



Реферат по теме магистерской работы
Содержание
2.1 Выбор метода для компрессии медицинских изображений
2.2 Выбор метода для фильтрации изображения
5. ОБЗОР ИССЛЕДОВАНИЙ И РАЗРАБОТОК
5.1 Обзор международных источников
5.2 Обзор национальных источников
5.3 Обзор локальных источников
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
ВВЕДЕНИЕ
Многие столетия человечество стремится создать приспособления, которые смогли бы упростить или вовсе решить поставленную задачу за человека. Одним из таких приспособлений бесспорно является компьютер, основные принципы работы которого сформулированы в далеком 1945 году знаменитым математиком Джоном фон Нейманом. Следует отметить, что эти же основополагающие принципы работы вычислительной машины актуальны и по сей день.
Компьютерные технологии в современном мире развиваются в бешеном темпе, создаются новые технологии, совершенствуются существующие, а компьютер все больше проникает во все сферы деятельности человека. Не исключением является и медицинская отрасль: компьютеры помогают выполнять операции, для которых микроскопическая точность – не просто выражение, восстанавливают, казалось бы, безвозвратно испорченные снимки органов и тканей человека, а благодаря развитию систем поддержки принятия решений (СППР) и вовсе могут помогать врачу поставить диагноз и назначать лечение.
1. АКТУАЛЬНОСТЬ ТЕМЫ
Одним из важнейших направлений использования компьютерных технологий для современной медицины является обработка изображений. Традиционно эта область делится на 3 составляющие: улучшение качества изображения, выделение границ объекта, и определение объема объекта по серии изображений.
Аспект качества изображения – краеугольный камень современной медицины. Нередко реальные изображения искажаются при сжатии, зашумляются, или же на интересующую врача область изображения отбрасываются тени других органов, что в свою очередь усложняет постановку правильного диагноза. Поэтому актуальной является задача очистки изображения от шумов и теней.
2. ПОСТАНОВКА ЗАДАЧИ
2.1 Выбор метода для компрессии медицинских изображений
Ведущую роль в медико-диагностической информации занимают медицинские изображения, которые в свою очередь характеризуются огромными объемами информации. Если принять во внимание ограниченность пространства для хранения данных и пропускную способность каналов связи – важность компактного представления информации выходит на первый план.
Основным и наиболее логичным выходом из ситуации является применение к исходному изображению компрессионных алгоритмов. Для правильного выбора алгоритма следует учитывать эффективность и быстродействие для каждого класса изображений (цветные, градации серого и черно-белые).
Общепринятым для медицинских изображений является то, что для сжатия данных применяются алгоритмы сжатия без потери данных, которые в свою очередь обеспечивают единственный и однозначный вариант восстановления данных. Но к сожалению коэффициент сжатия таких алгоритмов как правило не велик, порядка 3/8. Как следствие можно сделать вывод, что для достижения более хороших результатов необходимо использовать алгоритмы основанные на методах сжатия с потерями данных, что позволит на порядок увеличить коэффициент сжатия. Но также не стоит забывать, что выбранный алгоритм должен обеспечивать как сохранность диагностической информации, так и обеспечивать надежность в плане восстановления данных.
В качестве алгоритма сжатия с потерями данных выбран алгоритм вейвлет преобразований (WAVELET), который отлично подходит для работы с изображениями в градациях серого, а именно к такому виду и планируется приведение исходного изображения [1].
2.2 Выбор метода для фильтрации изображения
Получение высококачественного цифрового изображения, которое характеризуется высоким уровнем детализации и контрастности, хорошим уровнем яркости является необходимым условием для современной медицинской диагностики. Алгоритмы выполняющие подобные преобразования называются алгоритмами повышения качества исходного изображения.
Подавляющее большинство существующих методов улучшения качества основаны на эмпирическом или эвристическом подходе. Практически все из них не могут работать в полностью автономном режиме, требуя внесения поправок и корректировок некоторых параметров со стороны пользователя.
Для обеспечения полноценного автономного режима улучшения качества изображения решено использовать генетические алгоритмы (ГА) [2].
2.3 Предстоящий план работ
Практическую реализацию поставленной задачи можно представить в виде следующей схемы (рис.1):
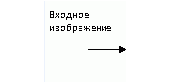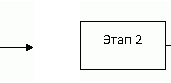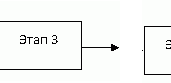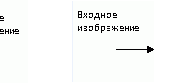
Рисунок 1 – План практической реализации проекта (анимация: количество кадров – 5 шт., размер – 16 килобайт)
Этап 1 – входное изображение преобразуется в градации серого.
