
Vladislav Chuprin
Faculty of computer science and technology
The department of applied mathematics and informatics
Speciality «Software engendering»
Improving the efficiency of the implementation of distributed computing within MapReduce software framework Hadoop
Scientific adviser: D.T.S, Professor Olga Dmitrieva
Abstract
Introduction
1.Relevance of the
topic
2 Research goals and objectives, expected results
3 A review of research and development
3.1
Scheduler in Hadoop
3.2 Scheduler Longest Approximate Time to End (LATE)
3.3 Uniform planning (FAIR scheduler) [5]
3.4 Hadoop 2.0. Capacity
scheduler [6]
4 The proposed algorithm is based on lottery
scheduling
Conclusions
List of sources
Introduction
Hadoop is a cloud-based system for distributed data processing in which incoming jobs are described in accordance with the programming model MapReduce. For smaller organizations using Hadoop, characterized by the presence of heterogeneous clusters of all resources available to them, and for large corporate systems - the presence of huge homogeneous clusters. Users of the system may be a group of individuals who are characterized by parameters such as priorities, the reserved amount of computing power, the guaranteed number of shared disk space, and more. Workload in the cluster must be distributed among an arbitrary number of user tasks and respond to a number of requirements.
Programming model. During the execution of distributed processing takes the input key / value pairs, and generates a result set similar pairs. Library user MapReduce computation is in two phases: Map and Reduce. Map, written by a customer receives as input and produces as output the key / value pairs. MapReduce framework groups together all intermediate results obtained in Map phase with the same intermediate key, and transmits them to the input phase Reduce. Function Reduce, usually written by a user obtain an intermediate key and a set of values associated with that key to combine the results in a supposedly smaller set of values. Typically, within a single Reduce call created zero and one output pair. Intermediate values are pass to Reduce in an iterative way, which allows you to store lists of values that are greater than the available memory.
1 Introduction
Planners play a critical role in achieving new levels of performance in systems based on Hadoop. It is important to choose the appropriate scheduling algorithm, given the limitations that imposes implementation Hadoop, while maintaining an acceptable level of distribution.
2 The purpose and objectives of the study
Objective is to conduct a comparative analysis of existing methods of planning and developing the concept of an optimized method. As part of the work required:
- explore the implementation scheduler Hadoop;
- analyze existing scheduling algorithms;
- offer its own approach based on studied the advantages and disadvantages of ready solutions;
3 Review of Research and Development
The main source of revealing theoretically basis paradigm MapReduce, we can assume the article Jeffrey Dean and Sanjay Ghemawat [1]. Implementation within the Hadoop scheduler described in detail in [3] and is the most comprehensive source on the subject. Depth research approaches to optimization are given in [4-8].
3.1 Scheduler in Hadoop
Hadoop MapReduce implementation in many ways consistent with the approach described in [1]. One main (master) node controls a plurality of slave (slaves) [2]. File with the original data, which is a distributed file system (HDFS), to provide fault tolerance and improved performance split into chunks (chunk) of the same size and replicated with a given coefficient of duplication. Hadoop MapReduce job splits received (job) on a variety of tasks (task). Each piece of input data is processed given Map function. Map phase output values are broken down by key and sent to the input phase Reduce (Fig. 1). The circuit shown in [3] (Fig. 2) illustrates the calculation using the approach MapReduce. Hadoop runs multiple tasks and Map Reduce several tasks in parallel on each slave node - 2 each for closing idle CPU and disk subsystem. Each slave node sends a message to the master node when computing tasks slots are empty, and then assigns a new task scheduler nodes. Built in Hadoop scheduler runs tasks in FIFO order with five priority levels [3]. When slots are exempt tasks, the scheduler scans the available tasks in order of priority, and saves time spent searching for the desired task.

Figure 1 - MapReduce computation scheme
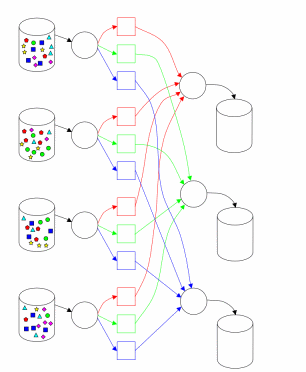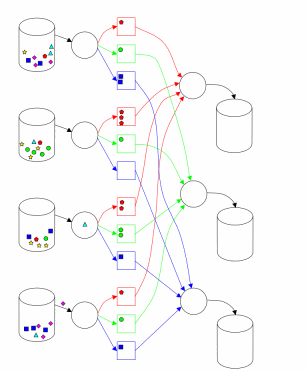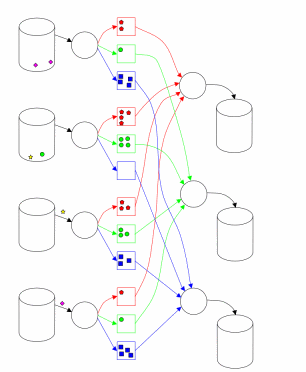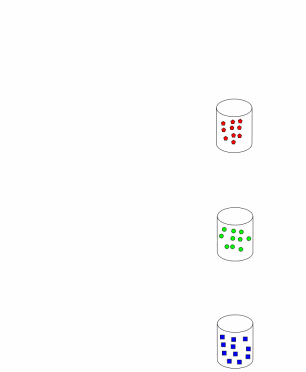
Figure 2 - Implementation of MapReduce
(animation: 35 frames, 10 repetition cycles, 112 KB)
Map tasks for the scheduler uses local optimization implemented in Google MapReduce [1]: After selecting the job scheduler allocates Map tasks to nodes having the maximum amount of data to perform (if possible, all data must be located on the selected node, otherwise - on one of the nodes Rack and finally the remote reception). Hadoop, uses backup tasks to mitigate the problem of heterogeneous clusters [1].
