
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 1.1 Цель и задачи исследования
- 1.2 Предполагаемая научная новизна
- 1.3 Практическая значимость
- 2. Обзор исследований и разработок
- 3. Методы решения задач распознавания
- 3.1 Метод построения эталонов
- 3.2 Метод потенциальных функций
- 3.3 Кластерный анализ
- 4. Обзор методов кластеризации данных
- 4.1 Алгоритм CURE (ClusteringUsing Representatives)
- 4.2 Алгоритм BIRCH (Balanced IterativeReducing and Clustering using Hierarchies
- 4.3 Алгоритм MST(Algorithm based on Minimum Spanning Trees)
- 4.4 Алгоритм k-средних(k-means)
- Выводы
- Список источников
- Важное замечание
Введение
Проблема распознавания образов уже давно привлекла внимание психологов, физиологов, инженеров и математиков. В последние годы интерес к ней значительно возрос, так как во многих областях науки и техники стала остро ощущаться необходимость ее решения. Это связано с разработкой большого количества разнообразных устройств (роботов, систем технической и медицинской диагностики, персональных, мобильных и карманных компьютеров), автоматическая работа которых невозможна без распознавания текущего состояния объектов, процессов, явлений и состояний, с которыми эти устройства работают.
Создание устройств, которые выполняют функции распознавания различных объектов, во многих случаях открывает возможность замены человека как элемента сложной системы специализированным автоматом. Такая замена позволяет значительно расширить возможности различных систем, выполняющих сложные информационно-логические задачи. В то же время автомат его заменяющий действует однообразно и обеспечивает всегда одинаковое качество, если он исправен.
Большинство современных прикладных задач, решаемых путем построения систем распознавания, характеризуется большим объемом исходных данных и возможностью добавления новых данных уже в процессе работы систем.
1. Актуальность работы
В настоящее время основным научным направлением является исследование и разработка алгоритмов и методов построения программных средств интеллектуального анализа данных. Актуальность данной тематики определяется наличием ряда важных прикладных задач, при решении которых требуется анализировать большие объемы разнородных сложноорганизованных данных. При этом объем и сложность организации таких данных часто не позволяют эффективно применять традиционные средства анализа, основанные на методах статистического анализа, информационного поиска и экспертных знаниях, что определяет необходимость применения средств интеллектуальных анализа данных, основанных на методах машинного обучения и искусственного интеллекта. Объемы данных настолько внушительны, что человеку просто не по силам проанализировать их самостоятельно, хотя необходимость проведения такого анализа вполне очевидна, ведь в этих «сырых данных» заключены знания, которые могут быть использованы при принятии решений.
Именно поэтому задача фильтрации данных является актуальной научно-технической задачей, требующей разработки современных подходов к её решению.
1.1 Цель и задачи исследования
Объектом исследования является обработка данных в системах распознавания.
Предметом исследования – алгоритм построения взвешенных обучающих выборок.
Целью выпускной работы магистра является разработка и исследование алгоритма построения обучающих выборок на основе методов кластеризации данных.
В процессе работы необходимо решить следующие задачи:
- исследование методов решения задач распознавания;
- исследование существующих алгоритмов построения выборок;
- исследование методов кластеризации данных;
- разработка алгоритма построения взвешенных обучающих выборок на основе выбранного метода;
- разработка программной системы.
1.2 Предполагаемая научная новизна
Научной новизной данной работы является разработка алгоритма построения взвешенных обучающих выборок на основе методов кластеризации данных – нового направления в предобработке обучающих выборок большого объема.
1.3 Практическая значимость
Практическая значимость данной работе состоит в разработке метода фильтрации данных (на основе кластеризации), позволяющего повысить качество исходных данных и, как следствие, эффективность работы всей системы в целом.
Создания
реальной системы построения взвешенных обучающих
выборок, тестирование и контроль качества их функционирования.
2. Обзор исследований и разработок
На глобальном уровне по проблеме распознавания проведено значительное количество исследований, представленное работами ряда таких специалистов как: Айзерман М.А. [1], Вайнцвайг М.Н. [2] и другие зарубежные специалисты.
