
Реферат за темою випускної роботи
Зміст
- Мета та задачi
- Актуальність теми
- Планована наукова новiзна
- Плануємi практичнi результати
- Огляд дослiдженнь i розробок iз теми
- Огляд дослiдженнь i розробок iз теми. Глобальний рiвень
- Огляд дослiдженнь i розробок iз теми. Нацiональний рiвень
- Огляд дослiдженнь i розробок iз теми. Локальний рiвень
- Короткий виклад власних результатiв
- Висновки
- Список выкористанних джерел
Мета та задачі
Основною метою даної магістерської роботи є розробка методу і алгоритму видобутку структурованих даних з текстів новин наукового стилю в області видобутку даних.
Актуальність теми
Завдання розробки інформаційних порталів знань є одним з найактуальніших на сьогоднішній день. Портали забезпечують зведення ресурсів, що відносяться до однієї галузі знань в єдиний інформаційний простір, забезпечують можливість відкритого і зручного доступу до них, а також автоматизують оперативний збір та індексацію нової інформації, що надходить в текстовому неструктурованому вигляді.
Великий обсяг накопиченої інформації і висока швидкість надходження нової пред'являють все більш жорсткі вимоги до сучасних інформаційних порталів. По-перше, в постійно зростаючих масивах даних стає важко (практично неможливо) знайти потрібну інформацію, по-друге, дані часто дублюються і суперечать один одному. Для вирішення цих проблем необхідний перехід на новий якісний рівень при обробці інформації – необхідно вести обробку на семантичному рівні, тобто враховувати зміст документів, що надходять. Така обробка забезпечується системами автоматичного аналізу тексту на природній мові, що використовують лінгвістичний підхід.
Дана робота покликана забезпечити нові метод та алгоритм вилучення структурованих даних, орієнтовані на роботу в обмеженій предметній і проблемній області, що забезпечує вилучення даних з наукових текстів в області вилучення даних з текстів.
Результати роботи даного методу можна буде використовувати при наповненні тематичного інформаційного аб новинного порталу.
Планована наукова новiзна
В даній магістерській роботі буде або розроблений новий метод і алгоритм вилучення структурування даних, або вдосконалений існуючий, стосовно вилучення структурованих даних з текстів новин наукового стилю в області вилучення даних.
Плануємi практичнi результати
В якості планованих результатів очікується метод і алгоритм вилучення структурованних даних з текстів новин наукового стилю в області вилучення даних, який можна буде застосувати до системи вилучення інфромації для створення електронних підручників, наповнення інформаційних та новинних порталів, створення тематичних сайтів.
Огляд дослiдженнь i розробок iз теми. Глобальний рiвень
Аналіз вимог до систем вилучення інформацій
Автоматична обробка тексту на природній мові дозволяє полегшити пошук і вилучення інформації з метою подальшої аналітичної обробки. Найчастіше потрібно аналіз великих масивів коротких текстів (наприклад, новин) з метою виділення значущої інформації. В якості такої інформації може виступати опис якоїсь події, його дійові особи, локалізація в просторі та часі [1].
Системи вилучення інформації здійснюють обробку тексту на різних рівнях:
- а) первинна фільтрація документа;
- б) лінгвістична обробка:
- 1) графематіка;
- 2) морфологія;
- 3) синтаксис;
- в) виділення простих семантичних структур;
- г) власне вилучення інформації;
- д) об'єднання побудованих структур;
- е) розрішення анафори і кореферентності.
В ідеалі система вилучення інформації повинна бути незалежною від мови і надавати можливість налаштування на будь природна мова. Однак у даній роботі мова піде в першу чергу про обробку текстів російською мовою [2].
Інструментальні засоби необхідні для реалізації систем ізвлченія інформації повинні забезпечувати [3]:
- а) мінімально необхідний набір стандартних функцій лінгвістичної обробки;
- б) можливість заміщення модулів і налаштування порядку їх застосування;
- в) стандартні засоби налагоджувальних вводу-виводу;
- г) підтримання деякого мови опису правил добування інформації.
