
Чуприн Владислав Ігорович
Факультет комп'ютерных наук и технологій
Кафедра прикладної математики та інформатики
Спеціальність «Інженерія программного забезпечення»
Підвищення ефективності реалізації моделі розподілених обчислень MapReduce у рамках програмного каркаса Hadoop
Науковий керівник: д.т.н., доц. Дмитрієва Ольга Анатоліївна
Реферат за темою випускної роботи
Вступ
1 Актуальність теми
2. Мета і завдання дослідження, плановані результати
3. Огляд
досліджень і розробок
3.1 Планувальник в Hadoop
3.2 Планувальник
«Longest Approximate Time to End (LATE)»
3.3 Рівномірний планування (FAIR scheduler) [5]
3.4 Hadoop 2.0. Capacity scheduler [6]
4. Запропонований алгоритм на основі лотерейного планування
Висновки
Список джерел
Вступ
Hadoop являє собою облачну систему для розподіленої обробки даних, в рамки якої входять завдання, описані відповідно до програмної моделі MapReduce. Для невеликих організацій, що використовують Hadoop, характерна наявність гетерогенних кластерів з усіх наявних у них ресурсів, а для великих корпоративних систем - наявність величезних гомогенних кластерів. Користувачами системи може бути група осіб, які характеризуються такими параметрами як пріоритети, зарезервована кількість обчислювальних потужностей, гарантована кількість розділяємого дискового простору та інше. Робоче навантаження всередині кластера має бути розподілене між довільною кількістю користувальницьких завдань і відповідати безлічі вимог.
Модель програмування. Під час виконання розподіленої обробки на вхід приймаються пари ключ/значення, і генерується результуюча множина аналогічних пар. Користувач бібліотеки MapReduce представляє обчислення у вигляді двох фаз: Map і Reduce. Map, написана користувачем, отримує на вхід, і створює на виході ключ/значення. Каркас MapReduce групує разом всі проміжні результати, отримані на фазі Map, з однаковим проміжним ключем, і передає їх на вхід фазі Reduce. Функція Reduce, зазвичай написана користувачем, приймає проміжний ключ і множину значень, пов'язаних з цим ключем, здійснюється об'єднання отриманих результатів у імовірно меншу множина значень. Зазвичай, в рамках одного виклику Reduce проводиться нуль чи одне вихідне значення. Проміжні значення подаються на вхід Reduce у ітеративному вигляді, що дозволяє зберігати списки значень, які є більшими, ніж розмір доступної оперативної пам'яті.
1 Актуальність теми
Планувальники відіграють критичну роль в досягненні нових рівнів продуктивності в системах на базі Hadoop. Важливо вибрати відповідний алгоритм планування, враховуючи обмеження, які накладає реалізація Hadoop, зберігаючи прийнятний рівень розподіленості.
2 Мета і завдання дослідження
Мета роботи полягає у проведенні порівняльного аналізу існуючих методів планування та розробки концепції оптимізованого методу. У рамках роботи, потрібно:
- дослідити реалізацію планувальника в Hadoop;
- проаналізувати існуючі алгоритми планування;
- запропонувати власний підхід на основі вивчених достоїнств і недоліків готових рішень;
3 Огляд досліджень і розробок
Основним джерелом, яке розкриває теоритичні основи парадигми MapReduce, можна вважати статтю Jeffrey Dean і Sanjay Ghemawat [1]. Реалізація планувальника в рамках Hadoop докладно описана в [3] і є максимально повним джерелом з цього питання. Глибокі дослідження підходів до оптимізації наведені в [4-8].
3.1 Планувальник в Hadoop
Реалізація MapReduce в Hadoop відповідає підходу, описаному в [1]. Один головний (master) вузол управляє множиною підлеглих (slaves) [2]. Файл з вихідними даними, який знаходиться в розподіленій файловій системі (HDFS), для забезпечення відмовостійкості і підвищення продуктивності розбивається на фрагменти (chunk) однакового розміру і реплікується із заданим коефіцієнтом дублювання. Hadoop розбиває отримані MapReduce завдання (job) на множину задач (task). Кожен фрагмент вхідної інформації обробляється заданою Map функцією. Результати Map фази розбиваються по ключу і спрямовуються на вхід фазі Reduce (рис. 1). Схема, наведена в [3] (рис. 2), ілюструє обчислення з використанням підходу MapReduce. Hadoop запускає кілька Map і Reduce завдань паралельно на кожному підпорядкованому вузлі - по 2 на кожному для перекриття простою CPU і дискової підсистеми. Кожен підлеглий вузол посилає головному вузлу повідомлення, коли слоти для обчислення завдань стають порожніми, і тоді планувальник призначає нові завдання вузлів. Вбудований в Hadoop планувальник запускає завдання в порядку FIFO з п'ятьма рівнями пріоритетів [3]. Коли слоти для виконання завдань звільняються, планувальник сканує наявні завдання в порядку убування пріоритетів, і зберігає час, витрачений на пошук необхідної задачі.
