
Реферат по теме выпускной работы
- Цели и задачи
- Актуальность темы
- Предполагаемая научная новизна
- Планируемые практические результаты
- Обзор исследований и разработок по теме
- Обзор исследований и разработок по теме. Глобальный уровень
- Обзор исследований и разработок по теме. Национальный уровень
- Обзор исследований и разработок по теме. Локальный уровень
- Краткое изложение собственных результатов
- Выводы
- Список источников
Цели и задачи
Основнной целью данной магистерской работы является разработка метода и алгоритмы извлечения структурированных данных из текстов новостей научного стиля в области извлечения данных.
Актуальность темы
Задача разработки информационных порталов знаний является одной из самых актуальных на сегодняшний день. Порталы обеспечивают сведение ресурсов, относящихся к одной области знаний в единое информационное пространство, обеспечивают возможность открытого и удобного доступа к ним, а также автоматизируют оперативный сбор и индексацию новой информации, поступающей в текстовом неструктурированном виде.
Большой объем накопленной информации и высокая скорость поступление новой предъявляют все более жесткие требования к современным информационным порталам. Во-первых, в постоянно разрастающихся массивах данных становится трудно (практически невозможно) найти нужную информацию; во-вторых, данные часто дублируются и противоречат друг другу. Для решения этих проблем необходим переход на новый качественный уровень при обработке информации – необходимо вести обработку на семантическом уровне, т.е. учитывать смысл или содержание поступающих документов. Такая обработка обеспечивается системами автоматического анализа текста на естественном языке, использующими лингвистический подход.
Данная работа призвана обеспечить новые метод и алгоритм извлечения структурированных данных, ориентированные на работу в ограниченной предметной и проблемной области, обеспечивающий извлечение даннх из научных текстов в области извлечения данных из текстов.
Результаты работы данного метода можно будет использовать для наполнения тематического информационного или новостного портала.
Предпологаемая научная новизна
В данной магистерской работе будет либо разработан новый метод и алгоритм извлечения структурирования данных, либо усовершенствован существующий, применительно к извлечению структурированных данных из текстов новостей научного стиля в области извлечения данных.
Планируемые практические результаты
В качестве планируемых результатов ожидается метод и алгоритм извлечения структуррированных данных из текстов новостей научного стиля в области извлечения данных, который можно будет применить к системе извлечения инфромации для создания электронных учебников, наполнения информационных и новостных порталов, создания тематических сайтов.
Обзор исследований и разработок по теме. Глобальный уровень
Анализ требований к системам извлечения информаций
Автоматическая обработка текста на естественном языке позволяет облегчить поиск и извлечение информации с целью дальнейшей аналитической обработки. Чаще всего требуется анализ больших массивов коротких текстов (например, новостей) с целью выделения значимой информации. В качестве такой информации может выступать описание какого-то события, его действующие лица, локализация в пространстве и времени [1].
Системы извлечения информации осуществляют обработку текста на разных уровнях:
- а) первичная фильтрация документа;
- б) лингвистическая обработка:
- 1) графематика;
- 2) морфология;
- 3) синтаксис;
- в) выделение простейших семантических структур;
- г) собственно извлечение информации;
- д) объединение построенных структур;
- е) разрешение анафоры и кореферентности.
В идеале система извлечения информации должна быть независимой от языка и предоставлять возможность настройки на любой естественный язык. Однако в данной работе речь пойдет в первую очередь об обработке текстов на русском языке [2].
Инструментальные средства необходимые для реализации систем извлчения информации должны обеспечивать [3]:
- а) минимально необходимый набор стандартных функций лингвистической обработки;
- б) возможность замещения модулей и настройки порядка их применения;
- в) стандартные средства отладочных ввода-вывода;
- г) поддержание некоторого языка описания правил извлечения информации.
Понятно, что нельзя закладывать в качестве основных требований, например, средства разрешения кореферентности или объединение построенных структур. Подобные задачи имеют множество решений, каждое из которых лучше подходит к той или иной предметной области. В частности, эксперименты с подходом к решению анафоры, обнаружили, что набор атрибутов (весовых коэффициентов), которые указывают значимость каждого из возможных антецедентов, должен настраиваться индивидуально для каждой предметной области, а для некоторых предметных областей такой подход применяется лишь с очень значительными ограничениями.
