
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд досліджень та розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд локальних джерел
- 4. Марківська модель для аналізу ефективності гетерогенних CMP архітектур мережних процесорів
- Висновки
- Перелік посилань
Вступ
Вимоги до пропускної спроможності комп'ютерних мереж з кожним роком постійно підвищуються. Крім того, численні експериментальні дослідження показують, що потоки в сучасних мережах не є найпростішими, а мають істотну післядію та самоподібність. Самоподібний процес характеризується наявністю викидів при відносно низькій швидкості потоку, що викликає значні втрати пакетів, навіть коли сумарна потреба в обслуговуванні далека від максимально припустимих значень [1]. Це явище пояснюється урахуванням лише усереднених властивостей трафіку в розрахунку необхідних характеристик мережного обладнання. Зокрема, при збільшенні розміру буфера на вході маршрутизатора ймовірність втрат падає значно повільніше, ніж для експоненціального закону, використовуваного в класичних моделях телетрафіку [2]. Таким чином, алгоритми обробки трафіку, орієнтовані на роботу з найпростішим потоком, а також мережні пристрої, які базуються на процесорах загального призначення, є вкрай неефективними для самоподібних вхідних потоків.
Мережні процесори (МП), спеціалізовані пристрої, що прийшли на зміну процесорам загального призначення, активно використовуються на різних рівнях стека протоколів. Проте їх головним призначенням є маршрутизація високошвидкісних потоків пакетів у ядрі Інтернет. Враховуючи підвищення вимог до пропускної спроможності комп'ютерних мереж, необхідно, щоб обробка потоків здійснювалася зі швидкістю каналу, до якого підключений маршрутизатор.
Крім того, мережні процесори, як і процесори загального призначення, надають широкі можливості з програмування. Програмованість архітектури, можливості паралельної і конвеєрної обробки дозволяють розширити області застосування багатоядерних МП.
1. Актуальність теми
Зростання інтенсивності обміну даними, необхідність забезпечення високої якості обслуговування мережних програм, облік періодично виникаючих затримок у передачі даних і втрати пакетів при недостатній продуктивності і обмежених ресурсах пам'яті роблять процесори загального призначення непридатними в задачах маршрутизації та управління мережею. Це збільшує актуальність проблеми створення високопродуктивних спеціалізованих мережних процесорів і їх програмного забезпечення.
Продуктивність мережних процесорів повністю залежить від ефективного вибору параметрів архітектури, швидкодії адаптивних алгоритмів аналізу пакетів, оптимального використання апаратних ресурсів системи. У той же час розробка апаратного рішення і програмування безлічі варіантів проектування МП призводить до істотних матеріальних, інтелектуальних і часових витрат. Отже, особливої важливості набуває задача створення комплексу аналітичних та імітаційних моделей, що дозволяють виконати дослідження характеристик ймовірних архітектур мережних процесорів, а також обробку та аналіз отриманих оцінок.
2. Мета і задачі дослідження та заплановані результати
Метою дослідження є підвищення ефективності процесу проектування архітектур мережних процесорів.
Для досягнення мети в магістерській роботі вирішуються такі основні задачі дослідження:
- Вивчення областей застосування мережних процесорів.
- Аналіз архітектури та програмного забезпечення сучасних мережних процесорів.
- Дослідження існуючих методик, підходів і методів моделювання МП.
- Розробка та програмна реалізація математичних моделей для дослідження властивостей архітектур мережних процесорів.
- Створення імітаційних моделей потоків вхідного трафіку МП.
- Проведення експериментів на моделях, обробка та аналіз результатів.
Об'єкт дослідження: процес обробки потоків пакетів мережними процесорами.
Предмет дослідження: моделі для оцінки ефективності багатопоточних-багатопроцесорних архітектур мережних процесорів, характеристики апаратних і програмних ресурсів МП.
В рамках магістерської роботи планується отримання актуальних наукових результатів за наступними напрямками:
- Побудова аналітичної моделі для оцінки продуктивності паралельних гетерогенних CMP архітектур МП.
- Розробка набору імітаційних моделей потоків пакетів вхідного трафіку різного виду, що надходить на вхід мережного процесора.
- Отримання і подальше дослідження результатів моделювання для виявлення залежностей показників ефективності архітектури МП від її основних параметрів.
В якості практичних результатів планується розробка програмного комплексу для дослідження ефективності мережних процесорів, що включає в себе наступні компоненти:
- Підсистема введення параметрів моделі.
