
Abstract
Content
- Introduction
- 1. The problem of training samples with many factors
- 2. Overview of Research and Development
- 2.1 Types of treatment Dunns
- 2.2 Methods for data compression
- 2.3 Algorithm STOLP
- 3. Analysis of the construction and optimization weighted training samples with the set of weighting coefficients
- Conclusions
- References
Introduction
Yet until recently, the problem of recognizing a person considered only from the perspective of qualitative characteristics, which were based on a study of receptors, such as the organs of sight, hearing, touch. Mathematical evaluation of the decision was not performed. But, recently introduced, cybernetics allowed to carry out the method of mathematical analysis, which will open up new possibilities in the study and design of automatic recognition systems. This allows you to replace a human specialized machine. Such substitution can significantly extend the capabilities of systems that make complex information and logic problems. After all, the quality of work performed by a person, is highly dependent on the human factor. In automated systems, the human factor is absent, which helps prevent many errors which could occur in manual systems.
For quite some time, the problem of recognition continues to attract the attention of experts in various scientific fields. There is growing and new algorithms for training samples in recognition systems. But not all algorithms give equally good results. Information on the change of recognizable objects enters the system of recognition in most cases in the form of new objects of the training sample, the number of which can reach tens of thousands, so the adaptive one of the key problems is the problem of preprocessing raw data samples [1]. That is why the optimization of these algorithms is one of the priority areas of data analysis in adaptive recognition systems.
1. The problem of training samples with many factors
In memory of the machine to store information about all implementations of the training set [2]. But if you reduce the sample with standards and store only part of the sample, this will greatly simplify the recognition. For example, as to leave only the reference point at which the distance from any point on the learning sample to the nearest standard, less than the distance to the nearest reference another class. But in this case there is a chance encounter with a situation in which the solution of the problem is possible only in the case of a brute force attack. If the number of objects in the sample is k, the number of checks in the training set is mi, and the number of all possible variants for a reference power for each k the sum of all k from the initial to the last object of the sample. It is obvious that the problem in this case is a combinatorial nature and is difficult to solve. To simplify this task, there are a number of algorithms that will be discussed below.
2. Overview of Research and Development
2.1 Types of treatment Dunns
Pretreatment data recognition systems is an iterative process that involves data cleansing, data compression, and data integration. Data cleaning is the removal of noise, missing data and data of poor quality.
Data compression involves finding the minimum feature space and representative data set based on the methods of reduction and transformation. Combining data allows us to reduce the amount of data preserving the original data using heuristic algorithms.
2.2 Methods for data compression
Urgent task is to compress the data, because it reduces the amount of data while preserving the original information. There are several methods that allow you to do it.
The first method is the selection of a set of objects of the original training set, each object which must meet the requirements.
Second method differs from the first in that it uses a different method of selecting objects, while using distance and an optimality criterion for the resulting sample. It consists in the construction of many new objects of samples that are based on the information on a subset of objects of the original sample.
For the first method uses the algorithms STOLP, FRiS-STOLP, NNDE (Nearest Neighbor Density Estimate) and MDCA (Multiscale Data CondensationAlgorithm). By the algorithms that implement the second method includes algorithms for LVQ (learning vector quantization), the algorithm clearly gorazbieniya feature space, the algorithm GridDC, a method of constructing a network of weighted samples w-objects.
2.3 Algorithm STOLP
to split the entire set of objects for reference, noise (emissions) and uninformative objects, use an algorithm STOLP. Standards for the algorithm are a subset of the sample, in which all objects are classified correctly using the training sample set of standards. The algorithm looks like a set of sequential actions. Initially there is training sample:
where x i - objects, y i = y * (x i ) - classes that belong to these objects. Furthermore, given the metric p X × X → R, so that the following hypothesis compactness.
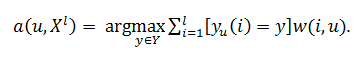
necessary to calculate the distance from the classified object to all objects of the training sample. The algorithm will look like:
STOLP example of the algorithm is shown in image 2. As originally selected reference points 1 and 2. But after a trial recognition of all points of the learning sample list of standards supplemented points 3, 4, 5.