На национальном уровне задача построения автоматических систем распознавания является одной из главных направлений прикладной математики и информатики. За последние 50 лет было созданно значительное количество методов и алгоритмов распознавания, классификацию которых можно найти в работах Васильева В.И. [3], Загогуйко М.Г. [4].
На локальном уровне, в пределах ДонНТУ, научные разработки в этой области ведут д.т.н., доц. Волченко Е.В. [5-6], а так же магистры 2012 года выпуска: Кузьменко И.Ю. [7] и Шкарпеткина Ю.Г. [8]
3. Методы решения задач распознавания
Для построения решающих правил нужна обучающая выборка. Обучающая выборка – это множество объектов, заданных значениями признаков и принадлежность которых к тому или иному классу достоверно известна "учителю" и сообщается учителем обучаемой системе. По обучающей выборке система строит решающие правила. Качество решающих правил оценивается по контрольной (экзаменационной) выборке, в которую входят объекты, заданные значениями признаков, и принадлежность которых тому или иному образу известна только учителю. Предъявляя обучаемой системе для контрольного распознавания объекты экзаменационной выборки, учитель в состоянии дать оценку вероятностей ошибок распознавания, то есть оценить качество обучения. К обучающей и контрольной выборкам предъявляются определённые требования. Например, важно, чтобы объекты экзаменационной выборки не входили в обучающую выборку (иногда, правда, это требование нарушается, если общий объём выборок мал и увеличить его либо невозможно, либо чрезвычайно сложно).
Обучающая и экзаменационная выборки должны достаточно полно представлять генеральную совокупность (гипотетическое множество всех возможных объектов каждого образа).
Итак, для построения решающих правил системе предъявляются объекты, входящие в обучающую выборку.
3.1 Метод построения эталонов
Для каждого класса по обучающей выборке строится эталон, имеющий значения признаков:
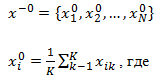
k – количество объектов данного образа в обучающей выборке,
i – номер признака.
По существу, эталон – это усреднённый по обучающей выборке абстрактный объект (рис. 2.1). Абстрактным мы его называем потому, что он может не совпадать не только ни с одним объектом обучающей выборки, но и ни с одним объектом генеральной совокупности.
Распознавание
осуществляется
следующим образом. На вход системы поступает объект
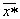 ,
принадлежность которого к тому или иному образу системе неизвестна. От
этого объекта измеряются расстояния до эталонов всех образов, и система
относит к тому образу, расстояние до эталона которого
минимально. Расстояние измеряется в той метрике, которая введена для
решения
определённой задачи распознавания.
,
принадлежность которого к тому или иному образу системе неизвестна. От
этого объекта измеряются расстояния до эталонов всех образов, и система
относит к тому образу, расстояние до эталона которого
минимально. Расстояние измеряется в той метрике, которая введена для
решения
определённой задачи распознавания.

Рисунок 3.1 – Построение эталонов
3.2 Метод потенциальных функций
Название
метода в определённой степени связано со следующей
аналогией (для простоты будем считать, что распознаётся два образа).
Представим
себе, что объекты являются точками  некоторого пространства X. В эти точки будем помещать заряды + qj, если
объект принадлежит образу s1, и –qj, если объект
принадлежит образу s2 (рис. 2.2).
некоторого пространства X. В эти точки будем помещать заряды + qj, если
объект принадлежит образу s1, и –qj, если объект
принадлежит образу s2 (рис. 2.2).

Рисунок 3.2 – Иллюстрация синтеза потенциальной функции в
процессе обучения
-----------
– потенциальная функция, порождаемая
одиночным объектом;
––––––– – суммарная потенциальная функция,
порожденная обучающей последовательностью.
Функцию, описывающую
распределение
электростатического потенциала в таком поле, можно использовать в
качестве
решающего правила (или для его построения). Если потенциал точки  ,
создаваемый единичным зарядом, находящимся в , равен
,
создаваемый единичным зарядом, находящимся в , равен 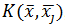 , то общий
потенциал в , создаваемый n зарядами, равен
, то общий
потенциал в , создаваемый n зарядами, равен
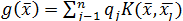
– потенциальная функция. Она, как в физике, убывает с ростом евклидова расстояния между и . Чаще всего в качестве потенциальной используется функция, имеющая максимум при = и монотонно убывающая до нуля при 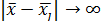 .
