



Реферат на тему магістерської роботи
Зміст
2.1 Вибір методу для компресії медичних зображень
2.2 Вибір методу для фільтрації зображення
5. ОГЛЯД ДОСЛІДЖЕНЬ І РОЗРОБОК
ВСТУП
Багато століть людство прагне створити пристосування, які змогли б спростити або зовсім вирішити поставлене завдання за людину. Одним з таких пристосувань безперечно є комп'ютер, основні принципи роботи якого сформульовані в далекому 1945 році знаменитим математиком Джоном фон Нейманом. Слід зазначити, що ці ж основоположні принципи роботи обчислювальної машини актуальні й донині.
Комп'ютерні технології в сучасному світі розвиваються в шаленому темпі, створюються нові технології, удосконалюються існуючі, а комп'ютер все більше проникає в усі сфери діяльності людини. Не виключенням є і медична галузь: комп'ютери допомагають виконувати операції, для яких мікроскопічна точність - не просто вираз, відновлюють, здавалося б, безповоротно зіпсовані знімки органів і тканин людини, а завдяки розвитку систем підтримки прийняття рішень (СППР) і зовсім можуть допомагати лікареві поставити діагноз і призначати лікування.
1. АКТУАЛЬНІСТЬ ТЕМИ
Одним з найважливіших напрямків використання комп'ютерних технологій для сучасної медицини є обробка зображень. Традиційно ця область ділиться на 3 складові: поліпшення якості зображення, виділення меж об'єкта, і визначення обсягу об'єкта по серії зображень.
Аспект якості зображення - наріжний камінь сучасної медицини. Нерідко реальні зображення спотворюються при стисненні, зашумлять, або ж на цікаву лікаря область зображення відкидаються тіні інших органів, що в свою чергу ускладнює постановку правильного діагнозу. Тому актуальною є задача очищення зображення від шумів і тіней.
2. ПОСТАНОВКА ЗАДАЧІ
2.1 Вибір методу для компресії медичних зображень
Провідну роль у медико-діагностичній інформації займають медичні зображення, які в свою чергу характеризуються величезними обсягами інформації. Якщо взяти до уваги обмеженість простору для зберігання даних і пропускну спроможність каналів зв'язку - важливість компактного представлення інформації виходить на перший план.
Основним і найбільш логічним виходом із ситуації є застосування до вихідного зображення компресійних алгоритмів. Для правильного вибору алгоритму слід враховувати ефективність і швидкодію для кожного класу зображень (кольорові, градації сірого та чорно-білі).
Загальноприйнятим для медичних зображень є те, що для стиснення даних застосовуються алгоритми стиснення без втрати даних, які в свою чергу забезпечують єдиний і однозначний варіант відновлення даних. Але на жаль коефіцієнт стиснення таких алгоритмів як правило не великий, порядку 3/8. Як наслідок можна зробити висновок, що для досягнення більш хороших результатів необхідно використовувати алгоритми засновані на методах стиснення з втратами даних, що дозволить на порядок збільшити коефіцієнт стиснення. Але також не варто забувати, що обраний алгоритм повинен забезпечувати як збереження діагностичної інформації, так і забезпечувати надійність в плані відновлення даних.
В якості алгоритму стиснення з втратами даних обраний алгоритм вейвлет перетворень (WAVELET), який відмінно підходить для роботи із зображеннями в градаціях сірого, а саме до такого виду і планується приведення вихідного зображення [1].
2.2 Вибір методу для фільтрації зображення
Отримання високоякісного цифрового зображення, яке характеризується високим рівнем деталізації і контрастності, хорошим рівнем яскравості є необхідною умовою для сучасної медичної діагностики. Алгоритми виконують подібні перетворення називаються алгоритмами підвищення якості вихідного зображення.
Переважна більшість існуючих методів покращення якості засновані на емпіричному або евристичному підході. Практично всі з них не можуть працювати в повністю автономному режимі, вимагаючи внесення поправок і коригувань деяких параметрів з боку користувача.
Для забезпечення повноцінного автономного режиму поліпшення якості зображення вирішено використовувати генетичні алгоритми (ГА) [2].
2.3 Майбутній план робіт
Практичну реалізацію поставленої задачі можна представити у вигляді такої схеми:

Малюнок 1 – План практичної реалізації проекту
Етап 1 – вхідне зображення перетвориться в градації сірого.
Етап 2 – отримане на попередньому етапі зображення компресує відповідно до алгоритму вейвлет перетворень.