Разработка целостной системы инструментальных средств требует единого подхода. Множество видов и этапов обработки текста может создать впечатление, что невозможно выразить лингвистическую информацию и информацию предметной области однообразно, но в действительности это не так [4].
Для успешного извлечения информации из текста система должна иметь некоторую дополнительную информацию, которая не присутствует в тексте в явном виде. Речь идет о набор атрибутов, приписанных фрагментам текста: морфологических, синтаксических, лексических, семантических и т. п. Для получения этой дополнительной информации о тексте производятся различные виды анализа текста. Анализ носит многоуровневый характер, поэтому можно считать, что лингвистический процессор состоит из набора анализаторов. Каждый анализатор исследует одну из лингвистических характеристик текста. Как правило, следующие уровни анализа текста используют результаты, полученные на предыдущих этапах. Применение правил извлечения информации не является последним этапом, который стоит отдельно, и мы рассматриваем его как часть прикладного семантического анализа [5].
Модель системы извлечения информации
Существует два основных подхода к представлению информации о тексте: ссылочный и аддитивный. Аддитивный подход подразумевает модификацию исходного текста с добавлением в него специальных служебных символов (вариант такого подхода использования языка разметки XML). Преимущество такого подхода в том, что текст после обработки может быть сохранен, и в дальнейшем всю полученную информацию можно восстановить без повторной обработки [6]. Недостатками этого метода является необходимость модификации текста и пониженная, по сравнению с ссылочным подходом, производительность. Ссылочный подход предлагает хранения информации о тексте отдельно от самого текста и привязку к тексту с использованием ссылок. Производительность здесь, как правило, выше, но возникает необходимость поддержки специальных структур данных. В ссылочном подходе можно выделить два направления:
- а) создание фиксированной объектной модели текста, что приемлемо для конечных программ обработки текста (однако при попытке обобщения сказывается нестабильность такой модели);
- б) создание унифицированного подхода, например, использование модели аннотаций, о которой рассказано ниже.
Процесс получения дополнительной информации при анализе текста будем называть аннотированием. Любая лингвистическая (и другая) информация о тексте представляется в виде аннотации. Аннотация сопоставляется с фрагментом текста, и принадлежит классу аннотаций и имеет атрибуты. Класс аннотаций - это строка, позволяющая разбить все аннотации на смысловые группы. Для сравнения аннотации и фрагмента текста используется начало и длина (или начало и конец) фрагмента текста, к которому приписана аннотация. Атрибуты аннотаций есть пара <имя, значение>. В классическом подходе считается, что имена атрибутов уникальные, а значение представляют собой строки, поэтому каждая аннотация может содержать только одно значение каждого атрибута. При практической реализации часто требуется представлять множественные атрибуты, в этом случае пользуются одним из двух способов:
- а) создание необходимого количества аннотаций, содержащих только атомарные значения атрибутов;
- б) использование некоторого способа кодирования информации для случая, когда в атрибуте нужно сохранить составленное сложное значение (например, введение специального символа-разделителя).
Надо заметить, что различные модули системы могут использоваться как один, так и другой способ. Второй способ является более универсальным, поскольку модули, поддерживающие его, смогут проанализировать аннотации, созданные модулями, поддерживающими первый способ (обратной совместимости нет). При практической реализации мы следовали в основном вторым способом.
Проблемы при использовании
первого способа можно
проиллюстрировать следующим примером [1].
Пусть
аннотация 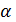 владеет
множеством атрибутов описанной формуле (1)
владеет
множеством атрибутов описанной формуле (1)
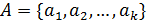 ,
(1)
,
(1)
где 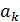 –
определенный атрибут множества атрибутов
–
определенный атрибут множества атрибутов 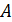 ,
для каждого из
которых, в свою очередь определен набор из
,
для каждого из
которых, в свою очередь определен набор из 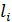 ,
описанный в формуле
(2)
,
описанный в формуле
(2)
 ,
(2)
,
(2)
где 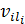 –
определенное значение атрибута из набора его значений
–
определенное значение атрибута из набора его значений 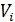 .
.
Тогда при классическом подходя к выражению вариативности каждая
аннотация
должна быть преобразована к виду представленному в формуле (3)
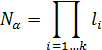 ,
(3)
,
(3)
Где 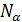 –
количество аннотаций, а – значения атрибутов.
–
количество аннотаций, а – значения атрибутов.
