Эволюционирующие нейронные сети для классификации галактик
Авторы статьи: Erick Cantu´-Paz, Chandrika Kamath
Автор перевода: А.И. Мартыненко
Источник: Evolving Neural Networks for the Classification of Galaxies
Аннотация
Планируется, что обзор FIRST (Слабые Изображения Радио- Неба в Двадцать-см) покроет 10,000 квадратных градусов северной и южной галактических шапок. До недавнего времени, астрономы классифицировали радиоизлучения галактик через визуальный осмотр FIRS изображений. Помимо того, что такой подход субъективен, подвержен ошибкам и скушен, он становится невозможным: после завершения, FIRST будет включать в себя почти миллионов галактик. Эта статья описывает применение шести методов эволюционирующих нейронных сетей (ЭВН) с генетическими алгоритмами (ГА) для выявления двойной изогнутости галактик. Целью является показать, что ГА может успешно решать некоторые общие проблемы в применении к ЭВН для классификации проблем, таких как обучение сети, выбор соответствующей сетевой топологии и выбор соответствующих свойств. Результаты показывают, что большинство методов, которые мы пробовали выполняются одинаково хорошо для наших данных, но использование ГА для выбора свойств, дало лучшие результаты.
1. Введение
Обзор FIRST был запущен в 1993 с целью создания радио- эквивалента для обсерватории. Пользуясь Очень Большим Массивом в Национальной Обсерватории Радио-Астрономии, FIRST планирует покрыть более чем 10,000 квадратных градусов северной и южной галактических шапок. В настоящее время, FIRST покрыл около 8,000 квадратных градусов, произведя более чем 32,000 высококачественных изображений. В пороге 1 mjy, есть приблизительно 90 радио испускающих галактик, или радио-источников, в типичном квадратном градусе.
Радио-источники демонстрируют широкий спектр морфологических типов, которые обеспечивают подсказки в класс источника, механизм эмиссии и свойства окружающей среды. Источники с изогнутой двойной морфологией представляют особый интерес, поскольку они указывают на наличие скоплений галактик, ключевую проект в пределах обзора FIRST. Ученые FIRST определили галактики с двойной изогнутостью методом визуального осмотра, которые помимо того, что субъективный, подвержен ошибкам и скушен, становится все более невозможным, так как опрос растет.
Наша цель автоматизировать классификацию галактик, используя методы интеллектуального анализа данных, к примеру такой метод, как нейронные сети. Нейронные сети (НС) были успешно использованы для классификации объектов во многих астрономических приложениях. Однако, успех НС во многом зависит от их архитектуры, алгоритма обучения и выбора свойств, используемых в процессе обучения. К сожалению, определение архитектуры нейронной сети – это процесс проб и ошибок; алгоритмы обучения должны быть тщательно настроены под данные; и актуальность свойств для классификации не может быть известна заранее. Наша цель показать, что генетические алгоритмы (ГА) может успешно решать такие проблемы как: выбор топологии, обучение и выбора свойств, приводя к точным сетям с хорошими способностями обобщения. Эта статья описывает применение шести комбинаций генетических алгоритмов и нейронных сетей для идентификации изогнутый двойных галактик.
Это исследование является одним из немногих, которое сравнивает методы различны эволюционных нейронных сетей на одном и том же домене. В отличие от других исследований, которые ограничиваются двумя или тремя методами, мы сравнили шесть комбинаций ГА и ЭНС с вручную разработанными сетями. Большинство методов, которые мы испытывали выполнялись одинаково хорошо для наших данных, но использование ГА для выбора свойств дало лучшие результаты. Эксперименты также показывают, что большинство из комбинаций ГА и НС произвело значительно более точную классификацию, чем мы смогли получить, проектируя сети ручным способом.
Следующий раздел описывает проблемы обнаружения изогнутый двойных галактик по данным FIRST. Раздел 3 описывает несколько существующих комбинаций ГА и НС. В разделе 4 представлены наши эксперименты и приведены результаты. Статья завершается нашими наблюдениями и планами работ на будущее.
2. Первое обследование данных
Рисунок 1 имеет несколько примеров радиоисточников с обследования FIRST. В то время как некоторые изогнутые двойные галактики относительно просты в форе (примеры (а) и (b)), другие, такие как те, в примерах (e) и (f), могут быть довольно сложными. Обратите внимание на сходство между изогнутыми двойными в примере (а) и не изогнутыми двойными в примере (с).