Зрозуміло, що не можна закладати в якості основних вимог, наприклад, засоби розрішення кореферентності або об'єднання побудованих структур. Подібні завдання мають безліч рішень, кожне з яких краще підходить до тієї чи іншої предметної області. Зокрема, експерименти з підходом до вирішення анафори, виявили, що набір атрибутів (вагових коефіцієнтів), які вказують значимість кожного з можливих антецедентов, повинен налаштовуватися індивідуально для кожної предметної області, а для деяких предметних областей такий підхід застосовується лише з дуже значними обмеженнями.
Розробка цілісної системи інструментальних засобів вимагає єдиного підходу. Безліч видів і етапів обробки тексту може створити враження, що неможливо виразити лінгвістичну інформацію та інформацію предметної області одноманітно, але насправді це не так [4].
Для успішного добування інформації з тексту система повинна мати деяку додаткову інформацію, яка не присутня в тексті в явному вигляді. Мова йде про набір атрибутів, приписаних фрагментами тексту: морфологічних, синтаксичних, лексичних, семантичних і т. п. Для отримання цієї додаткової інформації про текст виробляються різні види аналізу тексту. Аналіз носить багаторівневий характер, тому можна вважати, що лінгвістичний процесор складається з набору аналізаторів. Кожен аналізатор досліджує одну з лінгвістичних характеристик тексту. Як правило, такі рівні аналізу тексту використовують результати, отримані на попередніх етапах. Застосування правил вилучення інформації не є останнім етапом, який стоїть окремо, і ми розглядаємо його як частину прикладного семантичного аналізу [5].
Модель системи вилучення інформації
Існує два основних підходи до подання інформації про текст: контрольний і адитивний. Адитивний підхід має на увазі модифікацію вихідного тексту з додаванням в нього спеціальних службових символів (варіант такого підходу використання мови розмітки XML). Перевага такого підходу в тому, що текст після обробки може бути збережений, і надалі всю отриману інформацію можна відновити без повторної обробки [6]. Недоліками цього методу є необхідність модифікації тексту і знижена, порівняно з посиланнями підходом, продуктивність. Нормативний підхід пропонує зберігання інформації про текст окремо від самого тексту і прив'язку до тексту з використанням посилань. Продуктивність тут, як правило, вище, але виникає необхідність підтримки спеціальних структур даних. В посилальному підході можна виділити два напрямки:
- а) створення фіксованої об'єктної моделі тексту, що прийнятно для кінцевих програм обробки тексту (однак при спробі узагальнення позначається нестабільність такої моделі);
- б) створення уніфікованого підходу, наприклад, використання моделі анотацій, про яку розказано нижче.
Процес отримання додаткової інформації при аналізі тексту будемо називати анотування. Будь лінгвістична (і інша) інформація про текст представляється у вигляді анотації. Анотація зіставляється з фрагментом тексту, і належить класу анотацій і має атрибути. Клас анотацій – це рядок, що дозволяє розбити всі анотації на смислові групи. Для порівняння анотації та фрагмента тексту використовується початок і довжина (або початок і кінець) фрагмента тексту, до якого приписана анотація. Атрибути анотацій є пара <ім'я, значення>. В класичному підході вважається, що імена атрибутів унікальні, а значення представляють собою рядки, тому кожна анотація може містити лише одне значення кожного атрибута. При практичній реалізації часто потрібно представляти множинні атрибути, в цьому випадку користуються одним із двох способів:
- а) створення необхідної кількості анотацій, які містять лише атомарні значення атрибутів;
- б) використання деякого способу кодування інформації для випадку, коли в атрибуті потрібно зберегти складене складне значення (наприклад, введення спеціального символу-роздільника).
