
Abstract on the theme of master's work
Content
- Introduction
- 1. Theme actuality
- 2. Goal and tasks of research
- 3. Overview of researches and developments
- 4. Markov model for evaluation of heterogeneous CMP architectures
- Conclusion
- References
Introduction
The bandwidth requirements for computer networks are rapidly growing every year. In addition, numerous experimental studies have shown, that flows in today's networks are not simple and have a significant after-effect and self-similarity. Self-similar process causes considerable packet loss ratio, even when the total service demand is far from the maximum allowable values [1]. This phenomenon is explained by taking into account only the average properties of the traffic in terms of the required characteristics of network devices. In particular, with the increasing of the router input buffer capacity, loss probability falls significantly slower, than for the exponential law used in classical teletraffic models [2]. Thus, algorithms for traffic processing, meant to work with the simple flow, as well as network devices based on general purpose processors, are notoriously ineffective for self-similar input flows.
Network processors (NP), specialized units have succeeded to general purpose processors, are widely used at various levels of the protocol stack. However, their primary purpose is to route high-speed packet flows in the core of the Internet. Given the increasing bandwidth demands for computer networks, it is necessary, that the processing was carried out with a flow rate of a channel, that is connected to the router.
Besides, network processors, as well as general-purpose processors, provide ample opportunities for programming. Programmable architectures, parallel and pipeline processing can extend the field of application of multicore NP.
1. Theme actuality
The growing intensity of data exchange, the need to provide high quality of service for network applications, taking into account the recurring delays in data transmission and packet loss in low performance and limited resources of memory make general-purpose processors not applicable in the tasks of routing and network management. This increases the actuality of designing high-performance specialized network processors and its software.
Network processors performance is fully dependent on the effective choice of architecture parameters, performance of adaptive algorithms for packet analysis and optimal use of the hardware resources of the system. At the same time, the development of hardware solutions and programming of multiple design variants entails significant physical, intellectual and time costs. Consequently, the particular importance has the task of creating complex analytical and simulation models to perform studies of the characteristics of possible network processors architectures, as well as the processing and analysis of the estimates.
2. Goal and tasks of research
The aim of the study is to improve the efficiency of the network processors architectures design process.
Main tasks of research:
- The study of network processors applications.
- Analysis of the architecture and software of modern network processors.
- The study of existing methods, approaches and methods for NP modeling.
- Design and implementation of mathematical models to research the properties of network processors architectures.
- Creating simulation models of input traffic flow for NP.
- Experiments on models, results processing and analysis.
Research object: packet processing by network processors.
Research subject: models to evaluating the efficiency of multithreaded-multiprocessor network processors architectures, specification of network processors hardware and software resources.
3. Overview of researches and developments
The issues of network processors architectures modeling are widely covered in the works of American, European, Taiwanese researchers, scientists from the Middle East, India, China and Israel, to a lesser extent – by national authors. However, the known methods of NP research have a number of disadvantages, and there is no existing common methodology and approach to the modeling of network processors.
There are several basic parallel systems architecture types, the great part of networks processors is based on: SS (super-scalar processor), FGMT (fine-grained multithreaded processor), CMP (single chip multiprocessor), SMT (simultaneous multithreaded processor) [3-8]. The methodologies, approaches and methods for modeling of CMP-based architectures are proposed in [9-17]. Network processors performance may depend not only on the type and parameters of the network processor architectures and characteristics of network applications, but also on the work of queue management algorithms, applications and efficient workload sharing [18-25].
National researches are presented by works of Ph.D. Y. Ladyzhensky and his Ph.D. students V. Grishchenko and M. Younis [26-36].
4. Markov model for evaluation of heterogeneous CMP architectures
The model considers I processors, each of which contains J threads [17]. When a packet arrives at an idle thread, the thread either enters the ready queue of the processor waiting for execution or enters the active status, if no thread is currently active. Sometimes it issues a memory access to, for instance, perform table lookups and manipulate packet descriptors. Once serviced, it re-enters the ready queue or goes directly back to execution, if the ready queue is empty. Normally, the thread becomes idle again, after the packet is processed and passed to the succeeding thread. Nonetheless, it may get stuck and enter the finished status if the succeeding thread is busy with a packet.