Данные FIRST доступны на веб-сайте FIRST (sundog.stsci.edu). Есть две формы доступных данных: изображение карт и каталог. Изображения в рисунке 1 – это крупные планы галактик. Каталог (Уайт и др., 1997) получают путем подгонки двумерных Гауссиан для каждого радиоисточника на карту изображения. Каждая запись в каталоге соответствует одной Гауссиане.
Мы решили, что изначально, идентификация радиоисточников и извлечение их особенностей, будет производиться используя только каталог. Астрономы ожидали, что каталог является хорошей аппроксимацией всех, кроме самых сложных радиоисточников, а также некоторые особенности, которые по их мнению, были важны для идентификации двойных изогнутых легко вычислялись из каталога.
Мы идентифицировали особенности для задачи изогнутой двойной через обширные разговоры с астрономами FIRST. Когда они оправдали свои решения идентификации радиоисточника в качестве изогнутой двойной, они придали большое значение пространственным функциям, таким как расстояние и углы. Часто, астрономы характеризовали изогнутую двойную как радиоизлучающее "ядро" с одним или более дополнительных компонентов под разными углами.
В прошлом, мы сосредоточили свою работу на образцах, описанных тремя входами каталога, потому что мы более маркировали примеры этого типа. Наш предыдущий опыт с этим данными предложил, что лучшая точность обычно достигается, используя особенности, которые были извлечены, рассматривая тройные входы каталога (в противоположность двойным или единственным входам). Поэтому, в оставшейся части статьи мы сосредоточиваемся на 20 тройных особенностях, которые мы извлекли. Полный список особенностей описывается где-нибудь в другом месте (Фодор и др., 2000).
К сожалению, наша обучающая последовательность относительно маленькая, содержащая 195 примеров для источников тройных входов каталога. Поскольку изогнутые и не изогнутые двойные должны быть вручную помечены учеными FIRST, собрание воедино адекватно обучающего множества является нетривиальным. Кроме того, ученые, как правило, субъективны в своей маркировке галактик, и астрономы часто расходятся в случаях, которые трудно классифицировать. Так же нет никаких правдивых оснований, которые мы можем использовать, чтобы проверить наши результаты. Эти вопросы подразумевают, что сами по себе обучающие набор не очень точны, и есть предел точности, который мы можем получить.
Среди 195 помеченных примеров источников тройных входов, 28 не являются изогнутыми, а 167 изогнутые двойные галактики. Это несбалансированное распределение в обучающем множестве представляет проблемы при оценке точности NNS, которые обсуждаются в разделе 4.
3. Генетические нейронные сети
Генетические алгоритмы и нейронные сети были вместе использованы несколькими способами, и в этом разделе представлен краткий обзор предыдущей работы. В частности, ГА были использованы для поиска весов в сети и выбора наиболее соответствующих особенностей, обучающихся данных. ГА также используется, чтобы спроектировать структуру сети. Хорошо известно, что для решения нелинейных проблем, сеть должна иметь по крайней мере один скрытый слой между входами и выходами; но определение количества и размера скрытых слоев — это в основном метод проб и ошибок. ГА был использован для поиска этих параметров, а также для шаблона соединений и инструкции для генерации развития сети.
3.1 Обучение сети, используя ГА
Обучение НН оптимизационная задача с целью поиска набора весов, которые минимизирует ошибку. Поисковое пространство высокой размерности, в зависимости от меры погрешности, оно может содержать многочисленные локальные оптимумы. Некоторые учебные алгоритмы сети, такие как обратного распространения (ОР), используют некоторую форму градиента поиска, и может попасть в ловушку локальных оптимумов.
Простая комбинация генетических алгоритмов и нейронных сетей нужна, чтобы использовать ГА для поиска весов, что вынуждает сеть работать как желательно.

Рисунок 1: Пример радиоисточников: (a) - (d) изогнутые двойные, (c) - (d) неизогнутые двойные, (e) - (f) комплексные источники
Архитектура сети фиксирована пользователем до начала эксперимента. В этом методе каждая особь в ГА представляет собой вектор со всеми весами сети. Есть два популярных вариантов:
• Использование весов, найденных ГА без дальнейшего улучшения;
• Использование ГА, чтобы найти перспективный набор весов, из которых градиентный метод способен быстро выйти на оптимальный. Суть в том, что ГА быстро определит перспективные регионы пространства поиска, но они не могут настраивать параметры очень быстро.