Треба зауважити, що різні модулі системи можуть використовуватися як один, так і інший спосіб. Другий спосіб є більш універсальним, оскільки модулі, що підтримують його, зможуть проаналізувати анотації, створені модулями, що підтримують перший спосіб (зворотної сумісності немає). При практичної реалізації ми слідували в основному другим способом.
Проблеми при використанні
першого способу можна проілюструвати
наступним прикладом
[1]. Нехай анотація 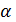 володіє безліччю
атрибутів описаної формулою (1)
володіє безліччю
атрибутів описаної формулою (1)
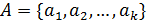 , (1)
, (1)
де 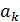 – певний
атрибут безлічі атрибутів
– певний
атрибут безлічі атрибутів 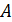 ,
для кожного з яких, в свою чергу визначено набір з
,
для кожного з яких, в свою чергу визначено набір з 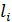 ,
описаний у формулі
(2)
,
описаний у формулі
(2)
 (2)
(2)
де 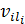 – певне
значення атрибута з набору його значень
– певне
значення атрибута з набору його значень 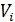 .
.
Тоді при класичному підходячи до вираження варіативності кожна анотація
повинна бути
перетворена до вигляду представленому у формулі (3)
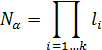 , (3)
, (3)
Де 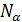 – кількість
анотацій, а –
значення атрибутів.
– кількість
анотацій, а –
значення атрибутів.
Огляд дослiдженнь i розробок iз теми. Нацiональний рiвень
Серед українських вчених найбільш значимий внесок до розробки методів і алгоритмів видобутку інформації з тексту новин зроблений Сокирко А.В. Деякі роботи Гладуна В.П. також мають відношення до даної тематики. Сокирко А.В. у своїй роботі «Графематичний аналіз» [7] вказує на переваги використання саме цього аналізотора для систем вилучення інформації.
Правила і вбудовані засоби систем вилучення інформації
Система застосування правил займається різними видами лінгвістичного аналізу. Вона дає можливість швидко виконувати розробку нових рівнів аналізу. Крім того, правила надають велику гнучкість системі завдяки тому, що модифікація правил виконується істотно легше, ніж модифікація коду 7лінгвістіческого процесора [7]. Однак обчислювальна ефективність аналізу, побудованого на правилах, нижче, ніж в коду лінгвістичного процесора.
Тому правила застосовувати не завжди доцільно. Поділ функцій між лінгвістичним процесором і системою правил проводиться за критерієм гнучкість/ефективність. Лінгвістичний процесор не володіє великою гнучкістю, але має високу продуктивність коду. Система правил більш повільна, але легко піддається модифікації.
Система складання фрейма здійснює пошук в тексті анотацій певного виду, які пов'язані з цільовою інформацією. Так як фрейм – це багатослотова структура, потрібно вміти розрізняти цільову інформацію, що відноситься до одного фрейму і в різних. Цю функцію здійснює підсистема збору фрейма.
Архітектура систем вилучення інформації
Незважаючи на те, що системи вилучення інформації можуть будуватися для виконання різних завдань, часом сильно відрізняються один від одного друг від друга, існують компоненти, які можна виділити практично в кожній системі.
До складу майже кожної системи вилучення інформації входять чотири основні компоненти, а саме: компонент розбиття на лексеми, деякий тип лексичного або морфологічного аналізу, синтаксичний аналіз (мікро-і макрорівень), модуль вилучення інформації і модуль для аналізу на рівні конкретної предметної області [8].
Залежно від вимог до конкретного програмного продукту, в наведену вище схему додають додаткові модулі аналізу (спеціальна обробка складних слів; усунення омонімії, виділення складових типів, що може також бути реалізований мову правил добування інформації, об'єднання часткових результатів).
