
Abstract
Table of contents
- Introduction
- 1. Relevance of the topic
- 2. The purpose and objectives of the study, scientific novelty
- 3. Review of Research and Development
- 3.1 Overview of international sources
- 3.2 Overview of national sources
- 3.3 Overview of local sources
- 4. Methods for the submission of proposals of the Russian language
- 4.1 Problems with text processing
- 4.2 Means of syntactic representation
- Findings
- List of sources
- References
Introduction
The interaction between linguistics and computer science began half a century ago with the emergence of the theory of Khomsky, generativizm development and the emergence of computers. Many linguistic ideas and concepts over the past decades have been taken and implemented in the programming, theoretical computer science and information systems. The most striking examples of such borrowing may be a basic component of a generative grammar of Khomsky, who became the prototype of the first artificial languages, compilers, or advanced by M. Minsky, a researcher in artificial intelligence, theory of frames to represent real objects in the systems of pattern recognition and natural language, which has played its role in the formation of object-oriented approach to programming, as well as in studies of semantic language, and inheritance, and polymorphism basic principles of object-oriented programming have been used in the design of lexicons [3].
At present, the creation of a full-fledged language processor (LP) is one of the most pressing problems in computational linguistics, a decision which would achieve a high level of formalization of linguistic structures in a variety of application purposes: creation of systems for automatic speech recognition to search the Internet [5].
On the part of its internal devices LP is a multi-level inverter. There are three levels of pofraznogo represent text, which correspond to levels of language – morphological, syntactic and semantic. Each level is served by the appropriate component of the model – an array of rules and specific vocabulary. The stage of morphological analysis is the most elaborated stage of linguistic processing of natural text, which is not the parsing.
In the development of segmentation algorithms, a full syntactic analysis, especially for languages with relatively free word order, which are Russian and Ukrainian, there are a number of difficulties because formal mathematical models and their dynamic software implementation is not able to grasp the complexity and diversity of language systems. In addition, the application of the formalism for structuring proposals of natural language, taking into account the types of syntactic relations, often leads to loss of the correct syntactic representation and a combinatorial explosion when the program is not able to calculate all possible structures. Simplification algorithms for sorting and rejection of the homonymous variants – a compromise which leads to low accuracy of parsing sentences. The task of the automated analysis of natural language syntax is reduced to two dimensions: quality, as determined by a pair of "accuracy (error rate in the constructed syntactic structure of sentences), completeness (the degree of coverage of the text syntactic relations, or connectivity of the graph suggests)", and speed, yet inadequate for a number of applications [8].
1. Relevance of the topic
Parsing is one of the most complex and important trends in the theory of computational linguistics. Parsers are widely used in areas such as the creation of compilers, databases, user interface design, artificial intelligence (AI), automatic processing of texts (AOT), in particular, for automated information retrieval systems (AIRS, or "search engine"), the machine translation (MT), the analysis of chemical formulas and identification of chromosome.
Because of the large growth of textual information and complex structured natural language (NL) texts, text analysis is an actual problem, especially in the last 15 – 20 years, when there is a tendency for information society
2. The purpose and objectives of the study, scientific novelty
The aim of this work is to develop a method for the isolation of basic syntactic structures in a common predicate of simple sentences of Russian language and syntax to establish links between them.

Рисунок 1 – Результат синтаксического анализа в виде предикатной структуры (анимация: 8 кадров, 8 циклов повторения, 131 килобайт)
The main objectives of the study:
- To analyze the main problems encountered in obtaining the syntactic structure of sentences.
- Make an overview of the approaches used to create the automatic parsing of natural language sentences, as well as ways of representing the syntactic structure of sentences, identify their shortcomings..
- Develop a method for identifying syntactic categories such proposal of the Russian language as a subject and predicate.
- Develop an algorithm for determining word suggestions due subordination of the Russian language.
- On the basis of the proposed methods and algorithms to develop a method to obtain the syntactic structure of a simple common proposal of the Russian language, which uses predicates.
- Consider the description of the methods of natural language (formal, grammatical and probabilistic-statistical).
