


Abstract
Warning! This abstract refers to a work that has not been completed yet.
Estimated completion date: June 2018. Contant author after that date to obtain complete text.
Content
- Introduction
- 1. Relevance of the research topic
- 2. The purpose and objectives of the study, the planned results
- 3. Current state of the problem
- 4. Detection and recognition of symbols in the image
- 4.1 Preprocessing an image
- 4.2 Detecting lines in an image
- 4.3 Segmentation of words on the image
- 4.4 Segmentation of characters in the image
- 4.4.1 Search for local luminance minima
- 4.4.2 Deleting false boundaries
- Сonclusions
- References
Introduction
The theme of text recognition falls under the pattern recognition section. And for a start, briefly about the very recognition of images. Image recognition or the theory of pattern recognition is a section of informatics and related disciplines that develops the principles and methods of classification and the identification of objects, phenomena, processes, signals, situations, etc., objects that are characterized by a finite set of certain properties and attributes.
There are two main directions in this area:
- studying the ability to recognize, which living beings have, the explanation and modeling of them;
- development of the theory and methods for constructing devices designed to solve individual problems for applied purposes
Everybody has known for a long time that there are millions of old books that are stored in strict security storages, access to which has only specialized staff. The use of these books is forbidden because of their decrepitude and decrepitude, since it is possible that they may crumble right in the hands of the reader, but the knowledge that they hold is undoubtedly a great treasure for humanity and therefore the digitization of these books is so important. This is in particular the specialists in the field of data processing.
We come closer to the topic of text recognition. It should be noted that the recognition of text is usually understood as the three main methods:
- comparison with a pre-prepared template
- recognition using criteria, an identifiable object;
- recognition using self-learning algorithms, including using neural networks.
Also it should be said that text recognition almost always goes in the compartment with the detection of text in the image.
Studies in this area have been conducted for a long time, which brought not a few fruits. To date, there are many algorithms for recognizing printed text on images, but still one hundred percent accuracy has not yet been achieved. Besides, most application solutions are able to recognize the English alphabet well. Recognition of the Russian alphabet and words passes in two basic stages. First, the text is searched for the image and its recognition, and poorly recognized words come to the result thanks to the search for similarities in lexicographic dictionaries.
1. Relevance of the research topic
Most developments in the field of information technology are mainly owned by foreign scientists, including achievements in the field of recognition of text on images. Therefore, most of the ready-made software solutions are oriented to English language and similar ones, and on the Russian spelling there are errors of recognition.
In Russian history, there are different versions of spelling. As modern development with difficulty or not fully recognize the familiar Russian text, what can we say about the pre-revolutionary Russian spelling. But the need for such developments still exists. The usual there is no access to old manuscript archives written in Old Slavonic, but thanks to modern technologies it is easy to find in the network scanned copies of this valuable knowledge. Unfortunately, the search for necessary information in electronic archives is difficult. To find you need to re-read a lot of records.
Therefore, it was decided to develop software that can recognize pre-revolutionary Russian spelling. Similar software the module can be embedded in a search engine, thereby providing the ability to search for information on old archives. For example, such a search can be useful to a person who studies his family tree and the origin of his family name.
2. The purpose and objectives of the study, the planned results
The aim of the master's thesis is to develop software for recognizing the printed text of pre-revolutionary Russian spelling.
To achieve this goal, you must perform the following tasks:
- analyze the current state of the problem of text recognition on images;
- analyze and compare existing algorithms, methods of text recognition on images;
- Analyze and compare realized text recognition software on images;
- develop an algorithm for preprocessing images with text;
- Develop an algorithm for detecting text and individual characters in the image
- develop the architecture of an artificial neural network
- Develop an algorithm for recognizing text based on an artificial neural network
- develop software, conduct testing;
- investigate the effectiveness of the developed algorithm.
3. Current state of the problem
To date, there are many different systems that can recognize text on images with high efficiency. The ABBYY FineReader software product is the most popular in the field of text recognition on images, but is mainly used to receive text from pdf-files [1] . Of course, this software product is not ideal and does not recognize 100% of the entire text. High efficiency provides a huge lexicographic dictionary, which is constantly replenished and improved. It is necessary for words, which are not fully recognized by recognition algorithms. In addition, the PDF document almost always has straight lines of text, which simplifies detection. In this case, you can apply the calculation of the average brightness value of each pixel row to detect lines of text, and then apply the same method, but for each line individually, to select words and letters.