Розбивка на слова при аналізі європейських мов не є проблемою, оскільки слова відокремлюються один від одного пробілом (або знаками пунктуації). Тим не менш, для обробки складних слів, абревіатур, буквено-цифрових комплексів та ряду інших особливих випадків потрібні специфічні алгоритми. З кордонами пропозицій, як правило, теж великих проблем не виникає. Однак при аналізі таких мов, як японський або китайський, визначення меж слова на основі орфографії неможливо. З цієї причини системи вилучення інформації, що працюють з такими мовами, повинні бути доповнені модулем сегментації тексту на слова [9].
В деякі системи поряд зі звичайними засобами лексичного і морфологічного аналізу можуть бути включені модулі для визначення і категоризації атрибутів частин мови, смислових навантажень слів, імен або інших нетривіальних лексичних одиниць.
Для багатьох предметних областей елементарний синтаксичний аналіз (наприклад, виділення іменних груп) може бути достатнім для визначення граматичної основи пропозиції, а також його основних частин, але в деяких випадках може знадобитися розширений або навіть повний синтаксичний аналіз.
Існують різні методи первинного вилучення інформації. В одних використовуються регулярні вирази «в чистому вигляді», в інших методах користуються простими правилами на основі регулярних виразів, також існує підхід з використанням спеціальних правил на основі цільових слотів і обмежень. Однак завдання всіх цих методів полягає у витяганні релевантної інформації в локальному контексті, глобалізація якого є завданням аналізу на рівні предметної області.
Цілком можливе створення системи, яка не вирішує проблеми кореферентності і не об'єднує цільові слоти, виділені з різних пропозицій, в єдиний цільової фрейм. Однак у багатьох випадках включення модулів для вирішення цих проблем суттєво підвищує ефективність всієї системи в цілому.
Огляд дослiдженнь i розробок iз теми. Локальний рiвень
Будучи одним із дуже помітних і значущих, Донецький національний технічний університет так само веде свої дослідження у сфері семантичного аналізу природно-мовних висловлювань. Однією з найбільш помітних, є робота Лук'яненко С.А., Безсонової А.В. і Казакової Є.І. Згідно з їх дослідженням, природна мова містить всі засоби для вираження алгоритмів і всіляких даних при їх машинної обробці. Але в силу того, що природна мова складається зі словника і граматики – будь-яка автоматизована система обробки природно-мовних повідомлень повинна мати у своєму складі «засоби граматичної обробки» і «засоби словникової (семантичної) обробки» [12] .
Системи подібного роду прийнято називати інтелектуальним інтерфейсом.Средства граматичної обробки природної мови є формалізований набір правил граматики російської мови. Але так як зміна слів не завжди вкладається в рамки регулярності, то формалізованої може бути не вся граматика [10]. Формалізований набір може бути не повним також і через недостатню науковості граматики. Таким чином, всі невраховані правила можна вважати неприпустимими.
При формалізації словника найбільш прийнятною є поуровневом обробка лексичних одиниць. Для кожної предметної області має бути визначений словник вихідних (непохідних) лексичних одиниць (нижній рівень), за допомогою якого і з використанням інформації про наявні афіксах можна обчислювати семантику будь-якого похідного слова, при цьому, також, засобами системи можна отримувати нові похідні слова, маючи їх семантичне відображення.
Отже, будь-який вид машинної обробки природної мови повідомлень включає в себе обробку окремих лексичних одиниць. У свою чергу, обробка окремих слів – обробка складових слово частин: кореня і афіксальних частин.
Схема обробки текстів новин
Всі системи вилучення інформації використовують багато в чому східні методи. Звернемося до типової послідовності обробки тексту в задачах вилучення інформації.
Оригінальний текст піддається графематічному аналізу; відбувається виділення слів і пропозицій. На наступних етапах відбувається виявлення складних слів, які повинні розглядатися як один (з точки зору морфологічного аналізатора). Графематічній аналіз зазвичай не вимагає настройки, залежить від предметної області, оскільки реалізація алгоритму графематічного аналізу підходить для більшості реальних програм
Морфологічний аналіз зазвичай працює на рівні окремих слів (можливо, складових) і повертає морфологічні атрибути даного слова. У випадку, коли атрибути не можуть бути встановлені однозначно, повертається кілька можливих варіантів морфологічного аналізу.