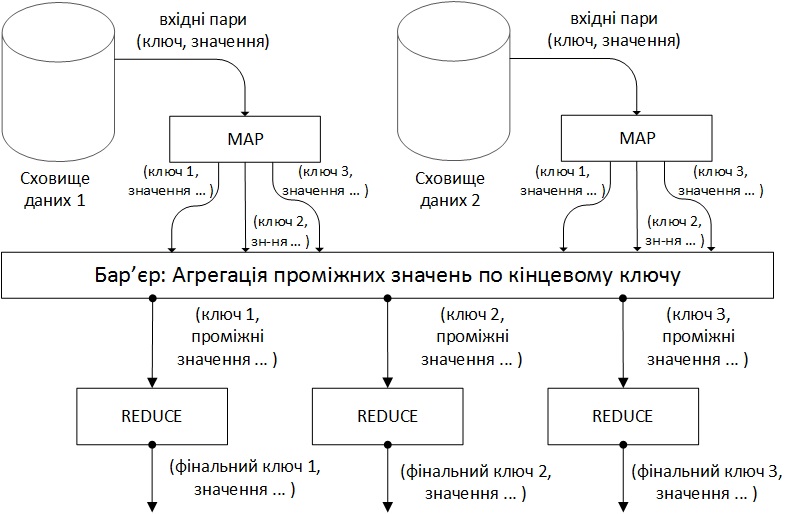
Рисунок 1 - Схема обчислень MapReduce
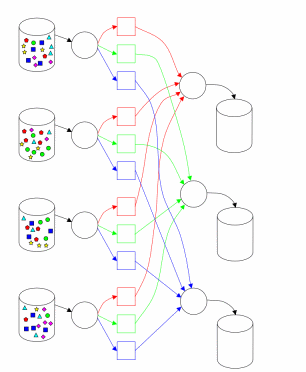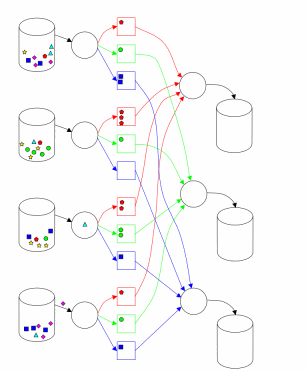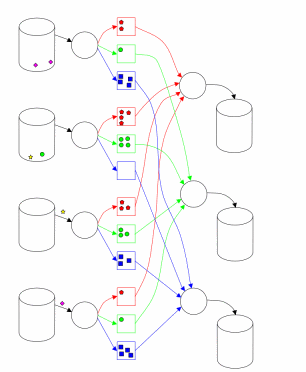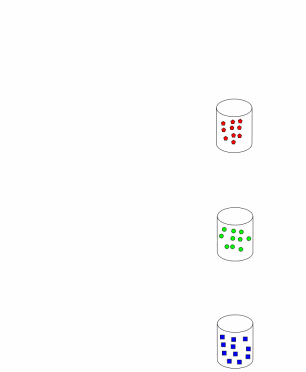
Рисунок 2 - Виконання MapReduce
(анімація: 35 кадрів, 10 циклів повторення, 112 кілобайт)
Для Map завдань планувальник використовує локальну оптимізацію, реалізовану в Google MapReduce [1]: після вибору завдання планувальник розподіляє Map завдання на вузли, що містять максимальну кількість даних для виконання (якщо можливо, всі дані повинні знаходиться на обраному вузлі, інакше - на одному з вузлів стійки і, нарешті, на віддаленій стійці). Hadoop, використовує резервне копіювання завдань для пом'якшення проблеми гетерогенних кластерів [1].
Планувальник в Hadoop виконує такі неявні припущення:
- Вузли повинні виконувати завдання строго за однаковий час.
