
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Мета і завдання дослідження
- 2. Передбачувана наукова новизна
- 3. Практичне значення
- 4. Проблема навчальних вибірок з безліччю коефіцієнтів
- 5. Огляд досліджень і розробок
- 5.1 Види обробки даних
- 5.2 Способи стиснення даних
- 5.3 Алгоритм STOLP
- 5.4 Алгоритм LVQ
- 6. Аналіз побудови та оптимізації зважених навчальних вибірок з безліччю вагових коефіцієнтів
- Висновки
- Перелік посилань
Вступ
Ще до недавно, задачі розпізнавання розглядалися людиною лише з позиції якісних характеристик, які грунтувалися на вивченні рецепторів, таких як органи зору, слуху, дотику. Математичну оцінку ухвалення рішення не проводили. Але, недавно з'явилася, кібернетика дозволила проводити метод математичного аналізу, що дозволило відкрити нові можливості в дослідженні і проектуванні автоматичних систем розпізнавання. Це дозволяє замінити людину спеціалізованим автоматом. Така заміна дозволяє значно розширити можливості систем, які виконують складні інформаційно-логічні завдання. Адже якість робіт, що виконуються людиною, дуже сильно залежить від людського фактора. В автоматизованих системах людський фактор відсутній, що дозволяє запобігти багато помилок, які б могли виникнути в неавтоматизованих системах.
Протягом досить тривалого часу, проблема розпізнавання продовжує привертати увагу фахівців у різних наукових галузях. З'являються все нові і нові алгоритми побудови навчальних вибірок в системах розпізнавання. Але ж не всі алгоритми дають однаково хороший результат. Інформація про зміну розпізнаваних об'єктів надходить у системи розпізнавання в більшості випадків у вигляді нових об'єктів навчальної вибірки, кількість яких може досягати десятків тисяч, тому для адаптивних систем однією з ключових проблем є проблема предобработки вихідних вибірок даних [1]. Саме тому оптимізація цих алгоритмів є одним з пріоритетних напрямків аналізу даних в адаптивних системах розпізнавання.
1. Мета і завдання дослідження
Об'єктом дослідження є завдання оптимізації вибірок з безліччю вагових коефіцієнтів.
Предметом дослідження - методи побудови та оптимізації зважених навчальних вибірок.
Метою випускної роботи магістра є розробка методів побудови та оптимізації зважених навчальних вибірок з безліччю вагових коефіцієнтів в адаптивних системах розпізнавання.
У процесі роботи необхідно вирішити наступні завдання:
2. Передбачувана наукова новизна
Науковою новизною даної роботи є розробка методу побудови та оптимізації навчальних вибірок в адаптивних системах розпізнавання з урахуванням безлічі вагових коефіцієнтів. Принцип побудови зважених навчальних вибірок полягає в усередненні локального підмножини даних, то можна припустити, що на основі зважених вибірок з безліччю вагових коефіцієнтів може бути побудований ефективний алгоритм об'єднання даних у кластера, якій би показував кращі результати розпізнавання і більш швидке виконання.
3. Практичне значення
Практична значимість даної роботи полягає в розробці методу побудови та оптимізації зважених навчальних вибірок. Якщо безліч вагових коефіцієнтів у цих вибірках буде дуже велике, то можуть знадобитися великі обчислювальні витрати і велика кількість часу для виконання алгоритму. До того ж, не завжди буде отримано найкраще рішення. Тому оптимізація вибірок за допомогою об'їдання даних, дозволила б підвищити якість вихідної безлічі даних і, як результат, ефективність роботи всієї системи в цілому.
4. Проблема навчальних вибірок з безліччю коефіцієнтів
У пам'яті машини необхідно зберігати відомості про всіх реалізаціях навчальної вибірки [2]. Але якщо скоротити вибірки за допомогою еталонів і зберігати тільки частина реалізації вибірки, то це істотно спростить розпізнавання. Наприклад, залишити в якості еталону тільки ті точки, при яких відстань від будь-якої точки навчальної вибірки до найближчого еталона, менше відстані до найближчого еталона іншого класу. Але в даному випадку існує ризик зіткнутися з такою ситуацією, при якій рішення задачі можливе тільки у разі перебору всіх варіантів. Якщо кількість об'єктів у вибірці становить k, то число перевірок у навчальній вибірці одно mi, а число всіх можливих варіантів для одного еталона для кожного k одно сума всіх k від початкового до останнього об'єкта вибірки. Очевидно, що завдання в такому випадку носить комбінаторний характер і є важко вирішуваною. Для спрощення даної задачі існує ряд алгоритмів, які будуть розглянуті нижче.
