
Разработка подсистемы решения уравнений для проблемно-ориентированных параллельных сред моделирования
Содержание
- Введение
- 1. Цель и задачи разработки новой подсистемы
- 2. Обзор существующих решений
- 3. Сравнение эффективности различных способов представления данных
- Выводы
- Список источников
Введение
Метод дискретного элемента (DEM), изначально разработанный Канделом и Стрэком, является наиболее мощным инструментом для расчета динамики большого количества частиц размера микрон и более [1]. Использование этого подхода означает, что исследуемая система представлена в виде набора отдельных частиц. Каждая частица описывается независимо от остальных, и в каждом шаге дискретизации по времени для каждой гранулы решаются уравнений движения Ньютона.
Использование DEM требует построения моделей технологических систем с большим набором дискретных частиц. На текущий момент количество моделируемых элементов может варьироваться между 103 и 107.
Результатом DEM моделирования является набор зависящих от времени параметров, таких как координаты, скорости, ускорения, что на практике представляется массивами данных. Эти характеристики должны быть сохранены на жестком диске и загружены с него в целях пост-обработки. Большого количества частиц (107), малые значения времени моделирования – с шагом порядка 1мкс и большой набор зависящих от времени параметров приводит к большому объем генерируемых данных. Типичный пример моделирования – 1 секунда работы аппарата с псевдоожиженным слоем с 150000 частиц генерирует набор данных, объемом 60 Гб [2].
Для сокращения используемого места на диске и ускорения работы с большим объемом данных, стоит задача разработки нового формат файла, позволяющий более эффективно обрабатывать и хранить данные.
1. Цель и задачи разработки новой подсистемы
Целью работы является ускорение процесса моделирования и постобработки данных за счет эффективного размещения данных в файле. Для достижения цели необходимо сравнить уже разработанные форматы файлов, выделить их достоинства и недостатки, и на основе полученных данных разработать формат, наиболее удовлетворяющий задаче моделирования. Сначала необходимо рассмотреть подробнее, что такое формат файла.
Различные форматы файлов могут различаться степенью детализации, один формат может быть «надстройкой» над другим или использовать элементы других форматов. Например, текстовый формат накладывает только самые общие ограничения на структуру данных. Формат HTML устанавливает дополнительные правила на внутреннее устройство файла, но при этом любой HTML-файл является в то же время текстовым файлом.
Текстовый формат файла – это формат, основанный на plain text. Вся информация представлена в виде текста. В текстовом формате можно представить любую информацию – но её нужно закодировать в текстовый вид.
В прикладных задачах для хранения данных используют текстовый формат CSV, XML, некоторые бинарные форматы, такие как EBML, HDF5 а так же часто разрабатывают свой бинарный формат. Каждый из перечисленных форматов имеет свои преимущества и недостатки, для более детального анализа нужно выполнить сравнение текстового и бинарного форматов.
2. Обзор существующих решений
Текстовый формат. Применимо к среде DEM моделирования был реализован формат хранения данных в CSV. Это формат имеет простую структуру, которая позволяет пользователю изменять данные в файле с помощью любого текстового редактора или использовать их в собственной программе. Новые частицы могут быть легко добавлены, а так же уже существующие частицы могут быть модифицированы или удалены без повреждения данных. Каждая частица хранится в виде одной строки текстового файла. В начале файла хранятся не зависящие от времени данные. Далее, во второй части файла хранятся зависящие от времени данные, такие как координаты и скорости частиц. На рисунке 2.1 представлена общая организация данных в файле. Весь файл представлен в виде непрерывного потока байтов.
