачи исследования, научная новизна
Целью данной работы является разработка метода вычленения базовых синтаксических структур в виде предикатов распространённых простых предложений русского языка и установление синтаксических связей между ними.

Рисунок 1 – Результат синтаксического анализа в виде предикатной структуры (анимация: 8 кадров, 8 циклов повторения, 131 килобайт)
Основные задачи исследования:
- Сделать обзор подходов, используемых при создании модуля автоматического синтаксического анализа предложений естественного языка, а также способов представления синтаксической структуры предложения, определить их недостатки.
- Провести анализ основных проблем, возникающих при получении синтаксической структуры предложения.
- Разработать метод, идентифицирующий такие синтаксические категории предложения русского языка, как подлежащее и сказуемое.
- Разработать алгоритм определения подчинительной связи слов предложения русского языка.
- На основе предложенных методов и алгоритмов разработать метод получения синтаксической структуры простого распространенного предложения русского языка, использующий предикаты.
- Рассмотреть методы описания естественного языка (формально-грамматический и вероятностно-статистический).
Объект исследования: предложения русского языка.
Предмет исследования: методы синтаксического анализа предложений естественно-языковых текстов.
Научная новизна исследовательской работы заключается в усовершенствовании метода получения синтаксической структуры простого распространенного предложения русского языка за счет использования атрибутивной формы описания объекта, субъекта и действия.
3. Обзор исследований и разработок
В основе задачи обработки ЕЯ-текстов лежат морфологический и морфемный анализ, синтаксический и семантический анализ, результатами которых являются модели текста, адекватно отражающие его словообразовательные, грамматические и смысловые конструкции. Синтаксический анализ (анализ грамматики) можно встретить в системах перевода, в подсистемах проверки грамматики. Несмотря на богатую теорию в области семантического анализа, применение находят лишь методы анализа основанные на статистических (факторных) характеристиках слов и словосочетаний анализируемого текста. Следует отметить, что подсистемы, реализующие указанные методы анализа текста, не предоставляют средств настройки процесса анализа, средств пополнения баз правил грамматики языка.
3.1 Обзор международных источников
В монографии Найхановой Л.В. «Технология создания методов автоматического построения онтологий с применением генетического и автоматного программирования» рассматриваются вопросы автоматизации процесса создания онтологий. Работа содержит базовые понятия онтологий, категориальный аппарат универсальных онтологий и основные методы их создания. Большое внимание в работе уделено технологиям генетического и автоматного программирования как средствам автоматического построения методов естественно-языковой обработки научного текста, необходимых для создания онтологий.
В работе Михайлова Д.В. «Теоретические основы оценки семантической эквивалентности, модели распознавания и компрессии текстов в открытых системах контроля знаний» приведен анализ существующих методов моделирования семантики конструкций ЕЯ и определение общих требований, предъявляемых к механизму сравнения смыслов на функциональном уровне.
Монография Манаенко Г.Н. включает в себя актуальные проблемы теории языка и теории журналистики. Обосновывается и разрабатывается информационно-дискурсивный подход к анализу языковых единиц, интегрирующий достижения различных областей гуманитарного знания [6].
3.2 Обзор национальных источников
В статье Ларисы Мелешкевич «Семантическая организация предложения и предикат: пути исследования» представлен анализ основных направлений исследования семантической структуры предложения и предиката и устанавливаются различия концепций.
Научная статья Боговик О.А. «Структурно-семантические особенности с предикатами знаний» включает в себя особенности структурно-семантического анализа предложений с предикатами знаний в английском, украинском и русском языках.
Статья Матлиной М.М. «Антропонимы и их транспозиты как главные компоненты преобразований предложений тождества» раскрывает суть общих и частных условий преобразований предложений тождества. Характеризуются все возможные преобразования предложений тождества, в которых позиции субъекта и предиката занимают антропонимы .
3.3 Обзор локальных источников
В статье Дорохиной Г. В. «Автоматическое выделение синтаксически связанных слов простого распространенного неосложненного предложения» изложен алгоритм определения являются ли два слова связанными подчинительной связью. Он состоит в проверке того, является ли первое слово главным и является ли второе слово главным. Если ни одно из слов не является главным, связи между словами нет. Метод формирования дерева синтаксического подчинения простого распространенного неосложненного предложения [10].
4. Способы представления предложений русского языка
Синтаксический анализ (СА) – развивающаяся область прикладной лингвистики. Цель синтаксического анализа – автоматическое построение функционального дерева фразы, т.е. нахождение взаимозависимостей между разноуровневыми элементами предложения. Синтаксическая структура отражает синтаксические связи, существующие между словами в предложении русского языка.
4.1 Проблемы, возникающие при обработке текстов
При синтаксическом анализе возникает несколько проблем – омонимия, эллипсис, анафора.
Синтаксическая омонимия.Среди многочисленных систем составляющих, которые могут быть выделены в предложении естественного языка, лишь немногие «правильны», т.е. отражают принятые в лингвистике соглашения о синтаксической структуре предложения данного языка. Предложение может иметь несколько «правильных» систем составляющих, соответствующих различным толкованиям предложения. Это явление называют синтаксической омонимией.