Обзор исследований и разработок по теме. Национальный уровень
Среди украинских ученых наиболее значимый вклад в разработку методов и алгоритмов извлечения информации из текста новостей сделан Сокирко А.В. Некоторые работы Гладуна В.П. также имеют косвенное отношение к данной тематике. Сокирко А.В. в своей работе «Графематический анализ» [7] указывает на преимущества использования именно этого анализотора для систем извлечения информации.
Правила и встроенные средства систем извлечение информации
Система применения правил занимается различными видами лингвистического анализа. Она дает возможность быстро выполнять разработку новых уровней анализа. Кроме того, правила предоставляют большую гибкость системе благодаря тому, что модификация правил выполняется существенно легче, чем модификация кода лингвистического процессора [7]. Однако вычислительная эффективность анализа, построенного на правилах, ниже, чем у кода лингвистического процессора.
Поэтому правила применять не всегда целесообразно. Разделение функций между лингвистическим процессором и системой правил проводится по критерию гибкость/эффективность. Лингвистический процессор не обладает большой гибкостью, но имеет высокую производительность кода. Система правил более медленная, но легко поддается модификации.
Система составления фрейма осуществляет поиск в тексте аннотаций определенного вида, которые связаны с целевой информацией. Так как фрейм – это многослотовая структура, нужно уметь различать целевую информацию, относящуюся к одному фрейму и в разных. Эту функцию осуществляет подсистема сбора фрейма.
Архитектура систем извлечения информации
Несмотря на то, что системы извлечения информации могут строиться для выполнения различных задач, порой сильно отличающихся друг от друга друг от друга, существуют компоненты, которые можно выделить практически в каждой системе.
В состав почти каждой системы извлечения информации входят четыре основные компонента (см. рис. 1), а именно: компонент разбиения на лексемы, некоторый тип лексического или морфологического анализа, синтаксический анализ (микро-и макроуровень), модуль извлечение информации и модуль для анализа на уровне конкретной предметной области [8].
В зависимости от требований к конкретному программному продукту, в приведенную выше схему добавляют дополнительные модули анализа (специальная обработка сложных слов; устранения омонимии, выделение составных типов, что может также быть реализован язык правил извлечения информации, объединения частичных результатов).
Разбивка на слова при анализе европейских языков не является проблемой, поскольку слова отделяются друг от друга пробелом (или знаками препинания). Тем не менее, для обработки сложных слов, аббревиатур, буквенно-цифровых комплексов и ряда других особых случаев требуются специфические алгоритмы. С границами предложений, как правило, тоже больших проблем не возникает. Однако при анализе таких языков, как японский или китайский, определения границ слова на основе орфографии невозможно. По этой причине системы извлечения информации, работающих с такими языками, должны быть дополнены модулем сегментации текста на слова [9].
В некоторые системы наряду с обычными средствами лексического и морфологического анализа могут быть включены модули для определения и категоризации атрибутов частей речи, смысловых нагрузок слов, имен или других нетривиальных лексических единиц.
Рисуннок 1 – Архитектура системы извлечения информации.
Для многих предметных областей элементарный синтаксический анализ (например, выделение именных групп) может быть достаточным для определения грамматической основы предложения, а также его основных частей, но в некоторых случаях может понадобиться расширенный или даже полный синтаксический анализ.
Существуют различные методы первичного извлечения информации. В одних используются регулярные выражения «в чистом виде», в других методах пользуются простыми правилами на основе регулярных выражений, также существует подход с использованием специальных правил на основе целевых слотов и ограничений. Однако задача всех этих методов заключается в извлечении релевантной информации в локальном контексте, глобализация которого является задачей анализа на уровне предметной области.
Вполне возможно создание системы, которая не решает проблемы кореферентности и не объединяет целевые слоты, выделенные из различных предложений, в единый целевой фрейм. Однако во многих случаях включение модулей для решения этих проблем существенно повышает эффективность всей системы в целом.
Обзор исследований и разработок по теме. Локальный уровень
Являясь одним из весьма заметных и значимых, Донецкий национальный технический университет так же ведет свои исследования в сфере семантического анализа естественно-языковых высказываний. Одной из наиболее заметных, является работа Лукьяненко С.А., Бессоновой А.В. и Казаковой Е.И. Согласно их исследованиям, естественный язык содержит все средства для выражения алгоритмов и всевозможных данных при их машинной обработке. Но в силу того, что естественный язык состоит из словаря и грамматики – любая автоматизированная система обработки естественно-языковых сообщений должна иметь в своем составе «средства грамматической обработки» и «средства словарной (семантической) обработки» [12].