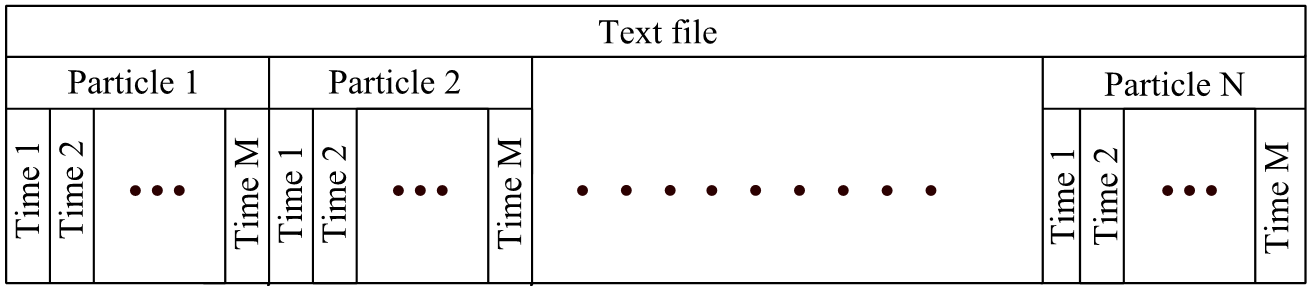
Рисунок 2.1 – Структура тестового файла
Несмотря на ранее описанной достоинства, у этого подхода к хранению есть ряд недостатков, который значительно ограничивает применимость данного формата. Первый недостаток – большой размер файлов с данными. Текстовый формат подразумевает, что любая цифра десятичной записи числа сохраняется как однобайтовый символ. Например, вместо 2 байтов, которые необходимы, чтобы сохранить значение ‘12345’, будут использованы 5 байт. Другой недостатком является относительно медленный доступ к данным. Чтобы сохранить данные одной частицы для различных моментов времени, может использоваться разное число байт. Именно поэтому невозможно определить точное смещение требуемого времени в файле. Для визуализации или для последующей обработки результатов моделирования, необходимо получить свойства частицы для определенного момента времени. Однако, запрошенная информация распределена по всему файлу, и так как невозможно определить точное положение нужных данных, файл должен быть прочитан полностью, даже если необходима информация только для конкретного короткого промежутка времени [3].
Во время моделирования необходимо хранить все данные полностью в оперативной памяти. Это ограничивает максимальный размер сгенерированных данных и вынуждает ограничивать объем данных размером виртуального адресного пространства. Например, в 32-разрядной архитектуре IA32 это 2 Гбайт.
Бинарный формат. Новый подход к хранению данных основывается на бинарном формате данных, поэтому размер сгенерированных файлов значительно меньше, по сравнению с текстовым. Двоичные данные расположены в файле в ином порядке, по сравнению с текстовым форматом. Независящие от времени данные, такие как количество частиц, их тип и масса хранятся в отдельном фале. В файле с зависящими от времени параметрами, все данные о одном моменте времени хранятся как один блок. Благодаря таком подходу, для того чтобы воспроизвести один «снимок» системы в процессе моделирования, достаточно загрузить только один блок данных из файла, а так как в нем содержатся все необходимые данные, нет потребности загрузить все данные в оперативную память.
В файле с независимыми от времени параметрами частиц, сохранятся так же дополнительная информация о размещении блоков данных в файле с координатами и скоростями. Это позволяет быстро находить данные, необходимые для воспроизведения определенного момента процесса моделирования [4].
Для сокращения используемого объема памяти используется линейная интерполяция данных. Это означает, когда значение для точки требуемого времени сможет быть предсказано от уже сохраненных данных, тогда новая точка данных не будет сохранена. Такой способ хранения уменьшает размер файла, но в случае с двоичными файлами это затрудняет реализацию. С текстовым форматом такой проблемы нет, потому что он полностью загружен в оперативную память. Но в случае двоичного формата данные для некоторой частицы могут отсутствовать в определенном моменте времени. Следовательно, оказывается невозможным получить запрошенную информацию. Чтобы избежать этой проблемы, в начале каждого блока данных, хранится информация о всех частицах, вне зависимости, возможно верно интерполировать значения, или нет.
Общая структура формата файла, который используется для хранения данных, показана на рисунке 2.2. В первом моменте времени любого блока данных хранится вся информация о каждой частице. Чтобы получить требуемую информацию для определенного момента времени, достаточно загрузить всего один блок данных [5].