.
Распознавание может осуществляться следующим способом. В точке , где находится неопознанный объект, вычисляется потенциал g(). Если он оказывается положительным, то объект относят к образу s1. Если отрицательным – к образу s2.
При большом объёме обучающей выборки эти вычисления достаточно громоздки, и зачастую выгоднее вычислять не g(), а оценивать разделяющую классы (образы) границу либо аппроксимировать потенциальное поле.
Выбор вида потенциальных функций – дело непростое. Например, если они очень быстро убывают с ростом расстояния, то можно добиться безошибочного разделения обучающих выборок. Однако при этом возникают определённые неприятности при распознавании неопознанных объектов (снижается достоверность принимаемого решения, возрастает зона неопределённости). При слишком "пологих" потенциальных функциях может необоснованно увеличиться количество ошибок распознавания, в том числе и на обучающих объектах.
3.3 Кластерный анализ
Кластерный анализ (самообучение, обучение без учителя, таксономия) применяется при автоматическом формировании перечня образов по обучающей выборке. Все объекты этой выборки предъявляются системе без указания, какому образу они принадлежат. Подобного рода задачи решает, например, человек в процессе естественно-научного познания окружающего мира. Этот опыт целесообразно использовать при создании соответствующих алгоритмов.
В основе кластерного анализа лежит гипотеза компактности. Предполагается, что обучающая выборка в признаковом пространстве состоит из набора сгустков (подобно галактикам во Вселенной). Задача системы – выявить и формализованно описать эти сгустки. Геометрическая интерпретация гипотезы компактности состоит в следующем.
Объекты, относящиеся к одному таксону, расположены близко друг к другу по сравнению с объектами, относящимися к разным таксонам. «Близость» можно понимать шире, чем при геометрической интерпретации. Например, закономерность, описывающая взаимосвязь объектов одного таксона, отличается от таковой в других таксонах, как это имеет место в лингвистических методах.
4. Обзор методов кластеризации данных
Кластеризация (или кластерный анализ) – это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.
Применение кластерного анализа в общем виде сводится к следующим этапам:
– отбор выборки объектов для кластеризации;
– определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменных;
– вычисление значений меры сходства между объектами;
– применение метода кластерного анализа для создания групп сходных объектов (кластеров);
– представление результатов анализа.
После получения и анализа результатов возможна корректировка выбранной метрики и метода кластеризации до получения оптимального результата.
4.1 Алгоритм CURE (Clustering Using REpresentatives)
При иерархической кластеризации выполняется последовательное объединение меньших кластеров в большие или разделение больших кластеров на меньшие [9].
Агломеративная группа методов характеризуется последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров. В начале работы алгоритма все объекты являются отдельными кластерами. На первом шаге наиболее похожие объекты объединяются в кластер. На последующих шагах объединение продолжается до тех пор, пока все объекты не будут составлять один кластер.
Алгоритм CURE выполняет иерархическую кластеризацию с использованием набора определяющих точек для определения объекта в кластер. Назначение: кластеризация очень больших наборов числовых данных. Ограничения: эффективен для данных низкой размерности, работает только на числовых данных. Достоинства: выполняет кластеризацию на высоком уровне даже при наличии выбросов, выделяет кластеры сложной формы и различных размеров, обладает линейно зависимыми требованиями к месту хранения данных и временную сложность для данных высокой размерности. Недостатки: есть необходимость в задании пороговых значений и количества кластеров.
Описание алгоритма [11]:
Шаг 1. Построение дерева кластеров, состоящего из каждой строки входного набора данных.
Шаг 2. Формирование «кучи» в оперативной памяти, расчет расстояния до ближайшего кластера (строки данных) для каждого кластера. При формировании кучи кластеры сортируются по возрастанию дистанции от кластера до ближайшего кластера. Расстояние между кластерами определяется по двум ближайшим элементам из соседних кластеров. Для определения расстояния между кластерами используются «манхеттенская», «евклидова» метрики или похожие на них функции.