As a result, a set of objects classified by reference, uninformative and emissions. However, the algorithm has not STOLP high efficiency. This is due to the fact that for each new iteration (when joining the next standard) need to re-classify all objects that can become standards. To do this, gently consider the amount of risk to them.
3. Analysis of construction and optimization of weighted training samples from a variety of weights
analysis of building optimization weighted training samples with multiple weights in adaptive recognition systems showed the following characteristics of the stages of building systems. The first step is the definition of attributes of the objects. Is to determine the full set of features that characterize the objects or phenomena for which the recognition system is developed. Initially, you must identify all the signs, even in the slightest degree describing objects or phenomena.
Next, you need to make a priori alphabet classes. The key to this problem is to choose the correct classification of the principle of satisfying the requirements of the classification system. In solving the following problems of a priori alphabet classes formed the working classes of the alphabet.
Development priori dictionary of signs is to develop priori dictionary of signs, which will include only those features for which can be obtained a priori information necessary to describe the classes in the language of these signs. In describing all classes priori alphabet classes in language features included in the dictionary features a priori, the method of teaching, learning, or just processing raw data [3]. Once all the classes have been described priori alphabet, a priori necessary to break feature space into regions corresponding to the classes of classes a priori alphabet.
construction worker alphabet characters and classes is a common approach to the problem of recognition. Its essence lies in the development of the alphabet and the class of the dictionary of attributes, which are the constraints on the construction of the system of recognition provide maximum value of the effectiveness of the recognition of the host, depending on the results of the recognition of unknown objects corresponding solutions [4].
efficiency rating system. Is selected performance evaluation and recognition of their values. As the performance of the system can be selected, for example, the average time of recognition, the probability to work properly. The efficiency of the system is usually estimated based on experimental data obtained during the study. The functioning of automatic recognition open, learn from the point of view of solving the problem of constructing decision rules.
Conclusions
This paper discussed the problem of the design and analysis of algorithms for constructing and optimizing the weighted training samples from a variety of weights in adaptive recognition systems. Clarified the problem with many training samples coefficients. The types of data and methods of compression.
An analysis of existing methods of construction and optimization of weighted training samples. Availability of the samples weights w-objects can store information about the number of objects replaceable and have the same characteristics allows for the area on which they are located. According to the results of the analysis as the object of investigation, the algorithm STOLP. On this basis, the development of a new method based on the weighted training samples gives a large number of benefits.
References
- Волченко Е.В. Сеточный подход к построению взвешенных обучающих выборок w-объектов в адаптивных системах распознавания // Вісник Національного технічного університету "Харківський політехнічний інститут". Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ "ХПІ", 2011. – № 36. – С. 12
- Профессиональная научная библиотека избранных естественно-научных изданий - Научная-библиотека.рф [Электронный ресурс]. – Режим доступа: http://www.sernam.ru/book_zg.php?id=49
- Информационно-аналитический ресурс, который посвящен вопросам ИИ - [Нейронные сети Электронный ресурс]. – Режим доступа:
http://neural-networks.ru/Arhitektura-LVQ-seti-51.html - Волченко Е.В., Кузьменко И.Ю. Анализ методов нахождения выбросов в обучающих выборках // Проблеми інформатики і моделювання. Тезиси одинадцятої міжнародної науково-технічної конференції. Секція "Молоді вчені". – Х.: НТУ "ХПІ", 2011. – С. 12 – 13.
- Загоруйко Н.Г. Методы распознавания и их применение. – М.: Сов. радио, 1972. – 208 с.
- Матвеев Ю.Н. Основы теории систем и системного анализа: Учебно-методическое пособие. Ч.1 // Тверь: ТГТУ, 2007. – С. 5
- Профессиональный информационно-аналитический ресурс, посвященный машинному обучению, распознаванию образов и интеллектуальному анализу данных - Интеллектуальный анализ данных [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/index.php
- Крисилов В.А., Юдин С.А., Олешко Д.Н. Использование гипотезы -компактности при построении обучающей выборки для прогнозирующих нейросетевых моделей // System Research & Information Technologies. – 2006. – № 3.
- Волченко Е.В. О способе опеределения близости объектов взвешенных обучающих выборок // Весник НТУ "ХПИ", выпуск №38, 2012