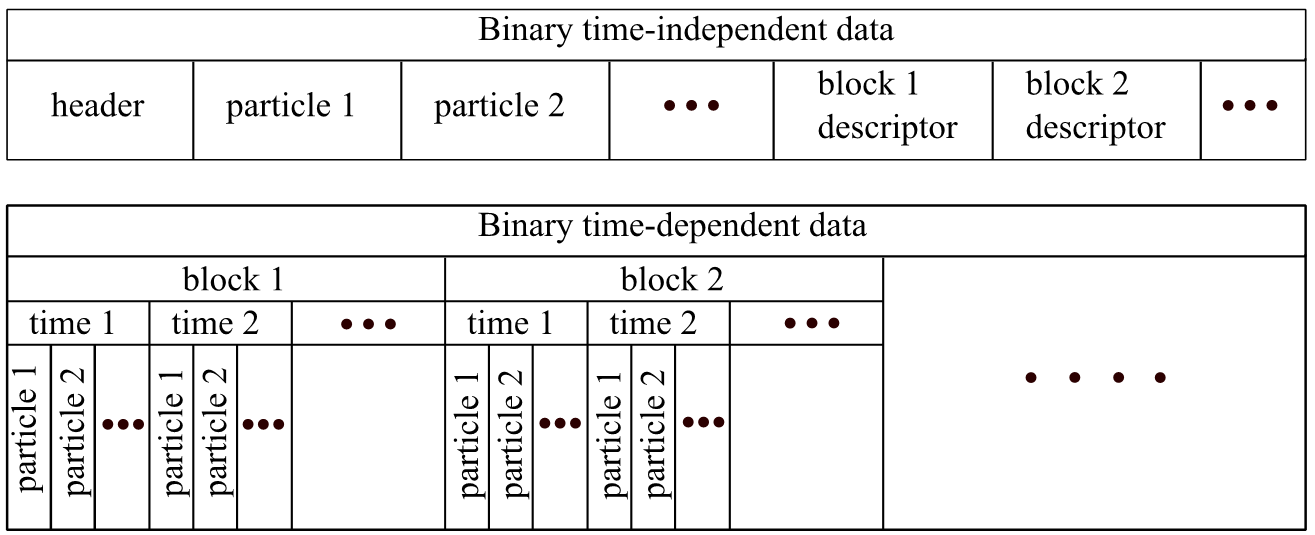
Рисунок 2.2 – Расположение данных в бинарном файле
В текущей версии среды моделирования, для которой разрабатывался формат, операции, связанные с хранением данных, инкапсулируются с подсистеме ввода-вывода. Чтобы создать новые частицы, удалить существующие и выполнить другие операции, был реализован общий интерфейс к системе хранения данных, не зависящий от используемого формата. Если используется бинарный формат файла, то автоматически выполняется свопинг данных на диск, что позволят освободить память от излишних данных [6].
В оперативную память всегда загружается по крайней мере 2 блока данных. Это необходимо, чтобы использовать алгоритм линейной интерполяции. Каждый раз, когда программа пытается получить доступ к некоторым данным, зависимым от времени, вызывается низкоуровневый менеджер ввода-вывода. Этот менеджер проверяет, присутствует ли требуемый блок в RAM. Если требуемый блок не был загружен, то текущие блоки из памяти удаляются, а новые загружаются.
В случае операций записи диспетчер ввода-вывода анализирует суммарный объем данных, который уже имеется в оперативной памяти. Когда объем данных в памяти превышает максимальный допустимый размер блока, тогда данные сохраняются на жесткий диск как отдельный блок.
Обобщенные блок-схемы алгоритмов сохранения и загрузки данных приведены на рисунке 2.3.
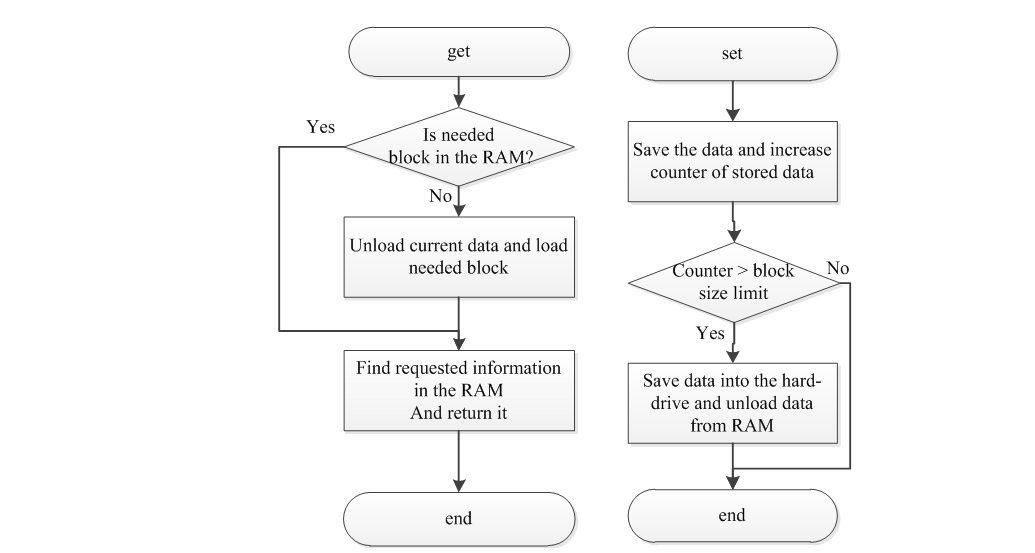
Рисунок 2.3 – Алгоритмы записи и чтения данных
3. Сравнение эффективности различных способов представления данных
Для того чтобы сравнить работу системы моделирования с текстовым и двоичным форматами файла, были разработаны и проведены тесты производительности. Результаты тестирования изображены в рисунке 3.2. Процесс доступа к данным с учетом блочного доступа к жесткому диску представлен на рисунке 3.1. На нем наглядно видно, что правильное расположения данных позволяет значительно ускорить процесс их обработки.
