
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження, наукова новизна
- 3. Огляд досліджень та розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Способи уявлення речень російської мови
- 4.1 Проблеми, що виникають при обробці тексту
- 4.1 Способи синтаксичного представлення
- Висновки
- Перелік посилань
- 4.1 Способи синтаксичного представлення
Вступ
Взаємодія між лінгвістикою і комп'ютерними науками почалося ще півстоліття тому з виникненням теорії Н. Хомського, розвитком генератівізма і появою електронно-обчислювальних машин. Багато лінгвістичних ідей та концепцій протягом останніх десятиліть були запозичені і втілені в програмуванні, теоретичній інформатикі та інформаційних системах. Найбільш яскравими прикладами такого запозичення можуть служити базисний компонент, що породжує граматики Н. Хомського, який став прототипом перших компіляторів штучних мов, або висунута М. Мінскі, дослідником в галузі ШІ, теорія фреймів для представлення реальних об'єктів в системах розпізнавання образів і природних мов, яка зіграла свою роль як у становленні об'єктно-орієнтованого підходу в програмуванні, так і в семантичних дослідженнях мови, а спадкування і поліморфізм – фундаментальні принципи об'єктно-орієнтованого програмування – стали застосовуватися в проектуванні лексиконів [3].
На сьогодні створення повноцінного лінгвістичного процесора (ЛП) є однією з найбільш актуальних завдань в комп'ютерній лінгвістиці, вирішення якої дозволило б досягти високого рівня формалізації мовних структур в різноманітних прикладних цілях: від створення систем автоматичного розпізнавання мови до пошукових систем в Інтернет [5].
З боку свого внутрішнього устрою ЛП являє собою багаторівневий перетворювач. У ньому розрізняються три рівні пофразно подання тексту, які відповідають рівням мови – морфологічний, синтаксичний і семантичний. Кожен з рівнів обслуговується відповідним компонентом моделі - масивом правил і певним словником. Стадія морфологічного аналізу є найбільш опрацьованим лінгвістичним етапом процесу обробки природного тексту, чого не можна сказати про синтаксичному аналізі.
При розробці алгоритмів сегментаційного, повного синтаксичного аналізу, особливо для мов з відносно вільним порядком слів, яким є російська та українська, існує ряд труднощів, оскільки формальні математичні моделі та їх програмні динамічні реалізації не здатні охопити всю складність і різноманіття мовної системи. Крім того, застосування формалізму для структурування пропозиції природної мови, що враховує типи синтаксичних зв'язків, часто призводить до втрати правильного синтаксичного представлення або комбінаторному вибуху, коли програма виявляється не в змозі прорахувати всі можливі варіанти структур. Спрощення алгоритмів і відмова від перебору омонімічних варіантів – компроміс, який призводить до низької точності синтаксичного аналізу пропозиції. Завдання автоматизованого аналізу синтаксису природної мови зводиться до двох параметрах: якості, який визначається парою „точність (рівень помилок в побудованих синтаксичних структурах пропозицій), повнота (ступінь покриття тексту синтаксичними зв'язками, або зв'язність графа пропозиції)“, і швидкості, поки що недостатній для ряду прикладних задач [8].
1. Актуальність теми
Синтаксичний аналіз є одним з найбільш складних і актуальних напрямів у теорії комп'ютерної лінгвістики. Синтаксичні аналізатори широко застосовуються в таких областях як створення компіляторів, проектування інтерфейсів баз даних, штучний інтелект (ШІ), автоматична обробка текстів (АОТ), в тому числі, для автоматизованих інформаційно-пошукових систем (АІПС, або «пошукових машин»), машинний переклад (МП), аналіз хімічних формул і розпізнавання хромосом.
Зважаючи на велику зростання обсягів текстової інформації та складної структурованості природно-мовних (ЕЯ) текстів, аналіз текстів являє собою актуальну проблему, особливо в останні 15–20 років, коли намітилася тенденція до інформатизації суспільства.
2. Мета і задачі дослідження, наукова новизна
Метою даної роботи є розробка методу вичленування базових синтаксичних структур у вигляді предикатів поширених простих речень російської мови і встановлення синтаксичних зв'язків між ними.

Рисунок 1 – Результат синтаксического анализа в виде предикатной структуры (анимация: 8 кадров, 8 циклов повторения, 131 килобайт)
Основні задачі дослідження:
- Зробити огляд підходів, що використовуються при створенні модуля автоматичного синтаксичного аналізу речень природної мови, а також способів подання синтаксичної структури речення, визначити їх недоліки.
- Провести аналіз основних проблем, що виникають при отриманні синтаксичної структури речення.
- Розробити метод, що ідентифікує такі синтаксичні категорії речення російської мови, як підмет і присудок.