Системы подобного рода принято называть интеллектуальным интерфейсом.Средства грамматической обработки естественного языка представляют собой формализованный набор правил грамматики русского языка. Но так как изменение слов не всегда вкладывается в рамки регулярности, то формализованной может быть не вся грамматика [10]. Формализованный набор может быть не полным также и из-за недостаточной научности грамматики. Таким образом, все неучтенные правила можно считать недопустимыми.
При формализации словаря наиболее приемлемой является поуровневая обработка лексических единиц. Для каждой предметной области должен быть определен словарь исходных (непроизводных) лексических единиц (нижний уровень), посредством которого и с использованием информации об имеющихся аффиксах можно исчислять семантику любого производного слова, при этом, также, средствами системы можно получать новые производные слова, имея их семантическое отображение.
Итак, любой вид машинной обработки естественного языка сообщений включает в себя обработку отдельных лексических единиц. В свою очередь, обработка отдельных слов – обработка составляющих слово частей: корня и аффиксальных частей.
Схема обработки текстов новостей
Все системы извлечение информации используют во многом восточные методы. Обратимся к типовой последовательности обработки текста в задачах извлечение информации.
Исходный текст подвергается графематичному анализа; происходит выделение слов и предложений. На последующих этапах происходит выявление сложных слов, которые должны рассматриваться как одно (с точки зрения морфологического анализатора). Графематичний анализ обычно не требует настройки, зависит от предметной области, поскольку реализация алгоритма графематичного анализа подходит для большинства реальных программ
Морфологический анализ обычно работает на уровне отдельных слов (возможно, составляющих) и возвращает морфологические атрибуты данного слова. В случае, когда атрибуты не могут быть установлены однозначно, возвращается несколько возможных вариантов морфологического анализа.
Результаты морфологического анализа используются при микро-и макросинтаксичному анализе. Микросинтаксичний анализ осуществляет построение ограниченного набора синтаксических связей (например, выделение именных групп). Задача макросинтаксичного анализа заключается в выделении в предложении крупных синтаксических единиц – фрагментов, и в становлении иерархии на множестве этих фрагментов. Разбивка на микро- и макросинтаксичний анализ условно, оно отражает тот факт, что для большинства задач извлечения информации достаточно поверхностного (микросинтаксичного анализа).
Эксперименты показывают, что лингвистический анализатор, обладавший богатыми выразительными возможностями, дает больше ошибок из-за того, что почти каждый уровень анализа представляет собой задачу, что не строгого, а тем более формализованного решения. В наибольшей степени это относится к синтаксического анализа. Поэтому в предметной области, где достаточно простого синтаксического анализа, мощный анализатор будет лишь вносить нежелательный шум, а производительность будет падать. Поскольку предметная область сужена от извлечение структурированных данных из текстов любых новостей в извлечении структурированных данных из текстов научных новостей в области поиска смысла текста.
Поскольку у каждого слова после выполнения морфологического анализа может присутствовать несколько омонимичных словоформ, то для улучшения качества синтаксического анализа и повышения его производительности можно использовать алгоритмы устранения омонимии, которые сокращают количество вариантов морфологического анализа. Часто задача снятия омонимии решается с помощью наборов правил, составление которых весьма трудоемкое, поскольку практически применены наборы оказываются достаточно большими [11].
В дальнейшем происходит выделение семантических классов (составных типов). При выделении составных типов осуществляется пометка фрагментов текста, которые позже (например, при применении правил) рассматриваются как единое целое (например, даты, имена, должности). Выделение семантических классов осуществляется на основе тезаурусов или правил, подобных правилам извлечения информации. Затем осуществляется применение правил извлечения информации к тексту. При выполнении условий и ограничений, описанных в правилах, выполняется функциональная часть правил. Функциональная часть позволяет строить целевые структуры данных или хранить дополнительную информацию, которая будет использована на последующих этапах. Чаще правила группируются по фазам: правила следующих фаз имеют доступ к информации, порожденной правилами предыдущих.