- Підсистема аналітичного моделювання МП, що виконує розрахунок показників ефективності архітектури з заданими параметрами.
- Підсистема імітаційного моделювання, до складу якої входять розроблені моделі вхідного трафіку.
- Підсистема аналізу результатів моделювання, яка призначена для виведення на екран показників ефективності, внутрішньої інформації про поточну модель, а також візуалізації залежностей з використанням як стандартних засобів мови C# і платформи .Net Framework 4.0, так і з застосуванням технології OLE для програмної взаємодії з табличним процесором MS Excel.
3. Огляд досліджень та розробок
У процесі проектування МП головною проблемою є вибір найбільш ефективної архітектури, що передбачає визначення числа процесорних елементів (обчислювальних ядер), їх можливостей щодо багатопоточної обробки пакетів, способу розміщення на кристалі функціональних блоків процесора і взаємозв'язків між ними, обсягів внутрішньої та зовнішньої пам'яті, а також інших не менш важливих параметрів. Тому питання моделювання архітектур мережних процесорів широко висвітлюється в роботах американських, європейських, тайваньських дослідників, науковців з Близького Сходу, Індії, Китаю та Ізраїлю, у меншій мірі – вітчизняних авторів. Однак відомі методи дослідження МП мають істотні недоліки, і на даний момент не розроблено єдиної методології та загального підходу до моделювання мережних процесорів.
3.1 Огляд міжнародних джерел
Існує декілька базових типів архітектур паралельних систем, що лежать в основі більшості мережних процесорів: SS (super-scalar processor), FGMT (fine-grained multithreaded processor), CMP (single chip multiprocessor), SMT (simultaneous multithreaded processor) [3]. P. Crowley, M.E. Fiuczynski, J.-L. Baer, і B.N. Bershad у своїй статті [4] виконали аналіз даних архітектур стосовно предметної області МП і їх оцінку з використанням апарату імітаційного моделювання. Ряд експериментів, спрямованих на отримання різних оцінок, показав значну перевагу SMT і CMP архітектур, виходячи з критерію завантаження як існуючих додатків, так і програм, які будуть виконуватися на МП у майбутньому. У подальшій роботі цієї ж групи дослідників [5] показано, що CMP і SMT архітектури демонструють приблизно рівну високу продуктивність. Різниця між ними полягає у відносній простоті апаратної (CMT) і програмної складових (SMT) відповідно.
Середовище моделювання SNP (“Simulator of Network Processor”), що призначене для моделювання типових SMT архітектур мережних процесорів, було розроблено індійськими вченими M. Koohi, H. Bayadi і M.N. Khaless [6]. Система грунтується на методі “clock-by-clock”. Відмінними рисами симулятора є його багатопоточна природа і можливість моделювання в тому числі мережного оточення, генераторів трафіку та мережного контролера, підключеного до МП.
Стаття [7] присвячена аналізу можливостей CMT архітектури, орієнтованої на обробку великої кількості потоків з низькими потребами в обслуговуванні. В [8] пропонується алгоритм планування для зниження числа промахів кеша другого рівня, який є критичним ресурсом процесора, і збільшення пропускної спроможності системи.
Методології, підходи та методи моделювання мережних процесорів на базі CMP архітектур описані в роботах [9-17]. В [9-10] представлена аналітична модель, що дозволяє визначити продуктивність обробки пакетів мережним процесором, оцінити необхідну площу кристала та рівень енергоспоживання. Модель враховує кількість процесорних елементів на чіпі, їх багатопоточні властивості, розміри внутрішньої пам'яті (на чіпі) і кеша для команд, а також потрібну кількість зовнішніх по відношенню до кристалу каналів пам'яті.
Моделюванню мережних процесорів сімейства Intel IXP присвячені статті [11-16]. Розроблені аналітична та імітаційна моделі процесора IXP425 [11], що працює в основі VPN-шлюза. Для цього були використані ланцюги Маркова та симулятор Omnet++. Досліджено параметри системи МП і її “вузькі місця”, приділяючи особливу увагу розмірам буфера.