5. Огляд досліджень і розробок
5.1 Види обробки даних
Передобробка даних в системах розпізнавання є ітеративним процесом, який включає очищення даних, стиснення даних і об'єднання даних. Очищення даних полягає у видаленні шуму, пропусків у даних і даних низької якості.
Стиснення даних включає знаходження мінімальні прізнаковие простору і репрезентативні безлічі даних на основі методів редукції і трансформації. Об'єднання даних дозволяє зменшити обсяг даних із збереженням вихідної інформації за допомогою евристичних алгоритмів.
5.2 Способи стиснення даних
Актуальним завданням є стиснення даних, адже це дозволяє зменшити обсяг даних із збереженням первісної інформації. Існує кілька методів, які дозволяють це зробити.
Перший метод полягає у відборі деякого безлічі об'єктів вихідної навчальної вибірки, кожен об'єкт якої повинен відповідати вимогам.
Другий метод відрізняється від першого тим, що використовує інший спосіб відбору об'єктів, при цьому використовуючи відстань і критерій оптимальності отриманої вибірки. Він полягає в побудові безлічі нових об'єктів вибірки, які будуються за інформацією про деяке підмножині об'єктів вихідної вибірки.
Для першого способу використовуються алгоритми STOLP, FRiS-STOLP, NNDE (Nearest Neighbor Density Estimate) і MDCA (Multiscale Data CondensationAlgorithm). До алгоритмів, які реалізують другий спосіб відносяться алгоритми LVQ (learning vector quantization), алгоритм чітко горазбіенія простору ознак, алгоритм GridDC, мережевий метод побудови зважених вибірок w-об'єктів.
5.3 Алгоритм STOLP
Для розбиття всієї множини об'єктів на еталонні, шумові (викиди) і неінформативні об'єкти, використовують алгоритм STOLP. Еталонами для даного алгоритму є підмножина вибірки, при якому всі об'єкти класифікуються правильно при використанні навчальної вибірки безлічі еталонів. Сам алгоритм виглядає як набір послідовних дій. Спочатку є навчальна вибірка:
где xi – об'єкти, yi=y*(xi) – класи, яким належать ці об'єкти. Крім того, задана метрика X × X → R, така, що виконується гіпотеза компактності.
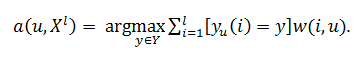
Необхідно обчислювати відстані від классифицируемого об'єкта до всіх об'єктів навчальної вибірки. Алгоритм буде виглядати як:
Приклад виконання алгоритму STOLP наведено на зображенні 2. Як еталон були спочатку вибрані точки 1 і 2. Але після пробного розпізнавання усіх точок навчальної вибірки список еталонів поповнився точками 3, 4, 5.

У підсумку, безліч об'єктів класифікувалося на еталонні, неінформативні і викиди. Однак, алгоритм STOLP має не високу ефективність. Це пояснюється тим, що для кожної нової ітерації (при приєднанні чергового еталона) необхідно заново класифікувати всі об'єкти, які можуть стати еталонами. Для цього ніжно вважати на них величину ризику.
5.4 Алгоритм LVQ
Алгоритм скорочення навчальної вибірки має схожу ідею із завданням кластеризації. Він полягає в розбитті вихідної вибірки на підмножини і їх обробку. Застосовується переважно для кластеризації вибірок великого обсягу і дозволяє виділити кластери складної форми.
Мережа LVQ має два шари: конкуруючий і лінійний. Конкуруючий шар виконує кластеризацію векторів, а лінійний шар співвідносить кластери з цільовими класами, заданими користувачем. [3]
Як в конкуруючому, так і в лінійному шарі припадає 1 нейрон на кластер або цільової клас. Таким чином, конкуруючий шар здатний підтримати до S1 кластерів; ці кластери, у свою чергу, можуть бути співвіднесені з S2 цільовими класами, причому S2 не перевищує S1.
Оскільки заздалегідь відомо, як кластери першого шару співвідносяться з цільовими класами другого шару, то це дозволяє заздалегідь задати елементи матриці ваг LW21. Однак щоб знайти правильний кластер для кожного вектора навчальної множини, необхідно виконати процедуру навчання мережі.
6. Аналіз побудови та оптимізації зважених навчальних вибірок з безліччю вагових коефіцієнтів
Аналіз побудови оптимізації зважених навчальних вибірок з безліччю вагових коефіцієнтів в адаптивних системах розпізнавання показав наступні особливості реалізації етапів побудови систем. Першим етапом є визначення ознак об'єктів. Полягає в тому, щоб визначити повний набір ознак, що характеризують об'єкти або явища, для розпізнавання яких розробляється система. Спочатку необхідно визначити всі ознаки, хоча б у найменшій мірі характеризують об'єкти або явища.