Эти подходы являются прямыми и многочисленными исследованиями показывающие хорошие результаты. Однако, поскольку соседние слои в сети, как правило, полностью соединены, общее количество весов O (N2), где N есть число единиц. Более длинные особи, как правило требуют больших групп населения, которые в свою очередь приводят к более высоким вычислительными затратам. Таким образом, ГА может быть эффективен _ для небольших сетей, но этот метод _ плохо масштабируем _ Еще одним недостатком является так называемая проблема перестановок (Radcli FF е, 1990). Проблема в том, что переставляя скрытые узлы сети, представление весов в хромосоме _ меняться, но сеть функционально одинакова. Некоторые перестановки не могут быть пригодны для ГА, потому что кроссовер может легко нарушить благоприятные комбинации весов. Чтобы смягчить эту проблему, Thierens др. (1991) предложил разместить входящие и исходящие веса скрытого слоя рядом друг с другом, данный метод кодирования был использован нами.
3.2 Характеристика выбора
Помимо поиска весов, ГА может быть использован для выбора свойств, которые вводятся в НН. Обучаемые экземпляры могут содержать ненужные или избыточные особенности, но, как правило, неизвестно априори какие особенности являются актуальными. Избежать нерелевантные или избыточные особенности желательно не только потому, что они увеличивают размер сети и время обучения, но также потому, что они могут снизить точность сети.
Применяя ГА для выбора свойств является прямым использованием того, что называется подходом оболочки: хромосома особей содержит один бит для каждого свойства, и значение бита определяет, будет ли использоваться особенность в классификации. Особи оцениваются путем обучения сети (которые имеют заранее определенную структуру) с подмножеством особенностей, указанных хромосоме. Итоговая оценка точности используется для расчета фитнесс функции.
3.3 Проектирование сетей с использованием ГА
Как упоминалось ранее, топология сети имеет решающее значение для ее работы. Если сеть имеет слишком мало узлов и соединений, оно не может быть в состоянии узнать необходимую концепцию. С другой стороны, если сеть имеет слишком много узлов и соединений, она может иметь слишком большую фитнесс функцию обучающихся данных и плохое обобщение. ГА были успешно использованы для разработки топологии НН. Есть два основных подхода для применения ГА в дизайне НН: использовать прямую кодировку указать каждое соединение в сети или развивать косвенный спецификацию в связи.
Ключевой идеей прямого кодирования является то, что нейронная сеть может рассматриваться как ориентированный граф, где каждый узел представляет собой нейрон, а каждое ребро является соединением. Общий способ представления направленных графов - это бинарная матрица смежности: I, -i элемент матрицы является одним, если есть ребро между узлами I и J, и нулю в противном случае. Матрица соединения может быть представлена в ГА просто путем конкатенации ее строк или столбцов (Miller и др., 1989; Бэлью др., 1990). С помощью этого метода, Whitley др. (1990) показал что ГА может найти топологии, которые обучаются быстрее чем типичная полностью связанная с прогнозированием сеть. ГА может быть явно предвзятым в пользу более мелких сетей, которые могут быть обучены быстрее.
Простой способ избежать указания всех соединений это остановиться на определенной топологии и алгоритме обучения, а затем использовать ГА Для нахождения значения параметров, которые дополняют сетевую спецификацию. Например, для полностью связанной с прогнозированием топологией, ГА может искать количество слоев и количество нейронов в слое. Другим примером может быть кодирование параметров конкретного алгоритма обучения, такие как импульс и скорость обучения ВР (Белью др, 1990;. & Маршалл Харрисон, 1991). Конечно, этот метод ограничен первоначальным выбором топологии и алгоритма обучения.
Другой подход заключается в использовании грамматики для кодирования правил, которые регулируют развитие сети. Китано (1990) представил раннюю грамматику - основанный доступ. Он использует матрицу связности для изображения сети, но вместо кодирующей матрицы непосредственно в хромосоме, матрица сгенерирована графом перезаписи грамматики. Хромосомы содержат правила, которые переписывать скалярные элементы в матрицу 2 × 2.
В этой грамматике, существует 16 терминальных символа, которые находятся в двоичной матрице 2 × 2. Есть 16 без терминальных символа и правила имеют вид n → m, где n является одним из скалярных не терминалов, и m 2 × 2 матрица не терминалов. Существует произвольно назначенный символ начала, и число перезаписывающихся шагов, фиксированных пользователем.