We can formally define a state of the system as:
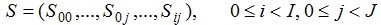
where 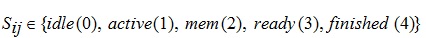 represents the status of
represents the status of 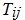 jth thread in processor i.
jth thread in processor i.
We construct a continuous Markov model to calculate the probabilities of the states and the performance NP characteristics. Simulation is performed only for the set of reachable states. This allows to save the memory resource and simulation time.
The example of packet processing by simulated system with two processors is shown in Figure 1.
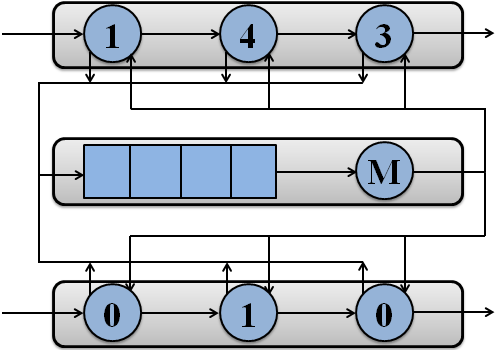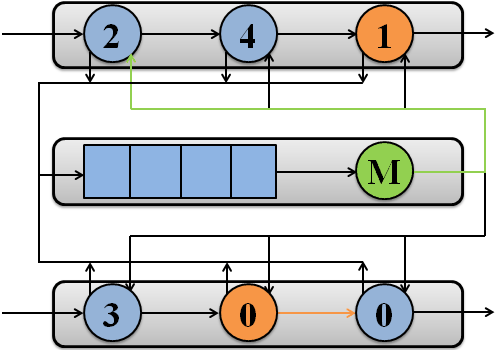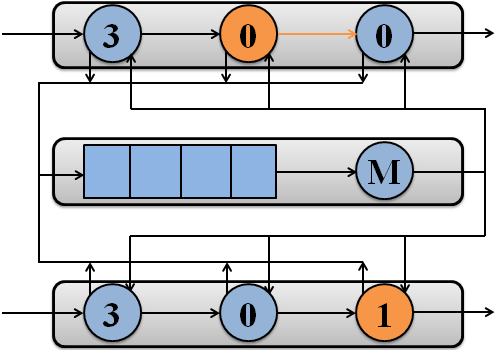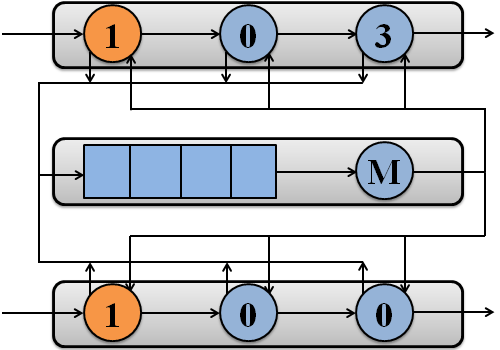
Figure 1 – Packet processing by simulated system with two processors
(animation: 7 frames, 7 cycles of repeating, 108 kilobytes)
(M – memory subsystem)
Suppose that the simulated architecture is defined by the following parameters:  .
Figures 2 and 3 shows the dependences of the memory and processors workload on the packet arrival rate and memory performance for the specified initial values.
.
Figures 2 and 3 shows the dependences of the memory and processors workload on the packet arrival rate and memory performance for the specified initial values.
