
Чуприн Владислав Игоревич
Факультет компьютерных наук и технологий
Кафедра прикладной математики и информатики
Специальность «Инженерия программного обеспечения»
Повышение эффективности реализации модели распределённых вычислений MapReduce в рамках программного каркаса Hadoop
Научный руководитель: д.т.н., доц. Дмитриева Ольга Анатольевна
Реферат по теме выпускной работи
Введение
1. Актуальность темы
2. Цель и задачи исследования, планируемые результаты
3. Обзор исследований и разработок
3.1 Планировщик в Hadoop
3.2 Планировщик «Longest Approximate Time to End (LATE)»
3.3 Равномерное планирование (FAIR scheduler) [5]
3.4 Hadoop 2.0. Capacity scheduler [6]
4. Предложенный алгоритм на основе лотерейного планирования
Выводы
Список источников
Введение
Hadoop представляет собой облачную систему для распределенной обработки данных, в рамках которой входящие задания описаны в соответствии с программной моделью MapReduce. Для небольших организаций, использующих Hadoop, характерно наличие гетерогенных кластеров из всех имеющихся у них ресурсов, а для больших корпоративных систем – наличие огромных гомогенных кластеров. Пользователями системы может быть группа лиц, которые характеризуются такими параметрами как приоритеты, зарезервированное количество вычислительных мощностей, гарантированное количество разделяемого дискового пространства и прочее. Рабочая нагрузка внутри кластера должна быть распределена между произвольным количеством пользовательских заданий и отвечать множеству требований.
Модель программирования. Во время выполнения распределенной обработки на вход принимаются пары ключ/значение, и генерируется результирующее множество аналогичных пар. Пользователь библиотеки MapReduce представляет вычисления в виде двух фаз: Map и Reduce. Map, написанная пользователем, получает на вход и производит на выходе ключ/значение. MapReduce каркас группирует вместе все промежуточные результаты, полученные на фазе Map с одинаковым промежуточным ключом, и передает их на вход фазе Reduce. Функция Reduce, обычно написанная пользователем, принимает промежуточный ключ и множество значений, связанных с этим ключом, осуществляется объединение полученных результатов в предположительно меньшее множество значений. Обычно, в рамках одного вызова Reduce производится ноль и одно выходное значение. Промежуточные значения подаются на вход Reduce в итеративном виде, что позволяет хранить списки значений, которые являются большими, чем размер доступной оперативной памяти.
1 Актуальность темы
Планировщики играют критическую роль в достижении новых уровней производительности в системах на базе Hadoop. Важно выбрать подходящий алгоритм планирования, учитывая ограничения, которые накладывает реализация Hadoop, сохраняя приемлемый уровень распределённости.
2 Цель и задачи исследования
Цель работы заключается в проведении сравнительного анализа существующих методов планирования и разработке концепции оптимизированного метода. В рамках работы, требуется:
- исследовать реализацию планировщика в Hadoop;
- проанализировать существующие алгоритмы планирования;
- предложить собственный подход на основе изученных достоинств и недостатков готовых решений;
3 Обзор исследований и разработок
Основным источником, раскрывающим теоретические основы парадигмы MapReduce, можно считать статью Jeffrey Dean и Sanjay Ghemawat [1]. Реализации планировщика в рамках Hadoop подробно описана в [3] и является максимально полным источником по этому вопросу. Глубокие исследования подходов к оптимизации приведены в [4-8].
3.1 Планировщик в Hadoop
Реализация MapReduce в Hadoop во многом соответствует подходу, описанному в [1]. Один главный (master) узел управляет множеством подчиненных (slaves) [2]. Файл с исходными данными, который находится в распределенной файловой системе (HDFS), для обеспечения отказоустойчивости и повышения производительности разбивается на фрагменты (chunk) одинакового размера и реплицируется с заданным коэффициентом дублирования. Hadoop разбивает полученные MapReduce задания (job) на множество задач (task). Каждый фрагмент входной информации обрабатывается заданной Map функцией. Выходные значения Map фазы разбиваются по ключу и направляются на вход фазе Reduce (рис. 1). Схема, приведенная в [3] (рис. 2), иллюстрирует вычисления с использованием подхода MapReduce. Hadoop запускает несколько Map задач и несколько Reduce задач параллельно на каждом подчиненном узле – по 2 на каждом для перекрытия простоя CPU и дисковой подсистемы. Каждый подчиненный узел посылает главному узлу сообщение, когда слоты для вычисления задач становятся пустыми, и тогда планировщик назначает новые задания узлам. Встроенный в Hadoop планировщик запускает задачи в порядке FIFO с пятью уровнями приоритетов [3]. Когда слоты для выполнения задач освобождаются, планировщик сканирует имеющиеся задачи в порядке убывания приоритетов, и сохраняет время, затраченное на поиск требуемой задачи.