- Завдання однаково інтенсивно використовують ресурси протягом усього часу виконання.
- Відсутні витрати на запуск спекулятивних завдань на вузлах, які мають простоюючий слот.
- Відсоток виконання певного завдання цілком відображає розмір виконаної роботи.
- Завдання з поганим прогресом стають відстаючими (strugglers).
- Завдання в одній категорії (Map або Reduce) вимагають однакового обсягу роботи.
3.2 Планувальник «Longest Approximate Time to End (LATE)»
Запропонований спекулятивний планувальник завдань дозволяє частково боротися з наведеними вище недоліками в оточеннях з умовами, більш наближеними до реальних. Основна ідея полягає в наступному: «Планувальник зазвичай спекулятивно запускає завдання які будуть мати найменшу тривалість виконання, так як ці завдання надають найкращі можливості для спекулятивного копіювання для обгону оригінальних завдань та мінімізації часу виконання завдання» [4]. Інтуїтивно подібна жадібна політика добра, якщо вузли працюють з постійною швидкістю, а також за відсутності витрат на запуск спекулятивної завдання на іншому вузлі, який простоює.
Для отримання найкращих шансів на розбиття вихідної задачі на спекулятивні вона повинна запускатися тільки на швидких вузлах - не відстаючих (stragglers) [10]. Планувальник досягає цього за допомогою простої евристики - не відкриваючи завдання на вузлах повільніше деякого порога, загальної виконаної роботи для усіх успішно завершених і виконаних завдань на вузлі. Ця евристика дозволяє досягти кращої продуктивності, ніж призначення спекулятивних завдань на перший вільний вузол. Інша опція дозволяє створення більш ніж однієї спекулятивної копії кожного завдання, однак може витрачати ресурси дарма. Як і планувальник Hadoop, відповідно до запропонованого алгоритму, виконується очікування протягом 1 хвилини перед запуском спекулятивної завдання.
3.3 Рівномірний планування (FAIR scheduler) [5]
Порталом Facebook був представлений рівномірний планувальник для розподілення завдань з використанням слотів. Його основні ідеї:
- Ізольованість: створення для всіх користувачів (завдань) ілюзії роботи на абсолютно приватному кластері.
- Статистичний перерозподіл: перерозподіл невикористаних обчислювальних ресурсів від одних користувачів іншим.
Планувальник використовує 2-х рівневу ієрархію. На верхньому рівні, виконується розбиття задач на пули, а на нижньому розбиття на слоти ресурсів, виділених під пул, між його завданнями (рис. 3). Варто відзначити, що планувальник в загальному випадку може бути узагальнений до довільної кількості рівнів. FAIR використовує ті ж алгоритми для розподілу слотів між завданнями пулу, що і планувальник Hadoop для розбиття на вузли [7]. Таким чином, можливі різні модифікації, відмінні від FIFO.

Рисунок 3 - Розподіл завдань по пулам
3.4 Hadoop 2.0. Capacity scheduler [6]
Планувальник обчислювальної потужності має деякі спільні риси з рівномірним планувальником, але є і значні відмінності. По-перше, планування обчислювальної потужності розраховане на великі кластери, які можуть мати кілька незалежних споживачів і кілька цільових додатків [8]. З цієї причини планувальник пропонує розширені можливості управління, а також надає гарантовану мінімальну обчислювальну потужність і розділяє надлишки обчислювальної потужності між користувачами. При плануванні обчислювальної потужності замість пулів створюються кілька черг, кожна - з конфігурованою кількістю слотів для Map і Reduce фаз [7]. Кожній черзі також призначається деяка гарантована обчислювальна потужність, при цьому загальна обчислювальна потужність кластера являє собою суму обчислювальних потужностей всіх черг. Черги контролюються, і якщо яка-небудь черга не споживає виділену їй обчислювальну потужність, надлишки можуть бути тимчасово віддані іншим чергам. З урахуванням того, що черги можуть представляти як фізичних осіб, так і великі організації, будь-які вільні обчислювальні ресурси перерозподіляється іншим споживачам.
4 Запропонований алгоритм на основі лотерейного планування
В основі алгоритму лежить роздача завданням лотерейних квитків на доступ до обчислювальних ресурсів. Коли планувальнику необхідно прийняти рішення, вибирається випадковим чином лотерейний квиток, і його володар отримує право запускати свої завдання на вузлах кластера. Більш важливим завданням можна роздати додаткові квитки, щоб збільшити ймовірність виграшу.