Результати морфологічного аналізу використовуються при мікро-і макросінтаксічному аналізі. Мікросінтаксічній аналіз здійснює побудову обмеженого набору синтаксичних зв'язків (наприклад, виділення іменних груп). Завдання макросінтаксічного аналізу полягає у виділенні в пропозиції великих синтаксичних одиниць – фрагментів, і в становленні ієрархії на безлічі цих фрагментів. Розбивка на мікро-і макросінтаксічній аналіз умовно, воно відображає той факт, що для більшості завдань вилучення інформації досить поверхневого (мікросінтаксічного аналізу).
Експерименти показують, що лінгвістичний аналізатор, що володів багатими виразними можливостями, дає більше помилок через те, що майже кожен рівень аналізу являє собою задачу, що не строгого, а тим більше формалізованого рішення. Найбільшою мірою це відноситься до синтаксичного аналізу. Тому в предметній області, де достатньо простого синтаксичного аналізу, потужний аналізатор буде лише вносити небажаний шум, а продуктивність буде падати. Оскільки предметна область звужена від витяг структурованих даних з текстів будь-яких новин у витягу структурованих даних з текстів наукових новин в області пошуку сенсу тексту.
Оскільки у кожного слова після виконання морфологічного аналізу може бути присутнім кілька омонімічних словоформ, то для поліпшення якості синтаксичного аналізу та підвищення його продуктивності можна використовувати алгоритми усунення омонімії, які скорочують кількість варіантів морфологічного аналізу. Часто завдання зняття омонімії вирішується за допомогою наборів правил, складання яких вельми трудомістка, оскільки практично застосовані набори виявляються досить великими [11].
Надалі відбувається виділення семантичних класів (складових типів). При виділенні складових типів здійснюється позначка фрагментів тексту, які пізніше (наприклад, при застосуванні правил) розглядаються як єдине ціле (наприклад, дати, імена, посади). Виділення семантичних класів здійснюється на основі тезаурусів або правил, подібних правилами добування інформації. Потім здійснюється застосування правил добування інформації до тексту. При виконанні умов і обмежень, описаних в правилах, виконується функціональна частина правил. Функціональна частина дозволяє будувати цільові структури даних або зберігати додаткову інформацію, яка буде використана на наступних етапах. Найчастіше правила групуються по фазах: правила наступних фаз мають доступ до інформації, породженої правилами попередніх.
Цільові фрейми можуть бути піддані додатковій обробці з метою підвищення якості роботи системи. Для цього використовуються засоби дозволу кореферентності та об'єднання часткових результатів. При вирішенні кореферентності в цільових фреймах особливим чином позначаються об'єкти, які описуються різними фрагментами тексту, але вказують на одну сутність реального світу. Об'єднання приватних полягає в пошуку частково заповнених цільових фреймів та прийнятті рішення про можливість об'єднання результатів. У випадку, коли об'єднання можливо, з декількох цільових фреймів збирається один, що володіє більш повною інформацією, ніж будь-який з вихідних. Об'єднання часткових результатів не має спільного рішення, як і ряд перелічених вище проблем, а вимагає настройки на предметну область. Алгоритми побудови правил об'єднання часткових результатів часто схожі з алгоритмами побудови правил вилучення інформації.
Таким чином ми бачимо, що для вилучення інформації з текстів наукових статей в області пошуку сенсу в тексті, можна використовувати типові алгоритми витяг структурованих даних з текстів новин.
Видобуток
структурованої інформації з текстів статей наукових
новин
Для витяг структурованої інформації з текстів статей наукових новин буде використовуватися технологія текстомайнінгу.