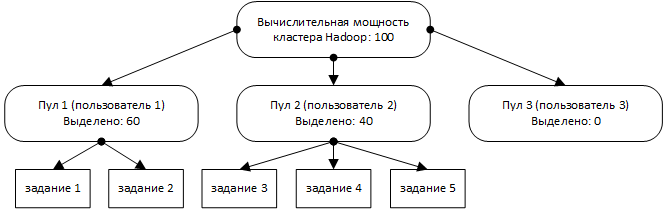
Рисунок 1 - Схема вычислений MapReduce
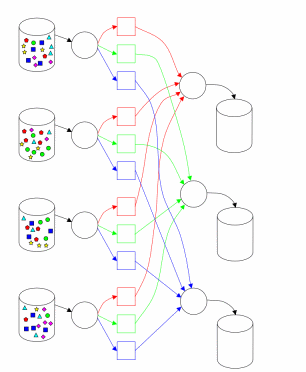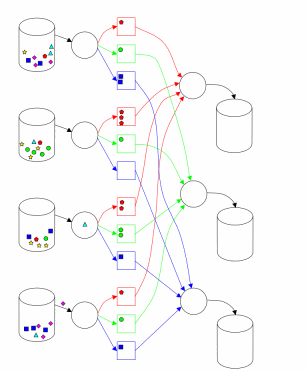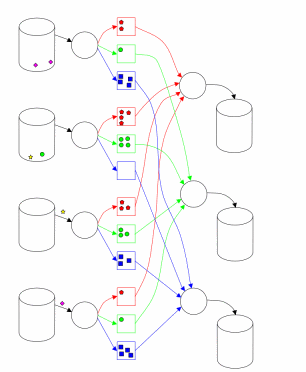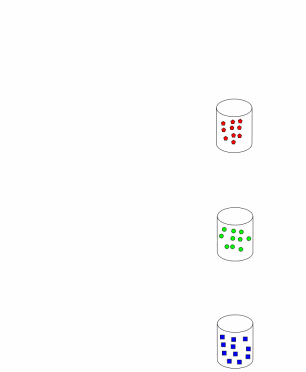
Рисунок 2 - Выполнение MapReduce
(анимация: 35 кадров, 10 циклов повторения, 112 килобайт)
Для Map задач планировщик использует локальную оптимизацию, реализованную в Google MapReduce [1]: после выбора задания планировщик распределяет Map задачи на узлы, содержащие максимальное количество данных для выполнения (если возможно, все данные должны находится на выбранном узле, иначе - на одном из узлов стойки и, наконец, на удаленной стойке). Hadoop, использует резервное копирование задач для смягчения проблемы гетерогенных кластеров [1].
Планировщик в Hadoop выполняет следующие неявные предположения:
- Узлы должны выполнять задачи строго за одинаковое время.
- Задачи одинаково интенсивно используют ресурсы на протяжении всего времени выполнения.
- Отсутствуют затраты на запуск спекулятивных задач на узлах, которые имеющих простаивающий слот.
- Процент выполнения определённой задачи целиком отражает размер проделанной работы.
- Задачи с плохим прогрессом становятся отстающими (strugglers).
- Задачи в одной категории (Map или Reduce) требуют одинакового объема работы.
3.2 Планировщик «Longest Approximate Time to End (LATE)»
Предложенный спекулятивный планировщик задач позволяет частично бороться с приведёнными выше недостатками в окружениях с условиями, более приближенными к реальным. Основная идея заключается в следующем: «Планировщик обычно спекулятивно запускает задачи которые будут иметь наименьшую продолжительность выполнения, так как эти задачи предоставляют наилучшие возможности для спекулятивного копирования для обгона оригинальных задач и минимизации времени выполнения задания» [4]. Интуитивно подобная жадная политика хороша, если узлы работают с постоянной скоростью, а также при отсутствии затрат на запуск спекулятивной задачи на другом простаивающем узле.