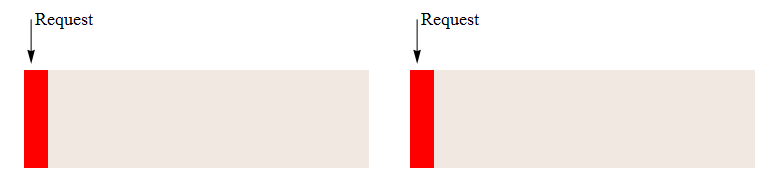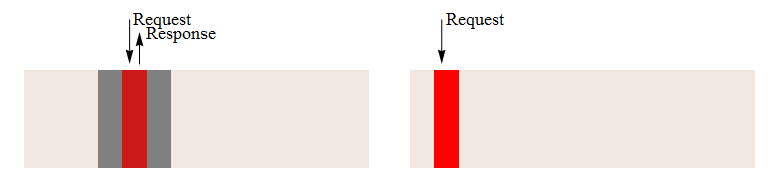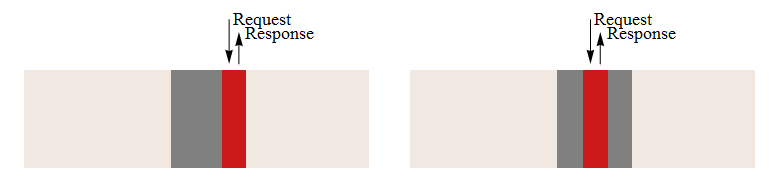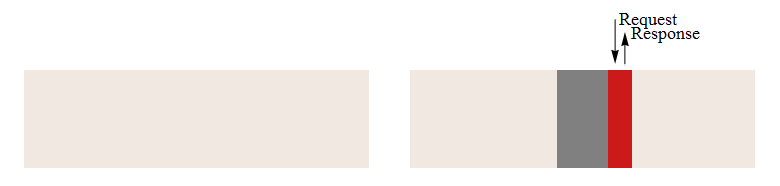
Рисунок 3.1 – Процесс чтения файла
(анимация: 18 кадров, 0.5 секунды интервал между кадрами, размер 35,3 килобайта, создана с помощью Wolfram Mathematica)
(анимация: 18 кадров, 0.5 секунды интервал между кадрами, размер 35,3 килобайта, создана с помощью Wolfram Mathematica)
На рисунке 3.2 слева показано время, которое требуется, чтобы открыть файл данных. При полученных результатах, может быть сделан вывод, что двоичные файлы в большинстве случаев загружаются больше чем в 10 раз быстрее текстовых. На рисунке 3.2 справа показана зависимость между временем произвольного доступа и размером файла. При использовании двоичного формата нет необходимости хранить все данные в RAM, следовательно использование памяти значительно меньше. Такой подход позволяет моделировать процессы с большим количеством частиц на длительном интервале времени.
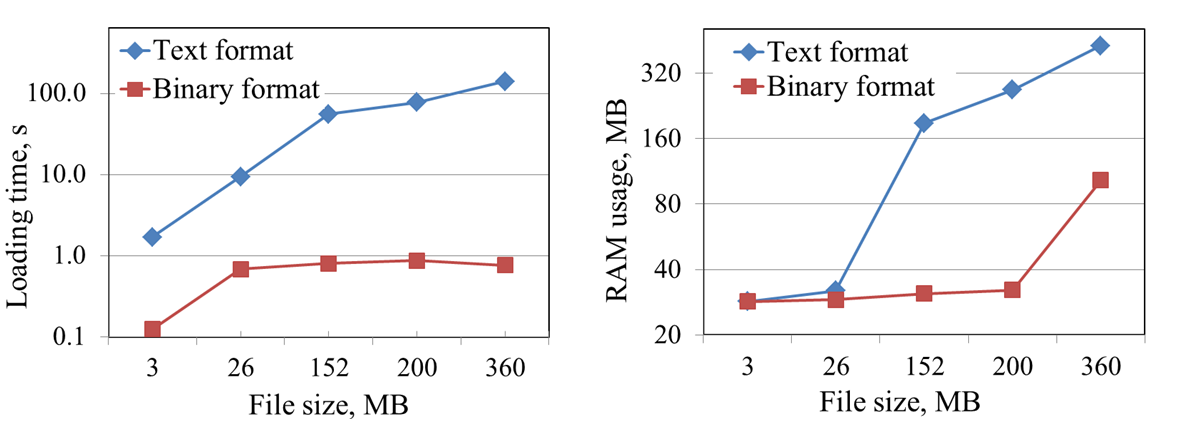
Рисунок 3.2 – Результаты тестов производительности, часть I
Однако, чтение и запись данных выполняются значительно медленнее, чем в текстовом формате. В случае двоичных данных требуется приблизительно 100мс для того чтобы получить данные, которые помещены в другой блок. Это можно увидеть на графиках, изображенных на рисунке 3.3 справа. Отношение между размером двоичного и текстового формата показано в рисунке 3.3 слева. При анализе проиллюстрированных результатов может быть сделан вывод о том, что двоичные файлы имеют значительно меньший объем, чем текстовые файлы.