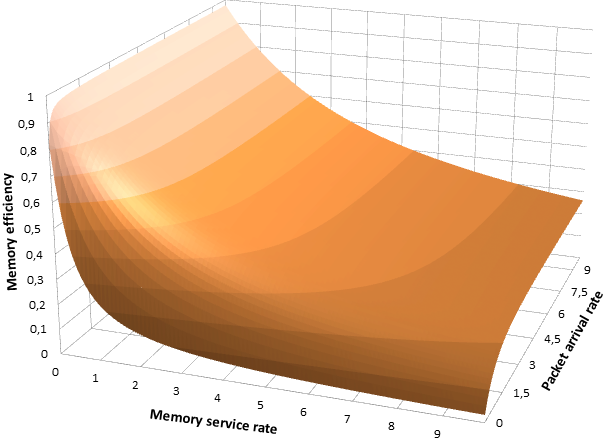
Figure 2 – Memory efficiency chart
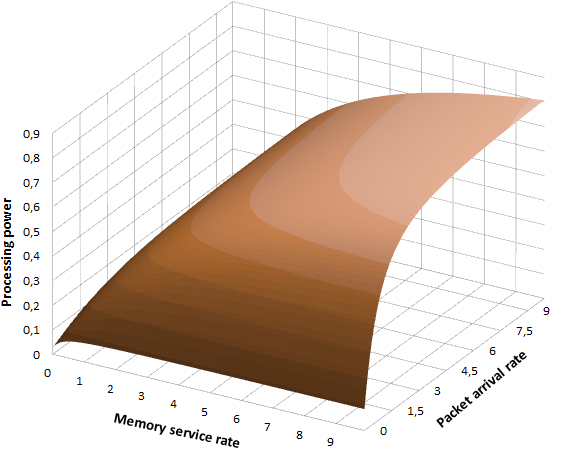
Figure 3 – Processing power chart
Quality of growth of investigated estimates is determined by the memory service rate. For small rate values performance metrics quickly reach a sustainability state, which is expressed in a significant percent of failures in service. At the same time, the increase of the memory subsystem performance causes a decrease of the memory utilization and an increase of processing power. As a consequence, system capacity is increased.
Conclusion
Experimental results show that the efficiency of the network processor largely depends on the performance of the memory subsystem. Limited memory resources may cause a decrease of processors workload. So the system failures appear, even when the packet arrival rate is low.
Master's work is dedicated to the actual scientific problem of network processors architecture modeling. In the trials carried out:
- The structure of the software that allows to explore the network processors performance is designed.
- Performed simulation of NP input traffic and studied it's properties.
- The analytical continuous-time model of CMP-based heterogeneous network processor architecture is implemented.
- Obtained and studied the architecture's efficiency indexes dependence on the packet arrival rate and other parameters.
Further studies focused on the following aspects:
- Expansion of the analytical model by adding the load balancing unit.
- Design of analytical models with discrete time, as well as a number of discrete-event simulation models and functional models on Petri networks.
This master's work is not completed yet. Final completion: December 2013. The full text of the work and materials on the topic can be obtained from the author or his head after this date.
References
- “Фрактальная катастрофа” TCP/IP [Электронный ресурс]. Режим доступа:
http://itc.ua/articles/_fraktalnaya_katastrofa_tcp_ip_5571/
- Зюльков И.А. Самоподобные свойства трафика систем с повторными вызовами / И.А. Зюльков // Вестник ВГУ. – 2002. – (Серия “Физика, математика”). – № 1. – С. 20-26.
- Musoll E., Nemirovsky M. Design Space Exploration of High-Performance Parallel Architectures / E. Musoll, M. Nemirovsky // Journal Integrated Circuits and Systems. – 2008. – vol. 3 (1). – pp. 32-38.
- Crowley P., Fiuczynski M.E., Baer J.-L., Bershad B.N. Characterizing Processor Architectures for Programmable Network Interfaces / P. Crowley, M.E. Fiuczynski, J.-L. Baer, B.N. Bershad // Proceedings of the 14th international conference on Supercomputing. – 2000. – pp. 54-65.
- Crowley P., Fiuczynski M.E., Baer J.-L. On the Performance of Multithreaded Architectures for Network Processors // Technical report. – 2000.
- Koohi M., Bayadi H., Khaless M.N. A simulation environment for network processor based on simultaneous multi thread architecture / M. Koohi, H. Bayadi, M.N. Khaless // Indian Journal of Science and Technology. – 2004. – vol. 5 (10). – pp. 3384–3389.
- Kapil S., McGhan H., Lawrendra J. A chip multithreaded processor for network-facing workloads / S. Kapil, H. McGhan, J. Lawrendra // Journal IEEE Micro. – 2004. – vol. 24 (2). – pp. 20-30.
