
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор локальных источников
- 4. Марковская модель для анализа эффективности гетерогенных CMP архитектур сетевых процессоров
- Выводы
- Список источников
Введение
Требования к пропускной способности компьютерных сетей с каждым годом неуклонно повышаются. Кроме того, многочисленные экспериментальные исследования показывают, что потоки в современных сетях не являются простейшими, а обладают существенным последействием и самоподобием. Самоподобный процесс характеризуется наличием выбросов при относительно низкой скорости потока, что вызывает значительные потери пакетов, даже когда суммарная потребность в обслуживании далека от максимально допустимых значений [1]. Это явление объясняется учетом лишь усредненных свойств трафика в расчете требуемых характеристик сетевого оборудования. В частности, при увеличении размера буфера на входе маршрутизатора вероятность потерь падает значительно медленнее, чем для экспоненциального закона, используемого в классических моделях телетрафика [2]. Таким образом, алгоритмы обработки трафика, ориентированные на работу с простейшим потоком, а также сетевые устройства, основанные на процессорах общего назначения, являются крайне неэффективными для самоподобных входных потоков.
Сетевые процессоры (СП), специализированные устройства, пришедшие на смену процессорам общего назначения, активно используются на различных уровнях стека протоколов. Однако их главным назначением является маршрутизация высокоскоростных потоков пакетов в ядре Интернет. Учитывая повышение требований к пропускной способности компьютерных сетей, необходимо, чтобы обработка потоков осуществлялась со скоростью канала, к которому подключен маршрутизатор.
Кроме того, сетевые процессоры, как и процессоры общего назначения, предоставляют широкие возможности по программированию. Программируемость архитектуры, возможности параллельной и конвейерной обработки позволяют расширить области применения многоядерных СП.
1. Актуальность темы
Рост интенсивности обмена данными, необходимость обеспечения высокого качества обслуживания сетевых приложений, учет периодически возникающих задержек в передаче данных и потери пакетов при недостаточной производительности и ограниченных ресурсах памяти делают процессоры общего назначения неприменимыми в задачах маршрутизации и управления сетью. Это увеличивает актуальность проблемы создания высокопроизводительных специализированных сетевых процессоров и их программного обеспечения.
Производительность сетевых процессоров полностью зависит от эффективного выбора параметров архитектуры, быстродействия адаптируемых алгоритмов анализа пакетов, оптимального использования аппаратных ресурсов системы. В то же время разработка аппаратного решения и программирование множества вариантов проектирования СП влечет за собой существенные материальные, интеллектуальные и временные затраты. Следовательно, особую важность приобретает задача создания комплекса аналитических и имитационных моделей, позволяющих выполнить исследования характеристик предполагаемых архитектур сетевых процессоров, а также обработку и анализ полученных оценок.
2. Цель и задачи исследования, планируемые результаты
Целью исследования является повышение эффективности процесса проектирования архитектур сетевых процессоров.
Для достижения цели в магистерской работе решаются следующие основные задачи исследования:
- Изучение областей применения сетевых процессоров.
- Анализ архитектуры и программного обеспечения современных сетевых процессоров.
- Исследование существующих методик, подходов и методов моделирования СП.
- Разработка и программная реализация математических моделей для исследования свойств архитектур сетевых процессоров.
- Создание имитационных моделей потоков входного трафика СП.
- Проведение экспериментов на моделях, обработка и анализ результатов.
Объект исследования: процесс обработки потоков пакетов сетевыми процессорами.
Предмет исследования: модели для оценки эффективности многопоточных-многопроцессорных архитектур сетевых процессоров, характеристики аппаратных и программных ресурсов СП.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Построение аналитической модели для оценки производительности параллельных гетерогенных CMP архитектур СП.
- Разработка набора имитационных моделей потоков пакетов входного трафика различного вида, поступающего на вход сетевого процессора.
- Получение и последующее исследование результатов моделирования для выявления зависимостей показателей эффективности архитектуры СП от ее основных параметров.
В качестве практических результатов планируется разработка программного комплекса для оценки производительности сетевых процессоров, включающего в себя следующие компоненты:
- Подсистема ввода параметров модели.
- Подсистема аналитического моделирования СП, выполняющая расчет показателей эффективности архитектуры с заданными параметрами.