Текстомайнінг (text mining) часто називають також текстовим датамайнінгом (text data mining), частково розкриває взаємозв'язок двох цих технологій. Якщо датамайнінг дозволяє витягувати нові знання (приховані закономірності, факти, невідомі взаємозв'язку і т.п.) з великих обсягів структурованої інформації (збереженої в базах даних), то текстомайнінг – знаходити нові знання в неструктурованих текстових масивах.
У цьому сенсі текстомайнінг додає до технології датамайнінга додатковий етап – переклад неструктурованих текстових масивів у структуровані. Після чого дані можуть оброблятися за допомогою стандартних методів датамайнігнга.
Найбільш простим завданням є текстомайнінг слабоструктурованих вузькоспеціалізованих текстових масивів (різні звіти про поломки, результати опитувань і т.п.). У текстових масивах, де форма документа і набір лексики обмежені, нову інформацію можна отримати, аналізуючи статистику на рівні окремих ключових слів (термінів). Коли ми говоримо про неструктуровані тексти, то в загальному вигляді задача зводиться до «розуміння» довільних текстів на природній мові – це одна з найстаріших задач штучного інтелекту (ШІ), яка може вирішуватися з використанням різних технологій, в першу чергу на базі методів обробки даних на природній мові – NLP (Natural Language Processing) на основі нейромережевих підходів, а також інших методів і їх комбінацій.
Величезна кількість інформації накопичується в численних текстових базах зберігаються в особистих ПК, локальних і глобальних мережах. І обсяг цієї інформації стрімко збільшується. Читання об'ємних текстів і пошук в гігантських масивах текстових даних малоефективні, тому стають все більш затребуваними рішення текстомайнінга [4].
Актуальність текстомайнінга зростає в міру того, як людям найрізноманітніших професій доводиться приймати рішення на основі аналізу великого обсягу неструктурованих і слабоструктурованих текстів.
Все більш цікавим стає аналіз громадської думки, вираженого в Web. Останнім часом блогосфера демонструє практично трикратне щорічне зростання. Одним з нових напрямків текстомайнінга є Opinion Mining (OM) (буквально – розкоп думок) – технологія, яка концентрується не стільки на зміст документа, скільки на думці, що він виражає.
Оцінити успішність проведеної рекламної кампанії, дізнатися, як до фірми відносяться в пресі. На ці та інші питання можна отримати відповідь за допомогою технології Opinion Mining.
Умовно систему текстомайнінга можна розділити на чотири блоки (рис. 3). Нижній блок об'єднує технології вилучення та фільтрації надходять на обробку текстів. Блок над ним відповідає за «розуміння» текстів на природній мові.
У наступному блоці перерахований набір необхідних користувачеві задач, кожна з яких вимагає свого технологічного рішення. У загальному випадку набір цих завдань може бути досить широким. До них слід віднести:
- - Класифікацію;
- - Кластеризація;
- - Побудова семантичних мереж;
- - Витяг фактів, понять (feature extraction)
- - Виписка думок;
- - Анотування, суммарізація (summarization);
- - відповідь на запит (question answering);
- - Тематичне індексування (thematic indexing);
- - Пошук за ключовими словами (keyword searching);
- - Створення таксономії і тезаурусів.
Останній блок об'єднує кошти, що формують графічний інтерфейс, і є важливим компонентом системи. Представлена належним чином інформація дозволяє людині побачити ті додаткові приховані закономірності, які не вдається виявити іншими методами.
В даний час пропонується досить багато інструментів текстомайнінга – від відносно простих програм, що спираються на статистичний аналіз окремих термінів у текстах, таких як WordStat, в складних програм типу Aerotext і Businessobjects Text Analysis.
З розвитком Інтернету аналіз, заснований на технологіях текстомайнінга, може реалізовуватися не тільки за допомогою впроваджуваних в організації програм, але і у вигляді онлайнового сервісу. Останнім часом текстомайнінговій аналіз множинних відкритих джерел інформації стає доступним для комерційних, політичних та інших організацій за рахунок появи саме таких онлайнових служб.
