
Розробка підсистеми рішення рівнянь для проблемно-орієнтованих паралельних середовищ моделювання
Зміст
- Вступ
- 1. Мета і завдання розробки нової підсистеми
- 2. Огляд існуючих рішень
- 3. Порівняння ефективності різних способів зберігання даних
- Висновки
- Список джерел
Вступ
Метод дискретного елемента (DEM), спочатку розроблений, є найбільш потужним інструментом для розрахунку динаміки великої кількості частинок розміру мікрон і більше [1]. Використання цього підходу означає, що досліджувана система представлена у вигляді набору окремих частинок. Кожна частка описується незалежно від інших, і в кожному кроці дискретизації по часу для кожної гранули вирішуються рівнянь руху Ньютона.
Використання DEM вимагає побудови моделей технологічних систем з великим обсягом дискретних частинок. На поточний момент кількість елементів у системі може варіюватися між 103 та 107.
Результатом DEM моделювання є набір залежних від часу параметрів, таких як координати, швидкості, прискорення, що на практиці представляється масивами даних. Ці характеристики повинні бути збережені на жорсткому диску і завантажені з нього в цілях пост-обробки.Велика кількість частинок (107), малі значення часу моделювання - з кроком порядку 1мкс і великий набір залежних від часу параметрів призводить до великої обсяг генеруються даних. Типовий приклад моделювання - 1 секунда роботи апарату з псевдозрідженим шаром з 150000 частинок генерує набір даних, об'ємом 60 Гб [2].
Для скорочення використовуваного місця на диску і прискорення роботи з великим обсягом даних, стоїть завдання розробки нового формат файлу, що дозволяє більш ефективно обробляти і зберігати дані.
1. Мета і завдання розробки нової підсистеми
Метою роботи є прискорення процесу моделювання і постобробки даних за рахунок ефективного розміщення даних у файлі. Для досягнення мети необхідно порівняти вже розроблені формати файлів, виділити їх достоїнства і недоліки, і на основі отриманих даних розробити формат, найбільш задовольняє завданню моделювання. Спочатку необхідно розглянути докладніше, що таке формат файлу.
Різні формати файлів можуть різнитися ступенем деталізації, один формат може бути "надбудовою" над іншим або використовувати елементи інших форматів. Наприклад, текстовий формат накладає лише загальні обмеження на структуру даних. Формат HTML встановлює додаткові правила на внутрішній устрій файлу, але при цьому будь-який HTML-файл є в той же час текстовим файлом.
Текстовий формат файлу - це формат, заснований на plain text. Вся інформація представлена у вигляді тексту. У текстовому форматі можна представити будь-яку інформацію - але її потрібно закодувати в текстовий вигляд.
У прикладних задачах для зберігання даних використовують текстовий формат CSV, XML, деякі бінарні формати, такі як EBML, HDF5 а так само часто розробляють свій бінарний формат. Кожен з перерахованих форматів має свої переваги і недоліки, для більш детального аналізу потрібно виконати порівняння текстового і бінарного форматів.
2. Огляд існуючих рішень
Текстовый формат. Застосовується до середовищі DEM моделювання був реалізований формат зберігання даних в CSV. Це формат має просту структуру, яка дозволяє користувачеві змінювати дані у файлі з допомогою будь-якого текстового редактора або використовувати їх у власній програмі. Нові частки можуть бути легко додані, а так само вже існуючі частинки можуть бути модифіковані або видалені без пошкодження даних. Кожна частка зберігається у вигляді одного рядка текстового файлу. На початку файлу зберігаються не залежать від часу дані. Далі, у другій частині файлу зберігаються залежать від часу дані, такі як координати і швидкості частинок. На рисунку 2.1 представлена загальна організація даних у файлі. Весь файл представлений у вигляді безперервного потоку байтів.