- Подсистема имитационного моделирования, в состав которой входят разработанные модели входного трафика.
- Подсистема анализа результатов моделирования, предназначенная для вывода на экран значений показателей эффективности, внутренней информации о текущей модели, а также визуализации зависимостей с использованием как стандартных средств языка C# и платформы .Net Framework 4.0, так и с применением технологии OLE для программного взаимодействия с табличным процессором MS Excel.
3. Обзор исследований и разработок
В процессе проектирования СП главной проблемой является выбор наиболее эффективной архитектуры, которая подразумевает определение числа процессорных элементов (вычислительных ядер), их возможностей по многопоточной обработке пакетов, способа размещения на кристалле функциональных блоков процессора и взаимосвязей между ними, объемов внутренней и внешней памяти, а также других не менее важных параметров. Поэтому вопрос моделирования архитектур сетевых процессоров широко освещается в работах американских, европейских, тайваньских исследователей, ученых из Ближнего Востока, Индии, Китая и Израиля, в меньшей степени – отечественных авторов. Однако известные методы исследования СП обладают существенными недостатками, и в настоящий момент не разработано единой методологии и общего подхода к моделированию сетевых процессоров.
3.1 Обзор международных источников
Существует несколько базовых типов архитектур параллельных систем, лежащих в основе большинства сетевых процессоров: SS (super-scalar processor), FGMT (fine-grained multithreaded processor), CMP (single chip multiprocessor), SMT (simultaneous multithreaded processor) [3]. P. Crowley, M.E. Fiuczynski, J.-L. Baer, и B.N. Bershad в своей статье [4] выполнили анализ данных архитектур применительно к предметной области СП и их оценку с использованием аппарата имитационного моделирования. Ряд экспериментов, направленных на получение различных оценок, показал значительное превосходство SMT и CMP архитектур, исходя из критерия загрузки как существующих приложений, так и приложений, которые будут выполняться на СП в будущем. В последующей работе этой же группы исследователей [5] показано, что CMP и SMT архитектуры демонстрируют приблизительно равную высокую производительность. Различие между ними заключается в относительной простоте аппаратной (CMT) и программной составляющих (SMT) соответственно.
Среда моделирования SNP («Simulator of Network Processor»), предназначенная для моделирования типовых SMT архитектур сетевых процессоров, была разработана индийскими учеными M. Koohi, H. Bayadi и M.N. Khaless [6]. Система основана на методе «clock-by-clock». Отличительными чертами симулятора являются его многопоточная природа и возможность моделирования в том числе сетевого окружения, генераторов трафика и сетевого контроллера, подключенного к СП.
Статья [7] посвящена анализу возможностей CMT архитектуры, ориентированной на обработку множества потоков с низкими потребностями в обслуживании. В [8] предлагается алгоритм планирования для снижения числа промахов кэша второго уровня, который является критическим разделяемым ресурсом процессора, и увеличения пропускной способности системы.
Методологии, подходы и методы моделирования сетевых процессоров на базе CMP архитектур описаны в работах [9-17]. В [9-10] представлена аналитическая модель, позволяющая определить производительность обработки пакетов сетевым процессором, оценить требуемую площадь кристалла и уровень энергопотребления. Модель учитывает количество процессорных элементов на чипе, их многопоточные свойства, размеры внутренней памяти (на чипе) и кэша для команд, а также требуемое число внешних по отношению к кристаллу каналов памяти.
Моделированию сетевых процессоров семейства Intel IXP посвящены статьи [11-16]. Разработаны аналитическая и имитационная модели процессора IXP425 [11], работающего в основе VPN-шлюза. Для этого были использованы цепи Маркова и симулятор Omnet++. Исследованы параметры системы СП и ее «узкие места», уделяя особое внимание размерам буфера.
В [12] разработано программное обеспечение для коммутатора, пересылающего IP4 пакеты, и исследовано его отображение на сетевой процессор Intel IXP1200. Выполнено сравнение аналитического и имитационного подходов к моделированию СП и получена оценка точности аналитических моделей сетевого приложения и архитектуры процессора, предназначенных для оценки возможных вариантов проектирования. В публикациях [13-14] представлены имитационные модели на основе сетей Петри для процессоров Intel IXP, позволяющие оценивать производительность приложений и архитектур, эффективность их взаимодействия, а также степени изменения порядка пакетов для приложений, пересылающих IP4 пакеты.