В [12] розроблено програмне забезпечення для комутатора, який пересилає IP4 пакети, та досліджено його відображення на мережний процесор Intel IXP1200. Виконано порівняння аналітичного та імітаційного підходів до моделювання МП і отримана оцінка точності аналітичних моделей мережного додатку та архітектури процесора, призначених для оцінки можливих варіантів проектування. У публікаціях [13-14] представлені імітаційні моделі на основі мереж Петрі для процесорів Intel IXP, що дозволяють оцінювати продуктивність додатків і архітектур, ефективність їх взаємодії, а також ступеня зміни порядку пакетів для додатків, які пересилають IP4 пакети.
Методологія системного рівня для розв'язання проблеми функціональності процесорних елементів і відображення структур даних додатків на блоки пам'яті мережного процесора з CMP архітектурою запропонована в [15]. Стаття містить опис програмної моделі та розроблених методів оптимізації. Методологія, розглянута в [16], спрямована на вирішення задач аналізу ефективності різних мережних додатків, що працюють на процесорі Intel IXP2400. Ця методологія передбачає розбиття додатків на блоки, що утворюють конвеєр, і оцінку обчислювальних вимог та вимог введення-виведення, а також запасів за навантаженням для кожного блоку. Визначається найбільш ефективне відображення блоків додатку на апаратні ресурси. Однак у даній роботі не враховується коефіцієнт використання процесорів і підсистеми пам'яті, та недостатньо досліджені підходи до проектування мережних процесорів [17].
У статті Y.-N. Lin. Y.-D. Lin. Y.-C. Lai [17] описані переваги та недоліки традиційних багатопоточних-багатопроцесорних архітектур мережних процесорів. Запропоновано аналітичну модель з безперервним часом та імітаційну модель на базі мереж Петрі. Підхід, використаний у роботі, враховує вплив пам'яті та черги готових до виконання на процесорі потоків, що часто ігнорується в інших публікаціях. Розроблено концепцію Р-М співвідношення, де Р і М являють собою обчислювальні навантаження та накладні витрати на доступ до пам'яті, викликані роботою програми. Виконана оцінка залежності між різними Р-М співвідношеннями і відповідним їм числом потоків на процесорі. Описані також способи усунення ефекту “вузького місця”, що виникає при малих Р-М співвідношеннях.
Продуктивність мережних процесорів може залежати не тільки від типу та параметрів архітектур мережних процесорів і характеристик мережних додатків, але також від роботи алгоритмів керування чергами заявок та ефективного розподілу навантаження по обчислювальним елементам [18-25].
3.2 Огляд локальних джерел
Національні дослідження проблем проектування та моделювання мережних процесорів представлені науковими роботами доцента кафедри прикладної математики та інформатики Донецького національного технічного університету Ю.В. Ладиженського і його аспірантів В.І. Грищенко та М. Юніса [26-36].
В публікаціях [26-28] описані особливості сучасних мережних процесорів, проведено аналіз технічних характеристик і функціональних можливостей найбільш перспективних МП для високонавантажених систем. Запропоновано узагальнену структуру типового багатоядерного мережного процесора.
Роботи [29-31] присвячені питанням моделювання та програмування пакетних мережних процесорів, а також моделюванню роботи додатків на МП.
У статтях [32-36] запропоновані аналітичні моделі МП і методика дослідження впливу архітектури кеша на продуктивність процесора. Експериментальним шляхом визначено оптимальні розміри кешей команд і даних для виконання задач обробки заголовків мережних пакетів, роботи з переданими даними та вирішення класичних задач маршрутизації. Вивчено вплив політики заміщення блоків у множинно-асоціативному кеші на продуктивність мережного процесора. Досліджено продуктивність структури мережного процесора з кешем команд, достатньо великим для розміщення всього програмного коду. Розроблено підхід, що дозволяє мінімізувати час, що витрачається на імітаційну частину комплексної методики за рахунок використання аналітичної моделі промахів кеша. В [36] представлена модель МП з роздільною пам'яттю для коду та даних і зроблене порівняння ефективності мережних процесорів із загальною та роздільною пам'яттю.
4. Марківська модель для аналізу ефективності гетерогенних CMP архітектур мережних процесорів
Модель системи складається з I процесорів, кожний з яких має J потоків [17]. Коли пакет надходить у вільний потік, даний потік розміщується в черзі готових до виконання потоків процесора або переходить в активний стан, якщо в поточний момент на процесорі немає активного потоку. Потік може запрошувати доступ до пам'яті, наприклад, для роботи з дескриптором пакета чи маршрутної таблицею. Після обслуговування в пам'яті потік поміщається в чергу готових до виконання або знову надходить на процесор, якщо ця черга порожня. Зазвичай потік знову стає вільним після того, як пакет буде обслужений і переданий наступному потоку. Однак якщо наступний потік зайнятий обслуговуванням пакета, поточний потік переходить у стан “завершений”.