Чтобы оценить фитнесс функции, правила расшифровываются, и матрица связности разрабатывается с применением всех правил, которые соответствуют не терминальным символам. Затем матрица связности интерпретируется и сеть строится и обучается с ОР.
Другими примерами грамматики на основе систем развития являются работа Бурса и Купера (1992) с системами Lindenmayer, метод "сотового кодирования" (Gruau, 1992 г.), и система Нола Fi, Эльман, и Паризи (1994), которая имитирует клетки роста, миграции и изменения.
4. Эксперименты
В этом разделе подробно описаны экспериментальные методы и результаты, которые мы получили с шестью комбинаций нейронных сетей и генетических алгоритмов.
Программы были написаны на C ++ и скомпилирован с g ++ версии 2.96. Эксперименты были выполнены на одном процессоре Linux (Red Hat 7.1) станции с двумя 1,5 ГГц процессорами Intel Xeon и 512 Мб памяти. Программы использовали генератор случайных чисел Mersenna Twister.
Все ГА использовали население в 50 человек. Мы использовали простой ГА с двоичным кодированием, попарно отборочного турнира, и многоточечный кроссовер. Количество точек пересечения варьировали в каждом эксперименте по длине хромосомы, L. Во всех случаях вероятность кроссовера 1, а вероятность мутации была установлена 1 / L. Начальная популяция была инициализирована равномерно рандомом.
Эксперименты используются прямого распространения сетей с одним скрытым слоем. Все нейроны соединены с "смещения" блок с постоянной мощностью 1,0. Если специфическая не эд иначе, выходные блоки связаны все скрытые единиц, которые в свою очередь связаны со всеми входами. В прямой связи операции, единицы расчета их сетевой активации
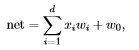
где d это количество входов в нейроне, xi -вход и wi - соответствующий вес, w0 - вес, соответствующий "смещению" блока. Каждый блок выдает выходное соответствие с f(net) = tanh (β * net), где β является специфическим коэффициентом пользователя. Простая обратного распространения была использована в некоторых экспериментах. Веса от скрытых до выходных слоев были обновлены с использованием Δwkj = ηδkyj = η (TK - Z) 0 (netk) YJ, где η обозначает скорость обучения, K индексы выходных блоков, tk желаемый выход, zk реальный выход, f0 является производной от F, и YJ является выходом J-й скрытого блока. Веса от i-го входа до скрытого слоя были обновлены с использованием
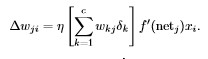
Во всех экспериментах, каждая функция данных была линейно нормирована на интервал [. - 1,1]. Тип галактики был закодирован в одном значении выходного (-1 для изогнутой и 1 для неизогнутой). При использовании обратного распространения, примеры были представлены в случайном порядке в течение 20 эпох. Все результаты представляют в средними более 10 пробегов алгоритмов. Сравнение проводили с использованием стандартных t-тестов с 95% уверенностью.
4.1 Расчет фитнесс функции
Одним из важнейших проектных решений по применению ГА расчет значений фитнесс функции для каждого члена популяции. Так как мы заинтересованы в сетях, которые точно предсказывают тип галактик, неиспользованных в обучении, расчет фитнесс функции должен включать в себя оценку обобщения способности сетей.
Есть несколько способов, чтобы оценить обобщение. Так как мы не так много обучающих данных, удержания из методов (разделительные данные в обучение и тестирование наборов и, возможно, дополнительные наборы проверки) не практично. Для расчета фитнесс функции, мы использовали оценку точности пятикратной кроссоверной проверки. В этом методе, данные D делится на пять не пересекающихся наборов, D1, ..., D5. На каждой итерации i (от 1 до 5), сеть обучается с D \ Di и тестируется на Di. Среднее из пяти тестов было использовано в качестве фитнесс функции. Лучше оценка точности будет использовать в среднем несколько кроссоверных экспериментов, но мы обнаружили, стоимость чрезмерной.
Для коррекции неравномерного распределения изогнутых и не изогнутых примеров в наших обучающих данных, мы вычисляем точность как среднее геометрическое точностей каждого класса галактики (изогнутые и не изогнутые) (Кубат and Matwin, 1997). Использование среднего геометрического дает равный вес к точности на обоих типах галактик в общей производительности.