Для получения наилучших шансов на разбиение исходной задачи на спекулятивные она должна запускаться только на быстрых узлах – не отстающих (stragglers) [10]. Планировщик достигает этого при помощи простой эвристики – не запуская задачи на узлах медленнее некоторого порога, общей проделанной работы для всех успешно завершенных и выполняющихся задач на узле. Эта эвристика позволяет достичь лучшей производительности, чем назначение спекулятивных задач на первый свободный узел. Другая опция позволяет существование более чем одной спекулятивной копии каждой задачи, однако может расходовать ресурсы напрасно. Как и планировщик Hadoop, согласно предложенному алгоритму, выполняется ожидание на протяжении 1 минуты перед запуском спекулятивной задачи.
3.3 Равномерное планирование (FAIR scheduler) [5]
Порталом Facebook был представлен равномерный планировщик для распределения задач с использованием слотов. Его основные идеи:
- Изолированность: создание для всех пользователей (заданий) иллюзии работы на абсолютно приватном кластере.
- Статистическое перераспределение: перераспределение неиспользуемых вычислительных ресурсов от одних пользователей другим.
Планировщик использует 2-х уровневую иерархию (рис. 3). На верхнем уровне, выполняется разбиение задач на пулы, а на нижнем разбиение слотов, выделенных под пул, между его задачами. Стоит отметить, что планировщик в общем случае может быть обобщён до произвольного количества уровней. FAIR использует те же алгоритмы для распределения слотов между задачами пула, что и планировщик Hadoop для разбиения на узлы [7]. Таким образом, возможны различные модификации, отличные от FIFO.
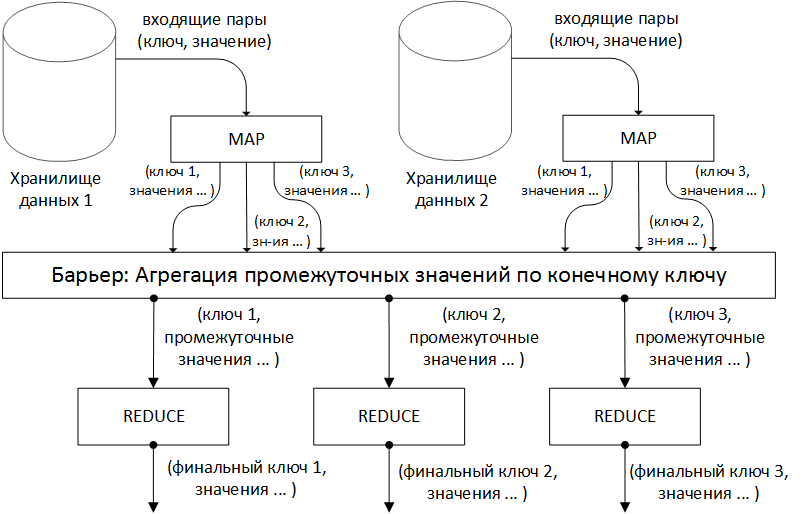
Рисунок 3 - Распределение заданий по пулам
3.4 Hadoop 2.0. Capacity scheduler [6]
Планировщик вычислительной мощности имеет некоторые общие черты с равномерным планировщиком, но есть и значительные отличия. Во-первых, планирование вычислительной мощности рассчитано на большие кластеры, которые могут иметь несколько независимых потребителей и несколько целевых приложений [8]. По этой причине планировщик предлагает расширенные возможности управления, а также предоставляет гарантированную минимальную вычислительную мощность и разделяет излишки вычислительной мощности между пользователями. При планировании вычислительной мощности вместо пулов создаются несколько очередей, каждая — с конфигурируемым количеством слотов для Map и Reduce фаз [7]. Каждой очереди также назначается некоторая гарантированная вычислительная мощность, при этом общая вычислительная мощность кластера представляет собой сумму вычислительных мощностей всех очередей. Очереди контролируются, и если какая-либо очередь не потребляет выделенную ей вычислительную мощность, излишки могут быть временно отданы другим очередям. С учетом того, что очереди могут представлять как физических лиц, так и крупные организации, любые свободные вычислительные ресурсы перераспределяется другим потребителям.