- Розробити алгоритм визначення підрядної зв'язку слів речення російської мови.
- На основі запропонованих методів і алгоритмів розробити метод отримання синтаксичної структури простого поширеного речення російської мови, що використовує предикати.
- Розглянути методи опису природної мови (формально-граматичний і ймовірнісно-статистичний).
Об'єкт дослідження: речення російської мови.
Предмет дослідження: методи синтаксичного аналізу речень природно-мовних текстів.
Наукова новизна дослідницької роботи полягає в удосконаленні методу отримання синтаксичної структури простого поширеного пропозиції російської мови за рахунок використання атрибутивної форми опису об'єкта, суб'єкта і дії.
3. Огляд досліджень та розробок
В основі завдання обробки ЕЯ-текстів лежать морфологічний і морфемний аналіз, синтаксичний і семантичний аналіз, результатами яких є моделі тексту, адекватно відображають його словотворчі, граматичні і смислові конструкції. Синтаксичний аналіз (аналіз граматики) можна зустріти в системах перекладу, в підсистемах перевірки граматики. Незважаючи на багату теорію в області семантичного аналізу, застосування знаходять лише методи аналізу засновані на статистичних (факторних) характеристиках слів і словосполучень аналізованого тексту. Слід зазначити, що підсистеми, які реалізують зазначені методи аналізу тексту, не надають коштів настройки процесу аналізу, засобів поповнення баз правил граматики мови.
3.1 Огляд міжнародних джерел
В монографії Найхановой Л.В. „Технологія створення методів автоматичної побудови онтологій із застосуванням генетичного і автоматного програмування“ розглядаються питання автоматизації процесу створення онтологій. Робота містить базові поняття онтологій, категоріальний апарат універсальних онтологій та основні методи їх створення. Велика увага в роботі приділена технологіям генетичного і автоматного програмування як засобам автоматичної побудови методів природно-мовної обробки наукового тексту, необхідних для створення онтологій.
У роботі Михайлова Д.В. „Теоретичні основи оцінки семантичної еквівалентності, моделі розпізнавання та компресії текстів у відкритих системах контролю знань“ наведено аналіз існуючих методів моделювання семантики конструкцій ЕЯ та визначення загальних вимог, що пред'являються до механізму порівняння смислів на функціональному рівні..
Монографія Манаенко Г.Н. включає в себе актуальні проблеми теорії мови та теорії журналістики. Обгрунтовується і розробляється інформаційно-дискурсивний підхід до аналізу мовних одиниць, що інтегрує досягнення різних галузей гуманітарного знання [6].
3.2 Огляд національних джерел
У статті Лариси Мелешкевич „Семантична організація пропозиції і предикат: шляхи дослідження“ подано аналіз основних напрямків дослідження семантичної структури речення і предиката і встановлюються відмінності концепцій.
Наукова стаття Боговик О.А. „Структурно-семантичні особливості з предикатами знань“ включає в себе особливості структурно-семантичного аналізу речень із предикатами знань в англійській, українській і російській мовах.
Стаття Матлин М.М. „Антропоніми та їх транспозіти як головні компоненти перетворень пропозицій тотожності“ розкриває суть загальних і приватних умов перетворень пропозицій тотожності. Характеризуються всі можливі перетворення пропозицій тотожності, в яких позиції суб'єкта і предиката займають антропоніми.
3.3 Огляд локальних джерел
У статті Дорохіної Г. В. „Автоматичне виділення синтаксично пов'язаних слів простого поширеного неускладненого реченняї“ викладено алгоритм визначення чи є два слова пов'язаними підрядним зв'язком. Він полягає в перевірці того, чи є перше слово головним і чи є друге слово головним. Якщо жодне з слів не є головним, зв'язки між словами немає. Метод формування дерева синтаксичного підпорядкування простого поширеного неускладненого речення [10].
4. Способи уявлення речень російської мови
Синтаксичний аналіз (СА) – розвивається область прикладної лінгвістики. Мета синтаксичного аналізу – автоматична побудова функціонального дерева фрази, тобто знаходження взаємозалежностей між різнорівневими елементами пропозиції. Синтаксична структура відображає синтаксичні зв'язки, що існують між словами в реченні російської мови.
4.1 Проблеми, що виникають при обробці тексту
При синтаксичному аналізі виникає кілька проблем – омонімія, еліпсис, анафора.
Синтаксична омонімія. Сeред численних систем складових, які можуть бути виділені в пропозиції природної мови, лише деякі „правильні“, тобто, відображають прийняті в лінгвістиці угоди про синтаксичній структурі речення цієї мови. Пропозиція може мати декілька „правильних“ систем складових, що відповідають різним тлумаченням пропозиції. Це явище називають синтаксичної омонімією.