Этап 2 – полученное на предыдущем этапе изображение компрессируется в соответствии с алгоритмом вейвлет преобразований.
Этап 3 – полученное на предыдущем этапе изображение фильтруется. Параметры фильтрации вычисляются с помощью ГА.
Этап 4 – отфильтрованное изображение восстанавливается в соответствии с алгоритмом вейвлет преобразований и при необходимости обратно преобразуется в цветное изображение. На выходе из этого этапа получим результирующее изображение.
3. ВЕЙВЛЕТ ПРЕОБРАЗОВАНИЯ
Упрощенный вариант вейвлет преобразования можно представить следующим образом (рис. 2):

Рисунок 2 – Упрощенная схема вейвлет преобразования
На первом этапе входное изображение преобразуется в пространство типа цветность/яркость. Для перевода в пространство YUV необходимо воспользоваться следующими формулами:
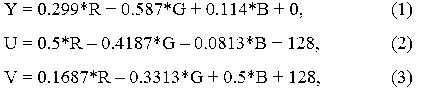
где Y – яркостная составляющая; U и V – компоненты, отвечающие за цвет (соответственно хроматический красный и хроматический синий); R, G и B – компоненты цвета, представленные в соответствии с RGB-моделью, где R – компонента, отвечающая за красный цвет; G – за зеленый; B – за синий.
Для обратного преобразования в модель RGB необходимо вектор, состоящий из значений Y, U, V перемножить на обратную матрицу из коэффициентов при R, G, B соответственно и впоследствии вычесть из получившегося вектора столбец свободных коэффициентов.
На втором этапе изображение обрабатывается двумя фильтрами: высокочастотным (ВЧ) по строкам и низкочастотным (НЧ) по столбцам с последующим прореживанием.
Фильтры представляют собой небольшие «окна». Значения яркости и цветности, попадающих в «окно» пикселей перемножаются с заданным набором коэффициентов самого окна и затем суммируются, а «окно» сдвигается для расчета следующего значения. Отсчеты НЧ и ВЧ составляющих определяются в соответствии с выражениями (4) и (5).
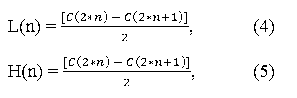
где n = 0, 1 … (N/2 – 1); C(2*n), C(2*n + 1) – отсчеты входящего цифрового сигнала; L(n) – низкочастотные коэффициенты преобразования фильтром; H(n) – высокочастотные коэффициенты преобразования фильтром.
В результате фильтрации вместо одного изображения размером m*n, будет получено 4 изображения размером (m/2)*(n/2). Результатом низкочастотной фильтрации по горизонтали или вертикали как правило является самое информативное изображение, которое подвергается дальнейшей обработке. Результаты высокочастотной фильтрации в подавляющем большинстве случаев отбрасываются.
Полученное после обработки НЧ и ВЧ фильтрами изображение квантуется и после кодирования попадает в выходной поток, в результате на выходе получаем массив определенных числовых коэффициентов.
На следующем этапе массив полученных коэффициентов квантуется и значения близкие к нулю отбрасываются. Новый массив кодируется в соответствии с алгоритмом в результате чего на выходе получается сжатое изображение.
4. ГЕНЕТИЧЕСКИЙ АЛГОРИТМ
В настоящее время быстро развивается новое направление в теории и практике искусственного интеллекта – эволюционные вычисления (ЭВ) [3]. Этот термин обычно используется для общего описания алгоритмов поиска, оптимизации или обучения основанных на некоторых формализованных принципах естественного эволюционного отбора. Особенности идей эволюции и самоорганизации заключаются в том, что они находят подтверждение не только для биологических систем, развивающихся много миллиардов лет. Эти идеи в настоящее время с успехом используются при разработке многих технических и, в особенности, программных систем.
Генетический алгоритм(ГА) – это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путем случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, аналогичных естественному отбору в природе [2].
Генетические алгоритмы в том виде, который они представляют собой сейчас, были основаны в Мичиганском Университете (University of Michigan) исследователем Джоном Холландом [4] и первоначально были разработаны для задачи оптимизации в качестве достаточно эффективного механизма комбинаторного перебора вариантов решения. В отличие от многих других работ, целью Дж. Холланда было не только решение конкретных задач, но исследование явления адаптации в биологических системах и применение его в вычислительных системах. При этом потенциальное решение – особь представляется хромосомой – двоичным кодом. Популяция содержит множество особей. В процессе эволюции используются четыре основных генетических оператора: репродукция, отбор, кроссинговер и мутация.