Пример:
1. Для зависимого слова можно найти разных «хозяев»: Он умеет заставить себя слушать (заставить себя или себя слушать); Сергей вернулся из командировки в Москву (вернулся в Москву или командировки в Москву); Мы встретили сына художника, приехавшего из Парижа (сына приехавшего или художника приехавшего); Роняет лес багряный свой убор (багряный лес или багряный убор). Такую омонимию называют стрелочной, потому что разные смыслы конструкции можно отобразить с помощью разных стрелок.
2. Пара «хозяин-слуга» выделяется единственным способом, но проинтерпретировать связь между этими словами можно по-разному: Преследование тигра закончилось неудачей (тигр преследует кого-то или кто-то преследует тигра). Такой вид омонимии называется разметочной.
3. Рядом расположенные слова могут по-разному объединяться в группы. В концерте приняли участие известные ансамбли и самодеятельные коллективы (прилагательное известные относится только к существительному ансамбли или также к коллективы). Такая омонимия называется конституентной.
Трудными для автоматической обработки являются такие вполне допустимые в ЕЯ явления, как эллипсис (пропуск обязательных фрагментов предложения в силу возможности их восстановления из предыдущего контекста) и анафора (отношение между словами или словосочетаниями, при котором в смысл одного выражения входит отсылка к другому, ранее упомянутому, языковому выражению).
Эллипсис – фигура слова, входящая в группу фигур убавления. Сущность его состоит в преднамеренном пропуске слова, предложения, фрагментов речи, которые подразумеваются и легко восстанавливаются по смыслу, контексту, ситуативно. При помощи эллипсиса демонстрируется экспрессия, нагнетается напряженность, передается динамика событий.
Анафора – отношение между словами или словосочетаниями, при котором в смысл одного выражения входит отсылка к другому, ранее упомянутому, языковому выражению.
4.2 Способы синтаксического представления
Граф – наиболее наглядный и наиболее распространенный способ представления синтаксической структуры предложения. При этом предложение представляется как линейно упорядоченное множество элементов (словоформ), на котором можно задать ориентированное дерево (узлы – элементы множества). Каждая дуга, связывающая пару узлов, интерпретируется как подчинительная связь между двумя элементами, направление которой соответствует направлению данной дуги.
Граф зависимости. Описание структур в форме классического графа зависимостей хорошо соответствует русской грамматической традиции: оно основывается на понятии бинарного словосочетания в предложении с выделенными главными и зависимыми элементами. Обычно ровно один узел графа в подавляющем большинстве моделей, соответствующий сказуемому, не имеет подчиняющего узла и называется вершиной. Иногда двумя вершинами представляют подлежащее и сказуемое.
Отношение подчинения задает частичный порядок на множестве узлов. Если одному узлу подчиняется сразу несколько узлов , то среди последних порядок не определен: граф зависимостей не передает информацию об относительной степени близости подчиненного слова к главному.
Иногда граф зависимостей одновременно с отношением подчинения задает и отношение линейного порядка следования узлов. Такой граф называется расположенным. Один из способов изображения такого графа.
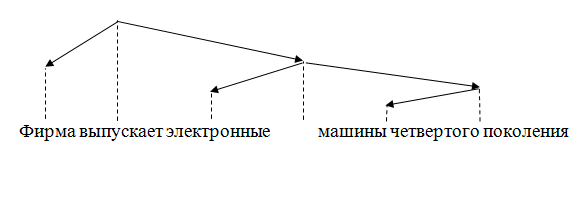
Рисунок 2 – Расположенный граф зависимостей
Граф непосредственных составляющих.Следует подчеркнуть, что деревья зависимостей дают возможность рассматривать направленные связи, но только между отдельными словами, системы составляющих характеризуют синтаксическую структуру предложения иначе – с их помощью словосочетания (или синтагмы) описываются в явном виде, но игнорируется ориентация связей (т.е. не различаются «хозяин» и «слуга»).
Синтагма – совокупность нескольких слов, объединённых по принципу семантико-грамматической сочетаемости, единица синтагматики. Объём конкретной синтагмы определяется не только реальным употреблением слов в связке, но и самой возможностью объединения предметов, признаков и процессов окружающей действительности. Минимальной длиной синтагмы следует считать простые словосочетания.
В основе модели дерева оставляющих лежит представление об устройстве предложения как о последовательном попарном синтагматическом сцеплении составляющих от минимальных – отдельных слов, до максимальной – предложения, составляющими которого в случае полного личного предложения являются группа подлежащего и группа сказуемого.
Представление синтаксической структуры в терминах дерева составляющих хорошо согласуется с традиционным «разбором» предложения, при котором подлежащее, сказуемое и их элементы описываются категориальными характеристиками – именами частей речи или групп.
Отличительной особенностью модели дерева составляющих является то, что она задает порядок (степень близости между словами) во множестве слов, которые в предыдущей модели подчинялись бы одному и тому же узлу [14].