Шаг 3. Слияние ближних кластеров в один кластер. Новый кластер получает все точки входящих в него входных данных. Расчет расстояния до остальных кластеров для новообразованного кластера. Для расчета расстояния кластеры делятся на две группы: первая группа – кластеры, у которых ближайшими кластерами считаются кластеры, входящие в новообразованный кластер, остальные кластеры – вторая группа. И при этом для кластеров из первой группы, если расстояние до новообразованного кластера меньше чем до предыдущего ближайшего кластера, то ближайший кластер меняется на новообразованный кластер. В противном случае ищется новый ближайший кластер, но при этом не берутся кластеры, расстояния до которых больше, чем до новообразованного кластера. Для кластеров второй группы выполняется следующее: если расстояние до новообразованного кластера ближе, чем предыдущий ближайший кластер, то ближайший кластер меняется. В противном случае ничего не происходит.
Шаг 4. Переход на шаг 3, если не получено требуемое количество кластеров.
4.2 Алгоритм BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies)
Дивизимная группа методов характеризуется последовательным разделением исходного кластера, состоящего из всех объектов, и соответствующим увеличением числа кластеров. В начале работы алгоритма все объекты принадлежат одному кластеру, который на последующих шагах делится на меньшие кластеры, в результате образуется последовательность расщепляющих групп.
В этом алгоритме предусмотрен двухэтапный процесс кластеризации.
Назначение: кластеризация очень больших наборов числовых данных. Ограничения: работа с только числовыми данными. Достоинства: двухступенчатая кластеризация, кластеризация больших объемов данных, работает на ограниченном объеме памяти, является локальным алгоритмом, может работать при одном сканировании входного набора данных, использует тот факт, что данные неодинаково распределены по пространству, и обрабатывает области с большой плотностью как единый кластер. Недостатки: работа с только числовыми данными, хорошо выделяет только кластеры сферической формы, есть необходимость в задании пороговых значений.
Описание алгоритма [12]:
Фаза 1. Загрузка данных в память.
Построение начального кластерного дерева (CF Tree) по данным (первое сканирование набора данных) в памяти;
Подфазы основной фазы происходят быстро, точно, практически нечувствительны к порядку.
Алгоритм построения кластерного дерева (CF Tree):
Кластерный элемент представляет из себя тройку чисел (N, LS, SS), где N – количество элементов входных данных, входящих в кластер, LS – сумма элементов входных данных, SS – сумма квадратов элементов входных данных.
Кластерное дерево – это взвешенно сбалансированное дерево с двумя параметрами: B – коэффициент разветвления, T – пороговая величина. Каждый нелистьевой узел дерева имеет не более чем B вхождений узлов следующей формы: [CFi, Childi], гд i = 1, 2, …, B; Childi – указатель на i-й дочерний узел.
Каждый листьевой узел имеет ссылку на два соседних узла. Кластер состоящий из элементов листьевого узла должен удовлетворять следующему условию: диаметр или радиус полученного кластера должен быть не более пороговой величины T.
Фаза 2 (необязательная). Сжатие (уплотнение) данных.
Сжатие данных до приемлемых размеров с помощью перестроения и уменьшения кластерного дерева с увеличением пороговой величины T.
Фаза 3. Глобальная кластеризация.
Применяется выбранный алгоритм кластеризации на листьевых компонентах кластерного дерева.
Фаза 4 (необязательная). Улучшение кластеров.
Использует центры тяжести кластеров, полученные в фазе 3, как основы.
Перераспределяет данные между «близкими» кластерами. Данная фаза гарантирует попадание одинаковых данных в один кластер.
4.3 Алгоритм MST (Algorithm based on Minimum Spanning Trees)
Назначение: кластеризация больших наборов произвольных данных.
Достоинства: выделяет кластеры произвольной формы, в т.ч. кластеры выпуклой и впуклой формы, выбирает из нескольких оптимальных решений самое оптимальное.