Методология системного уровня для решения проблемы функциональности процессорных элементов и отображения структур данных приложений на блоки памяти сетевого процессора с CMP архитектурой предложена в [15]. Статья содержит описание программной модели и разработанных методов оптимизации. Методология, рассматриваемая в [16], направлена на решение задач анализа эффективности различных сетевых приложений, работающих на процессоре Intel IXP2400. Эта методология предполагает разбиение приложений на блоки, образующие конвейер, и оценку вычислительных требований и требований ввода-вывода, а также запасов по нагрузке для каждого блока. Определяется наиболее эффективное отображение блоков приложения на аппаратные ресурсы. Однако в данной работе не учитывается коэффициент использования процессоров и подсистемы памяти, и недостаточно исследованы подходы к проектированию сетевых процессоров [17].
В статье Y.-N. Lin, Y.-D. Lin, Y.-C. Lai [17] описаны достоинства и недостатки традиционных многопоточных-многопроцессорных архитектур сетевых процессоров. Предложены аналитическая модель с непрерывным временем и имитационная модель на базе сетей Петри. Подход, использованный в работе, учитывает влияние памяти и очереди готовых к выполнению на процессоре потоков, что часто игнорируется в других публикациях. Разработана концепция Р-М соотношения, где Р и М представляют собой вычислительные нагрузки и накладные расходы на доступ к памяти, вызванные работой приложения. Выполнена оценка зависимости между различными Р-М соотношениями и соответствующим им требуемым числом потоков на процессоре. Описаны также способы устранения эффекта «узкого места», возникающего при малых Р-М соотношениях.
Производительность сетевых процессоров может зависеть не только от типа и параметров архитектур сетевых процессоров и характеристик сетевых приложений, но также от работы алгоритмов управления очередями заявок и эффективного распределения загрузки по вычислительным элементам [18-25].
3.2 Обзор локальных источников
Национальные исследования проблем проектирования и моделирования сетевых процессоров представлены научными работами доцента кафедры прикладной математики и информатики Донецкого национального технического университета Ю.В. Ладыженского и его аспирантов В.И. Грищенко и М. Юниса [26-36].
В публикациях [26-28] описаны особенности современных сетевых процессоров, проведен анализ технических характеристик и функциональных возможностей наиболее перспективных СП для высоконагруженных систем. Предложена обобщенная структура типичного многоядерного сетевого процессора.
Работы [29-31] посвящены вопросам моделирования и программирования пакетных сетевых процессоров, а также моделированию работы приложений на СП.
В статьях [32-36] предложены аналитические модели СП и методика исследования влияния архитектуры кэша на производительность процессора. Экспериментальным путем определены оптимальные размеры кэшей команд и данных для выполнения задач обработки заголовков сетевых пакетов, работы с передаваемыми данными и решения классических задач маршрутизации. Изучено влияние политики замещения блоков в множественно-ассоциативном кэше на производительность сетевого процессора. Исследована производительность структуры сетевого процессора с кэшем команд, достаточно большим для размещения всего программного кода. Разработан подход, позволяющий минимизировать время, затрачиваемое на имитационную часть комплексной методики за счет использования аналитической модели промахов кэша. В [36] представлена модель СП с раздельной памятью для кода и данных и произведено сравнение эффективности сетевых процессоров с общей и раздельной памятью.
4. Марковская модель для анализа эффективности гетерогенных CMP архитектур сетевых процессоров
Модель системы состоит из I процессоров, каждый из которых имеет J потоков [17]. Когда пакет поступает в свободный поток, данный поток помещается в очередь готовых к выполнению потоков процессора или переходит в активное состояние, если в текущий момент на процессоре нет активного потока. Поток может запрашивать доступ к памяти, например, для работы с дескриптором пакета или маршрутной таблицей. После обслуживания в памяти поток помещается в очередь готовых к выполнению либо вновь поступает на процессор, если данная очередь пуста. Обычно поток снова становится свободным после того, как пакет будет обслужен и передан следующему потоку. Однако если следующий поток занят обслуживанием пакета, текущий поток переходит в состояние «завершен».