On images, the text is not always perfectly smooth (more precisely, almost never happens, especially if it's a scanned text), that's why detection is essential but this problem has been solved for a long time. Algorithms for recognizing car license plates apply the method of calculating the angle of rotation of a text to recognize license plate number on the road camera [2] . Thus, in some countries, if the driver violates the rules of the road, he is sent a fine to mail in automatic mode.
If there are so many solutions for recognizing text on images, there is no software product that could recognize pre-revolutionary Russian orthography.
4. Detection and recognition of symbols in the image
4.1 Preprocessing an image
For a person it's easy to read text on an image, regardless of image quality and clarity text, which can not be said about the computer. Therefore, to ensure correct recognition of the text, a number of transformations for the maximum simplification of the task of detection, and later the recognition of the text.For processing is applied The most effective filter for removing noises in the image is the median filter [3] . It clears the image from noise and makes it maximally clean, removing noise and thereby amplifying a useful signal. An example of filter operation is shown in Figure 4.1.
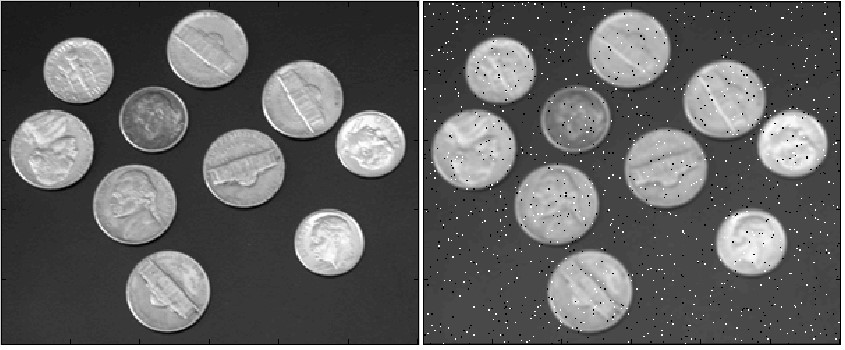
Figure 4.1 - Example of the operation of the median filter (noisy image and image after processing)
The filtering phase is very important for the next stage of processing. The computer processes information in a binary system, so binary information is easiest. In the next step, a monochrome filter is applied to the image, which brings the image to black and white format, which is the binary information [3] .
The monochrome filter takes the image to black and white, highlighting the text in the image. During processing, the brightness of each pixel is calculated on the image and setting it to black or white color, depending on the overall level of brightness of the image. After processing, the image with text has the form as in Figure 4.2.

Figure 4.2 - Processed image
4.2 Detecting lines in an image
To find the text on the image, the average brightness value of each pixel row is calculated by the formula:
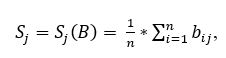
where S j is the average brightness value of the pixel row, n is the width of the recognized picture, b ij is the pixel brightness.
After that, the average brightness value of the whole image is calculated using the formula:
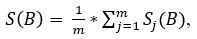
where S (B) is the average brightness value of the entire image, m is the height of the recognized image, S j (B) is the average brightness value of the pixel row.
The average brightness in the line spacing of the text should be small (in the ideal case it is zero) [4] . Therefore, the brightness of the text border lines can be expressed in terms of the average brightness of the image using the formula:
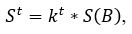
where 0
Similarly, the brightness of the bottom border of a text string can also be expressed in terms of the average brightness of the entire image using the formula:
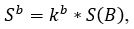
where 0
The work of the string segmentation algorithm consists in sequentially viewing an array of mean values ??(s 1 , ..., s m ) and the detection of a set of pairs of indices (s i t , s i b ) of pixel rows corresponding to the upper s i t and the lower s i b to the faces of the image of row i that satisfy the following conditions:
1. The conditions of the upper border of the text string.
The beginning of a text string or a region of steady increase in brightness is fixed if the following set of conditions is fulfilled:
- the brightness of the current pixel string exceeds the limit s t ;
- the brightness of the two previous pixel rows below this boundary;
- the brightness of the next three lines is higher than the border s b .
This means that in the pixel row with the number i the image of the text string begins, if,
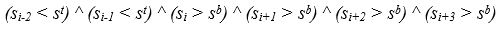
2. Conditions for the bottom of the text string.
The end of the stable brightness enhancement area is determined if the following conditions are met:
- the beginning of the region was fixed;
- the brightness of the current pixel string exceeds the limit s t ;
- the brightness of the next pixel row below the boundary s b .
Or:
- the beginning of the region was fixed;
- the brightness of the next three lines is below the limit s b .
