
Abstract
Table of contents
- 1. Topicality of the research
- 2. Goals and tasks of the study
- 3. Current studies and former works overview
- 4. Main concepts
- 4.1 Existing multicore computers analysis
- 4.2 Means of parallel computing
- 5. Cluster systems analysing methods. Model of a homogeneous computing cluster
- 5.1 Performance evaluation
- 6. Planned practical results
- References
1. Topicality of the research
With the development of information technologies the number of computing system dependent tasks is constantly growing. The complexity of these tasks grows concurrently with the number and so do requirements of the computing resources. Personal computers have long ago lost the ability to meet those requirements, and that's why computing clusters are used for high-performance computations. Sweeping advance of clustering systems creates possibilities for a new use of high-performance computations, e.g. in business, economics, as opposed to traditional application to science (genetics, astronomy, weather prediction). And that is why the efficiency analysis of multiprocessor computing systems and the research of new ways to increase their performance are now particularly important in parallel computing studies.
2. Goals and tasks of the study
The goal of this research is to develop an efficient parallel algorithm of building an analytic model of the cluster system.
Therefore, the main tasks are:
- Overview and analyse current computing systems.
- Develop a Markov model of cluster system operation
- Compute basic characteristics of a cluster system, its structure and task considered.
- Evaluate and analyse performance of a computing system
3. Current studies and former works overview
There is a continuous work on the research and development of computer systems: algorithms are developed to improve computing systems performance, the problems of load balancing in the network planning, bottleneck identifying are solved. The main researchers on campus of the Donetsk National Technical University are
- Ph.D., Professor Lev Feldman
- Ph.D., Docent Tatiana Mihailova
Huge advance was achieved due to great work of former graduates:
- Tetyana Dyachenko (Scientific adviser: associate professor Natalia Datsun)
Research of the parallel algorithm for Markov models of computer systems
- Olga Kucherenosova (Scientific adviser: Bashkov E.O. Adviser: Mihajlova T.V.)
Efficiency research of parallel computing system
- Andrii Yuskov (Scientific adviser: Professor Lev Feldman)
Efficiency of cluster systems functioning
This research is based on preceding work done by these graduates. The novelty of this current work is based upon a fact that prior models were made with a limitation of only one class of task in a system. It is sufficient to continue research and develop a Markov model of a cluster that processes different kinds of tasks. The research is conducted in partnership with a fellow student Ilya Bibikov (Scientific adviser: Ph.D., Professor Lev Feldman. Masters research theme: Performance evaluation of parallel computing systems). The difference in construction lays in choosing modelling limitations. It was decided to operate only with a constant number of tasks during a model simulation.
4 Main concepts
Computing System:
In the narrow sense Computing System is a set of technical means, which includes at least two processors, linked by a common system-wide management and use of resources (memory, peripherals, software, etc.). In a wider sense – an interconnected set of computer hardware and software designed to process information [1].
Cluster – a group of interconnected computer systems (nodes) that work together to form a single computing resource, creating an illusion of having a single computer. One of the standard network technologies is used to allow communication between nodes (Fast/Gigabit Ethernet, Myrinet) based on bus architecture, or a switch. Examples of cluster computing systems: NT-cluster in the NCSA, Beowulf-clusters.
A single-processor computer or a SMP type computing system can act as a cluster node (Symmetric multiprocessing is represented logically as a single machine). As a rule, it is not a specialized device adapted for use in a computer system as in MPP (massive parallel processing), but a commercially available computers and systems. Another feature of the cluster architecture is that a single system combines units of different types, from personal computers to powerful systems. Cluster systems with identical nodes are called homogeneous (uniform) clusters and with heterogeneous nodes – heterogeneous (non-uniform) clusters [2]. Typical cluster is depicted on Fig. 1.

Figure 1 – Cluster system
Cluster consists of:
- Controlling Server
- Computer Nodes
- LAN – Local Area Network
- SAN – Storage Area Network
4.1 Existing multicore computers analysis
Today in the world there are many classes and types of computers, all of them can be classified by the number of instruction streams and the number of data streams that the system simultaneously processes (Flynn's taxonomy):
- SISD, Single Instruction stream over a Single Data stream.
- SIMD, Single Instruction, Multiple Data.
- MISD, Multiple Instruction Single Data.
- MIMD, Multiple Instruction Multiple Data.
The most common and effective systems are MIMD-computers. The computer of this type consists of multiple processors that operate asynchronously and independently. At any time, different processors can execute commands using different parts of the same data [3].
4.2 Means of parallel computing
There are several different approaches to parallel computing systems programming:
- Using common programming languages with communication libraries for interprocessor communication (PVM, MPI, HPVM, MPL, OpenMP, ShMem)
- Using specialized parallel programming languages and extensions (parallel implementations of Fortran, C/C++, ADA, Modula-3)
- Using ways of automatic and semi-automatic parallelization of sequential programms(BERT 77, FORGE, KAP, PIPS, VAST)
- Using basic languages with parallel procedures from specialized libraries (ATLAS, DOUG, GALOPPS, NAMD, ScaLAPACK).
Many tools that simplify the development of parallel programs are available for developers [4].
According to the experience of users of high-performance cluster systems, most efficient programs are written specifically with the need of interprocessor communication. And despite the fact that the programs that use shared memory interface or tools for automatic parallelization are much more convenient, the most popular today are MPI and PVM libraries.
