
Abstract of the theme of master's work
Content
- Introduction
- 1. Theme actuality
- 2. Goal and tasks of research
- 3. Network processors applications analysis
- 4. Experiments on queuing network model
- Conclusion
- References
Introduction
Network processors (NP) are designed to provide both performance and flexibility through parallel and programmable architecture, making them superior to general-purpose processors on performance and to hardware-based solutions on flexibility. But NPs also introduce new challenges. It is important to study the limitations of NP architectures so that one can take full advantage of NP resources to achieve the required performance for a given application [1].
1. Theme actuality
The growth of traffic in computer networks makes important the problem of creating specialized high-performance network processors and software for processing data streams at different levels of the protocol stack. Therefore, developing applications, that will maximize the network processors performance is very important.
2. Goal and tasks of research
The goal of research is analytical models analysis and methods for performance analysis of network-processor-based application designs, models implementation in software design.
Main tasks of research:
- Network processors applications analysis.
- NP architecture analysis and NP software analysis.
- design of mathematical models to research the NP applications efficiency.
- mathematical models implementation in software project.
- experimental research on models.
3. Network processors applications analysis
Network processors are used in the manufacture of many different types of network equipment such as:
- routers, software routers and switches;
- firewalls;
- session border controllers;
- intrusion detection devices;
- intrusion prevention devices;
- network monitoring systems.
In [2] discussed network processors of the past, present and future.
As the number of applications for network processors has grown, the market has begun to segment into three main network equipment areas: core, edge and access. Each of these areas has different target applications and performance requirements. Core devices sit in the middle of the network. As a result, they are the most performance-critical and the least responsive to flexibility. Examples of these devices are gigabit and terabit routers.
Edge devices sit between the core network and access devices. Examples of edge devices include URL load balancers and firewalls. They are focused on medium-high data rates and higher layer processing, so a certain amount of flexibility is required.
Access equipment provides various devices access to the network. Most of their computation relates to aggregating numerous traffic streams and forwarding them through the network. Examples of access devices include cable modem termination systems and base stations for wireless networks. Each level of the network requires a different mix of processing performance, features and costs. To meet these needs effectively, network processors must be optimized not only for the specific requirements of the equipment, but also for the services delivered in each segment of the network infrastructure.
Application Categorization
- Control-Plane tasks
- Less time-critical
- Control and management of device operation
- Table maintenance, port states, etc.
- Data-Plane tasks
- Operations occurring real-time on “packet path”
- Core device operations
- Receive, process and transmit packets
This paper focuses on the layer-4 (L4) switch, a layer-7 (L7) switch and a layer-4 and layer-7 combined switch (L4-7) that works at both layers [21].

Figure 1 – Operations on a content-aware switch
(animation: 11 frames, 7 cycles of repeating, 21 kilobytes)
An L4 switch performs content-blind routing at the TCP layer. It determines the target server when a client requests a TCP connection with TCP SYN packet. It then assigns packets pertaining to the same connection to the same server. This mechanism is efficient, for packets do not go through the application level. However, it lacks the ability of dispatching requests according to contents.
An L7 switch, also known as a content-aware switch, operates at the application level. It provides application traffic management through deep packet inspections. An L7 switch performs the standard handshake procedure with clients at the client-side interface without any server involved. At the serverside interface, the switch keeps persistent TCP connection with each individual server, thus reducing connection establishment overheads.
A number of algorithms have been devised for L4 switches and L7 switches. They can be categorized as static algorithms, client state aware algorithms, server state aware algorithms, and client and server state aware algorithms. Descriptions of these algorithms can be found in a recent survey paper [22].
4. Experiments on queuing network model
For the model shown in Figure 2, discussed in more detail in [1], we have developed C # software using MS Visual Studio 2012.
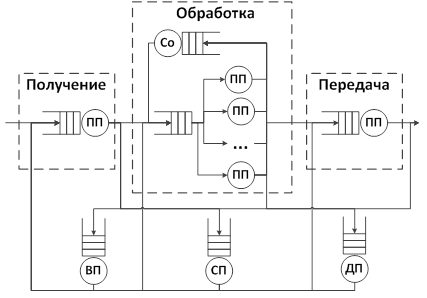
Figure 2 – Queuing network model
We have carried out experiments on this model. Service demands of each resource may be calculated via network processor application pseudo code analysis. Performance characteristics were evaluated using this program. There are service demands of each resource, maximum service demands and maximum system throughput.
Figure 3 illustrates how the performance changes according to the number of requests. The system reaches the maximum performance, when the request number is 5.
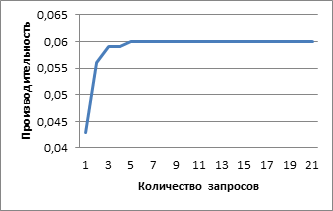
Figure 3 – Results of experiments
We note that adding additional pocket processors makes no significant performance improvement. This is because the bottleneck of the application is on SRAM access.
Conclusion
Performance analysis of network-processor-based applications at the design stage is an important task to simplify the comparison of projects for satisfaction the performance requirements.
Master's work is devoted to design of mathematical models to research the NP applications efficiency, as well as the development of applications to carry out experiments on these models.
As part of the research carried out:
- Network processors applications analysis.
- NP architecture analysis and NP software analysis.
- Analysis of mathematical models to research the NP applications efficiency.
- Implementation of program modules for software performance analysis.
- Some experiments on model.
Further studies focused on the following aspects:
- Finalization applications to work with different models.
- Distribution version of computation moduls.
- Determinate effective parameters of the network-processor-based application designs through experiments on model.