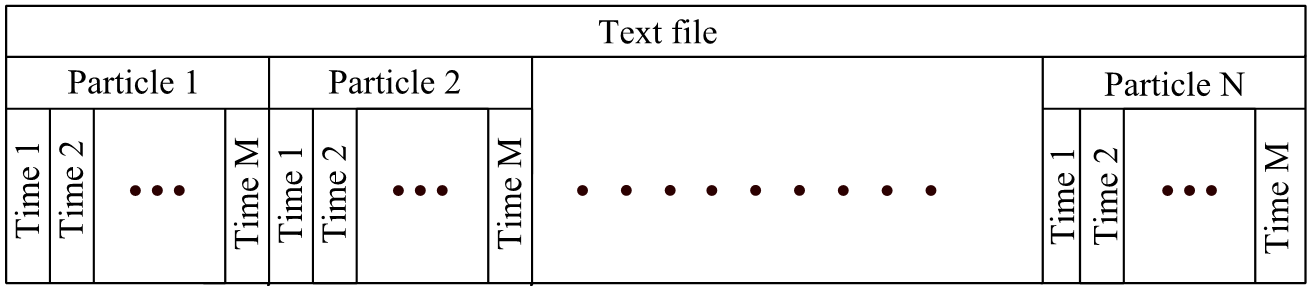
Рисунок 2.1 – Структура тестового файлу
Незважаючи на раніше описаної гідності, у цього підходу до зберігання є ряд недоліків, який значно обмежує застосовність даного формату. Перший недолік - великий розмір файлів з даними. Текстовий формат передбачає, що будь-яка цифра десяткового запису числа зберігається як однобайтовий символ. Наприклад, замість 2 байтів, які необхідні, щоб зберегти значення '12345', будуть використані 5 байт. Інший недоліком є відносно повільний доступ до даних. Щоб зберегти дані однієї частинки для різних моментів часу, може використовуватися різне число байт. Саме тому неможливо визначити точний зсув необхідного часу у файлі. Для візуалізації або для подальшої обробки результатів моделювання, необхідно отримати властивості частинки для певного моменту часу. Однак, запитана інформація розподілена по всьому файлу, і так як неможливо визначити точне положення потрібних даних, файл повинен бути прочитаний повністю, навіть якщо необхідна інформація тільки для конкретного короткого проміжку часу [3].
Під час моделювання необхідно зберігати всі дані повністю в оперативній пам'яті. Це обмежує максимальний розмір згенерованих даних і змушує обмежувати обсяг даних розміром віртуального адресного простору. Наприклад, в 32-розрядної архітектури IA32 це 2 Гбайт.
Бінарний формат. Новий підхід до зберігання даних грунтується на бінарному форматі даних, тому розмір згенерованих файлів значно менше, в порівнянні з текстовим. Двійкові дані розташовані у файлі в іншому порядку, в порівнянні з текстовим форматом. Незалежні від часу дані, такі як кількість частинок, їх тип і маса зберігаються в окремому фалі. У файлі з залежними від часу параметрами, всі дані про одному моменті часу зберігаються як один блок. Завдяки такому підходу, для того щоб відтворити один кадр системи в процесі моделювання, досить завантажити тільки один блок даних з файлу, а так як в ньому містяться всі необхідні дані, немає потреби завантажити всі дані в оперативну пам'ять.
У файлі з незалежними від часу параметрами частинок, збережуться також додаткова інформація про розміщення блоків даних у файлі з координатами і швидкостями. Це дозволяє швидко знаходити дані, необхідні для відтворення певного моменту процесу моделювання [4].
Для скорочення використовуваного об'єму пам'яті використовується лінійна інтерполяція даних. Це означає, коли значення для точки необхідного часу зможе бути передбачене від уже збережених даних, тоді нова точка даних не буде збережена. Такий спосіб зберігання зменшує розмір файлу, але у випадку з двійковими файлами це ускладнює реалізацію. З текстовим форматом такої проблеми немає, тому що він повністю завантажений в оперативну пам'ять. Але у випадку довічного формату дані для деякої частки можуть бути відсутні в певному моменті часу. Отже, виявляється неможливим отримати запитану інформацію. Щоб уникнути цієї проблеми, на початку кожного блоку даних, зберігається інформація про всіх частинках, незалежно, можливо вірно інтерполювати значення, чи ні.
