
Abstract
Content
- Goals and Objectives
- The relevance of the research topic
- Expected scientific novelty
- Planned practical results
- A review of research and development on the subject.
- A review of research and development on the subject. Global level
- A review of research and development on the subject. National level
- A summary of the results of their own
- Conclusion
- References
Goals and Objectives
Main purpose of this master's work is to develop methods and algorithms for extracting structured data from text news scientific style of data retrieval.
The relevance of the research topic
Task of developing information knowledge portals,is one of the most relevant today. Portals provide a reduction of resources relating to one area of expertise into a single information space, provide an open and easy access to them, as well as automate the online data collection and indexing new information coming in the form of unstructured text.
Large amount of accumulated information and high-speed flow of new impose more stringent requirements for modern information portals. First, in an ever-proliferating volumes of data becomes difficult (almost impossible) to find the information you need, and secondly, the data often overlap and contradict each other. To solve these problems requires a transition to a new level in the processing of information – is necessary to conduct the processing on the semantic level, so consider the meaning or content of incoming documents. This treatment is provided with automatic text analysis in natural language using linguistic approach.
This work is intended to provide the new method and algorithm for extracting structured data-oriented work in a limited subject matter and the subject area that provides recovery of data from scientific texts in the field of data extraction from texts
The results of this method can be used for thematic content of the information or news portal.
Expected scientific novelty
In this master's work will be developed a new method and algorithm for extracting structured data, or improved, with respect to the extraction of structured data from text news scientific style of data retrieval.
Planned practical results
As expected deliverables method and algorithm for extracting structured data from texts news scientific style of data retrieval that can be applied to the Information retrieval system for creating e-books, content information and news portals, creation thematic websites.
A review of research and development on the subject. Global level
Requirements analysis to systems of information retrieval
Automatic processing of natural language can facilitate the search and retrieval nformation in order to further analytical treatment. Most often require analysis of large arrays in short texts (eg news) in order to highlight important information. As this information may be a description of an event, its actors, the localization in space and time [1] .
Retrieval systems perform text processing on different levels:
- a) the primary filter paper;
- b) linguistic processing:
- c) grafematika;
- d) morphology;
- e) syntax;
- f) selection of simple semantic structures;
- g) the actual retrieval of information;
- h) the association of built structures;
- i) the resolution of anaphora and koreferentnosti.
Ideally retrieval system should be independent of language and provide the ability to customize to any natural language. However, in this paper it will be primarily on the processing of texts in russian [2].
Tools necessary to implement the systems should provide information extraction [3]:
- a) The minimum set of standard functions of linguistic processing;
- b) the ability to replace modules and configure their application;
- c) the standard means of debugging input and output;
- d) the maintenance of a rules description language information retrieval.
Clear that it is impossible to lay as basic requirements, such as funds permit, or the union koreferentnosti built structures. Similar problems have multiple solutions, each of which is better suited to a particular subject area. In particular, experiments with the approach to solving the anaphora, found that a set of attributes (weights), which indicate the importance of each of the possible antecedents must be configured individually for each subject area, and for some subject areas, this approach applies only to a very significant limitations.
Design an integrated system of tools requires a unified approach. Many types and stages of word processing can create the impression that it is impossible to express the linguistic information and the information domain is uniform, but in reality it is not [4].
Successful retrieval of information from the text of the system should have some additional information that is not present in the text explicitly. This is a set of attributes assigned to the fragments of the text: morphological, syntactic, lexical, semantic, etc. For more information on this text, produced different kinds of text analysis. The analysis is multi-level character, so we can assume that the language processor consists of a set of analyzers. Each analyzer examines one of the linguistic characteristics of text. As a rule, the following levels of text analysis using the results obtained in the previous stages. The use of information extraction rules is not the last step, which stands alone, and we consider it as part of the application of semantic analysis [5].