Пространство состояний модели есть:
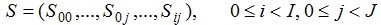
где 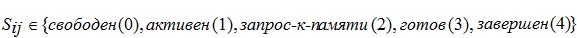 представляет собой состояние
представляет собой состояние 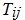 j-го потока i-го процессора.
j-го потока i-го процессора.
Строится непрерывная марковская модель для расчета вероятностей состояний и характеристик производительности СП. Моделирование выполняется только для множества достижимых состояний, что существенно сокращает затраты памяти и время моделирования.
Пример обработки пакетов потоками моделируемой системы на двух процессорах показан на рисунке 1.
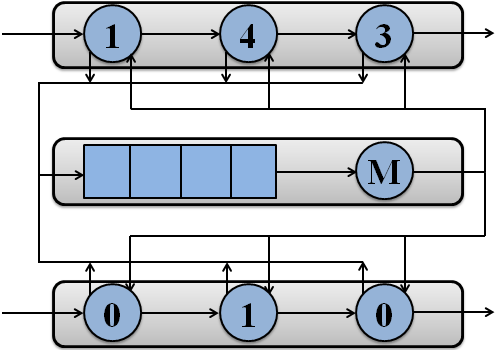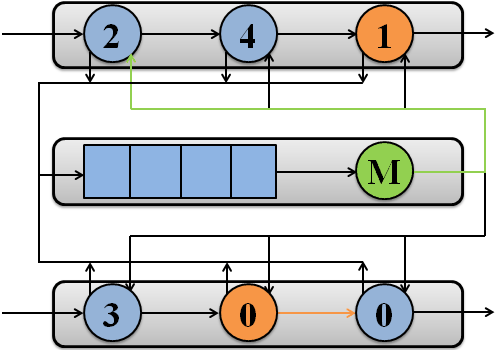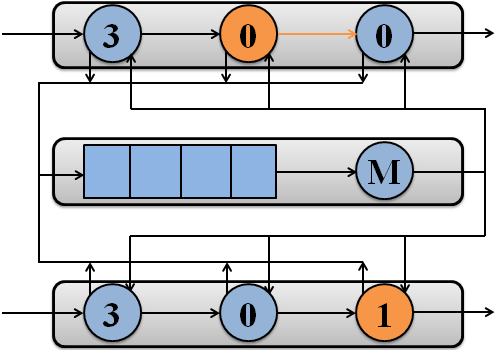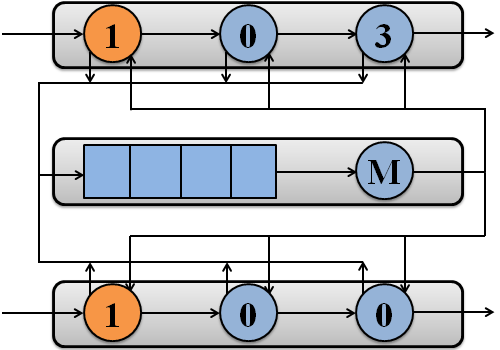
Рисунок 1 – Обработка пакетов потоками моделируемой системы на двух процессорах
(анимация: 7 кадров, 7 циклов повторения, 108 килобайт)
(M – подсистема памяти)
Пусть моделируемая архитектура задается следующими параметрами:
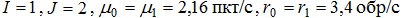 . На
рисунках 2 и 3 приведены зависимости
характеристик загрузки памяти и процессоров от интенсивности потока пакетов и
производительности памяти СП для указанных значений исходных данных.
. На
рисунках 2 и 3 приведены зависимости
характеристик загрузки памяти и процессоров от интенсивности потока пакетов и
производительности памяти СП для указанных значений исходных данных.