The object of study: proposals of the Russian language.
Subject of research: the methods of parsing sentences of natural language texts.Scientific novelty of the research is to improve the method for obtaining the syntactic structure of a simple common proposal of the Russian language through the use of attributive forms describe the object, subject and action.
Scientific novelty of the research is to improve the method for obtaining the syntactic structure of a simple common proposal of the Russian language through the use of attributive forms describe the object, subject and action
3. Review of Research and Development
At the heart of the problem of processing of NL-texts are morphological and morphemic analysis, syntactic and semantic analysis, the results of which are models of text that adequately reflect its derivation, grammatical and semantic structure. Syntactic analysis (grammar) can be found in the systems of translation, grammar checking in the subsystems. Despite the rich theory of semantic analysis, application methods are only based on statistical analysis (factor) characteristics of words and phrases of the analyzed text. It should be noted that the subsystems that implement these methods for analysis of the text, do not provide the customization process analysis, replenishment of base rules of grammar.
3.1 Overview of international sources
The book of Naykhanova "The technology to create methods for automatic construction of ontologies using genetic programming and the FSM," discusses how to automate the process of creating ontologies. The paper contains the basic concepts of ontology, an ontology of categories and universal basic methods of creating them. Much attention is paid to techniques of genetic programming and the FSM as a means of automatic methods for constructing natural language processing scientific text needed to create ontologies.
In Mikhailov "Theoretical framework for the assessment of semantic equivalence, model identification and compression of texts in an open system of knowledge control" is an analysis of existing methods of modeling the semantics of natural language constructions, and to identify common requirements for the mechanism of the comparison of meanings at the functional level.
Monograph Manaenko includes the actual problems of the theory of language and theory of journalism. Substantiated and developed information-discursive approach to the analysis of linguistic units, integrating the achievement of different areas of the humanities [6].
3.2 Overview of national sources
The article by Larisa Meleshkevich "Semantic organization offers and the predicate: the way of research,"an analysis of the main directions of research proposals and the semantic structure of the predicate and the set difference of concepts.
Cited Bogovik "The structural and semantic features of predicates of knowledge" includes the features of structural and semantic analysis of sentences with the predicates of knowledge in English, Ukrainian and Russian languages.
Article Matlin MM "Anthroponyms and transpozity as principal components transformation of identity sentences," reveals the essence of general and special conditions of transformation of identity sentences. Characterized by all possible transformations of identity sentences in which subject and predicate positions occupied anthroponomy.
3.3 Overview of local sources
The article Dorokhina "Automatic extraction of syntactically related words common simple uncomplicated proposals" outlined an algorithm for determining whether two words are related subordinate bond. It consists in checking whether the first word of the principal and whether the second word is paramount. If none of the words is not the main, there is no connection between the words. A method of forming a syntactic tree subordination simple uncomplicated common proposals [10].
4. Methods for the submission of proposals of the Russian language
Parsing the (CA) – developing area of applied linguistics. The purpose of parsing – automatic generation of functional tree phrases, ie finding a different level of interdependence between the elements of the proposal. The syntactic structure reflects the syntactic links between words in a sentence of the Russian language.
4.1 Problems with word processing
When parsing, there are several problems – homonymy, ellipsis, anaphora.
The syntactic homonymy. Among the many components of the system, which can be identified in a natural language sentence, only a few "correct", ie, reflect accepted in linguistics agreement on the syntactic structure of sentences of this language. The proposal may have multiple "correct" system components corresponding to different interpretations of the proposal. This phenomenon is called the syntactic homonymy.
Example:
1. For dependent word you can find different "owners": He is able to bring myself to listen (to make himself or herself to listen), Sergei returned from a trip to Moscow (or returned to Moscow trip to Moscow) We met the artist's son, who came from Paris ( son who came, or the artist who had come); forest sheds its crimson dress (scarlet or crimson cap timber). This arrow is called homonymy, because the different meanings of the design can be displayed by different arrows.
2. Words "boss-servant" stands the only way, but to interpret the relationship between these words can be different: Chase the tiger ended in failure (tiger pursuing someone or someone is following a tiger). This type of homonymy is a road marking.