Model of information retrieval system
There are two basic approaches to providing information about the text: a reference and an additive. An additive approach involves modification of the source text with the addition of special service indicators (variant of this approach using a markup language XML). The advantage of this approach is that the text after processing can be saved in the future all information can be recovered without re-processing [6]. The disadvantages of this method is the need to modify the text and reduced, compared with a reference approach performance. Reference approach offers store information about the text separately from the text itself and bind to the text with references. Productivity is usually higher, but there is a need to support special data structures. In the reference approach can be divided into two areas:
- a) the establishment of a fixed object model of the text that is acceptable to the end word processing programs (however, when trying to generalize affects the instability of such a model);
- b) the creation of a unified approach, for example, using a model annotation, of which more later.
Process more information in the analysis of the text is called
annotation. Any linguistic (and other) information about the text
appears in the form of annotations. Abstract compared with a fragment
of text, and the class has attributes and annotations. Class
annotations – a string that allows you to break all the
annotations on
the semantic groups. For comparison, annotation, and a piece of text
using the start and length (or the beginning and end) fragment of the
text, which is attributed to the abstract. The attributes of annotation
is a pair
- a) the establishment of the required number of abstracts that contain only atomic values ??of attributes;
- b) the use of a method of encoding information for the case where the attribute you want to save a complex composed value (for example, the introduction of a special character-separator).
It should be noted that the various modules of the system can be used as one or the other way. The second method is more universal, because the modules that support it will be able to analyze the annotations created by the modules that support the first option (no backwards compatibility). In practical implementation, we followed mainly by the second method.
problems when using the first method can be illustrated by the
following example [1]. Let the abstract 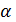 has many attributes
described formula (1)
has many attributes
described formula (1)
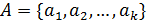 , (1)
, (1)
where 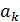 –
specific attribute sets of attributes
–
specific attribute sets of attributes 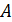 , each of which, in
turn, defines a set of
, each of which, in
turn, defines a set of 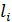 , described in (2)
, described in (2)
 (2)
(2)
where 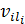 –
some attribute value from the set of its values
–
some attribute value from the set of its values 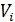 .
.
Then the classical approach to expression variability, each abstract must be transformed
to the form presented in equation (3)
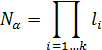 , (3)
, (3)
Where 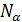 – the
number of annotations, and – attribute values.
– the
number of annotations, and – attribute values.
A review of research and development on the subject. National level
Among Ukrainian scholars the most significant contribution to the develop methods and algorithms for extracting information from text news made Sokirko A. Some of Gladun VP works also have an indirect relation to the subject. Sokirko A. in his work "Grafematichesky Analysis" [7] points to the benefits of using this particular analizator for retrieval systems.
Rules and embedded systems, information retrieval
System of rules deals with various kinds of linguistic analysis. It allows you to quickly complete the development of new levels of analysis. In addition, the rules are more flexible system due to the fact that the modification of the rules is performed substantially better than the modification of the code language processor [7]. However, the computational efficiency of the analysis, which was built on rules, lower than that of the linguistic code of the processor.
Therefore, the rules apply not always appropriate. The division of functions between the linguistic processor and a system of rules is carried out by the flexibility / efficiency. Language processor does not have great flexibility, but has a high-performance code. The system of rules is slower, but can be easily modified.
The system of frame searches in the text of a certain type annotations that are associated with the target information. Since the frame – it bagatoslotovaya structure must be able to distinguish target information related to the same frame and different. This function performs the collection subsystem frame.
Extract information systems architecture
Despite the fact that the information extraction system can be built for different tasks, sometimes greatly differing from each other, there are components that can be identified in virtually every system.
In almost every part of information extraction consists of four main components, namely the component split into tokens, some type of lexical or morphological analysis, syntactic analysis (micro-and macro-level), information retrieval and unit module for analysis at the level of a particular domain [8].
Depending on the requirements of a particular software product, in the above scheme adds additional analysis modules (special processing of compound words, homonyms removal, separation of composite types, which can also be realized by the rules of the language information extraction, combining partial results).
Breakdown on the words in the analysis of European languages ??is not a problem, since the words are separated by a space (or punctuation marks). However, the processing of compound words, abbreviations, alphanumeric systems and some other special cases require specific algorithms. On the borders of the proposals are generally too large there is no problem. However, the analysis of languages such as Japanese or Chinese, the definition of word boundaries based on the spelling impossible. For this reason, information retrieval system, working with such languages ??should be supplemented by a module segmentation of text into words [9].