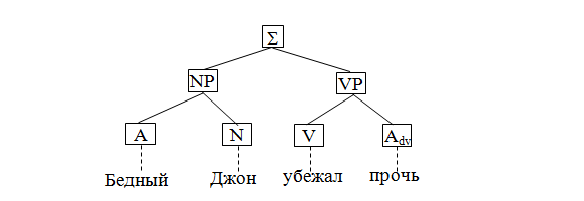
Рисунок 3 – Схема связей
Дерево составляющих передает также соответствие между синтагматикой и линейной упорядоченностью слов в предложении. Нарушение прямого соответствия выражается в форме прерывных (или разрывных) составляющих, которые особенно распространены в языках со свободным порядком слов. Как и в графе зависимостей, в дереве составляющих могут использоваться условные узлы и связи.
Пусть х – произвольная непустая цепочка. Множество С отрезков цепочки х называется системой составляющих этой цепочки, если оно удовлетворяет двум условиям:
1) множество С содержит отрезок, состоящий из всех точек цепочки х, и все одноточечные отрезки x;
2) любые два отрезка из С либо не пересекаются, либо один из них содержится в другом.
Элементы С называются составляющими. Одноточечные отрезки называются точечными (тривиальными) составляющими [15].
Выводы
В процессе выполнения данной работы были решены следующие задачи:
– произведён обзор подходов, используемых при синтаксическом анализе предложений естественного языка;
– проанализирована предикатная структура предложения;
– обоснован выбор синтаксического представления предложения в виде предикатной структуры;
– выявлены основные проблемы, возникающие при синтаксическом анализе – синтаксическая омонимия, эллипсис и анафора.
В последующем, результаты будут использоваться для написания дипломного проекта, в котором предполагается:
– алгоритм определения подчинительной связи слов предложения русского языка;
– метод, идентифицирующий такие синтаксические категории предложения русского языка, как подлежащее и сказуемое;
– метод получения синтаксической структуры простого распространенного предложения русского языка, использующий предикаты.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: январь 2012 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Ягунова Елена Викторовна Вариативность стратегий восприятия звучащего текста(экспериментальное исследование на материале русскоязычных текстов разных функциональных стилей) монография / Ягунова Е.В.; Перм.ун-т; СПбГУ – Пермь, 395с. 2008
- Леонтьева Н.Н. Автоматическое понимание текста: системы, модели, ресурсы: учебное пособие – М.: Издательский центр «Академия», 2006– 228 с.
- Мельчук 1999 – Мельчук И.А. Опыт теории лингвистических моделей «Смысл«Текст» – М., 1999, – С. 52–63.
- Апресян и др. 1989 – Апресян Ю.Д., Богуславский И.М., Иомдин Л.Л. и др. Лингвистическое обеспечение системы ЭТАП-2 – М.: Наука, 1989
- Перцова Н.Н. К построению глубинно-семантического компонента модели понимания текста // Проблемы вычислительной лингвистики и автоматической обработки текста на естественном языке – М., 1980– 114 с.
- Новиков А.И. Семантика текста и ее формализация, – М.: Наука, 1983– 453 с.
- Файн В.С. Распознавание образов и машинное понимание естественного языка – М.: Наука, 1987, – С. 21–43.
- Откупщикова М. И. Синтаксис связного текста: учебное пособие – Л., 1984– 276 с.
- Севбо И.П. Структура связного текста и автоматизация реферирования – М.: Наука, 1969, – С. 201–236.
- Емашова О.А., Мальковский М.Г. Функциональные стили русского языка и их влияние на задачу автоматического реферирования текста // Компьютерная лингвистика и интеллектуальные технологии: Труды международной конференции «Диалог 2007» (Бекасово, 30 мая-3 июня 2007 г.) / Под ред. Л.Л. Иомдина, Н.И. Лауфер, А.С. Нариньяни, В.П. Селегея – М.: Изд-во РГГУ, 2007– 324 с.
- Волкова И.А., Руденко Т.В. Формальные грамматики и языки. Элементы теории трансляции. – М.: Изд-во МГУ, 1999 – 62 с.
- Волкова И.А., Мальковский М.Г., Одинцев Н.В. Адаптивный Синтаксический анализатор // Диалог 2003: Труды Международного семинара. – М., 2003, Т. 1. – С. 401–406
- Сусов И. П. Введение в языкознание – М.: Восток-Запад, 2006 – 382 с.
- Современный русский язык: Учебник для филологических специальностей высших учебных заведений / В.А. Белошапкова, Е.А. Брызгунова, Е.А. Земская и др.; Под ред. Белошапковой – 3-е изде, испр. и доп. – М.: Азбуковник, 1997 – 928 с.
- Ножов И.М. Морфологическая и синтаксическая обработка текста (модели программы). – М.: Наука, 2003 – 140 с.
- Евдокимова И.С. Естественно-языковые системы: курс лекций – Улан-Удэ: Издательство ВСГТУ, 2006 – 92 с.