3.2 Scheduler Longest Approximate Time to End (LATE)
Proposed speculative scheduler allows you to partially deal with the above shortcomings in environments with conditions close to real. The basic idea is as follows: "The scheduler is usually speculative runs tasks that will have the smallest execution time, as these tasks to the best opportunities for overtaking speculative copy of the original objectives and minimize task time" [4]. Intuitively such a greedy policy is good, if the nodes run at a constant speed, as well as the absence of start-up costs of speculative task on another node is idle [10].
3.3 Uniform planning (FAIR scheduler) [5]
Facebook portal was presented scheduler for uniform distribution of tasks using the slots (Fig. 3). His basic ideas:
- Isolation: the creation for all users (tasks) illusion of a completely private cluster.
- Statistical redistribution: redistribution of unused computing resources from one user to another.

Figure 3 - Task allocation to pools
3.4 Hadoop 2.0. Capacity scheduler [6]
When planning the computing power instead of pools created several queues, each - with configurable number of slots for the Map and Reduce phases [7]. Each queue is also assigned some guaranteed computing power, the total computing power of a cluster is the sum of the computing power of all queues [8]. Queues are monitored and if any place does not consume processing power allocated to it, the excess may be temporarily given to other queues. Given the fact that the queue can represent both individuals and large organizations, any free computing resources redistributed to other consumers.
4 The proposed algorithm is based on lottery scheduling
Algorithm is based on the distribution of tasks lottery tickets for access to computing resources. When the scheduler has to decide randomly selected lottery ticket, and the holder is entitled to run their jobs on the cluster nodes. More important tasks you can give more tickets to increase the probability of winning.
Conclusions
Implementation connection scheduler is another step in the evolution of cluster computing system using Hadoop. Support for plug-in scheduler allows to use (and develop) schedulers optimized for a particular workload and the particular application [9]. In addition, new planners made it possible to create multi-user data storage system using Hadoop, by allowing sharing of the entire infrastructure Hadoop multiple users and organizations.
Hadoop system develops as the evolution of its usage patterns and now supports new types of workloads and usage scenarios (eg, large multi-data repository and common data repository for multiple organizations). These new flexibilities offered Hadoop, are a huge step forward towards a more optimized use of resources in the cluster analysis of large amounts of data.
This master's work is not completed yet. Final completion: December 2014. The full text of the work and materials on the topic can be obtained from the author or his head after this date.
References
- Dean J. Simplified Data Processing on Large Clusters / J. Dean, S. Ghemawat / / Electronic edition, Google Inc., 2004. - 16 p
- Chuprin VI Analysis of security problems the architecture of distributed applications for example NoSQL software framework Hadoop / VI Chuprin, AV Chernyshev, NE Gubenko / / Proceedings of Conference VI International Scientific and Technical Conference "Іnformatika that komp'yuternі tehnologії", Donetsk, Donetsk National Technical University, Donetsk National Technical University, 2013. - C. 369-373
- Zaharia M. Improving MapReduce Performance in Heterogeneous Environments / M. Zaharia, A. Konwinski, AD Joseph, R. Katz, I. Stoica / / Electronic edition, Berkley., 2009. - pp. 69-75
- Xiao Z. A Hierarchical Approach to Maximizing MapReduce Efficiency / Z. Xiao, H. Chen, B. Zang / / IEEE Computer Society., 2011. - pp. 36-97
- Zaharia M. Improving MapReduce Performance in Heterogeneous Environments / M. Zaharia, A. Konwinski, AD Joseph, R. Katz, I. Stoica / / Electronic edition, Berkley., 2009. - pp. 325-331
- Rasooli A. An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems / A. Rasooli, DG Down / / Department of Computing and Software McMaster University., 2012. - pp. 257-289
- Sandholm T. Dynamic Proportional Share Scheduling in Hadoop [Electron resource]. - Mode of access: http://www.cs.huji.ac.il/~feit/parsched/jsspp10/p7-sandholm.pdf
- Shvachko K. The Hadoop Distributed File System. / Konstantin Shvachko, Hairong Kuang, Sanjai Radia, Robert Chansler // MSST '10 Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), 2010. - pp. 1-10
- Hunt P. ZooKeeper: wait-free coordination for internet-scale systems. / P. Hunt, M. Konar, FP Junqueira, and B. Reed / / USENIXATC'10: Proceedings of the 2010 USENIX conference on USENIX annual technical conference. Berkeley, CA, USA: USENIX Association, 2010. - pp. 11-11
- Chang F. Bigtable: a distributed storage system for structured data. / F. Chang, J. Dean, S. Ghemawat, WC Hsieh, DA Wallach, M. Burrows, T. Chandra, A. Fikes, RE Gruber / / Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation, vol. 7, p. 15-15