4.2 Обучение сетей с использованием ГА
Мы реализовали первой из методов, описанных в разделе 3.1: А. был использован для поиска весов сети. Сеть имела 20 входов, соответствующих каждому из особенностей в данных, 25 скрытых слоев, и один выход. Каждый вес был представлен 10 битами, и диапазон возможных весов был [-10,10].
Для этого эксперимента, ГА используется с населением в 50 особей, каждая длиной L = 5510 бит (551 общий вес). Количество точек пересечения было установлен 25, а частота мутаций была 0.00018 (≈ 1 / l). Как и во всех экспериментах, был использован попарный турнир выбора без замены.
Второй метод обучения описанный в разделе 3.1- это запуск ОР с использованием весов представленных особями в ГА для инициализации сети. Мы реализовали этот метод и использовали ту же архитектуру сети и параметры ГА, как и в первом эксперименте. Каждая сеть была обучена с использованием 20 эпох ОР со скоростью обучения η 0,1 и β 0,4.
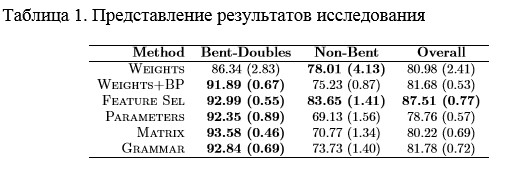
Веса и Веса + ОР в таблице 1 представляют средние точность лучших сетей, обнаруженных в каждом цикле ГА для этих двух серий экспериментов. Результаты выделены жирным шрифтом в таблице лучших результатов и тех, кто не многозначительно хуже, чем лучше (в соответствии с t-тестом, который может обнаружить больше различий, чем на самом деле существует). Добавление ОР производит значительное улучшение в размере точности для изогнутой двойной, которая имеет первостепенное значение для астрономов. Тем не менее, улучшение общей точности не значимы.
4.3 Выбор функций
Следующим сочетанием ГА и НН является использование ГА для выбора особенностей, которые будут использоваться для обучения сетей, как описано в разделе 3.2. Как и в предыдущем эксперименте, мы устанавливаем ряд скрытых элементов до 25, скорость обучения η 0,1 и β 0,4. Сети обучались 20 эпох ОР.
Наши данные имеют 20 особенностей, и, следовательно, хромосом в ГА 20 битные. ГА использует OnePoint кроссовер и те же параметры, что и в предыдущих экспериментах. Результаты точности помечены Feature Sel и значительно лучше, чем другие результаты в таблице 1.
ГА последовательно выбирает около половины возможностей, и часто выбирают особенности, которые уместны для идентификации изогнутых двойных галактик, таких как меры симметрии и углов.
4.4 Проектирование сетей с использованием ГА
Для нашего первого приложения ГА для разработки сети, ГА был использован для нахождения количества скрытых элементов, параметров для ОР, и ряда начальных весов, как описано в разделе 3.3.Скорость обучения была закодирована с четырьмя битами и диапазон возможных значений был [0,1]. Коэффициент β для функции активации также кодировался четырьмя битами и его диапазон был [0,1]. Верхние и нижние диапазоны для начальных весов кодировались пятью битами каждый и было разрешено изменяться в пределах [-10,0] и [0,10], соответственно. Наконец, число скрытых слоев было представлено семью битами и могло принимать значения в [0,127].
После извлечения параметров из хромосомы, сеть была построена и инициализируема в соответствии с параметрами и обучена 20 эпохами ОР. Там нет явного предпочтения мелких сетей, но есть неявный уклон в сторону сетей, которые могут быстро учиться, так как мы используем только 20 эпох ОР. Вполне вероятно, что небольшие сети учатся быстрее, чем крупные, и поэтому вполне вероятно, что ГА предпочитает небольшие сети.
ГА использовал двухточечный кроссовер и те же параметры, что и в предыдущих экспериментах. Результаты точности помечены Parameters в таблице 1. В среднем, лучшая скорость обучения, найденная ГА была 0,82 (0,06 станд. ошибка), что выше, чем обычные рекомендации 0,1-0,2. Возможно, скорость обучения высока из-за неявного предпочтения быстрого обучения. Это предпочтение может также объяснить среднее число скрытых слоев, которое сравнительно небольшое 15,6 (станд. ошибка 2.8). Среднее β было 0,16 (0,01), а диапазон начальных весов был [-3.51, 3.45] (оба с станд. ошибка 0,4).