In some systems, along with the usual tools of lexical and morphological analysis modules can be included to define and categorize the attributes of the parts of speech, meaning loads of words, names or other non-trivial lexical items.
For many domains the elementary syntactic analysis (for example, the allocation of nominal groups) may be sufficient to determine the grammatical basis of the proposal and its key parts, but in some cases may require advanced or even a complete parse.
There are various methods of primary information retrieval. Some regular expressions are used in a "pure form", in other methods use simple rules based on regular expressions, there is also an approach with the use of special regulations on the basis of trust and restrictions on slots. However, the problem of all these methods is to extract the relevant information in the local context, globalization is an objective analysis on the level of the domain.
It is possible to create a system that does not solve the problem koreferentnosti and integrates targeted slots allocated from the various proposals into a single target frame. However, in many cases, the inclusion of modules to address these issues increases the efficiency of the whole system.
A summary of the results of their own
Based on the analysis for the further development of methods and algorithms considered in the determination of bigrams material science texts to extract information from texts. The results obtained by this treatment will serve as the basis for the further development of algorithms to extract data text novstey scientific style of data retrieval from texts.
Conclusion
Need in automatically extract structured data from text of articles scientific news is an important part of the problem of extracting information systems research, which is still not fully reshennoy.Dannoe study has value for the extraction of data from both the scientific texts, the texts of other subject areas.
Described in this paper the architecture of information extraction can significantly ease the tasks of extracting information from texts of news of a scientific nature. The proposed architecture allows you to make new tools without breaking existing functionality. Work can continue creating the tools extract structured information from texts of news of a scientific nature in search of meaning in the text, extending the algorithms and architecture for the system to extract structured information from texts of any news.
In the future, the use of structured data extraction from the texts of news of a scientific nature is possible to create thematic information portal.
References
1. Кормалев Д. А. Архитектура инструментальных средств систем извлечения информации из текстов / Д. А. Кормалев, Е. П. Куршев, Е. А. Сулейманова, И. В. Трофимов // Программные системы: теория и приложения. – 2004. – T.1, №3. – С. 49-68.
2. Кормалев Д. A. Приложения технологии извлечения информации из текстов: теория и практика / Д. А. Кормалев, Е. П. Куршев, Е. А. Сулейманова, И. В. Трофимов // Прикладная и компьютерная математика. – 2003. – Т. 2, №1. – С. 118-125.
3. Брик А. В. Исследование и разработка вероятностных методов синтаксического анализа текста на естественном языке: дис. канд. тех. наук: 07.03.02; защищена 25.01.02; утв. 17.03.02 МГТУ им. Н. Э. Баумана. – 2002. – 213 с.
4.Беленький. А.К. Текстомайнинг. Извлечение информации из неструктурированных текстов // КомпьютерПресс. –2008. – Т.2, №10. – С. 43-64.
5. Андреев А.М. Модель извлечения фактов из естественно-языковых текстов и метод ее обучения / А.М. Андреев, Д.В. Березкин, К.В. Симаков // КомпьютерПресс. – 2008. – Т.2, №4. – С. 32-43.
6. Толпегин. И.В. Информационные технологии анализа русских естественно-языковых текстов// Программные системы: теория и приложения. – 2006. – Т.2, №4. – С. 17-32.
7. Сокирко А.В. Графематический анализ. – СПб.: ПИТЕР, 2001. – 201 с.
8. Riloff E.Information Extraction as a Stepping Stone toward Story Understanding // Montreal, Canada: MIT Press – 1999. – №5(2). – P. 32-53.
9. Nahm U. Y., Mooney R. J.Mining Soft-Matching Rules from Textual Data // IJCAI. – 2001. – №10(2). – P. 979-986.
10. Appelt D. E., Israel D. Introduction to information extraction technology // IJCAI: tutorial. – 1999. – №2(5). – P. 136-156.
11. Huffman S. B.Learning information extraction patterns from examples// Learning for Natural Language Processing. – 1995. – №4(6). – P. 246-260.
12. Лукьяненко С.А.
Моделирование семантики естественно-языковых высказываний в
автоматизированных информационных cистемах [Электронный ресурс].
– Режим
доступа:
http://masters.donntu.ru/2006/fema/lukyanenko/library/art03.htm