- Fedorova A., Seltzer M., Small C., Nussbaum D. Performance of multithreaded chip multiprocessors and implications for operating system design / A. Fedorova, M. Seltzer, C. Small, D. Nussbaum // ATEC '05 Proceedings of the annual conference on USENIX Annual Technical Conference. – 2005. – pp. 26-29.
- Franklin M.A., Wolf T. A Network Processor Performance and Design Model with Benchmark Parameterization / M.A. Franklin, T. Wolf // Proceedings of International Symposium on High-Performance Computer Architecture. – 2002. – pp. 63-74.
- Wolf T., Franklin M.A. Performance models for network processor design / T. Wolf, M.A. Franklin // IEEE Transactions on Parallel and Distributed Systems. – 2006. – vol. 17 (6). – pp. 548–561.
- Ali F.H., Ahmed O.F. Modeling and Analysis of IXP425 Network Processor / F.H. Ali, O.F. Ahmed // Al-Rafadain Engineering Journal. – 2012. – vol. 20 (2). – pp. 116-130.
- Gries M., Kulkarni C., Sauer C., Keutzer K. Comparing Analytical Modeling with Simulation for Network Processors: A Case Study / M. Gries, C. Kulkarni, C. Sauer, K. Keutzer // Proceeding DATE '03 Proceedings of the conference on Design, Automation and Test in Europe: Designers' Forum. – 2003. – vol. 2. – pp. 256-261.
- Govind S., Govindarajan R. Performance Modeling and Architecture Exploration of Network Processors / S. Govind, R. Govindarajan // Second International Conference on the Quantitative Evaluation of Systems. – 2005. – pp. 189-198.
- Govind S., Govindarajan R., Kuri J. Packet Reordering in Network Processors / S. Govind, R. Govindarajan, J. Kuri // Parallel and Distributed Processing Symposium. – 2007. – pp. 1-10.
- Ramamurthi V., McCollum J., Ostler C., Chatha K.S. System Level Methodology for Programming CMP based Multi-threaded Network Processor Architectures / V. Ramamurthi, J. McCollum, C. Ostler, K.S. Chatha // ISVLSI '05 Proceedings of the IEEE Computer Society Annual Symposium on VLSI: New Frontiers in VLSI Design. – 2005. – pp. 110-116.
- Lakshmanamurthy S., Liu K.-Y., Pun Y., Huston L., Naik U. Network Processor Performance Analysis Methodology / S. Lakshmanamurthy, K.-Y. Liu, Y. Pun, L. Huston, U. Naik // Intel Technology Journal. – 2002. – vol. 6 (3). – pp. 19-28.
- Lin Y.-N., Lin Y.-D., Lai Y.-C. Thread Allocation in CMP-based Multithreaded Network Processors / Y.-N. Lin, Y.-D. Lin, Y.-C. Lai // Parallel Computing. – 2010. – vol. 36 (2-3). – pp. 104-116.
- Papaefstathiou I., Orphanoudakis T., Kornaros G., Kachris C., Mavroidis I., Nikologiannis A. Queue Management in Network Processors / I. Papaefstathiou, T. Orphanoudakis, G. Kornaros, C. Kachris, I. Mavroidis, A. Nikologiannis // Proceedings of the Design, Automation and Test in Europe Conference and Exhibition (DATE '05). – 2005. – pp. 112-117.
- Menasce D.A., Saha D., Porto S.C. Da S., Almeida V.A. F., Tripathi S.K. Static and Dynamic Processor Scheduling Disciplines in Heterogeneous Parallel Architectures / D.A. Menasce, D. Saha , S.C. Da S. Porto , V.A. F. Almeida , S.K. Tripathi // Journal of Parallel and Distributed Computing. – 1995. – vol. 28 (1). – pp. 1-18.
- D. Pan, Y. Yang. Buffer Management for Lossless Service in Network Processors / Pan D., Yang. Y. // 14th IEEE Symposium on High-Performance Interconnects. – 2006. – pp. 81-86.