References
- Jie Lu, Jie Wang, "Analytical Performance Analysis of Network-Processor-Based Application Designs", Computer Communications and Networks, 2006. ICCCN 2006. Proceedings.15th International Conference on, October 2006
- Network processors of the past, present and future. White Paper. GlobalLogic. 2010.
- Ладыженський Ю.В. Моделирование сетевых процессоров пакетной обработки данных / Ю.В. Ладыженский, В.И. Грищенко // Матеріали міжнародної науково-практичної конференції «Інтернет – Освіта – Наука – 2006», м. Вінниця, 10 – 14 жовтня р. – 2006. – Т. 2. С. 417-422.
- В.И. Грищенко, Ю.В. Ладыженский, Моатаз Юнис. Влияние выделенного кэша команд на производительность сетевого процессора.// Наукові праці Донецького національного технічного університету, серія «Інформатика, кібернетика та обчислювальна техніка»,вып. 13 (185), Донецк, ДонНТУ, 2011. – С. 85-91.
- В.И. Грищенко, Ю.В. Ладыженский. Исследование влияния раздельной памяти на производительность многоядерного сетевого процессора. // Наукові праці Донецького національного технічного університету. Серiя «Проблеми моделювання та автоматизації проектування» (МАП-2011). Випуск: 9 (179) - Донецьк: ДонНТУ. - 2011. – 356 с.
- Моделирование маршрутизаторов на многоядерных сетевых процесорах / Грищенко В.И., Ладыженский Ю.В.//Научные труды ДонНТУ. Серия «Информатика, кибернетика и вычислительная техника».– 2010.– Вып. 12(165).– С.169-176
- Ning Weng and Tilman Wolf, “Pipelining vs. multiprocessors – choosing the right network processor system topology,” in Proc. of Advanced Networking and Communications Hardware Workshop (ANCHOR 2004) in conjunction with The 31st Annual International Symposium on Computer Architecture (ISCA 2004), Munich, Germany, June 2004.
- Tilman Wolf, Mark A. Franklin, "Performance Models for Network Processor Design," IEEE Transactions on Parallel and Distributed Systems, vol. 17, no. 6, pp. 548-561, Jun., 2006.
- Ahmadi M., Wong S. A Performance Model for Network Processor Architectures in Packet Processing Systems, Proceedings of the 19th International Conference on Parallel and Distributed Computing and Systems (PDCS 2007), pp. 176-181, Cambridge, Massachusetts, USA, November 2007.
- G. Memik and W. H. Mangione-Smith. NEPAL: A framework for efficiently structuring applications for network processors. InProc. Of Network Processor Workshop in conjunction with Ninth International Symposium on High Performance Computer Architecture (HPCA-9), Feb. 2003.
- Lothar Thiele, Samarjit Chakraborty, Matthias Gries, and Simon Kunzli, “Design space exploration of network processor architectures,” in Proc. of First Network Processor Workshop (NP-1) in conjunction with Eighth International Symposium on High Performance Computer Architecture (HPCA-8), Cambridge, MA, Feb. 2002, pp. 30–41.
- Tilman Wolf, Mark A. Franklin, "Performance Models for Network Processor Design," IEEE Transactions on Parallel and Distributed Systems, vol. 17, no. 6, pp. 548-561, Jun., 2006.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Перспективные архитектуры и тенденции развития современных сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Материалы IV международной научно-технической конференции «Моделирование и компьютерная графика – 2011». – Донецк, 2011. – С. 93-97.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Основные направления развития современных сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия «Інформатика, кібернетика та обчислювальна техніка»). – № 14 (188). – С. 123-127.
- Юнис М., Грищенко В.И., Ладыженский Ю.В. Обобщенная структура сетевых процессоров / М. Юнис, В.И. Грищенко, Ю.В. Ладыженский // Материалы VII международной научно-технической конференции студентов, аспирантов и молодых ученых «Информатика и компьютерные технологии – 2011». – Донецк, 2011. – С. 386-391.
- Ладыженский Ю.В., Грищенко В.И. Программирование процессоров обработки пакетов в компьютерных сетях / Ю.В. Ладыженский, В.И. Грищенко // Матеріали міжнародної науково-практичної конференції «Сучасні проблеми і досягнення в галузі радіотехніки, телекомунікацій та інформаційних технологій». – Запорожье, 2006. – C. 159-161.
- Грищенко В.И., Ладыженский Ю.В. Моделирование работы приложений на сетевых процессорах / В.И. Грищенко, Ю.В. Ладыженский // Материалы международной научно-практической конференции «Моделирование и компьютерная графика – 2007». – Донецк, 2007. – С. 167-173.
- Грищенко В.И., Ладыженский Ю.В. Исследование архитектуры кэша сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский // Науково-технічний журнал «Радіоелектронні і комп’ютерні системи». – № 6 (25). – С. 186-192.
- Ладиженский Ю.В., Грищенко В.И. Влияние политики замещения записей в кэше на производительность сетевого процессора / Ю.В. Ладыженский, В.И. Грищенко // Наукові праці ДонНТУ. – Донецк, 2007. – (Серия «Обчислювальна техніка та автоматизація»). – № 12 (118). – С. 114-119.
- Грищенко В.И., Ладыженский Ю.В. Оптимизация методики моделирования кэша сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский // Материалы III международной научно-технической конференции «Моделирование и компьютерная графика – 2009». – Донецк, 2009. – C. 249-254.
- J. Lu and J. Wang, "Performance Modeling and Analysis of Web Switch". in Proc. Int. CMG Conference, 2005, pp.665-672.
- V. Cardellini, E. Casalicchio, M. Colajanni, and P. S. Yu. The state of the art in locally distributed web-server systems. ACM Computing Surveys, 34(2):263-311, 2002.