Простір станів моделі є:
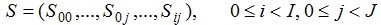
де 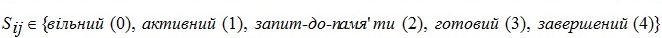 представляє собою стан
представляє собою стан 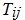 j-го потока i-го процесора.
j-го потока i-го процесора.
Будується безперервна марківська модель для розрахунку ймовірностей станів і характеристик продуктивності МП. Моделювання виконується тільки для множини досяжних станів, що істотно скорочує витрати пам'яті і часу моделювання.
Приклад обробки пакетів потоками системи на двох процесорах зображений на рисунку 1.
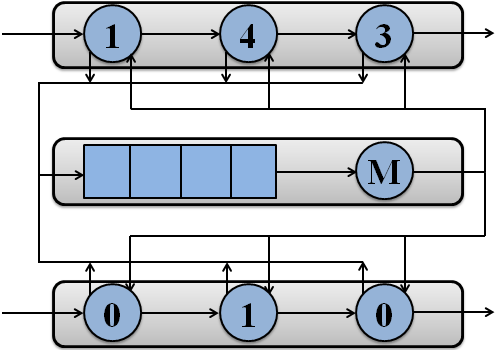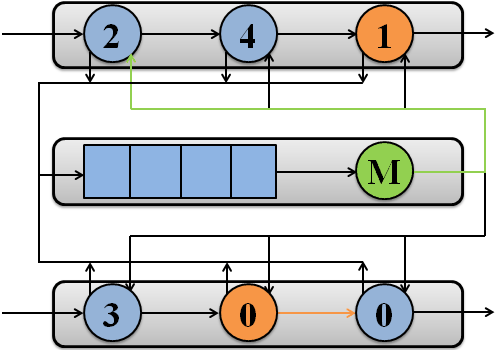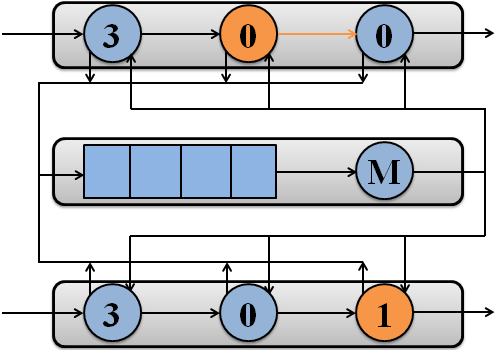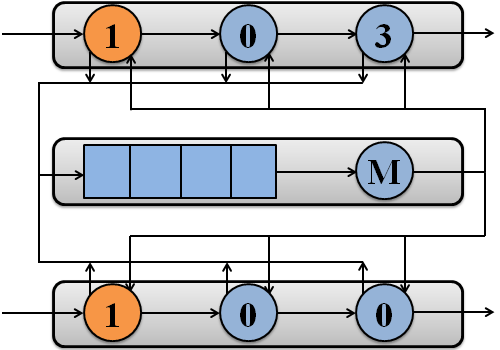
Рисунок 1 – Обробка пакетів потоками системи на двох процесорах
(анімація: 7 кадрів, 7 циклів повторення, 108 кілобайт)
(M – підсистема пам'яті)
Нехай архітектура, що моделюється, задається наступними параметрами:
 . На
рисунках 2 і 3 наведені залежності
характеристик завантаження пам'яті та процесорів від інтенсивності потоку пакетів і
продуктивності пам'яті МП для вказаних значень вихідних даних.
. На
рисунках 2 і 3 наведені залежності
характеристик завантаження пам'яті та процесорів від інтенсивності потоку пакетів і
продуктивності пам'яті МП для вказаних значень вихідних даних.