3. Some words can be arranged in various ways to form groups. The concert was attended by prominent ensembles and amateur groups (the adjective is only known to a noun or as to the ensembles of groups). This is called homonymy constituent.
Difficult for the automatic processing of these are quite acceptable in the NL phenomenon of ellipsis (omission of the mandatory sentence fragments because of the possibility of recovery from the previous context), and anaphora (the relation between words or phrases in which the meaning of one expression is a reference to another, previously referred to , linguistic expression).
Ellipsis – a figure of speech, part of the subtraction of figures. Its essence consists in the deliberate omission of words, sentences, fragments of speech that means, and can easily be restored within the meaning, context, situational. With the ellipse shows the expression, forced tension passed the dynamics of events.
Anaphora – the relationship between words or phrases in which the meaning of one expression is a reference to another, previously mentioned, linguistic expression.
4.2 Means of syntactic representation
Count – the most obvious and most common way of representing the syntactic structure of sentences. In this case the proposal is presented as a linearly ordered set of elements (word forms), which you can set oriented tree (nodes – elements of the set). Each arc connecting a pair of nodes is interpreted as a subordinate relationship between the two elements, the direction which corresponds to the direction of the arc.
Dependency graph
Description of structures in the classical form of the dependency graph corresponds well to Russian grammatical tradition: it is based on the notion of a binary phrase in a sentence with dedicated principal and subordinate elements. Normally exactly one node of the graph in the vast majority of models corresponding to the predicate, not subordinating node and is called the vertex. Sometimes the two peaks represent the subject and predicate.
The attitude of subordination determines a partial order on the set of nodes. If one site is subject to several sites, among the latter procedure is not defined: the dependency graph does not pass the information on the relative proximity of the word slave to the master.
Sometimes the dependency graph simultaneously with the attitude and the attitude of submission specifies the linear order of nodes. Such a graph is located. One way to picture such a graph.
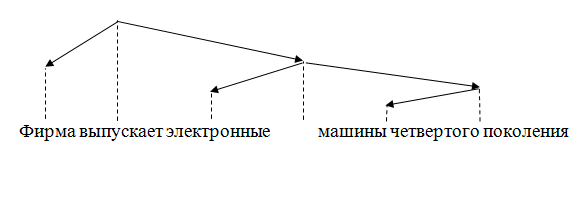
Рисунок 2 – Расположенный граф зависимостей
Count immediate constituents
It should be emphasized that the trees provide an opportunity to consider the dependence of directed communication, but only between individual words, the system components describe the syntactic structure suggests otherwise – with their help, the phrase (or syntagm) are described in explicit form, but ignores the orientation of the bonds (ie, do not differ "master" and "servant").
Syntagma – a set of few words, united on the principle of semantic and grammatical compatibility, syntagmatic unit. The volume of a particular syntagm is not only the actual use of words in a bundle, but also the possibility of combining objects, features and processes of reality. Minimum length of syntagm should be considered a simple phrase.
The model tree is the idea of leaving the unit offers both a syntagmatic sequence of pairwise linkage components of the minimum – single words, to the maximum – offers, components of which in the case of a complete personal offers are subject to the group and the group predicate.
Presentation of the syntactic structure in terms of tree components in good agreement with the traditional "analysis of" proposals, in which the subject, predicate and their elements are described by categorical characteristics – the names of the parts of speech or groups.
A distinctive feature of the model tree components is that it specifies the order (degree of similarity between the words) in a variety of words that in the previous model would be submitted to the same node [14].
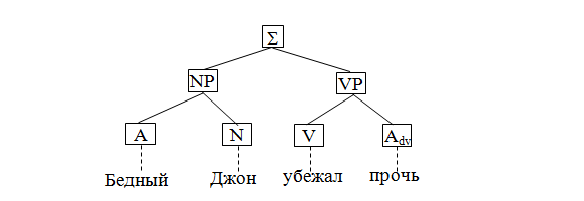
Рисунок 3 – Схема связей
Wood components and transmits the correspondence between the syntagmatic and the linear ordering of words in a sentence. Violation of a direct correspondence is expressed in the form of continuous (or discontinuous) components, which are particularly common in languages with free word order. As in the dependency graph, the tree component can be used by the conditional nodes and links.