Загальна структура формату файлу, який використовується для зберігання даних, показана на рисунку 2.2. У першому моменті часу будь-якого блоку даних зберігається вся інформація про кожній частці. Щоб отримати необхідну інформацію для певного моменту часу, досить завантажити всього один блок даних [5].
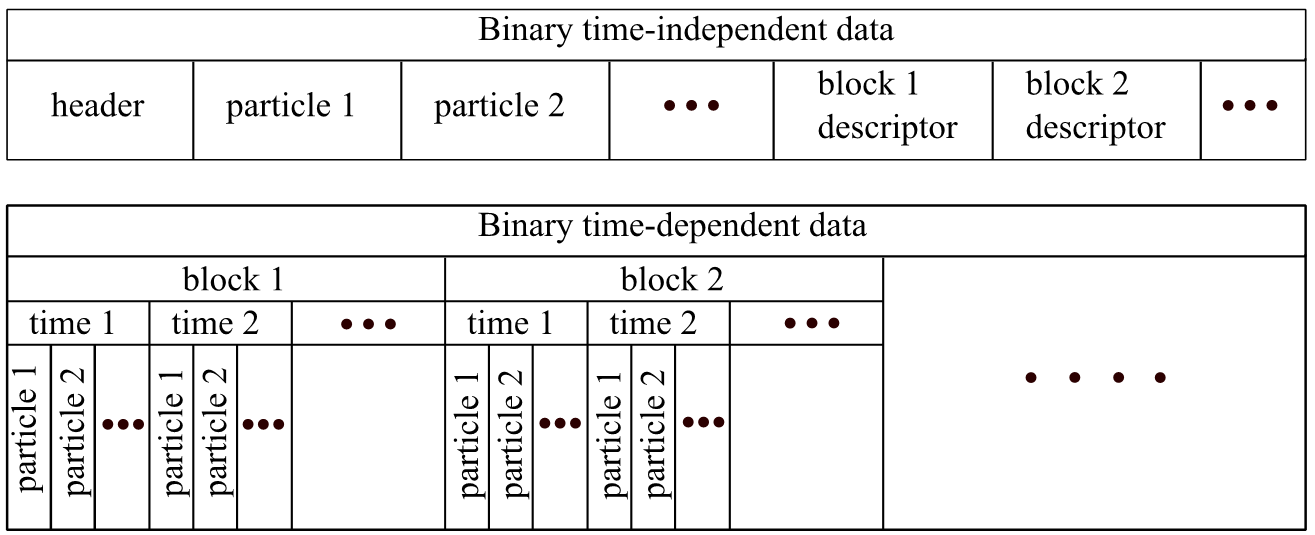
Рисунок 2.2 – Розташування даних в бінарному файлі
У поточній версії середовища моделювання, для якої розроблявся формат, операції, пов'язані із зберіганням даних, инкапсулируются з підсистемі введення-виведення. Щоб створити нові частинки, видалити існуючі та виконати інші операції, був реалізований загальний інтерфейс до системи зберігання даних, що не залежить від використовуваного формату. Якщо використовується бінарний формат файлу, то автоматично виконується свопинг даних на диск, що дозволять звільнити пам'ять від зайвих даних [6].
В оперативну пам'ять завжди завантажується принаймні 2 блоку даних. Це необхідно, щоб використовувати алгоритм лінійної інтерполяції. Кожен раз, коли програма намагається отримати доступ до деяких даних, залежним від часу, викликається низькорівневий менеджер вводу-виводу. Цей менеджер перевіряє, чи присутній необхідний блок в RAM. Якщо потрібний блок не був завантажений, то поточні блоки з пам'яті видаляються, а нові завантажуються.