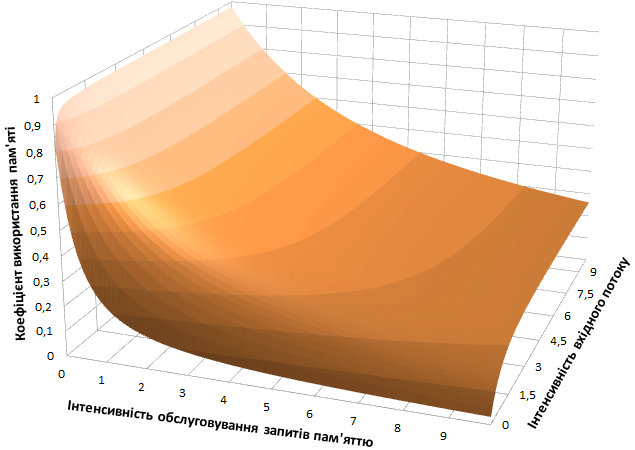
Рисунок 2 – Зміна коефіцієнта використання пам'яті
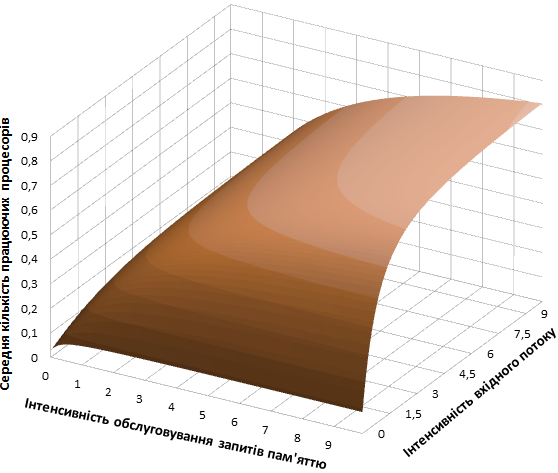
Рисунок 3 – Зміна середньої кількості працюючих процесорів
Якість росту досліджуваних оцінок визначається величиною інтенсивності обслуговування заявок підсистемою пам'яті. При малих її значеннях показники ефективності швидше досягають стабільності, яка на практиці виражається в наявності істотного процента відмов в обслуговуванні. У той же час збільшення продуктивності пам'яті призводить до зниження коефіцієнта її використання та зростання завантаження процесора. Як наслідок, пропускна спроможність системи збільшується.
Висновки
Результати проведених експериментів свідчать про те, що ефективність мережного процесора значною мірою залежить від продуктивності підсистеми пам'яті. Обмеження ресурсів пам'яті може призвести до зниження коефіцієнта завантаження процесорів і виявлятися у появі відмов системи при порівняно невеликих інтенсивностях вхідного потоку.
Магістерська робота присвячена актуальній науковій задачі моделювання архітектур мережних процесорів. У рамках проведених досліджень виконано:
- Розроблена структура програмного комплексу, який дозволяє досліджувати продуктивність мережних процесорів.
- Виконано імітаційне моделювання вхідного трафіку МП і вивчено його властивості.
- Програмно реалізована аналітична модель з безперервним часом для гетерогенної CMP архітектури мережного процесора.
- Отримано і досліджено залежності показників ефективності архітектури від інтенсивності вхідного потоку пакетів та інших параметрів.
Подальші дослідження направлені на наступні аспекти:
- Розширення аналітичної моделі за рахунок додавання в неї блоку балансування завантаження, яке надходить на процесорні елементи.
- Розробка аналітичних моделей з дискретним часом, а також ряду імітаційних дискретно-подійних функціональних моделей і моделей на мережах Петрі.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2013 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після вказаної дати.
Перелік посилань
- “Фрактальная катастрофа” TCP/IP [Электронный ресурс]. Режим доступа:
http://itc.ua/articles/_fraktalnaya_katastrofa_tcp_ip_5571/
- Зюльков И.А. Самоподобные свойства трафика систем с повторными вызовами / И.А. Зюльков // Вестник ВГУ. – 2002. – (Серия “Физика, математика”). – № 1. – С. 20-26.
- Musoll E., Nemirovsky M. Design Space Exploration of High-Performance Parallel Architectures / E. Musoll, M. Nemirovsky // Journal Integrated Circuits and Systems. – 2008. – vol. 3 (1). – pp. 32-38.
- Crowley P., Fiuczynski M.E., Baer J.-L., Bershad B.N. Characterizing Processor Architectures for Programmable Network Interfaces / P. Crowley, M.E. Fiuczynski, J.-L. Baer, B.N. Bershad // Proceedings of the 14th international conference on Supercomputing. – 2000. – pp. 54-65.