4 Предложенный алгоритм на основе лотерейного планирования
Алгоритм построен на базе аналогичной модели для много процессорніх систем. Основная идея заключается в раздаче задачам лотерейных билетов на доступ к вычислительным ресурсам. В момент принятия решения планировщик выбирает случайным образом лотерейный билет, и его обладатель получает право запускать свои задания на узлах кластера. Для увеличения вероятности выигрыша более приоритетным заданиям можно раздать дополнительные билеты.
Лотерейное планирование отличается высокой отзывчивостью. Например, если при постановке в очередь заданию достается несколько билетов, то уже в следующей лотерее его шансы на выигрыш пропорциональны количеству билетов. Задания одного пользователя могут при необходимости обмениваться билетами. Так, если от пользователя приходит новое, более приоритетное задание, то часть существующих билетов может быть отдано в его пользу.
Для некоторых задач лотерейное планирование позволяет находит более гибкие решения. В качестве примера можно привести кластер, на котором выполняется обработка пользовательских поисковых запросов. Часть запросов могут менять свой приоритет в зависимости от уже отправленных, например, по причине незначительного различия запрашиваемой информации. Тогда одному из заданий можно выдать часть кредитов уже существующего для оптимизации времени отклика и детализировать поисковую выдачу в момент окончания менее приоритетного задания.
Выводы
Внедрение подключаемого планировщика стало еще одним шагом в эволюции кластерных вычислений с использованием системы Hadoop [9]. Поддержка подключаемых планировщиков позволяет использовать (и разрабатывать) планировщики, оптимизированные для конкретной рабочей нагрузки и конкретного приложения. Кроме того, новые планировщики сделали возможным создание многопользовательских хранилищ данных с использованием системы Hadoop, благодаря обеспечению возможности совместного использования всей инфраструктуры Hadoop несколькими пользователями и организациями.
Система Hadoop развивается по мере эволюции ее моделей использования и теперь поддерживает новые типы рабочих нагрузок и сценариев использования (например, большие многопользовательские хранилища данных и общие хранилища данных для нескольких организаций). Эти новые гибкие возможности, которые предоставляет Hadoop, являются громадным шагом вперед в направлении более оптимизированного использования кластерных ресурсов при анализе больших объемов данных.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список литературы
- Dean J. Simplified Data Processing on Large Clusters / J. Dean, S. Ghemawat // Electronic edition, Google Inc., 2004. – 16 c
- Чуприн В.И. Анализ проблем безопасности архитектуры распределённых NoSQL приложений на примере программного каркаса Hadoop / В.И. Чуприн, А.В. Чернышова, Н.Е. Губенко // Материалы конференции VI международной научно-технической конференции "Інформатика та комп'ютерні технології", Донецьк, ДонНТУ, ДонНТУ, 2013. – C. 369-373
- Zaharia M. Improving MapReduce Performance in Heterogeneous Environments / M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, I. Stoica // Electronic edition, Berkley., 2009. – C. 69-75
- Xiao Z. A Hierarchical Approach to Maximizing MapReduce Efficiency / Z. Xiao, H. Chen, B. Zang // IEEE Computer Society., 2011. – C. 36-97
- Zaharia M. Improving MapReduce Performance in Heterogeneous Environments / M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, I. Stoica // Electronic edition, Berkley., 2009. – C. 325-331
- Rasooli A. An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems / A. Rasooli, D. G. Down // Department of Computing and Software McMaster University., 2012. – C. 257-289
- Sandholm T. Dynamic Proportional Share Scheduling in Hadoop [Електроний ресурс]. – Режим доступу: http://www.cs.huji.ac.il/~feit/parsched/jsspp10/p7-sandholm.pdf
- Shvachko K. The Hadoop Distributed File System. / Konstantin Shvachko, Hairong Kuang, Sanjai Radia, Robert Chansler //MSST '10 Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), 2010. - C. 1-10
- Hunt P. ZooKeeper: wait-free coordination for internet-scale systems. / P. Hunt, M. Konar, F. P. Junqueira, and B. Reed // USENIXATC'10: Proceedings of the 2010 USENIX conference on USENIX annual technical conference. Berkeley, CA, USA: USENIX Association, 2010. - C. 11–11
- Chang F. Bigtable: a distributed storage system for structured data. / F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, R. E. Gruber // Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation, vol. 7, p. 15-15