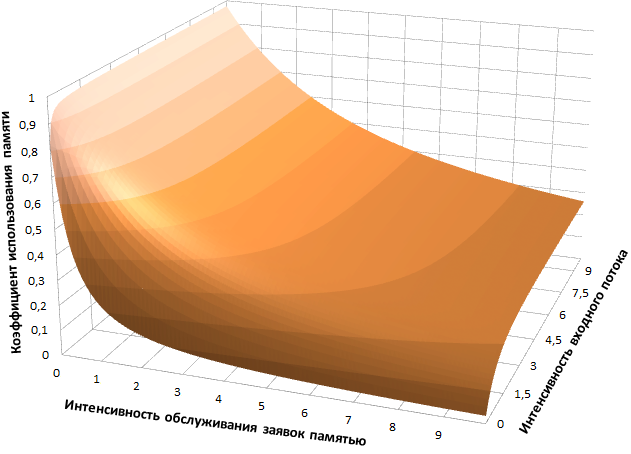
Рисунок 2 – Изменение коэффициента использования памяти
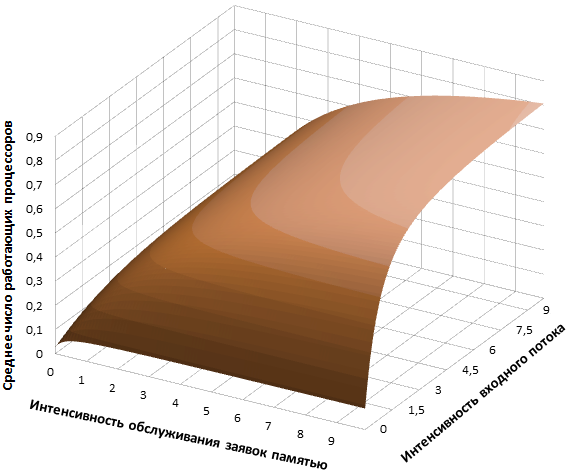
Рисунок 3 – Изменение среднего числа работающих процессоров
Качество роста исследуемых оценок определяется величиной интенсивности обслуживания заявок подсистемой памяти. При малых ее значениях показатели эффективности быстрее достигают устойчивости, которая на практике выражается в наличии существенной доли отказов в обслуживании. В то же время увеличение производительности памяти приводит к снижению коэффициента ее использования и возрастанию загрузки процессора. Как следствие, пропускная способность системы увеличивается.
Выводы
Результаты проведенных экспериментов показывают, что эффективность сетевого процессора в значительной мере зависит от производительности подсистемы памяти. Ограничение ресурсов памяти может привести к снижению коэффициента загрузки процессоров и проявляться в появлении отказов системы при сравнительно небольших интенсивностях входного потока.
Магистерская работа посвящена актуальной научной задаче моделирования архитектур сетевых процессоров. В рамках проведенных исследований выполнено:
- Разработана структура программного комплекса, позволяющего исследовать производительность сетевых процессоров.
- Выполнено имитационное моделирование входного трафика СП и изучены его свойства.
- Программно реализована аналитическая модель с непрерывным временем для гетерогенной CMP архитектуры сетевого процессора.
- Получены и исследованы зависимости показателей эффективности архитектуры от интенсивности входного потока пакетов и других параметров.
Дальнейшие исследования направлены на следующие аспекты:
- Расширение аналитической модели за счет добавления в нее блока балансировки загрузки, поступающей на процессорные элементы.
- Разработка аналитических моделей с дискретным временем, а также ряда имитационных дискретно-событийных функциональных моделей и моделей на сетях Петри.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2013 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- «Фрактальная катастрофа» TCP/IP [Электронный ресурс]. Режим доступа:
http://itc.ua/articles/_fraktalnaya_katastrofa_tcp_ip_5571/
- Зюльков И.А. Самоподобные свойства трафика систем с повторными вызовами / И.А. Зюльков // Вестник ВГУ. – 2002. – (Серия «Физика, математика»). – № 1. – С. 20-26.
- Musoll E., Nemirovsky M. Design Space Exploration of High-Performance Parallel Architectures / E. Musoll, M. Nemirovsky // Journal Integrated Circuits and Systems. – 2008. – vol. 3 (1). – pp. 32-38.
- Crowley P., Fiuczynski M.E., Baer J.-L., Bershad B.N. Characterizing Processor Architectures for Programmable Network Interfaces / P. Crowley, M.E. Fiuczynski, J.-L. Baer, B.N. Bershad // Proceedings of the 14th international conference on Supercomputing. – 2000. – pp. 54-65.
- Crowley P., Fiuczynski M.E., Baer J.-L. On the Performance of Multithreaded Architectures for Network Processors // Technical report. – 2000.
- Koohi M., Bayadi H., Khaless M.N. A simulation environment for network processor based on simultaneous multi thread architecture / M. Koohi, H. Bayadi, M.N. Khaless // Indian Journal of Science and Technology. – 2004. – vol. 5 (10). – pp. 3384–3389.