Приклад:
1. Для залежного слова можна знайти різних „господарів“: Він вміє змусити себе слухати (змусити себе або себе слухати); Сергій повернувся з відрядження до Москви (повернувся в Москву або відрядження в Москву); Ми зустріли сина художника, який приїхав з Парижа ( сина приїхав або художника приїхав); Безмовно ліс багряний свій убір (багряний ліс або багряний убір). Таку омонимию називають стрілочної, тому що різні смисли конструкції можна відобразити за допомогою різних стрілок.
2. Пара „господар-слуга“ виділяється єдиним способом, але проінтерпретувати зв'язок між цими словами можна по-різному: Переслідування тигра закінчилося невдачею (тигр переслідує когось або хтось переслідує тигра). Такий вид омонімії називається розмічальної.
3. Ряд розташовані слова можуть по-різному об'єднуватися в групи. У концерті взяли участь відомі ансамблі та самодіяльні колективи (прикметник відомі відноситься тільки до іменника ансамблі або також до колективи). Така омонімія називається констітуентной
Важкими для автоматичної обробки є такі цілком допустимі в ЕЯ явища, як еліпсис (пропуск обов'язкових фрагментів пропозиції в силу можливості їх відновлення з попереднього контексту) і анафора (відношення між словами чи словосполученнями, при якому в сенс одного висловлювання входить відсилання до іншого, раніше згаданого , мовною висловом).
Еліпсіс – фігура слова, що входить до групи фігур збавляння. Сутність його полягає в навмисному пропуску слова, пропозиції, фрагментів мови, які маються на увазі і легко відновлюються за змістом, контексту, ситуативно. За допомогою Еліпсіс демонструється експресія, нагнітається напруженість, передається динаміка подій.
Анафора – відношення між словами чи словосполученнями, при якому в сенс одного висловлювання входить відсилання до іншого, раніше згаданого, мовною висловом.
4.2 Способи синтаксичного представлення
Граф – найбільш наочний і найбільш поширений спосіб представлення синтаксичної структури пропозиції. При цьому пропозиція подається як лінійно упорядкований безліч елементів (словоформ), на якому можна задати орієнтоване дерево (вузли – елементи множини). Кожна дуга, що пов'язує пару вузлів, інтерпретується як підрядний зв'язок між двома елементами, напрямок якої відповідає напрямку даної дуги.
Граф залежності.Опис структур у формі класичного графа залежностей добре відповідає російської граматичної традиції: воно грунтується на понятті бінарного словосполучення в реченні з виділеними головними і залежними елементами. Зазвичай рівно один вузол графа в переважній більшості моделей, відповідний присудка, не має підпорядковуючого вузла і називається вершиною. Іноді двома вершинами представляють підмет і присудок.
Відношення підпорядкування задає частковий порядок на множині вузлів. Якщо одному вузлу підпорядковується відразу декілька вузлів, то серед останніх порядок не визначений: граф залежностей не передає інформацію про відносну ступеня близькості підлеглого слова до головного.Іноді граф залежностей одночасно зі ставленням підпорядкування задає і ставлення лінійного порядку проходження вузлів. Такий граф називається розташованим. Один із способів зображення такого графа.
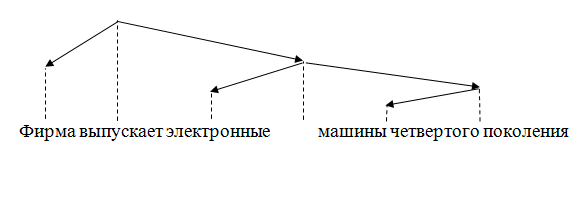
Рисунок 2 – Расположенный граф зависимостей
Граф безпосередніх складових.Слід підкреслити, що дерева залежностей дають можливість розглядати спрямовані зв'язку, але тільки між окремими словами, системи складових характеризують синтаксичну структуру пропозиції інакше – з їх допомогою словосполучення (або синтагми) описуються в явному вигляді, але ігнорується орієнтація зв'язків (тобто не розрізняються „господар“ і „слуга“).
Синтагма – сукупність декількох слів, об'єднаних за принципом семантико-граматичної сполучуваності, одиниця синтагматики. Обсяг конкретної синтагми визначається не тільки реальним вживанням слів в зв'язці, але й самою можливістю об'єднання предметів, ознак і процесів навколишньої дійсності. Мінімальною довжиною синтагми слід вважати прості словосполучення.
В основі моделі дерева залишають лежить уявлення про устрій пропозиції як про послідовне попарному синтагматичному зчепленні складових від мінімальних – окремих слів, до максимальної – пропозиції, складовими якого в разі повного особистого пропозиції є група підмета і група присудка. Подання синтаксичної структури в термінах дерева складових добре узгоджується з традиційним „розбором“ пропозиції, при якому підмет, присудок і їх елементи описуються категоріальними характеристиками – іменами частин мови або груп.