Короткий виклад власних результатів
На основі проведеного аналізу для подальшої розробки методів і алгоритмів розглядається визначення біграм на матеріалі наукових текстів з вилучення даних з текстів. Результати отримані в результаті такої обробки послужать основою для подальшої розробки алгоритму отримання даних їхніх текстів новстей наукового стилю в області вилучення даних з текстів.
Висновок
Необхідність автоматичного вилучення структурованих даних з текстів статей наукових новин є важливою частиною проблеми дослідження систем вилучення інформації, яка все ще залишається не повністю решенной.Данное дослідження має цінність для області вилучення даних, як з наукових текстів, так текстів інших предметних областей.
Описана в цій роботі архітектура коштів вилучення інформації дозволяє істотно полегшити рішення задач вилучення інформації з текстів новин наукового характеру. Запропонована архітектура дозволяє вносити нові засоби без порушення функціональності існуючих. Роботу можна продовжити створюючи інструментальні засоби витяг структурованої інформації з текстів новин наукового характеру в області пошуку сенсу в тексті, розширюючи алгоритми й архітектуру для використання системи для вилучення структурованої інформації з текстів будь-яких новин.
У майбутньому використання системи вилучення структурованих даних з текстів новин наукового характеру можливо при створенні тематичного інформаційного порталу.
Перелік посилань
1. Кормалев Д. А. Архитектура инструментальных средств систем извлечения информации из текстов / Д. А. Кормалев, Е. П. Куршев, Е. А. Сулейманова, И. В. Трофимов // Программные системы: теория и приложения. – 2004. – T.1, №3. – С. 49-68.
2. Кормалев Д. A. Приложения технологии извлечения информации из текстов: теория и практика / Д. А. Кормалев, Е. П. Куршев, Е. А. Сулейманова, И. В. Трофимов // Прикладная и компьютерная математика. – 2003. – Т. 2, №1. – С. 118-125.
3. Брик А. В. Исследование и разработка вероятностных методов синтаксического анализа текста на естественном языке: дис. канд. тех. наук: 07.03.02; защищена 25.01.02; утв. 17.03.02 МГТУ им. Н. Э. Баумана. – 2002. – 213 с.
4.Беленький. А.К. Текстомайнинг. Извлечение информации из неструктурированных текстов // КомпьютерПресс. –2008. – Т.2, №10. – С. 43-64.
5. Андреев А.М. Модель извлечения фактов из естественно-языковых текстов и метод ее обучения / А.М. Андреев, Д.В. Березкин, К.В. Симаков // КомпьютерПресс. – 2008. – Т.2, №4. – С. 32-43.
6. Толпегин. И.В. Информационные технологии анализа русских естественно-языковых текстов// Программные системы: теория и приложения. – 2006. – Т.2, №4. – С. 17-32.
7. Сокирко А.В. Графематический анализ. – СПб.: ПИТЕР, 2001. – 201 с.
8. Riloff E.Information Extraction as a Stepping Stone toward Story Understanding // Montreal, Canada: MIT Press – 1999. – №5(2). – P. 32-53.
9. Nahm U. Y., Mooney R. J.Mining Soft-Matching Rules from Textual Data // IJCAI. – 2001. – №10(2). – P. 979-986.
10. Appelt D. E., Israel D. Introduction to information extraction technology // IJCAI: tutorial. – 1999. – №2(5). – P. 136-156.
11. Huffman S. B.Learning information extraction patterns from examples// Learning for Natural Language Processing. – 1995. – №4(6). – P. 246-260.
12. Лукьяненко С.А.
Моделирование семантики естественно-языковых высказываний в
автоматизированных информационных cистемах [Электронный ресурс].
– Режим
доступа:
http://masters.donntu.ru/2006/fema/lukyanenko/library/art03.htm