- Kapil S., McGhan H., Lawrendra J. A chip multithreaded processor for network-facing workloads / S. Kapil, H. McGhan, J. Lawrendra // Journal IEEE Micro. – 2004. – vol. 24 (2). – pp. 20-30.
- Fedorova A., Seltzer M., Small C., Nussbaum D. Performance of multithreaded chip multiprocessors and implications for operating system design / A. Fedorova, M. Seltzer, C. Small, D. Nussbaum // ATEC '05 Proceedings of the annual conference on USENIX Annual Technical Conference. – 2005. – pp. 26-29.
- Franklin M.A., Wolf T. A Network Processor Performance and Design Model with Benchmark Parameterization / M.A. Franklin, T. Wolf // Proceedings of International Symposium on High-Performance Computer Architecture. – 2002. – pp. 63-74.
- Wolf T., Franklin M.A. Performance models for network processor design / T. Wolf, M.A. Franklin // IEEE Transactions on Parallel and Distributed Systems. – 2006. – vol. 17 (6). – pp. 548–561.
- Ali F.H., Ahmed O.F. Modeling and Analysis of IXP425 Network Processor / F.H. Ali, O.F. Ahmed // Al-Rafadain Engineering Journal. – 2012. – vol. 20 (2). – pp. 116-130.
- Gries M., Kulkarni C., Sauer C., Keutzer K. Comparing Analytical Modeling with Simulation for Network Processors: A Case Study / M. Gries, C. Kulkarni, C. Sauer, K. Keutzer // Proceeding DATE '03 Proceedings of the conference on Design, Automation and Test in Europe: Designers' Forum. – 2003. – vol. 2. – pp. 256-261.
- Govind S., Govindarajan R. Performance Modeling and Architecture Exploration of Network Processors / S. Govind, R. Govindarajan // Second International Conference on the Quantitative Evaluation of Systems. – 2005. – pp. 189-198.
- Govind S., Govindarajan R., Kuri J. Packet Reordering in Network Processors / S. Govind, R. Govindarajan, J. Kuri // Parallel and Distributed Processing Symposium. – 2007. – pp. 1-10.
- Ramamurthi V., McCollum J., Ostler C., Chatha K.S. System Level Methodology for Programming CMP based Multi-threaded Network Processor Architectures / V. Ramamurthi, J. McCollum, C. Ostler, K.S. Chatha // ISVLSI '05 Proceedings of the IEEE Computer Society Annual Symposium on VLSI: New Frontiers in VLSI Design. – 2005. – pp. 110-116.
- Lakshmanamurthy S., Liu K.-Y., Pun Y., Huston L., Naik U. Network Processor Performance Analysis Methodology / S. Lakshmanamurthy, K.-Y. Liu, Y. Pun, L. Huston, U. Naik // Intel Technology Journal. – 2002. – vol. 6 (3). – pp. 19-28.
- Lin Y.-N., Lin Y.-D., Lai Y.-C. Thread Allocation in CMP-based Multithreaded Network Processors / Y.-N. Lin, Y.-D. Lin, Y.-C. Lai // Parallel Computing. – 2010. – vol. 36 (2-3). – pp. 104-116.
- Papaefstathiou I., Orphanoudakis T., Kornaros G., Kachris C., Mavroidis I., Nikologiannis A. Queue Management in Network Processors / I. Papaefstathiou, T. Orphanoudakis, G. Kornaros, C. Kachris, I. Mavroidis, A. Nikologiannis // Proceedings of the Design, Automation and Test in Europe Conference and Exhibition (DATE '05). – 2005. – pp. 112-117.
- Menasce D.A., Saha D., Porto S.C. Da S., Almeida V.A. F., Tripathi S.K. Static and Dynamic Processor Scheduling Disciplines in Heterogeneous Parallel Architectures / D.A. Menasce, D. Saha , S.C. Da S. Porto , V.A. F. Almeida , S.K. Tripathi // Journal of Parallel and Distributed Computing. – 1995. – vol. 28 (1). – pp. 1-18.
- D. Pan, Y. Yang. Buffer Management for Lossless Service in Network Processors / Pan D., Yang. Y. // 14th IEEE Symposium on High-Performance Interconnects. – 2006. – pp. 81-86.