This means that in the pixel row with the number i the image of the text string ends, if it was previously determined that the string started, and the condition is met,
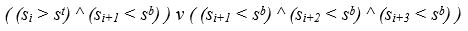
As a result, many pairs of indices of the upper and lower faces of the rows are formed. The difference between these indices gives height of text strings. However, such an algorithm finds the average height of each text string and "cuts off" the characters that protrude in height for this average height.
To avoid this, it is necessary to expand the found boundaries. We can propose the following algorithm for expanding the boundaries. Among the text strings found, a string with a minimum height H min is defined, and then all borders on each side are expanded to the value is 0.3 * H min . This does not result in line merging. line spacing is generally larger than the height of a line [5] . An example of the processed image is shown in Figure 4.3.

Figure 4.3 - Selecting line boundaries
Thus, as a result of the algorithm on the source image, the position of all text lines is marked.
4.3 Segmentation of words on the image
At the second stage of solving the problem of segmentation of the image of the text, from the images of the lines. The input for the algorithm segmentation of words is an image, any single text string that is obtained from the original image document after applying the segmentation algorithm to it (see Figure 4.4).
Figure 4.4 - Selected line image
To improve the quality of the algorithm for selecting words from a string, two transformations of the input image are performed at the beginning of its operation.
The contrast enhancement threshold filter by the following formula:
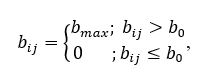
where i = 1 ... n; j = 1 ... m; b 0 - the brightness threshold.
Such a transformation, with a correctly selected threshold b 0 , helps to reduce noise, i.e. remove a significant number of extra points. The result of the threshold filter operation is shown in Figure 4.5.
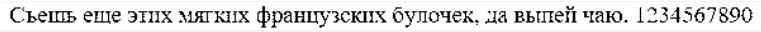
Figure 4.5 - The result of the threshold filter operation
"Smearing" filter - for each bright (black) point of the original image, paint the neighboring points.
As a result of this transformation, close points are combined into a continuous region and instead of a set of small points we get a picture consisting of several solid spots with a sufficiently sharp boundary as in Figure 4.6.

Figure 4.6 - The result of the "smearing" filter
The work of the word segmentation algorithm is very similar to the segmentation of the lines, only in the case of words is the calculation the brightness of the pixel columns and the search for vertical word boundaries, otherwise the algorithm is identical to [5] .
As a result of the work, the image becomes as in Figure 4.7.
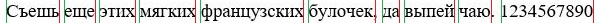
Figure 4.7 - Picture of a line with highlighted words
4.4 Segmentation of characters in the image
In most images of words, the symbols are located close to each other and the intersignal intervals are not so pronounced, as in the case of interline or inter-vertex intervals. Therefore, the algorithm for segmenting symbols is more complex and not as obvious as those considered earlier algorithms for segmenting lines and words [6].
The input for the symbol segmentation algorithm is an image of any word that is obtained from the image of the text string after applying the word segmentation algorithm to it.
The algorithm for symbol segmentation is based on the fact that the average brightness in intersignal intervals is at least lower average brightness in the images of symbols. Its (segmentation algorithm) general scheme consists of two main parts:
- search for all column indices corresponding to local minimums of the average brightness of the columns
- detecting and removing from this list of indexes false character boundaries.
The ultimate goal of the work is to find indexes of column-borders between characters.
4.4.1 Search for local luminance minima
The search for local minima of the average brightness of the columns c i occurs at adjacent intervals of the column index change [6]. The size of the interval is selected based on the height of the line. For most fonts, the ratio of the symbol width to its height does not exceed 0.3. Therefore, the size of the interval is chosen as d j = 0.3 * m, where m is the height of the word in pixels.
Finding the minima works like this:
First, for all the pixel columns of the original image, we find their average brightness values using the formula:
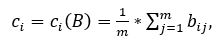
where m is the height of the word in pixels.
Among the values of c i, we look for the first minimum on the segment i = 1, ..., d j .
Suppose that it was found for the index i 1 min .
The next minimum is found on the segment i = (i 1 min +1), ..., (i 1 min + 1 + d j ).
The search procedure is repeated until the boundary (i = n) of the word image is reached.
All i j min values corresponding to local minima are stored in the W 0 list. The result is shown in Figure 4.8.
Figure 4.8 - An image of a word with local minima of the average brightness of the columns
4.4.2 Deleting false boundaries
Deleting false intersymbol boundaries occurs in several steps listed below.
1. The local minimum brightness in column number i is the "candidate" for belonging to the inter-character interval, if the value the average brightness c i in this column is less than a certain brightness boundary cb and the mean brightness value in the columns that are separated from this local minimum by 2 pixels to the left or to the right more than the brightness limit. The brightness boundary can be determined through the mean the brightness of the picture by the formula (4.7).