Standard communication library MPI (MPICH2, Open MPI, Cray MPI, etc.) are the primary means for creating parallel programs for distributed computing systems (CS). The basis of these libraries constitute differentiated communication functions (Point-to-point communications) and collective operations (Collective communications) of information exchange between the branches of parallel programs [5].
5.Cluster systems analysing methods. Model of a homogeneous computing cluster
Analytical and simulation models and methods of experimental research are used for quality evaluation and optimization of parallel computing systems.
One method of assessing the quality of a computing system models is queuing theory, that makes it possible to define quality indicators such as throughput, utilization, average response time, and others.
The main task is to analyse the queues. Markov models are being used for that [6].
The basic simplified model of discrete homogeneous cluster with shared disk usage is shown on Fig. 2. The model was constructed using the technique [7]. System has N uniform application servers, D disks and a controlling server.
Tasks(their number is constant and equals M) come for service on the servers and form a a FIFO (first in – first out
) type queue, and are later distributed among application servers.

Figure 2 – Structural scheme of a cluster Markov model
(animation: 9 frames, 10 repeats, 1 sec delay, size – 493x323, 79.1 kB)
Task processing characteristics are following:
- p10 – end of processing a task on a controlling server probability
- p11 – inquiry probability to a server (1..N)
- p21 – inquiry probability to a D disks
- p10 – end of processing a task on a app server probability
- p20 – end of disk utilization probability, server(1..N) inquiry
5.1 Performance evaluation
Algorithm used in a parallel implementation of Markov models [8] consists of two parts: construction of transitive probabilities matrix and stationary probabilities calculation.
For a stationary probabilities vector construction 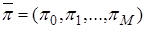 solving a system of the linear algebraic equations is required,
solving a system of the linear algebraic equations is required, 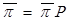
Construction of transitive probabilities matrix. Number of states of the system equals the number of placements of j tasks on N nodes: 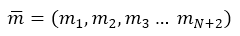 , with mi – as a number of tasks at node i.
, with mi – as a number of tasks at node i.
Number of states for a defined number of tasks is calculated as: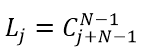 , and the total number of states is:
, and the total number of states is:
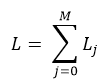
Dimension of a matrix depends on the amount of tasks in the simulated system and varies from several thousands to several millions
Calculation of a matrix element doesn't depend on neighbouring elements. Therefore, as it is possible to use parallel data processing as described in [9].
Stationary probabilities allow us to calculate timing and device utilization characteristics using methods [10]:
6 Planned practical results
At the end of the research following results are expected:
- Discrete Markov Model of a uniform computing cluster.
- Basic characteristics of a computing system.
- New parallel algorithm for the implementation of a discrete Markov model of a homogeneous cluster.
- Basic characteristics of parallelization.
Important note: Master's work has not been completed when this abstract was written. Conclusion of the master's work: December, 2014. Full text and materials on the topic can be obtained from the author or her supervisor after that date.
References
- Чекменев С. Е. Архитектура вычислительных систем. [Electronic source].– Access Mode:http://stankin.ru/..
- Кластер // Словарь терминов в коллекции "Вычислительные системы" [Electronic source]. – Access Mode:http://www.nsc.ru/win/elbib/data/show_page.dhtml?77+858
- Чистяков А.В., Ислямова И.С. Метод и технологии параллельного программирования при решении прикладных задач / Инженерия программного обеспечения 2010 Том 3.
- Эффективные кластерные решения. [Electronic source] – Access Mode:http://www.ixbt.com/cpu/clustering.shtml
- Курносов М.Г. MPIPerf: пакет оценки эффективности коммуникационных функций стандарта MPI // Труды международной научной конференции "Параллельные вычислительные технологии (ПаВТ-2012)". – Новосибирск, 2012. – С. 212-223.
- Клейнрок Л. Вычислительные системы с очередями. –М.: Мир, 1979.-600с.
- Фельдман Л.П., Малинская Э.Б. Аналитическое моделирование вычислительных систем с приоритетным обслуживанием программ. //Электронное моделирование. – К., 1985. – №6.– с. 78-82.
- Михайлова Т.В. Параллельный алгоритм построения дискретной модели Маркова // Искусственный интеллект. Интеллектуаьные и многопроцесорные системы. Материалы Международной научно-технической конференции, 25-30 сентября 2006г., Таганрог-Донецк-Минск, 2006.
- Мищук Ю.К., Фельдман Л.П. Моделирование параллельной реализации марковских моделей в многопроцессорных вычислительных системах // Матеріали I всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених – 19-21 травня 2010р., Донецьк, ДонНТУ. – 2010. – с. 238-240Матеріали I всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених – 19-21 травня 2010р., Донецьк, ДонНТУ. – 2010. – с. 238-240 600с.
- Фельдман Л.П., Михайлова Т.В. Оценка эффективности кластерных систем с использованием моделей Маркова. //Известия ТРТУ. Тематический выпуск: Материалы Всероссийской научно-технической конференции с международным участием
Компьютерные технологии в инженерной и управленческой деятельности
. – Таганрог: ТРТУ, 2002. – №2 (25). – С. 50-53.