- Kencl L., Boudec Le J.-Y. Adaptive Load Sharing for Network Processors / L. Kencl, J.-Y. Le Boudec // IEEE/ACM Transactions on Networking. – 2008. – vol. 16 (2). – pp. 293-306.
- Keslassy I., Kogan K., Scalosub G., Segal M. Providing Performance Guarantees in Multipass Network Processors / I. Keslassy, K. Kogan, G. Scalosub, M. Segal // IEEE/ACM Transactions on Networking. – 2012. – vol. 20 (6). – pp. 1895-1909.
- Shpiner A., Keslassy I., Cohen R. Reducing the Reordering Delay in Multi-Core Network Processors // Technical report. – 2012.
- Evaluating Dynamic Task Mapping in Network Processor Runtime Systems / X. Huang, T. Wolf // IEEE Transactions on Parallel and Distributed Systems. – 2007. – pp. 1086-1098.
- Wolf T., Pappu P., Franklin M.A. Predictive scheduling of network processors / T. Wolf, P. Pappu, M.A. Franklin // Computer Networks: The International Journal of Computer and Telecommunications Networking – Network processors. – 2003. – vol. 41 (5). – pp. 601-621.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Перспективные архитектуры и тенденции развития современных сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Материалы IV международной научно-технической конференции “Моделирование и компьютерная графика – 2011”. – Донецк, 2011. – С. 93-97.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Основные направления развития современных сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия “Інформатика, кібернетика та обчислювальна техніка”). – № 14 (188). – С. 123-127.
- Юнис М., Грищенко В.И., Ладыженский Ю.В. Обобщенная структура сетевых процессоров / М. Юнис, В.И. Грищенко, Ю.В. Ладыженский // Материалы VII международной научно-технической конференции студентов, аспирантов и молодых ученых “Информатика и компьютерные технологии – 2011”. – Донецк, 2011. – С. 386-391.
- Ладыженский Ю.В., Грищенко В.И. Моделирование сетевых процессоров пакетной обработки данных / Ю.В. Ладыженский, В.И. Грищенко // Материалы международной научно-практической конференции “Интернет – Образование – Наука – 2006”. – Виница, 2006. – Т. 2. – С. 417-422.
- Ладыженский Ю.В., Грищенко В.И. Программирование процессоров обработки пакетов в компьютерных сетях / Ю.В. Ладыженский, В.И. Грищенко // Матеріали міжнародної науково-практичної конференції “Сучасні проблеми і досягнення в галузі радіотехніки, телекомунікацій та інформаційних технологій”. – Запорожье, 2006. – C. 159-161.
- Грищенко В.И., Ладыженский Ю.В. Моделирование работы приложений на сетевых процессорах / В.И. Грищенко, Ю.В. Ладыженский // Материалы международной научно-практической конференции “Моделирование и компьютерная графика – 2007”. – Донецк, 2007. – С. 167-173.
- Грищенко В.И., Ладыженский Ю.В. Исследование архитектуры кэша сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский // Науково-технічний журнал “Радіоелектронні і комп’ютерні системи”. – № 6 (25). – С. 186-192.
- Ладиженский Ю.В., Грищенко В.И. Влияние политики замещения записей в кэше на производительность сетевого процессора / Ю.В. Ладыженский, В.И. Грищенко // Наукові праці ДонНТУ. – Донецк, 2007. – (Серия “Обчислювальна техніка та автоматизація”). – № 12 (118). – С. 114-119.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Влияние выделенного кэша команд на производительность сетевого процессора / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия “Інформатика, кібернетика та обчислювальна техніка”). – № 13 (185). – С. 85-91.
- Грищенко В.И., Ладыженский Ю.В. Оптимизация методики моделирования кэша сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский // Материалы III международной научно-технической конференции “Моделирование и компьютерная графика – 2009”. – Донецк, 2009. – C. 249-254.
- Грищенко В.И., Ладыженский Ю.В. Исследование влияния раздельной памяти на производительность многоядерного сетевого процессора / В.И. Грищенко, Ю.В. Ладыженский // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия “Проблеми моделювання та автоматизації проектування”). – № 9 (179).