У разі операцій запису диспетчер вводу-виводу аналізує сумарний обсяг даних, який вже є в оперативній пам'яті. Коли об'єм даних у пам'яті перевищує максимальний допустимий розмір блоку, тоді дані зберігаються на жорсткий диск як окремий блок.
Узагальнені блок-схеми алгоритмів збереження і завантаження даних наведені на рисунку 2.3.
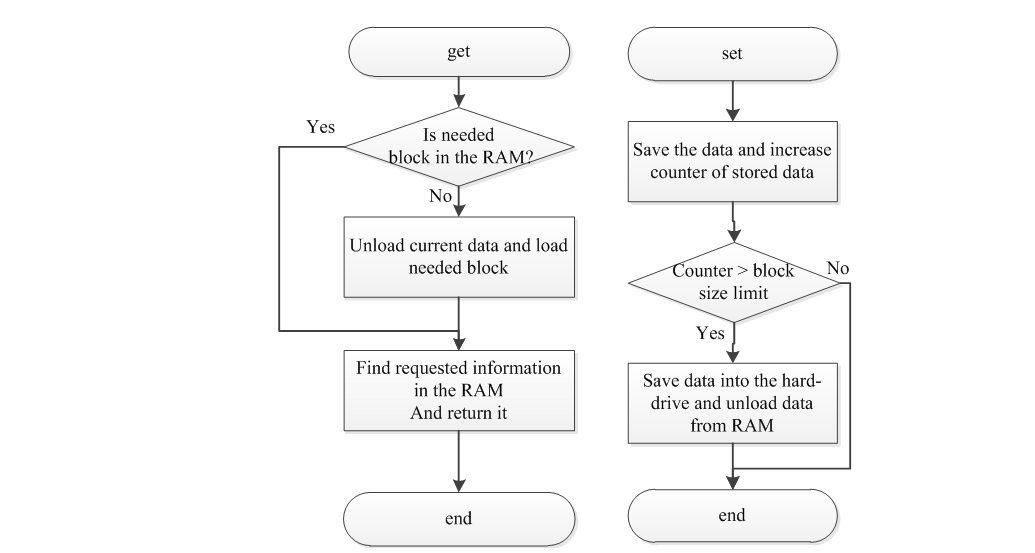
Рисунок 2.3 – Алгоритми запису і читання даних
3. Порівняння ефективності різних способів зберігання даних
Для того щоб порівняти роботу системи моделювання з текстовим і двійковим форматами файлу, були розроблені і проведені тести продуктивності. Результати тестування зображені у рисунку 3.2. Процес доступу до даних з урахуванням блочного доступу до жорсткого диску представлений на рисунку 3.1. На ньому наочно видно, що правильне розташування даних дозволяє значно прискорити процес їх обробки.