Принцип работы ГА заключается в следующем: во-первых – каждая особь является решением конкретно поставленной проблемы; во-вторых – множество особей составляют собой популяцию, то есть область потенциально возможных вариантов решения поставленной задачи; в-третьих – поиск оптимального решения поставленной задачи выполняется в процессе эволюции популяции с помощью вышеупомянутых операторов репродукции, отбора, кроссинговера и мутации.
Как и процесс биологической эволюции генетические алгоритмы основаны на 3х основополагающих принципах:
1) Выживает сильнейший [5]. Принцип сформулирован Чарльзом Дарвином в 1859 году в книге «Происхождение видов путем естественного отбора». Суть принципа заключается в том, что по словам Ч. Дарвина особи, более приспособленные для решения своей задачи в определенной среде выживают и приносят здоровое потомство, слабые же наоборот вымирают. Этот принцип описывает два первых генетических оператора: репродукцию и отбор.
2) Хромосома потомка состоит из частей хромосом родителей. Принцип сформулирован Грегором Менделем в 1865 году. Реализацией этого принципа является оператор кроссинговера.
3) В процессе эволюции у особей появляются гены, отсутствующие у родителей (мутация). Принцип сформулирован Гюго де Фризом в 1890 году в книге «Мутационная теория». Термин мутация использовался им для описания резких изменений свойств потомков или же приобретение новых свойств отсутствующих у родителей, тем самым повышая изменчивость популяции.
Процесс выполнения ГА можно разбить на 10 этапов, которые для большей наглядности проиллюстрированы на блок-схеме (рис. 3).
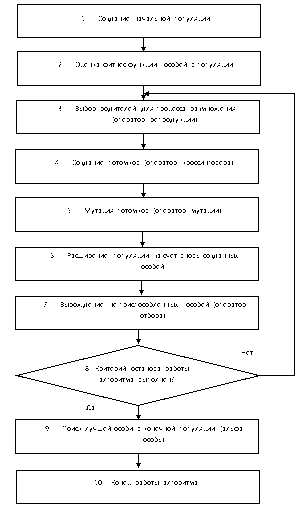
Рисунок 3 – Алгоритм работы ГА
5. ОБЗОР ИССЛЕДОВАНИЙ И РАЗРАБОТОК
5.1 Обзор международных источников
Примерами работ наших заграничных коллег в похожем направлении являются:
1) Статья Судипто Гьюхо и Боулоса Харба на тему «Алгоритмы аппроксимации для вейвлет преобразования кодированого потока данных» [6];
2) Статья Чао Гонг-Ту и Кси Донг-Мея на тему «Анализ алгоритма вейвлет преобразований и его реализация на языке C» [7];
3) Статья Дж. Бейлкина, Р. Койфмана и В. Рокхлина на тему «Быстрые вейвлет преобразования и численные методы» [8].
5.2 Обзор национальных источников
Примерами работ наших соотечественников являются:
1) Статья А.М. Губского на тему «Комбинация вейвлет-анализа и генетического алгоритма для минимизации ошибок глобальной навигационной системы». Предложен многоуровневый алгоритм оценки погрешностей разнородных источников навигационной системы на основе вейвлет-преобразования с интеллектуальной настройкой вейвлета с помощью генетического алгоритма и оценкой погрешности отдельного источники путем оптимизации параметров многоуровневого вейвлет-преобразования [9];
2) Статья Сороки А.М., Ковалец П.Е., Хейдорова И.Э. на тему «Метод классификации речевых сигналов с использованием адаптивного признакового описания на основе вейвлет-преобразования и генетического алгоритма». В статье представлен метод построения признакового описания на основе адаптивной базовой вейвлет-функции, использование которого позволяет повысить различительную способность признакового описания. Предложен многоэтапный метод классификации фонем русского языка с использованием полученных адаптивных вейвлет-функций, учитывающий способ образования фонем и позволяющий повысить точность классификации фонем [10];
3) Статья А.В. Ниценко и Т.С. Хашана на тему «Применение комплексного непрерывного вейвлет-преобразования Морле в обработке аудиосигналов». В статье предложен модифицированный метод фазового вокодера на основе комплексного непрерывного преобразования Морле. Комбинация указанного метода, линейной интерполяции и КИХ-фильтра позволила разработать алгоритм изменения темпа сигнала без изменения его тона [11].