Етап 3 – отримане на попередньому етапі зображення фільтрується. Параметри фільтрації обчислюються за допомогою ГА.
Етап 4 – відфільтроване зображення відновлюється відповідно до алгоритму вейвлет перетворень і при необхідності назад перетвориться в кольорове зображення. На виході з цього етапу отримаємо результуюче зображення.
3. ВЕЙВЛЕТ ПЕРЕТВОРЕННЯ
Спрощений варіант вейвлет перетворення можна представити таким чином (мал. 2):

Малюнок 2 – Спрощена схема вейвлет перетворення
На першому етапі вхідне зображення перетворюється в простір типу кольоровість / яскравість. Для переведення в простір YUV необхідно скористатися наступними формулами:
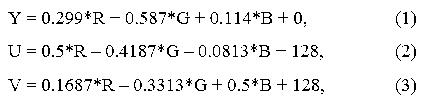
де Y - яркостная складова; U і V - компоненти, що відповідають за колір (відповідно хроматичний червоний і хроматичний синій); R, G і B - компоненти кольору, подані відповідно до RGB-моделлю, де R - компонента, що відповідає за червоний колір; G - за зелений; B - за синій.
Для зворотного перетворення в модель RGB необхідно вектор, що складається з значень Y, U, V перемножити на зворотну матрицю з коефіцієнтів при R, G, B відповідно і згодом відняти з отриманого вектора стовпець вільних коефіцієнтів.
На другому етапі зображення обробляється двома фільтрами: високочастотним (ВЧ) по рядках і низькочастотних (НЧ) за стовпцями з подальшим проріджуванням.
Фільтри являють собою невеликі «вікна». Значення яскравості і кольоровості, що потрапляють в «вікно» пікселів перемножуються із заданим набором коефіцієнтів самого вікна і потім сумуються, а «вікно» зсувається для розрахунку наступного значення. Відліки НЧ і ВЧ складових визначаються відповідно до виразами (4) і (5).
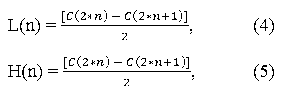
де n = 0, 1 ... (N / 2 - 1); C (2 * n), C (2 * n + 1) - відліки вхідного цифрового сигналу; L (n) - низькочастотні коефіцієнти перетворення фільтром; H (n) - високочастотні коефіцієнти перетворення фільтром.
У результаті фільтрації замість одного зображення розміром m * n, буде отримано 4 зображення розміром (m / 2) * (n / 2). Результатом низькочастотної фільтрації по горизонталі або вертикалі як правило є саме інформативне зображення, яке піддається подальшій обробці. Результати високочастотної фільтрації в переважній більшості випадків відкидаються.
Отримане після обробки НЧ і ВЧ фільтрами зображення квантується і після кодування потрапляє у вихідний потік, в результаті на виході отримуємо масив певних числових коефіцієнтів.
На наступному етапі масив отриманих коефіцієнтів квантується і значення близькі до нуля відкидаються. Новий масив кодується відповідно до алгоритму в результаті чого на виході виходить стислий зображення.
4. ГЕНЕТИЧНИЙ АЛГОРИТМ
В даний час швидко розвивається новий напрямок в теорії і практиці штучного інтелекту - еволюційні обчислення (ЕВ) [3]. Цей термін зазвичай використовується для загального опису алгоритмів пошуку, оптимізації або навчання заснованих на деяких формалізованих принципах природного еволюційного відбору. Особливості ідей еволюції і самоорганізації полягають в тому, що вони знаходять підтвердження не тільки для біологічних систем, що розвиваються багато мільярдів років. Ці ідеї в даний час з успіхом використовуються при розробці багатьох технічних і, особливо, програмних систем.
Генетичний алгоритм (ГА) - це евристичний алгоритм пошуку, використовуваний для вирішення завдань оптимізації та моделювання шляхом випадкового підбору, комбінування і варіації шуканих параметрів з використанням механізмів, аналогічних природному відбору в природі [2].
Генетичні алгоритми в тому вигляді, який вони представляють собою зараз, були засновані в Мічиганському Університеті (University of Michigan) дослідником Джоном Холландом [4] і спочатку були розроблені для задачі оптимізації в якості досить ефективного механізму комбінаторного перебору варіантів рішення. На відміну від багатьох інших робіт, метою Дж. Холланда було не тільки вирішення конкретних завдань, але дослідження явища адаптації в біологічних системах і застосування його в обчислювальних системах. При цьому потенційне рішення - особина представляється хромосомою - двійковим кодом. Популяція містить безліч особин. У процесі еволюції використовуються чотири основних генетичних оператора: репродукція, відбір, кросинговер і мутація.