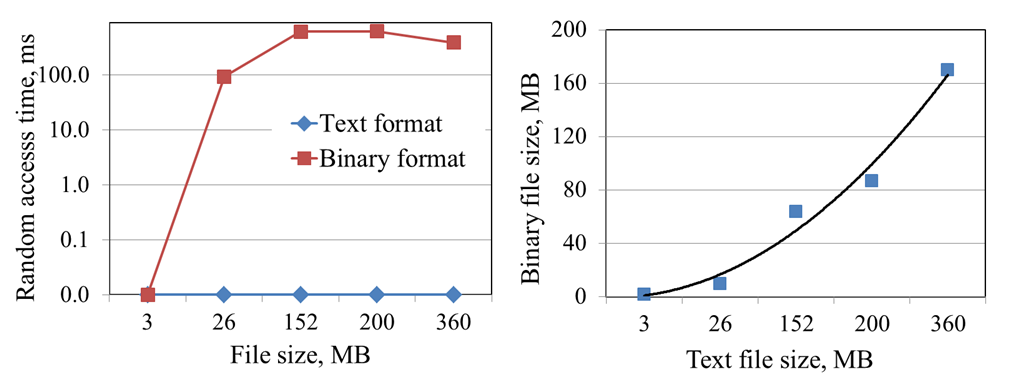
Рисунок 3.3 – Результаты тестов производительности, часть II
Выводы
Результаты, генерируемые системой моделирования методом дискретного элемента, состоят из огромного набора данных. Чтобы выполнить последующую обработку результатов, должен быть разработан эффективный формат хранения данных. В данной работе был предложен новый подход, позволяющий хранить данные DEM моделирования более эффективно и снять ряд ограничений, такие как объем оперативной памяти и скорость ввода-вывода.
Новый метод хранения основывается на использовании двоичного формата файла, в котором результаты DEM разделены по отдельным блоками данных. Эти блоки сохранены независимо друг от друга и лишь несколько из них загружены в RAM в каждый момент времени. Такой подход оптимизирует использование памяти и увеличивает эффективность программы. Как другое преимущество нового формата может быть подчеркнута минимизация размера файлов данных.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Cundall P.A., Strack O.D.L. A discrete numerical model for granular assemblies. Geotechnique 29, 1979, 47-65.
- Янушкевич В.А., Святный В.А. «Сравнение способов хранения данных в процессе моделирования сыпучих веществ»
- Cundall, P. A., Strack, O. D. L., 1979. Numerical models for granular assemblies. Geotechnique, pp. 47-65.
- Dosta M., Antonyuk S., Heinrich2 S. „Multiscale simulation of fluidized bed granulation process”, Chemical Engineering Technology, 2012, Vol. 35, 1373-1380.
- Antonyuk S., Khanal M., Tomas J., Heinrich S. Impact breakage of spherical granules: experimental study and DEM simulation, Chemical Engineering and Processing 45, 2006, 838-856.
- Poschel, T., Saluena, C., Schwager, T., 2001. Scaling properties of granular materials. Physical Review E 64 (1), (Art. No. 011308 Part 1).
- Schaefer, J., Dippel, S., Wolf, D.E., 1996. Force schemes in simulations of granular materials. Journal De Physique I 6 (1), 5–20.
- Walton, O.R., Braun, R.L. Viscosity, granular-temperature, and stress calculations for shearing assemblies of inelastic, frictional disks. Journal of Rheology, 30, 1986, 949- 980.
- Poeschel T., Schwager T. Computational granular dynamics. Models and algorithms. Springer, 2005.
- Ianushkevych V., Dosta M. (M.Sc.), Antonyuk S. (Dr.-Ing.), Heinrich2 S. (Prof.), Svyatnyy V.A. (Prof.) "Advanced data storage of DEM simulations results"