Лотерейне планування характеризується кількома цікавими властивостями. Наприклад, якщо при постановці в чергу завданням дістається кілька квитків, то вже в наступній лотереї його шанси на виграш пропорційні кількості квитків. Іншими словами, лотерейне планування має високу чутливість. Завдання одного користувача можуть при необхідності обмінюватися квитками. Так, якщо від користувача приходить нове, більш пріоритетне завдання, то частина існуючих квитків може бути віддано на його користь.
Лотерейне планування дозволяє вирішувати завдання, які не вирішити за допомогою інших алгоритмів. Як приклад можна привести кластер, на якому виконується обробка користувальницьких пошукових запитів. Частина запитів можуть міняти свій пріоритет в залежності від уже відправлених, наприклад, з причини незначно відмінності запитуваної інформації. Тоді одному із завдань можна видати частину кредитів вже існуючого для оптимізації часу відгуку і деталізувати пошукову видачу в момент закінчення менш пріоритетного завдання.
Висновки
Впровадження планувальника, який можна підключати, стало ще одним кроком в еволюції кластерних обчислень з використанням системи Hadoop. Підтримка підключаються планувальників дозволяє використовувати (і розробляти) планувальники, оптимізовані для конкретного робочого навантаження і конкретного программного забезпечення [9]. Крім того, нові планувальники зробили можливим створення багатокористувацьких сховищ даних з використанням системи Hadoop, завдяки забезпеченню можливості спільного використання всієї інфраструктури Hadoop декількома користувачами і організаціями.
Система Hadoop розвивається разом з еволюцією її моделей використання і тепер підтримує нові типи робочих навантажень і сценаріїв використання (наприклад, великі багатокористувацькі сховища даних і загальні сховища даних для декількох організацій). Ці нові гнучкі можливості, які надає Hadoop, є величезним кроком вперед у напрямку більш оптимізованого використання кластерних ресурсів при аналізі великих обсягів даних.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2014 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після вказаної дати.
Список літератури
- Dean J. Simplified Data Processing on Large Clusters / J. Dean, S. Ghemawat // Electronic edition, Google Inc., 2004. – 16 c
- Чуприн В.И. Анализ проблем безопасности архитектуры распределённых NoSQL приложений на примере программного каркаса Hadoop / В.И. Чуприн, А.В. Чернышова, Н.Е. Губенко // Материалы конференции VI международной научно-технической конференции "Інформатика та комп'ютерні технології", Донецьк, ДонНТУ, ДонНТУ, 2013. – C. 369-373
- Zaharia M. Improving MapReduce Performance in Heterogeneous Environments / M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, I. Stoica // Electronic edition, Berkley., 2009. – C. 69-75
- Xiao Z. A Hierarchical Approach to Maximizing MapReduce Efficiency / Z. Xiao, H. Chen, B. Zang // IEEE Computer Society., 2011. – C. 36-97
- Zaharia M. Improving MapReduce Performance in Heterogeneous Environments / M. Zaharia, A. Konwinski, A. D. Joseph, R. Katz, I. Stoica // Electronic edition, Berkley., 2009. – C. 325-331
- Rasooli A. An Adaptive Scheduling Algorithm for Dynamic Heterogeneous Hadoop Systems / A. Rasooli, D. G. Down // Department of Computing and Software McMaster University., 2012. – C. 257-289
- Sandholm T. Dynamic Proportional Share Scheduling in Hadoop [Електроний ресурс]. – Режим доступу: http://www.cs.huji.ac.il/~feit/parsched/jsspp10/p7-sandholm.pdf
- Shvachko K. The Hadoop Distributed File System. / Konstantin Shvachko, Hairong Kuang, Sanjai Radia, Robert Chansler //MSST '10 Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), 2010. - C. 1-10
- Hunt P. ZooKeeper: wait-free coordination for internet-scale systems. / P. Hunt, M. Konar, F. P. Junqueira, and B. Reed // USENIXATC'10: Proceedings of the 2010 USENIX conference on USENIX annual technical conference. Berkeley, CA, USA: USENIX Association, 2010. - C. 11–11
- Chang F. Bigtable: a distributed storage system for structured data. / F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, R. E. Gruber // Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation, vol. 7, p. 15-15