Принцип роботи ГА полягає в наступному: по-перше - кожна особина є рішенням конкретно поставленої проблеми; по-друге - безліч особин складають собою популяцію, тобто область потенційно можливих варіантів вирішення поставленої задачі; по-третє - пошук оптимального вирішення поставленого завдання виконується в процесі еволюції популяції за допомогою вищезазначених операторів репродукції, відбору, кросинговеру і мутації.
Як і процес біологічної еволюції генетичні алгоритми засновані на 3х основоположних принципах:
1) Виживає сильніший [5][5]. Принцип сформульований Чарльзом Дарвіном в 1859 році в книзі «Походження видів шляхом природного відбору». Суть принципу полягає в тому, що за словами Ч. Дарвіна особини, більш пристосовані для вирішення свого завдання в певному середовищі виживають і приносять здорове потомство, слабкі ж навпаки вимирають. Цей принцип описує два перших генетичних оператора: репродукцію і відбір.
2) Хромосома нащадка складається з частин хромосом батьків. Принцип сформульований Грегором Менделем в 1865 році. Реалізацією цього принципу є оператор кросинговеру.
3) У процесі еволюції у особин з'являються гени, відсутні у батьків (мутація). Принцип сформульований Гюго де Фріз у 1890 році в книзі «Мутационная теорія». Термін мутація використовувався ним для опису різких змін властивостей нащадків або ж придбання нових властивостей відсутніх у батьків, тим самим підвищуючи мінливість популяції.
Процес виконання ГА можна розбити на 10 етапів, які для більшої наочності проілюстровані на блок-схемі (мал. 3).
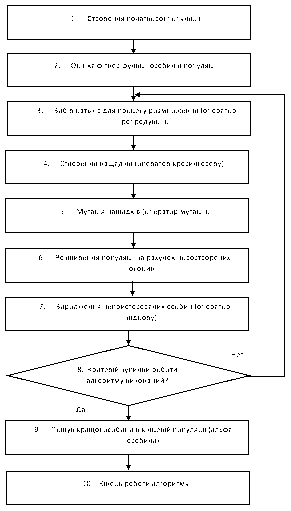
Малюнок 3 – Алгоритм роботи ГА
5. ОГЛЯД ДОСЛІДЖЕНЬ І РОЗРОБОК
5.1 Огляд міжнародних джерел
Прикладами робіт наших закордонних колег у схожому напрямку є:
1) Стаття Судіпто Гьюхо і Боулоса окупантів на тему «Алгоритми апроксимації для вейвлет перетворення кодування потоку даних» [6];
2) Стаття Чао Гонг-Ту і Кси Донг-Мея на тему «Аналіз алгоритму вейвлет перетворень і його реалізація мовою C» [7];
3) Стаття Дж. Бейлкіна, Р. Койфмана і В. Рокхліна на тему «Швидкі вейвлет перетворення і чисельні методи» [8].
5.2 Огляд національних джерел
Прикладами робіт наших співвітчизників є:
1) Стаття А.М. Губського на тему «Комбінація вейвлет-аналізу та генетичного алгоритму для мінімізації помилок глобальної навігаційної системи». Запропоновано багаторівневий алгоритм оцінки похибок різнорідних джерел навігаційної системи на основі вейвлет-перетворення з інтелектуальною налаштуванням вейвлета за допомогою генетичного алгоритму та оцінкою похибки окремого джерела шляхом оптимізації параметрів багаторівневого вейвлет-перетворення [9];
2) Стаття Сороки А.М., Ковалець П.Є., Хейдорова І.Е. на тему «Метод класифікації мовних сигналів з використанням адаптивного признакового опису на основі вейвлет-перетворення і генетичного алгоритму». У статті представлено метод побудови признакового опису на основі адаптивної базової вейвлет-функції, використання якого дозволяє підвищити розрізнювальну здатність признакового опису. Запропоновано багатоетапний метод класифікації фонем російської мови з використанням отриманих адаптивних вейвлет-функцій, що враховує спосіб утворення фонем і дозволяє підвищити точність класифікації фонем [10];
3) Стаття А.В. Ніценко і Т.С. Хашана на тему «Застосування комплексного безперервного вейвлет-перетворення Морле в обробці аудіосигналів». У статті запропоновано модифікований метод фазового вокодера на основі комплексного безперервного перетворення Морлі. Комбінація зазначеного методу, лінійної інтерполяції і КИХ-фільтра дозволила розробити алгоритм зміни темпу сигналу без зміни його тону [11].