- Crowley P., Fiuczynski M.E., Baer J.-L. On the Performance of Multithreaded Architectures for Network Processors // Technical report. – 2000.
- Koohi M., Bayadi H., Khaless M.N. A simulation environment for network processor based on simultaneous multi thread architecture / M. Koohi, H. Bayadi, M.N. Khaless // Indian Journal of Science and Technology. – 2004. – vol. 5 (10). – pp. 3384–3389.
- Kapil S., McGhan H., Lawrendra J. A chip multithreaded processor for network-facing workloads / S. Kapil, H. McGhan, J. Lawrendra // Journal IEEE Micro. – 2004. – vol. 24 (2). – pp. 20-30.
- Fedorova A., Seltzer M., Small C., Nussbaum D. Performance of multithreaded chip multiprocessors and implications for operating system design / A. Fedorova, M. Seltzer, C. Small, D. Nussbaum // ATEC '05 Proceedings of the annual conference on USENIX Annual Technical Conference. – 2005. – pp. 26-29.
- Franklin M.A., Wolf T. A Network Processor Performance and Design Model with Benchmark Parameterization / M.A. Franklin, T. Wolf // Proceedings of International Symposium on High-Performance Computer Architecture. – 2002. – pp. 63-74.
- Wolf T., Franklin M.A. Performance models for network processor design / T. Wolf, M.A. Franklin // IEEE Transactions on Parallel and Distributed Systems. – 2006. – vol. 17 (6). – pp. 548–561.
- Ali F.H., Ahmed O.F. Modeling and Analysis of IXP425 Network Processor / F.H. Ali, O.F. Ahmed // Al-Rafadain Engineering Journal. – 2012. – vol. 20 (2). – pp. 116-130.
- Gries M., Kulkarni C., Sauer C., Keutzer K. Comparing Analytical Modeling with Simulation for Network Processors: A Case Study / M. Gries, C. Kulkarni, C. Sauer, K. Keutzer // Proceeding DATE '03 Proceedings of the conference on Design, Automation and Test in Europe: Designers' Forum. – 2003. – vol. 2. – pp. 256-261.
- Govind S., Govindarajan R. Performance Modeling and Architecture Exploration of Network Processors / S. Govind, R. Govindarajan // Second International Conference on the Quantitative Evaluation of Systems. – 2005. – pp. 189-198.
- Govind S., Govindarajan R., Kuri J. Packet Reordering in Network Processors / S. Govind, R. Govindarajan, J. Kuri // Parallel and Distributed Processing Symposium. – 2007. – pp. 1-10.
- Ramamurthi V., McCollum J., Ostler C., Chatha K.S. System Level Methodology for Programming CMP based Multi-threaded Network Processor Architectures / V. Ramamurthi, J. McCollum, C. Ostler, K.S. Chatha // ISVLSI '05 Proceedings of the IEEE Computer Society Annual Symposium on VLSI: New Frontiers in VLSI Design. – 2005. – pp. 110-116.
- Lakshmanamurthy S., Liu K.-Y., Pun Y., Huston L., Naik U. Network Processor Performance Analysis Methodology / S. Lakshmanamurthy, K.-Y. Liu, Y. Pun, L. Huston, U. Naik // Intel Technology Journal. – 2002. – vol. 6 (3). – pp. 19-28.
- Lin Y.-N., Lin Y.-D., Lai Y.-C. Thread Allocation in CMP-based Multithreaded Network Processors / Y.-N. Lin, Y.-D. Lin, Y.-C. Lai // Parallel Computing. – 2010. – vol. 36 (2-3). – pp. 104-116.
- Papaefstathiou I., Orphanoudakis T., Kornaros G., Kachris C., Mavroidis I., Nikologiannis A. Queue Management in Network Processors / I. Papaefstathiou, T. Orphanoudakis, G. Kornaros, C. Kachris, I. Mavroidis, A. Nikologiannis // Proceedings of the Design, Automation and Test in Europe Conference and Exhibition (DATE '05). – 2005. – pp. 112-117.
- Menasce D.A., Saha D., Porto S.C. Da S., Almeida V.A. F., Tripathi S.K. Static and Dynamic Processor Scheduling Disciplines in Heterogeneous Parallel Architectures / D.A. Menasce, D. Saha , S.C. Da S. Porto , V.A. F. Almeida , S.K. Tripathi // Journal of Parallel and Distributed Computing. – 1995. – vol. 28 (1). – pp. 1-18.