Целевые фреймы могут быть подвергнуты дополнительной обработке с целью повышения качества работы системы. Для этого используются средства разрешения кореферентности и объединения частичных результатов. При решении кореферентности в целевых фреймах особым образом обозначаются объекты, которые описываются различными фрагментами текста, но указывают на одну сущность реального мира. Объединение частных заключается в поиске частично заполненных целевых фреймов и принятии решения о возможности объединения результатов. В случае, когда объединение возможно, из нескольких целевых фреймов собирается один, обладающий более полной информацией, чем любой из выходных. Объединение частичных результатов не имеет общего решения, как и ряд вышеперечисленных проблем, а требует настройки на предметную область. Алгоритмы построения правил объединения частичных результатов часто схожи с алгоритмами построения правил извлечение информации.
Таким образом мы видим, что для извлечение информации из текстов научных статей в области поиска смысла в тексте, можно использовать типовые алгоритмы извлечение структурированных данных из текстов новостей.
Извлечение структурированной информации из текстов статей научных новостей
Для извлечение структурированной информации из текстов статей научных новостей будет использоваться технология текстомайнингу.
Текстомайнинг (text mining) часто называют также текстовым датамайнингом (text data mining), частично раскрывает взаимосвязь двух этих технологий. Если датамайнинг позволяет извлекать новые знания (скрытые закономерности, факты, неизвестные взаимосвязи и т.п.) с больших объемов структурированной информации (хранимой в базах данных), то текстомайнинг – находить новые знания в неструктурированных текстовых массивах.
В этом смысле текстомайнинг добавляет к технологии датамайнинга дополнительный этап - перевод неструктурированных текстовых массивов в структурированы. После чего данные могут обрабатываться с помощью стандартных методов датамайнигнга.
Наиболее простой задачей является текстомайнинг слабоструктурированных узкоспециализированных текстовых массивов (различные отчеты о поломках, результаты опросов и т.п.). В текстовых массивах, где форма документа и набор лексики ограничены, новую информацию можно извлечь, анализируя статистику на уровне отдельных ключевых слов (терминов). Когда мы говорим о неструктурированные тексты, то в общем виде задача сводится к «пониманию» произвольных текстов на естественном языке – это одна из старейших задач искусственного интеллекта (ИИ), которая может решаться с использованием различных технологий, в первую очередь на базе методов обработки данных на естественном языке – NLP (Natural Language Processing) на основе нейросетевых подходов, а также других методов и их комбинаций.
Огромное количество информации накапливается в многочисленных текстовых базах хранятся в личных ПК, локальных и глобальных сетях. И объем этой информации стремительно увеличивается. Чтение объемных текстов и поиск в гигантских массивах текстовых данных малоэффективны, поэтому становятся все более востребованными решения текстомайнинга [4].
Актуальность текстомайнинга возрастает по мере того, как людям самых разных профессий приходится принимать решения на основе анализа большого объема неструктурированных и слабоструктурированных текстов (рис. 2).
Все более интересным становится анализ общественного мнения, выраженного в Web. В последнее время блогосфера демонстрирует практически трехкратное ежегодный рост. Одним из новых направлений текстомайнинга является Opinion Mining (OM) (буквально – раскоп мыслей) – технология, которая концентрируется не столько на содержание документа, сколько на мысли, что он выражает.
Оценить успешность проведенной рекламной кампании, узнать, как к фирме относятся в прессе. На эти и другие вопросы можно получить ответ с помощью технологии Opinion Mining.
Рисунок 2 – Ожидаемое снижение / рост данных различной степени структурированности в ближайшие три года
Условно систему текстомайнинга можно разделить на четыре блока (рис. 3). Нижний блок объединяет технологии извлечения и фильтрации поступают на обработку текстов. Блок над ним отвечает за «понимание» текстов на естественном языке.
В следующем блоке перечисленный набор необходимых пользователю задач, каждая из которых требует своего технологического решения. В общем случае набор этих задач может быть достаточно широким. К ним следует отнести:
- - Классификацию;
- - Кластеризация;
- - Построение семантических сетей;
- - Извлечение фактов, понятий (feature extraction)
- - Выписка мыслей;
- - Аннотирование, суммаризация (summarization);
- - Ответ на запрос (question answering);
- - Тематическое индексирование (thematic indexing);
- - Поиск по ключевым словам (keyword searching);
- - Создание таксономии и тезаурусов.

Рисунок 3 – Структура обобщенной системы текстомайнинга. (Анимация: размер - 104 Кб; количество циклов - 5; количество кадров - 4)
Последний блок объединяет средства, формирующие графический интерфейс, и является важным компонентом системы. Представленая должным образом информация позволяет человеку увидеть те дополнительные скрытые закономерности, которые не удается обнаружить другими методами.