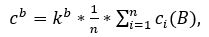
where 0
The first condition of the intersymbol boundary can be written in the following form
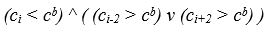
As a result, the indexes of the local minima W 0 are removed from the list of indexes of the columns, the average brightness of which does not satisfy this condition, the second list of W 1 indexes "candidates" is formed in the intersignal boundaries as in Figure 4.9.
Figure 4.9 - Image of a word after deleting a part of false boundaries
2. Identify the relationships between the columns of pixels. At this step in the segmentation algorithm, we will analyze the connectivity of the symbol images and remove from the list W 1 false boundaries that cut the character into parts. This can occur with wide loosely coupled symbols, for example, symbols of the Russian alphabet П, Н, Ц. Moreover, the symbol can be connected either in the upper (П), or in the middle (Н), or in the lower part (Ц) of the pixel columns. To avoid wrong classification of connectivity, we divide the image into three levels vertically and will analyze these levels separately from each other [7]. The division of the symbol image into parts occurs in the following proportion: the upper level is 30% of the symbol height, the average level is 40% of the symbol height, the lower level is 30% of the symbol height.
We formulate the connectivity conditions for two adjacent pixel columns k and k + 1:
- for the brightness maximums of three levels b kh1 , b km1 , b kl1 of column k and luminance maxima of three levels b (k +1) h2 , b (k + 1) m2 , b (k + 1) l2 of the column k + 1, the following condition must be satisfied: (h1 = h2) v (m1 = m2) v (l1 = l2);
- the average brightness of column k should be less than the brightness maximum of the adjacent column k + 1, c (k)
max (k + 1); - the maximum brightness in column k should be greater than twice the absolute value of the difference between the values of the brightness maxima
column k and adjacent column k + 1,
c max (k)> 2 * | c max (k) - c max (k + 1) |.
If for this column all the conditions of connectivity with neighbors left and right are satisfied, then the boundary is deleted as false, otherwise, one more is performed check [8]. The distance to the previous (left) border dk must be greater than the permissible minimum d min .
d k > d min .
d min = 0.4 * n.
where n is the height of the image of the word
As a result, indexes of columns that have a link with neighbors on the left and right are removed from the list of indexes of "candidates" W 1 a finite list of boundary indices W 2 is formed. This is shown graphically in Figure 4.10.
Figure 4.10 - Word image after processing
Thus, from any picture you can get a set of image-symbols that can be recognized using an artificial neural network. The general sequence of steps of the algorithm is given below.

Figure 1 - Steps of the algorithm for selecting symbols
(Animation: Size: 104Kb; Frames: 9; Repeats: 15; Delay: 2s.)
Сonclusions
In the work, existing methods and software for text recognition on images are examined and analyzed. The advantages and disadvantages of methods are also highlighted.
The algorithm for detecting and segmenting text on images is given. Using the above method, you can find the text in the image and segment it up to one character. After that, each character is sent to the input of an artificial neural network, which acts as a recognizer.
The choice of an artificial neural network as a text recognizer is due to its versatility, high efficiency and capability additions to other spellings [9].
References
- Как это работает: FineReader – [Электронный ресурс]. – Режим доступа: https://www.ixbt.com/soft/finereader.shtml
- Распознавание автомобильных номеров в деталях – [Электронный ресурс]. – Режим доступа: https://habrahabr.ru/company/recognitor/blog/225913/
- S. Milyaev, O. Barinova and T. Novikova.
Image binarization for end-to-end text understanding in natural images
. // ICDAR. – 2013. – p. 230 – 238. - J. Mata, O. Chum, M. Urban and T. Pajdl
Robust wide baseline stereo from maximally stable extremal regions
. // British Machine Vision Conference. – 2002. – p. 384–393. - X.C. Yin and K. Huang
Robust text detection in natural scene images
. – CoRR. – 2013. – p. 189–196. - H. Chen, S. Tsai, G.Schroth, D. M. Chen, R. Grzeszczuk and B. Girod
Robust text detection in natural images with edge-enhanced maximally stable extremal regions
. // IEEE International Conference on Image Processing – 2011. – p. 332–340. - L. Gomez, D. Karatzas.
Multi-script text extraction from natural scenes
. // ICDAR – 2013. – p. 123–131. - Новиков Ф.А.
Дискретная математика для программистов
. // СПб.: Питер. – 2000. – 304 с. - Хайкин Саймон.
Нейронные сети: полный курс. Второе издание
. – [пер. с англ.]. // М.: Вильямс. – 2006. – 1014 с