- Kencl L., Boudec Le J.-Y. Adaptive Load Sharing for Network Processors / L. Kencl, J.-Y. Le Boudec // IEEE/ACM Transactions on Networking. – 2008. – vol. 16 (2). – pp. 293-306.
- Keslassy I., Kogan K., Scalosub G., Segal M. Providing Performance Guarantees in Multipass Network Processors / I. Keslassy, K. Kogan, G. Scalosub, M. Segal // IEEE/ACM Transactions on Networking. – 2012. – vol. 20 (6). – pp. 1895-1909.
- Shpiner A., Keslassy I., Cohen R. Reducing the Reordering Delay in Multi-Core Network Processors // Technical report. – 2012.
- Evaluating Dynamic Task Mapping in Network Processor Runtime Systems / X. Huang, T. Wolf // IEEE Transactions on Parallel and Distributed Systems. – 2007. – pp. 1086-1098.
- Wolf T., Pappu P., Franklin M.A. Predictive scheduling of network processors / T. Wolf, P. Pappu, M.A. Franklin // Computer Networks: The International Journal of Computer and Telecommunications Networking – Network processors. – 2003. – vol. 41 (5). – pp. 601-621.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Перспективные архитектуры и тенденции развития современных сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Материалы IV международной научно-технической конференции «Моделирование и компьютерная графика – 2011». – Донецк, 2011. – С. 93-97.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Основные направления развития современных сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия «Інформатика, кібернетика та обчислювальна техніка»). – № 14 (188). – С. 123-127.
- Юнис М., Грищенко В.И., Ладыженский Ю.В. Обобщенная структура сетевых процессоров / М. Юнис, В.И. Грищенко, Ю.В. Ладыженский // Материалы VII международной научно-технической конференции студентов, аспирантов и молодых ученых «Информатика и компьютерные технологии – 2011». – Донецк, 2011. – С. 386-391.
- Ладыженский Ю.В., Грищенко В.И. Моделирование сетевых процессоров пакетной обработки данных / Ю.В. Ладыженский, В.И. Грищенко // Материалы международной научно-практической конференции «Интернет – Образование – Наука – 2006». – Виница, 2006. – Т. 2. – С. 417-422.
- Ладыженский Ю.В., Грищенко В.И. Программирование процессоров обработки пакетов в компьютерных сетях / Ю.В. Ладыженский, В.И. Грищенко // Матеріали міжнародної науково-практичної конференції «Сучасні проблеми і досягнення в галузі радіотехніки, телекомунікацій та інформаційних технологій». – Запорожье, 2006. – C. 159-161.
- Грищенко В.И., Ладыженский Ю.В. Моделирование работы приложений на сетевых процессорах / В.И. Грищенко, Ю.В. Ладыженский // Материалы международной научно-практической конференции «Моделирование и компьютерная графика – 2007». – Донецк, 2007. – С. 167-173.
- Грищенко В.И., Ладыженский Ю.В. Исследование архитектуры кэша сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский // Науково-технічний журнал «Радіоелектронні і комп’ютерні системи». – № 6 (25). – С. 186-192.
- Ладиженский Ю.В., Грищенко В.И. Влияние политики замещения записей в кэше на производительность сетевого процессора / Ю.В. Ладыженский, В.И. Грищенко // Наукові праці ДонНТУ. – Донецк, 2007. – (Серия «Обчислювальна техніка та автоматизація»). – № 12 (118). – С. 114-119.
- Грищенко В.И., Ладыженский Ю.В., Юнис М. Влияние выделенного кэша команд на производительность сетевого процессора / В.И. Грищенко, Ю.В. Ладыженский, М. Юнис // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия «Інформатика, кібернетика та обчислювальна техніка»). – № 13 (185). – С. 85-91.
- Грищенко В.И., Ладыженский Ю.В. Оптимизация методики моделирования кэша сетевых процессоров / В.И. Грищенко, Ю.В. Ладыженский // Материалы III международной научно-технической конференции «Моделирование и компьютерная графика – 2009». – Донецк, 2009. – C. 249-254.
- Грищенко В.И., Ладыженский Ю.В. Исследование влияния раздельной памяти на производительность многоядерного сетевого процессора / В.И. Грищенко, Ю.В. Ладыженский // Наукові праці ДонНТУ. – Донецк, 2011. – (Серия «Проблеми моделювання та автоматизації проектування»). – № 9 (179).