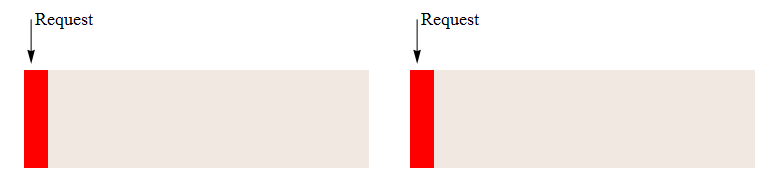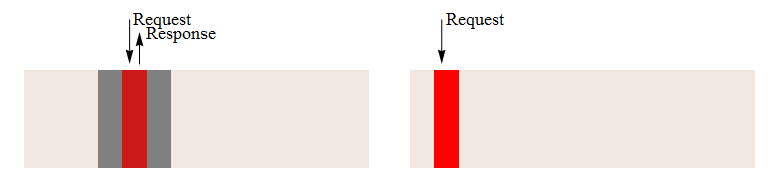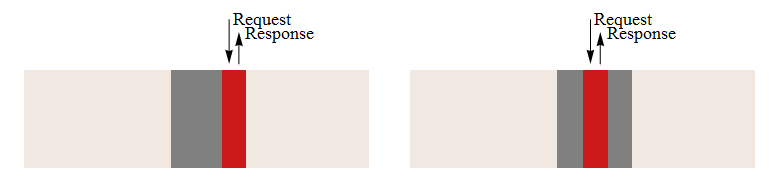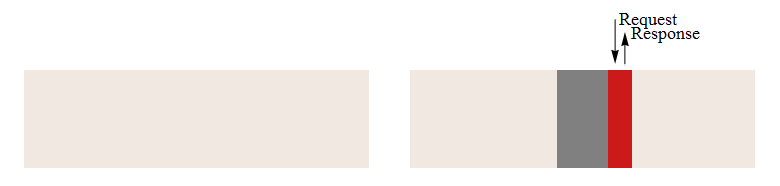
Рисунок 3.1 – Процес читання файлу
(анімація: 18 кадрів, 0.5 секунди інтервал між кадрами, розмір 35,3 кілобайта зроблено в Wolfram Mathematica)
(анімація: 18 кадрів, 0.5 секунди інтервал між кадрами, розмір 35,3 кілобайта зроблено в Wolfram Mathematica)
На рисунку 3.2 зліва показано час, що потрібно, щоб відкрити файл даних. При отриманих результатах, може бути зроблений висновок, що двійкові файли в більшості випадків завантажуються більше ніж у 10 разів швидше текстових. На рисунку 3.2 праворуч показана залежність між часом довільного доступу і розміром файлу. При використанні двійкового формату немає необхідності зберігати всі дані в RAM, отже використання пам'яті значно менше. Такий підхід дозволяє моделювати процеси з великою кількістю частинок на тривалому інтервалі часу.
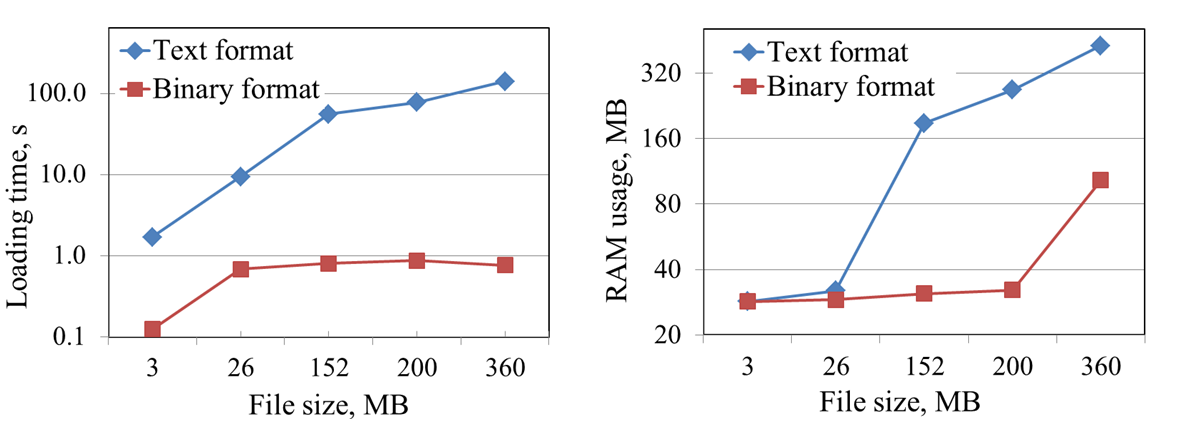
Рисунок 3.2 – Результати тестів продуктивності, частина I
Однак, читання і запис даних виконуються значно повільніше, ніж в текстовому форматі. У разі двійкових даних потрібно приблизно 100мс для того щоб отримати дані, які поміщені в інший блок. Це можна побачити на графіках, зображених на рисунку 3.3 справа. Відношення між розміром довічного і текстового формату показано в рисунку 3.3 зліва. При аналізі проілюстрованих результатів може бути зроблений висновок про те, що двійкові файли мають значно менший обсяг, ніж текстові файли.