5.3 Обзор локальных источников
Студенты и сотрудники ДонНТУ проводили следующие исследования:
1) Статья Ю.А. Скобцова, В.Ю. Скобцова, К.М. Нассер Ияда – Проверяющие тесты crosstalk неисправностей на основе эволюционных методов. Рассматривается проблема построения проверяющих тестов для "перекрестных неисправностей" типа Crosstalk, характерных для глубокого субмикронного проектирования элементной базы современных компьютерных систем. При решении поставленной задачи используется многозначное логическое моделирование и генетический алгоритм генерации проверяющих тестов для этих неисправностей [12];
2) Учебное пособие – Скобцов Ю.А. Основы эволюционных вычислений [4].
ЗАКЛЮЧЕНИЕ
Различные методы фильтрации изображений имеют в своей основе попиксельные операции, то есть последовательное наложение различных фильтрующих масок на каждую точку изображения.
Анализ существующих методов компрессии медико-диагностических изображений с последующей фильтрацией показал, что целесообразно усовершенствовать и оптимизировать уже существующие алгоритмы для решения конкретной заданной задачи.
Основным заданием магистерской работы будем считать создание приложения для компрессии, улучшения качества изображения на основе ГА, и декомпрессии исходного медико-диагностического изображения. Для корректного использования разрабатываемого приложения необходимо разработать проектную документацию.
Возможно дополнение магистерской работы дополнительными исследованиями в различных, непосредственно связанных с исследуемой темой, областях.
На момент написания данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2015г – январь 2016г. Полный текст работы и материалы по теме могут быть получены непосредственно у автора или его научного руководителя после указанной даты.
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
1. Вейвлет преобразования // Интернет ресурс – режим доступа: https://ru.wikipedia.org/wiki/Вейвлет-преобразование.
2. Генетический алгоритм // Интернет ресурс – режим доступа: https://ru.wikipedia.org/wiki/Генетический_алгоритм.
3. Эволюционные вычисления // Интернет ресурс – режим доступа: https://ru.wikipedia.org/wiki/Эволюционные_алгоритмы.
4. Скобцов Ю.А. Основы эволюционных вычислений // Учебное пособие. – Донецк:ДонНТУ – 2008 – 326с.
5. Ч.Дарвин. Происхождение видов путем естественного обора или сохранение благоприятных рас в борьбе за жизнь // Интернет ресурс – режим доступа: http://charles-darwin.narod.ru/origin-content.html.
6. Sudipto Guha, Boulos Harb. Approximation Algorithms for Wavelet Transform Coding of Data Streams // Интернет ресурс – режим доступа: http://arxiv.org/pdf/cs/0604097.pdf.
7. Zhao Hong-tu, Xi Dong-mei. Analysis on Algorithm of Wavelet Transform And Its Realization in C Language // Интернет ресурс – режим доступа: http://www.academypublisher.com/proc/isecs10w/papers/isecs10wp336.pdf.
8. G. Beylkin, R. Coifman, V. Rokhlin. Fast Wavelet Transforms and Numerical Algorithms I // Интернет ресурс – режим доступа: https://amath.colorado.edu/faculty/beylkin/papers/BE-CO-RO-1991.pdf.
9. А.М. Губський. Комбінація вейвлет-аналізу та генетичного алгоритму для мінімізації похибок глобальної навігаційної системи // Науковий вісник НЛТУ України. – 2011. – С. 355-362.
10. Сорока А.М., Ковалец П.Е., Хейдоров И.Э. Метод классификации речевых сигналов с использованием адаптивного признакового описания на основе вейвлет-преобразования и генетического алгоритма // Речевые технологии. – № 3-4. – 2013. – С. 84-95.
11. А.В. Ниценко , Т.С. Хашан. Применение комплексного непрерывного вейвлет-преобразования Морле в обработке аудиосигналов // Интернет ресурс – режим доступа: http://dspace.nbuv.gov.ua/bitstream/handle/123456789/7671/095-Nitsenko.pdf?sequence=1.
12. Ю.А. Скобцов, В.Ю. Скобцов, К.М. Нассер Ияд. Проверяющие тесты crosstalk неисправностей на основе эволюционных методов. // Вестник «Информатика и моделирование» – 2010. – С. 170-176.