Описание алгоритма [13]
Шаг 1 Построение минимального остовного дерева:
Связный, неориентированный граф с весами на ребрах G(V, E), в котором V – множество вершин(контактов), а E – множество их возможных попарных соединений (ребер), для каждого ребра (u,v) однозначно определено некоторое вещественное число w(u,v) — его вес (длина или стоимость соединения).
Алгоритм Борувки:
1. Для каждой вершины графа находимо ребро с минимальным весом.
2. Добавляем найденные ребра к остовному дереву, при условии их безопасности.
3. Находим и добавляем безопасные ребра для несвязанных вершин к остовному дереву.
4. Общее время работы алгоритма: O(ELogV).
Алгоритм Крускала:
1. Обход ребер по возрастанию весов. При условии безопасности ребра добавляем его к основному дереву.
2. Общее
время работы алгоритма: O(ELogE).
Алгоритм Прима:
1. Выбор корневой вершины.
2. Начиная с корня добавляем безопасные ребра к остовному дереву.
Общее время работы алгоритма: O(ELogV).
Шаг
2 Разделение на кластеры. Дуги с наибольшими весами
разделяют кластеры. Принцип
работы описанных выше групп методов в виде
дендрограммы показан на рис. 4.1
")
Рисунок 4.1 – Дендограмма работы агломеративных и дивизимных методов (анимация: объем 106 KB, размер 586x364, количество кадров 10, задержка между кадрами 50мс, задержка между последним и первым кадром 100 мс количество циклов повторения 5)
4.4 Алгоритм k-средних (k-means)
Наиболее распространен среди неиерархических методов алгоритм k-средних, также называемый быстрым кластерным анализом. Полное описание алгоритма можно найти в работе Хартигана и Вонга (Hartigan and Wong, 1978). В отличие от иерархических методов, которые не требуют предварительных предположений относительно числа кластеров, для возможности использования этого метода необходимо иметь гипотезу о наиболее вероятном количестве кластеров.
Алгоритм k-средних строит k кластеров, расположенных на возможно больших расстояниях друг от друга. Основной тип задач, которые решает алгоритм k-средних, – наличие предположений (гипотез) относительно числа кластеров, при этом они должны быть различны настолько, насколько это возможно. Выбор числа k может базироваться на результатах предшествующих исследований, теоретических соображениях или интуиции.
Общая идея алгоритма: заданное фиксированное число k кластеров наблюдения сопоставляются кластерам так, что средние в кластере (для всех переменных) максимально возможно отличаются друг от друга.
Описание алгоритма:
1. Первоначальное распределение объектов по кластерам.
Выбирается число k, и на первом шаге эти точки считаются "центрами" кластеров. Каждому кластеру соответствует один центр.
Выбор начальных центроидов может осуществляться следующим образом:
– выбор k-наблюдений для максимизации начального расстояния;
– случайный выбор k-наблюдений;
– выбор первых k-наблюдений.
В результате каждый объект назначен определенному кластеру.
2.Итеративный процесс.
Вычисляются центры кластеров, которыми затем и далее считаются покоординатные средние кластеров. Объекты опять перераспределяются.
Процесс вычисления центров и перераспределения объектов продолжается до тех пор, пока не выполнено одно из условий:
– кластерные центры стабилизировались, т.е. все наблюдения принадлежат кластеру, которому принадлежали до текущей итерации;
– число итераций равно максимальному числу итераций.
На рис. 4.2 приведен пример работы алгоритма k-средних для k, равного двум.

Рисунок 4.2 – Пример
работы алгоритма k-средних (k=2)
Выбор числа кластеров является сложным вопросом. Если нет предположений относительно этого числа, рекомендуют создать 2 кластера, затем 3, 4, 5 и т.д., сравнивая полученные результаты.
После получений результатов кластерного анализа методом k-средних следует проверить правильность кластеризации (т.е. оценить, насколько кластеры отличаются друг от друга). Для этого рассчитываются средние значения для каждого кластера. При хорошей кластеризации должны быть получены сильно отличающиеся средние для всех измерений или хотя бы большей их части.