Следующий эксперимент использовал ГА для поиска матрицы связности, как описано в разделе 3.3. Мы фиксировали количество скрытых элементов 25, учебная норма 0,1 и β 0,4. Нейроны нумеруются последовательно, начиная со входов и следуя к скрытым слоям и выходам. Матрица связности кодируется путем конкатенации ее строки. Так как мы позволяем прямые связи между входами и выходами, длина строки (скрытый + выходов) * входы + скрытые *выходы = (26 * 20) + (25 * 1) = 545 бит. Для этой длинной строки, мы используем 10 очков кроссовера и те же параметры ГА, что и раньше. Результаты, соответствующие этому методу обозначены Matrix в таблице 1.
Мы также реализовали метод Китано – граф, повторно пишущий грамматику. Мы ограничили количество шагов перезаписи до 6, результат в сетях с более 64 единицами. Поскольку хромосомы кодируют четыре бинарных матрицы 2 × 2 для каждого из 16 правил, длина строки 256 бит. ГА использовал пять точек пересечения. Результаты, полученные с помощью этого метода помечены Gramma в таблице 1.
4.5 Сравнение и обсуждение
В таблице 1 приведены результаты, полученные с каждого метода. Результаты показывают, несколько различий между разными методами в степени точности для изогнутых двойных. В то время как прямое кодирование соединений (Matrix) имеет лучшую точность, четыре других метода не кажутся значительно менее точными. С точки зрения точности на не изогнутых двойных и общей точности, ясно, что методом отбора особенностей получены лучшие результаты.
Мы также провели многочисленные эксперименты с сетями, разработанных вручную. Лучшие параметры, которые мы смогли обнаружить в течение 20 эпох обратного распространения были те, которые используются в экспериментах с ГА: β = 0,1, скорость обучения составляла 0,4, а число скрытых слоев было 25. Среднее десяти 10-кратных экспериментов кроссовера приведенных в точности на не изогнутых двойных только 16,4% (с станд. ошибка 1,7) и на изогнутых 99,69% (0,16). Общая точность оценивается средней геометрической точностью это разочарование 23,41% (2.02).
Увеличение количества учебных эпох до 100 поднял уровень средней геометрической точности до 72.69% (0,32). Точность на не изогнутых двойных также улучшилась до 56,7%, в то время как точность на изогнутых слегка снизилась до 94,38%.
5. Выводы
Эта статья представила сравнение шести комбинаций ГА и НН для отождествления изогнутый двойных галактик вопросе FIRST. Наши эксперименты показывают, что для этого приложения, некоторые комбинации ГА и НН представляют классификаторы, которые являются конкурентоспособными с сетями, разработанными вручную. Для нашего приложения, мы обнаружили, несколько различий среди комбинаций ГА и НН, которые мы использовали. Только последовательно лучший метод должен был пользовать ГА, чтобы выбрать особенности, использованные для обучения сетей, которые предполагали, что некоторые из особенностей в обучающей последовательности неуместны или избыточны.
Есть несколько путей, чтобы расширить эту работу. Очень несбалансированный набор обучение представляет некоторые трудности, что можно было бы избежать или смягчить путем включения больше примеров класса меньшинства. Однако, расширять обучающий набор нетривиально, поскольку маркировка является субъективной и разногласия среди экспертов являются общими.
Другие методы оптимизации, эволюционные и традиционных, могут быть использованы для обучения НН. В этой статье мы использовали простой генетический алгоритм с двоичным кодированием, но и другие эволюционные алгоритмы работают на векторах вещественных чисел, которые могут быть непосредственно сопоставлены с весами в сети или параметров ОР (но не к матрице связности, грамматики, или особенностям выбора приложений). Есть другие комбинации ГА и НН, которые мы не включили в данное исследование, но кажутся многообещающими. Например, с эволюционные алгоритмы используют население сетей, естественным продолжением этой работы было бы использовать эволюционные алгоритмы для создания ансамблей, которые сочетают несколько НН, улучшить точность классификаций.
Недостатком использования генетических алгоритмов в сочетании с нейронными сетями является длительное время вычисления. Это может быть препятствием для применения этих методов для больших наборов данных, но есть многочисленные альтернативы, чтобы улучшить производительность генетических алгоритмов. Например, мы могли бы приблизить оценку фитнесс функции с помощью выборки или мы можем использовать по сути параллельный характер ГА с использованием нескольких процессоров.