Let x – an arbitrary non-empty string. Many segments of the chain C x is the system components in the chain if it satisfies two conditions:
1. the set C contains a segment that consists of all points x of the chain, and all segments of the one-point x;
2. any two segments of C are either disjoint or one contains the other.
The elements of C are called components. Segments are called point-point (trivial) components [15].
Findings
In carrying out this work were solved the following problems::
– Reviewed the approaches used to parse sentences of natural language;
– Analyze the predicate sentence structure;
– The choice of the syntactic presentation of the proposal in the form of predicate structure;
– Identify the main problems encountered when parsing – syntactic homonymy, ellipsis, and anaphora.
Subsequently, the results will be used to write the diploma project, which assumes:
– Algorithm for determining the relation of subordination of the Russian language words in a sentence;
– Method of identifying these syntactic categories proposals of the Russian language as a subject and predicate;
In writing this essay master's work is not yet complete.
References
- Ягунова Елена Викторовна Вариативность стратегий восприятия звучащего текста(экспериментальное исследование на материале русскоязычных текстов разных функциональных стилей) монография / Ягунова Е.В.; Перм.ун-т; СПбГУ – Пермь, 395с. 2008
- Леонтьева Н.Н. Автоматическое понимание текста: системы, модели, ресурсы: учебное пособие – М.: Издательский центр «Академия», 2006– 228 с.
- Мельчук 1999 – Мельчук И.А. Опыт теории лингвистических моделей «Смысл«Текст» – М., 1999, – С. 52–63.
- Апресян и др. 1989 – Апресян Ю.Д., Богуславский И.М., Иомдин Л.Л. и др. Лингвистическое обеспечение системы ЭТАП-2 – М.: Наука, 1989
- Перцова Н.Н. К построению глубинно–семантического компонента модели понимания текста // Проблемы вычислительной лингвистики и автоматической обработки текста на естественном языке – М., 1980– 114 с.
- Новиков А.И. Семантика текста и ее формализация, – М.: Наука, 1983– 453 с.
- Файн В.С. Распознавание образов и машинное понимание естественного языка – М.: Наука, 1987, – С. 21–43.
- Откупщикова М. И. Синтаксис связного текста: учебное пособие – Л., 1984– 276 с.
- Севбо И.П. Структура связного текста и автоматизация реферирования – М.: Наука, 1969, – С. 201–236.
- Емашова О.А., Мальковский М.Г. Функциональные стили русского языка и их влияние на задачу автоматического реферирования текста // Компьютерная лингвистика и интеллектуальные технологии: Труды международной конференции «Диалог 2007» (Бекасово, 30 мая–3 июня 2007 г.) / Под ред. Л.Л. Иомдина, Н.И. Лауфер, А.С. Нариньяни, В.П. Селегея – М.: Изд-во РГГУ, 2007– 324 с.
- Волкова И.А., Руденко Т.В. Формальные грамматики и языки. Элементы теории трансляции. – М.: Изд-во МГУ, 1999 – 62 с.
- Волкова И.А., Мальковский М.Г., Одинцев Н.В. Адаптивный Синтаксический анализатор // Диалог 2003: Труды Международного семинара. – М., 2003, Т. 1. – С. 401–406
- Сусов И. П. Введение в языкознание – М.: Восток-Запад, 2006 – 382 с.
- Современный русский язык: Учебник для филологических специальностей высших учебных заведений / В.А. Белошапкова, Е.А. Брызгунова, Е.А. Земская и др.; Под ред. Белошапковой – 3-е изде, испр. и доп. – М.: Азбуковник, 1997 – 928 с.
- Ножов И.М. Морфологическая и синтаксическая обработка текста (модели программы). – М.: Наука, 2003 – 140 с.
- Евдокимова И.С. Естественно-языковые системы: курс лекций – Улан-Удэ: Издательство ВСГТУ, 2006 – 92 с.