5.3 Обзор локальных источников
Студенти та співробітники ДонНТУ проводили такі дослідження:
1) Стаття Ю.А. Скобцова, В.Ю. Скобцова, К.М. Нассер Іяда - Перевіряючі тести crosstalk несправностей на основі еволюційних методів. Розглядається проблема побудови перевіряючих тестів для "перехресних несправностей" типу Crosstalk, характерних для глибокого субмікронного проектування елементної бази сучасних комп'ютерних систем. При вирішенні поставленого завдання використовується багатозначне логічне моделювання і генетичний алгоритм генерації перевіряючих тестів для цих несправностей [12];
2) Навчальний посібник - Скобцов Ю.А. Основи еволюційних обчислень [4].
ВИСНОВКИ
Різні методи фільтрації зображень мають у своїй основі попіксельно операції, тобто послідовне накладення різних фільтруючих масок на кожну точку зображення.
Аналіз існуючих методів компресії медико-діагностичних зображень з подальшою фільтрацією показав, що доцільно удосконалити та оптимізувати вже існуючі алгоритми для вирішення конкретної заданої задачі.
Основним завданням магістерської роботи будемо вважати створення програми для компресії, поліпшення якості зображення на основі ГА, і декомпресії вихідного медико-діагностичного зображення. Для коректного використання розроблюваного докладання необхідно розробити проектну документацію.
Можливе доповнення магістерської роботи додатковими дослідженнями в різних, безпосередньо пов'язаних з досліджуваної темою, областях.
На момент написання даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2015р - січень 2016р. Повний текст роботи та матеріали по темі можуть бути отримані безпосередньо у автора або його наукового керівника після зазначеної дати.
СПИСОК ВИКОРИСТАНИХ ДЖЕРЕЛ
1. Вейвлет перетворення // Інтернет ресурс – режим доступу: https://ru.wikipedia.org/wiki/Вейвлет-преобразование.
2. Генетичний алгоритм// Інтернет ресурс – режим доступу: https://ru.wikipedia.org/wiki/Генетический_алгоритм.
3. Еволюційні обчислення // Інтернет ресурс – режим доступу: https://ru.wikipedia.org/wiki/Эволюционные_алгоритмы.
4. Скобцов Ю.А. Основы эволюционных вычислений // Учебное пособие. – Донецк:ДонНТУ – 2008 – 326с.
5. Ч.Дарвин. Происхождение видов путем естественного обора или сохранение благоприятных рас в борьбе за жизнь // Интернет ресурс – режим доступа: http://charles-darwin.narod.ru/origin-content.html.
6. Sudipto Guha, Boulos Harb. Approximation Algorithms for Wavelet Transform Coding of Data Streams // Интернет ресурс – режим доступа: http://arxiv.org/pdf/cs/0604097.pdf.
7. Zhao Hong-tu, Xi Dong-mei. Analysis on Algorithm of Wavelet Transform And Its Realization in C Language // Интернет ресурс – режим доступа: http://www.academypublisher.com/proc/isecs10w/papers/isecs10wp336.pdf.
8. G. Beylkin, R. Coifman, V. Rokhlin. Fast Wavelet Transforms and Numerical Algorithms I // Интернет ресурс – режим доступа: https://amath.colorado.edu/faculty/beylkin/papers/BE-CO-RO-1991.pdf.
9. А.М. Губський. Комбінація вейвлет-аналізу та генетичного алгоритму для мінімізації похибок глобальної навігаційної системи // Науковий вісник НЛТУ України. – 2011. – С. 355-362.
10. Сорока А.М., Ковалец П.Е., Хейдоров И.Э. Метод классификации речевых сигналов с использованием адаптивного признакового описания на основе вейвлет-преобразования и генетического алгоритма // Речевые технологии. – № 3-4. – 2013. – С. 84-95.
11. А.В. Ниценко , Т.С. Хашан. Применение комплексного непрерывного вейвлет-преобразования Морле в обработке аудиосигналов // Интернет ресурс – режим доступа: http://dspace.nbuv.gov.ua/bitstream/handle/123456789/7671/095-Nitsenko.pdf?sequence=1.
12. Ю.А. Скобцов, В.Ю. Скобцов, К.М. Нассер Ияд. Проверяющие тесты crosstalk неисправностей на основе эволюционных методов. // Вестник «Информатика и моделирование» – 2010. – С. 170-176.