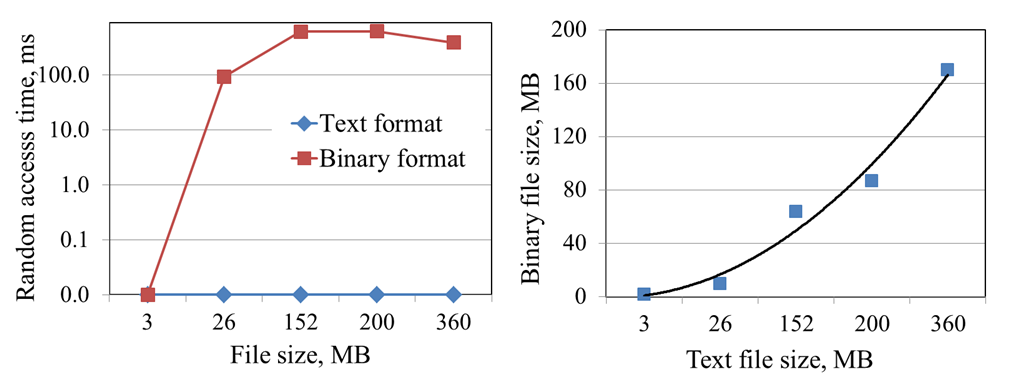
Рисунок 3.3 – Результати тестів продуктивності, частина II
Висновки
Результати, що генеруються системою моделювання методом дискретного елемента, складаються з величезного набору даних. Щоб виконати наступну обробку результатів, має бути розроблений ефективний формат зберігання даних. У даній роботі був запропонований новий підхід, що дозволяє зберігати дані DEM моделювання більш ефективно і зняти ряд обмежень, такі як обсяг оперативної пам'яті і швидкість введення-виведення.
Новий метод зберігання грунтується на використанні двійкового формату файлу, в якому результати DEM розділені по окремих блоками даних. Ці блоки збережені незалежно один від одного і лише кілька з них завантажено в RAM в кожен момент часу. Такий підхід оптимізує використання пам'яті і збільшує ефективність програми. Як інша перевага нового формату може бути підкреслена мінімізація розміру файлів даних.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2014 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Список джерел
- Cundall P.A., Strack O.D.L. A discrete numerical model for granular assemblies. Geotechnique 29, 1979, 47-65.
- Янушкевич В.А., Святный В.А. «Сравнение способов хранения данных в процессе моделирования сыпучих веществ»
- Cundall, P. A., Strack, O. D. L., 1979. Numerical models for granular assemblies. Geotechnique, pp. 47-65.
- Dosta M., Antonyuk S., Heinrich2 S. „Multiscale simulation of fluidized bed granulation process”, Chemical Engineering Technology, 2012, Vol. 35, 1373-1380.
- Antonyuk S., Khanal M., Tomas J., Heinrich S. Impact breakage of spherical granules: experimental study and DEM simulation, Chemical Engineering and Processing 45, 2006, 838-856.
- Poschel, T., Saluena, C., Schwager, T., 2001. Scaling properties of granular materials. Physical Review E 64 (1), (Art. No. 011308 Part 1).
- Schaefer, J., Dippel, S., Wolf, D.E., 1996. Force schemes in simulations of granular materials. Journal De Physique I 6 (1), 5–20.
- Walton, O.R., Braun, R.L. Viscosity, granular-temperature, and stress calculations for shearing assemblies of inelastic, frictional disks. Journal of Rheology, 30, 1986, 949- 980.
- Poeschel T., Schwager T. Computational granular dynamics. Models and algorithms. Springer, 2005.
- Ianushkevych V., Dosta M. (M.Sc.), Antonyuk S. (Dr.-Ing.), Heinrich2 S. (Prof.), Svyatnyy V.A. (Prof.) "Advanced data storage of DEM simulations results"