Достоинства алгоритма k-средних:
– простота использования;
– быстрота использования;
– понятность и прозрачность алгоритма.
Недостатки алгоритма k-средних:
– алгоритм слишком чувствителен к выбросам, которые могут искажать среднее. Возможным решением этой проблемы является использование модификации алгоритма – алгоритм k-медианы;
– алгоритм может медленно работать на больших базах данных. Возможным решением данной проблемы является использование выборки данных.
Выводы
В ходе работы были рассмотрены методы для построения взвешенных обучающих выборок. Были рассмотрены основные методы кластеризации данных. Установлено, что за последние годы были разработаны различные методы предобработки данных. Было отмечено, что из-за большого количества исходных данных, важное значение играет предобработка информации.
По результатам проведенного анализа в качестве объекта исследования выбрана задача построения взвешенных обучающих выборок.
Список источников
- Айзерман М.А., Браверман Э.М., Глушков В.М. и др. Теория распознавания образов и обучающих систем. – Изв. АН СССР, Техническая кибернетика № 5, 1963, с. 98-101.
- Вайнцвайг М.Н. Алгоритм обучения распознавания образов «Кора». В сб.: Алгоритмы обучения распознавания образов. – М.: 1972, с. 110-116.
- Васильев В.И. Распознающие системы: Справочник. / В.И. Васильев – К.: Наукова думка, 1983. – 423 с.
- Загоруйко Н.Г. Прикладные методы анализа знаний и данных / Н.Г. Загоруйко. – Новосибирск: Издательство института математики, 1999. – 270 с.
- Волченко Е.В. Сеточный подход к построению взвешенных обучающих выборок w-объектов в адаптивных системах распознавания // Вісник Національного технічного університету «Харківський політехнічний інститут». Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ «ХПІ», 2011. – № 36. – С. 12-22.
- Волченко Е.В. Модифицированный метод потенциальных функций / Е.В. Волченко II Бионика интеллекта. – 2006. – № 1 (64). – С. 86-92.
- Волченко Е. В., Кузьменко И. Ю. Анализ методов нахождения выбросов в обучающих выборках / Харьковский Политехнический Институт // Материалы ХI Международной научно-технической конференции/ Секция «Молодые ученые«. – Харьков, ХПИ – 2011, , с. 12-13.
- Автореферат магистерской работы Шкарпеткина Ю.Г. «Исследование и разработка метода заполнения пропусков в взвешенных обучающих выборках данных» [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2012/iii/shkarpetkina/diss/index.htm
- Чубукова И.А. Data Mining. Учебное пособие. – М.: Интернет-Университет Информационных технологий; БИНОМ. Лаборатория знаний, 2006. – 382 с.: ил., табл. – (Серия «Основы информационных технологий»)
- Паклин Н. «Кластеризация категорийных данных: масштабируемый алгоритм CLOPE». [Электронный ресурс]. – Режим доступа: http://www.basegroup.ru/clusterization/clope.htm
- Sudipto Guha, Rajeev Rastogi, Kyuseok Shim «CURE: An Efficient Clustering Algorithm for Large Databases». Proceedings of the 1998 ACM SIGMOD international conference on Management of data pp.. 73-84
- Tian Zhang, Raghu Ramakrishnan, Miron Livny «BIRCH: An Efficient Data Clustering Method for Very Large Databases». Proceedings of the 1996 ACM SIGMOD international conference on Management of data pp. 103-114
- Daniel Fasulo «An Analysis Of Recent Work on Clustering Algorithms». [Электронный ресурс]. – Режим доступа: http://logic.pdmi.ras.ru/ics/papers/aca.pdf
- Паклин Н. «Алгоритмы кластеризации на службе Data Mining». [Электронный ресурс]. – Режим доступа: http://www.basegroup.ru/clusterization/datamining.htm
Важное замечание
При написании данного автореферата магистерская работа еще не завершена. Предположительная дата завершения – январь 2014 г. Полный текст работы, а также материалы по теме могут быть получены у автора или его руководителя после указанной даты.