- D. Pan, Y. Yang. Buffer Management for Lossless Service in Network Processors / Pan D., Yang. Y. // 14th IEEE Symposium on High-Performance Interconnects. – 2006. – pp. 81-86.
- Kencl L., Boudec Le J.-Y. Adaptive Load Sharing for Network Processors / L. Kencl, J.-Y. Le Boudec // IEEE/ACM Transactions on Networking. – 2008. – vol. 16 (2). – pp. 293-306.
- Keslassy I., Kogan K., Scalosub G., Segal M. Providing Performance Guarantees in Multipass Network Processors / I. Keslassy, K. Kogan, G. Scalosub, M. Segal // IEEE/ACM Transactions on Networking. – 2012. – vol. 20 (6). – pp. 1895-1909.
- Shpiner A., Keslassy I., Cohen R. Reducing the Reordering Delay in Multi-Core Network Processors // Technical report. – 2012.
- Evaluating Dynamic Task Mapping in Network Processor Runtime Systems / X. Huang, T. Wolf // IEEE Transactions on Parallel and Distributed Systems. – 2007. – pp. 1086-1098.
- Wolf T., Pappu P., Franklin M.A. Predictive scheduling of network processors / T. Wolf, P. Pappu, M.A. Franklin // Computer Networks: The International Journal of Computer and Telecommunications Networking – Network processors. – 2003. – vol. 41 (5). – pp. 601-621.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Перспективные архитектуры и тенденции развития современных сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Материалы IV международной научно-технической конференции “Моделирование и компьютерная графика – 2011”. – Донецк, 2011. – С. 93-97.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Основные направления развития современных сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия “Інформатика, кібернетика та обчислювальна техніка”). – № 14 (188). – С. 123-127.
- Юнис М., Грищенко В.И., Ладыженский Ю.В. Обобщенная структура сетевых процессоров / М. Юнис, В.И. Грищенко, Ю.В. Ладыженский // Материалы VII международной научно-технической конференции студентов, аспирантов и молодых ученых “Информатика и компьютерные технологии – 2011”. – Донецк, 2011. – С. 386-391.
- Ладыженский Ю.В., Грищенко В.И. Моделирование сетевых процессоров пакетной обработки данных / Ю.В. Ладыженский, В.И. Грищенко // Материалы международной научно-практической конференции “Интернет – Образование – Наука – 2006”. – Виница, 2006. – Т. 2. – С. 417-422.
- Ладыженский Ю.В., Грищенко В.И. Программирование процессоров обработки пакетов в компьютерных сетях / Ю.В. Ладыженский, В.И. Грищенко // Матеріали міжнародної науково-практичної конференції “Сучасні проблеми і досягнення в галузі радіотехніки, телекомунікацій та інформаційних технологій”. – Запорожье, 2006. – C. 159-161.
- Грищенко В.И., Ладыженский Ю.В. Моделирование работы приложений на сетевых процессорах / В.И. Грищенко, Ю.В. Ладыженский // Материалы международной научно-практической конференции “Моделирование и компьютерная графика – 2007”. – Донецк, 2007. – С. 167-173.
- Грищенко В.И., Ладыженский Ю.В. Исследование архитектуры кэша сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский // Науково-технічний журнал “Радіоелектронні і комп’ютерні системи”. – № 6 (25). – С. 186-192.
- Ладиженский Ю.В., Грищенко В.И. Влияние политики замещения записей в кэше на производительность сетевого процессора / Ю.В. Ладыженский, В.И. Грищенко // Наукові праці ДонНТУ. – Донецк, 2007. – (Серия “Обчислювальна техніка та автоматизація”). – № 12 (118). – С. 114-119.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Влияние выделенного кэша команд на производительность сетевого процессора / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия “Інформатика, кібернетика та обчислювальна техніка”). – № 13 (185). – С. 85-91.
- Грищенко В.И., Ладыженский Ю.В. Оптимизация методики моделирования кэша сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский // Материалы III международной научно-технической конференции “Моделирование и компьютерная графика – 2009”. – Донецк, 2009. – C. 249-254.
- Грищенко В.И., Ладыженский Ю.В. Исследование влияния раздельной памяти на производительность многоядерного сетевого процессора / В.И. Грищенко, Ю.В. Ладыженский // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия “Проблеми моделювання та автоматизації проектування”). – № 9 (179).