Відмінною особливістю моделі дерева складових є те, що вона задає порядок (ступінь близькості між словами) у безлічі слів, які в попередній моделі підпорядковувалися б одного й того ж сайту [14].
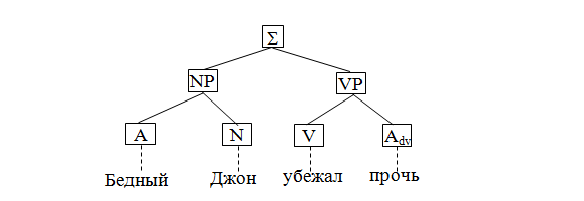
Рисунок 3 – Схема связей
Дерево складових передає також відповідність між синтагматика і лінійної впорядкованістю слів у реченні. Порушення прямого відповідності виражається у формі перериваних (або розривних) складових, які особливо поширені в мовах з вільним порядком слів. Як і в графі залежностей, в дереві складових можуть використовуватися умовні вузли та зв'язку.
Висновки
В процесі виконання даної роботи були вирішені наступні завдання:
- Проведений огляд підходів, що використовуються при синтаксичному аналізі пропозицій природної мови.
- Проаналізована предикатна структура речення
- Обгрунтований вибір синтаксичного представлення речення у вигляді предикатной структури.
- Виявлено основні проблеми, що виникають при синтаксичному аналізі - синтаксична омонімія, еліпсис і анафора.
У подальшому, результати будуть використовуватися для написання дипломного проекту, в якому передбачається:
- Алгоритм визначення підрядної зв'язку слів речення російської мови.
- Метод, що ідентифікує такі синтаксичні категорії речень російської мови, як підмет і присудок
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: січень 2013 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після вказаної дати.
Перелік посилань
- Ягунова Елена Викторовна Вариативность стратегий восприятия звучащего текста(экспериментальное исследование на материале русскоязычных текстов разных функциональных стилей) монография / Ягунова Е.В.; Перм.ун-т; СПбГУ – Пермь, 395с. 2008
- Леонтьева Н.Н. Автоматическое понимание текста: системы, модели, ресурсы: учебное пособие – М.: Издательский центр «Академия», 2006– 228 с.
- Мельчук 1999 – Мельчук И.А. Опыт теории лингвистических моделей «Смысл«Текст» – М., 1999, – С. 52–63.
- Апресян и др. 1989 – Апресян Ю.Д., Богуславский И.М., Иомдин Л.Л. и др. Лингвистическое обеспечение системы ЭТАП-2 – М.: Наука, 1989
- Перцова Н.Н. К построению глубинно-семантического компонента модели понимания текста // Проблемы вычислительной лингвистики и автоматической обработки текста на естественном языке – М., 1980– 114 с.
- Новиков А.И. Семантика текста и ее формализация, – М.: Наука, 1983– 453 с.
- Файн В.С. Распознавание образов и машинное понимание естественного языка – М.: Наука, 1987, – С. 21–43.
- Откупщикова М. И. Синтаксис связного текста: учебное пособие – Л., 1984– 276 с.
- Севбо И.П. Структура связного текста и автоматизация реферирования – М.: Наука, 1969, – С. 201–236.
- Емашова О.А., Мальковский М.Г. Функциональные стили русского языка и их влияние на задачу автоматического реферирования текста // Компьютерная лингвистика и интеллектуальные технологии: Труды международной конференции «Диалог 2007» (Бекасово, 30 мая-3 июня 2007 г.) / Под ред. Л.Л. Иомдина, Н.И. Лауфер, А.С. Нариньяни, В.П. Селегея – М.: Изд-во РГГУ, 2007– 324 с.
- Волкова И.А., Руденко Т.В. Формальные грамматики и языки. Элементы теории трансляции. – М.: Изд-во МГУ, 1999 – 62 с.
- Волкова И.А., Мальковский М.Г., Одинцев Н.В. Адаптивный Синтаксический анализатор // Диалог 2003: Труды Международного семинара. – М., 2003, Т. 1. – С. 401–406
- Сусов И. П. Введение в языкознание – М.: Восток-Запад, 2006 – 382 с.
- Современный русский язык: Учебник для филологических специальностей высших учебных заведений / В.А. Белошапкова, Е.А. Брызгунова, Е.А. Земская и др.; Под ред. Белошапковой – 3-е изде, испр. и доп. – М.: Азбуковник, 1997 – 928 с.
- Ножов И.М. Морфологическая и синтаксическая обработка текста (модели программы). – М.: Наука, 2003 – 140 с.
- Евдокимова И.С. Естественно-языковые системы: курс лекций – Улан-Удэ: Издательство ВСГТУ, 2006 – 92 с. .