Далі необхідно скласти апріорний алфавіт класів. Головним у цій задачі є вибір правильного принципу класифікації, що задовольняє вимогам, що пред'являються до системи класифікації. При вирішенні наступних завдань з апріорного алфавіту класів формується робочий алфавіт класів системи.
Розробка апріорного словника ознак полягає в розробці апріорного словника ознак, до якого увійдуть тільки ті ознаки, щодо яких може бути отримана апріорна інформація, необхідна для опису класів мовою цих ознак. При описі всіх класів апріорного алфавіту класів на мові ознак, включених до апріорний словник ознак, використовується метод навчання, самонавчання або безпосередньої обробки вихідних даних [4]. Після того, як всі класи апріорного алфавіту були описані, необхідно розбити апріорне простір ознак на області, що відповідають класам апріорного алфавіту класів.
Побудова робочого алфавіту ознак і класів являє собою загальну постановку проблеми розпізнавання. Суть її полягає в розробці такого алфавіту класів і такого словника ознак, які в умовах обмежень на побудову системи розпізнавання забезпечують максимальне значення показника ефективності системи розпізнавання, приймаючої залежно від результатів розпізнавання невідомих об'єктів відповідні рішення [5].
Оцінка ефективності роботи системи. Полягає у виборі показників ефективності системи розпізнавання та оцінці їх значень. В якості показників ефективності системи можуть бути обрані, наприклад, середній час розпізнавання, ймовірність правильної роботи. Ефективність роботи системи, як правило, оцінюється на підставі експериментальних даних, отриманих в ході досліджень. Функціонування систем автоматичного розпізнавання відкритого типу, навчаються з точки зору вирішення завдання побудови вирішальних правил.
Висновки
У даній роботі була розглянута задача розробки та аналізу алгоритмів побудови та оптимізації зважених навчальних вибірок з безліччю вагових коефіцієнтів в адаптивних системах розпізнавання. З'ясовано проблеми навчальних вибірок з безліччю коефіцієнтів. Розглянуто види обробки даних і способи їх стиснення.
Виконано аналіз існуючих методів побудови та оптимізації зважених навчальних вибірок. Наявність ваг у вибірках w-об'єктів дозволяє зберігати інформацію про кількість замінних об'єктів, а так само, дозволяє провести характеристику тій області, на якій вони розташовані. За результатами проведеного аналізу в якості об'єкта дослідження обрано алгоритм STOLP. Виходячи з цього, розробка нового методу на основі зважених навчальних вибірках дає великий ряд переваг.
Список джерел
- Волченко Е.В. Сеточный подход к построению взвешенных обучающих выборок w-объектов в адаптивных системах распознавания // Вісник Національного технічного університету "Харківський політехнічний інститут". Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ "ХПІ", 2011. – № 36. – С. 12
- Профессиональная научная библиотека избранных естественно-научных изданий - Научная-библиотека.рф [Электронный ресурс]. – Режим доступа: http://www.sernam.ru/book_zg.php?id=49
- Информационно-аналитический ресурс, который посвящен вопросам ИИ - [Нейронные сети Электронный ресурс]. – Режим доступа:
http://neural-networks.ru/Arhitektura-LVQ-seti-51.html - Волченко Е.В., Кузьменко И.Ю. Анализ методов нахождения выбросов в обучающих выборках // Проблеми інформатики і моделювання. Тезиси одинадцятої міжнародної науково-технічної конференції. Секція "Молоді вчені". – Х.: НТУ "ХПІ", 2011. – С. 12 – 13.
- Загоруйко Н.Г. Методы распознавания и их применение. – М.: Сов. радио, 1972. – 208 с.
- Матвеев Ю.Н. Основы теории систем и системного анализа: Учебно-методическое пособие. Ч.1 // Тверь: ТГТУ, 2007. – С. 5
- Профессиональный информационно-аналитический ресурс, посвященный машинному обучению, распознаванию образов и интеллектуальному анализу данных - Интеллектуальный анализ данных [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/index.php
- Крисилов В.А., Юдин С.А., Олешко Д.Н. Использование гипотезы -компактности при построении обучающей выборки для прогнозирующих нейросетевых моделей // System Research & Information Technologies. – 2006. – № 3.
- Волченко Е.В. О способе опеределения близости объектов взвешенных обучающих выборок // Весник НТУ "ХПИ", выпуск №38, 2012