В настоящее время предлагается довольно много инструментов текстомайнинга – от относительно простых программ, опирающихся на статистический анализ отдельных терминов в текстах, таких как WordStat, в сложных программ типа Aerotext и Businessobjects Text Analysis.
С развитием Интернета анализ, основанный на технологиях текстомайнинга, может реализовываться не только с помощью внедряемых в организации программ, но и в виде онлайнового сервиса. В последнее время текстомайнинговий анализ множественных открытых источников информации становится доступным для коммерческих, политических и других организаций за счет появления именно таких онлайновых служб.
Краткое изложение собственный результатов
На основе проведенного анализа для дальнейшей разработки методов и алгоритмов рассматривается определение биграмм на материале научных текстов по извлечению данных из текстов. Результаты полученные в результате такой обработки послужат основой для дальнейшей разработки алгоритма извлечения данных их текстов новстей научного стиля в области извлечения данных из текстов.
Заключение
Необходимость автоматического извлечения структурированных данных из текстов статей научных новостей является важной частью проблемы исследования систем извлечения информации, которая все еще остается не полностью решенной.Данное исследование имеет ценность для области извлечения данных, как из научных текстов, так текстов других предметных областей.
Описанная в этой работе архитектура средств извлечение информации позволяет существенно облегчить решение задач извлечения информации из текстов новостей научного характера. Предложенная архитектура позволяет вносить новые средства без нарушения функциональности существующих. Работу можно продолжить создавая инструментальные средства извлечение структурированной информации из текстов новостей научного характера в области поиска смысла в тексте, расширяя алгоритмы и архитектуру для использования системы для извлечения структурированной информации из текстов любых новостей.
В будущем использование системы извлечения структурированных данных из текстов новостей научного характера возможно при создании тематического информационного портала.
Список источников
1. Кормалев Д. А. Архитектура инструментальных средств систем извлечения информации из текстов / Д. А. Кормалев, Е. П. Куршев, Е. А. Сулейманова, И. В. Трофимов // Программные системы: теория и приложения. – 2004. – T.1, №3. – С. 49-68.
2. Кормалев Д. A. Приложения технологии извлечения информации из текстов: теория и практика / Д. А. Кормалев, Е. П. Куршев, Е. А. Сулейманова, И. В. Трофимов // Прикладная и компьютерная математика. – 2003. – Т. 2, №1. – С. 118-125.
3. Брик А. В. Исследование и разработка вероятностных методов синтаксического анализа текста на естественном языке: дис. канд. тех. наук: 07.03.02; защищена 25.01.02; утв. 17.03.02 МГТУ им. Н. Э. Баумана. – 2002. – 213 с.
4.Беленький. А.К. Текстомайнинг. Извлечение информации из неструктурированных текстов // КомпьютерПресс. –2008. – Т.2, №10. – С. 43-64.
5. Андреев А.М. Модель извлечения фактов из естественно-языковых текстов и метод ее обучения / А.М. Андреев, Д.В. Березкин, К.В. Симаков // КомпьютерПресс. – 2008. – Т.2, №4. – С. 32-43.
6. Толпегин. И.В. Информационные технологии анализа русских естественно-языковых текстов// Программные системы: теория и приложения. – 2006. – Т.2, №4. – С. 17-32.
7. Сокирко А.В. Графематический анализ. – СПб.: ПИТЕР, 2001. – 201 с.
8. Riloff E.Information Extraction as a Stepping Stone toward Story Understanding // Montreal, Canada: MIT Press – 1999. – №5(2). – P. 32-53.
9. Nahm U. Y., Mooney R. J.Mining Soft-Matching Rules from Textual Data // IJCAI. – 2001. – №10(2). – P. 979-986.
10. Appelt D. E., Israel D. Introduction to information extraction technology // IJCAI: tutorial. – 1999. – №2(5). – P. 136-156.
11. Huffman S. B.Learning information extraction patterns from examples// Learning for Natural Language Processing. – 1995. – №4(6). – P. 246-260.
12. Лукьяненко С.А.
Моделирование семантики естественно-языковых высказываний в
автоматизированных информационных cистемах [Электронный ресурс].
– Режим
доступа:
http://masters.donntu.ru/2006/fema/lukyanenko/library/art03.htm