


Реферат по теме выпускной работы
Внимание! Данный реферат относится к еще не завершенной работе.
Примерная дата завершения: Июнь 2018 г. Обращайтесь к автору после указанной даты для получения окончательного варианта.
Содержание
- Введение
- 1. Актуальность темы исследования
- 2. Цель и задачи исследования, планируемые результаты
- 3. Современное состояние проблемы
- 4. Обнаружение и распознавание символов на изображении
- 4.1 Предобработка изображения
- 4.2 Детектирование строк на изображении
- 4.3 Сегментация слов на изображении
- 4.4 Сегментация символов на изображении
- 4.4.1 Поиск локальных минимумов яркости
- 4.4.2 Удаление ложных границ
- Выводы
- Список источников
Введение
Тема распознавания текста попадает под раздел распознавания образов. И для начала коротко о самом распознавании образов. Распознавание образов или теория распознавания образов - это раздел информатики и смежных дисциплин, развивающий основы и методы классификации и идентификации предметов, явлений, процессов, сигналов, ситуаций и т. п. объектов, которые характеризуются конечным набором некоторых свойств и признаков.
Можно выделить два основных направления в этой области:
- изучение способностей к распознаванию, которыми обладают живые существа, объяснение и моделирование их;
- развитие теории и методов построения устройств, предназначенных для решения отдельных задач в прикладных целях.
Всем давно известно, что существуют миллионы старых книг, которые хранятся в хранилищах строгого режима, доступ к которым имеет только специализированный персонал. Использование этих книг запрещено по причине их ветшалости и дряхлости, так как возможно, что они могут рассыпаться прямо в руках читателя, но знания, которые они хранят, представляют, несомненно, большой клад для человечества и поэтому оцифровка этих книг столь важна. Именно этим в частности занимаются специалисты в области обработки данных.
Приблизимся еще ближе к теме распознавания текста. Следует заметить, что под распознаванием текста обычно понимают три главных метода:
- сравнение с заранее подготовленным шаблоном;
- распознавание с использованием критериев, распознаваемого объекта;
- распознавание при помощи самообучающихся алгоритмов, в том числе при помощи нейронных сетей.
Также следует сказать, что распознавание текста почти всегда идет в купе с обнаружением текста на изображении.
Исследования в этой области ведутся уже давно, что принесло не мало плодов. На сегодняшний день существует множество алгоритмов распознавания печатного текста на изображениях, но все же стопроцентная точность еще не достигнута. Кроме того, большинство прикладных решений способны хорошо распознавать текст английского алфавита. Распознавание русского алфавита и слов проходит в два основных этапа. Сначала происходит поиск текста на изображении и его распознавание, а плохо распознанные слова приходят к результату благодаря поиску схожестей в лексикографических словарях.
1. Актуальность темы исследования
Большинство разработок в области информационных технологий в основном принадлежат зарубежным ученым в том числе и достижения в области распознавания текста на изображениях. Поэтому большинство готовых программных решений ориентированы на английский язык и ему подобные, а на русской орфографии происходят ошибки распознавания.
В русской истории существуют различные версии орфографий. Так как современные разработки с трудом или не до конца распознают привычный русский текст, что уж говорить о дореволюционной русской орфографии. Но необходимость таких разработках все же существует. У обычного человека нет доступа к старым рукописным архивам, написанным на старославянском, но благодаря современным технологиям легко можно найти в сети отсканированные копии этих ценных знаний. К сожалению поиск необходимой информации в электронных архивах затруднено. Чтобы найти нужную информацию, необходимо перечитать множество записей.
Поэтому и было решено разработать программное обеспечение, способное распознавать дореволюционную русскую орфографию. Подобный программный модуль можно встроить в поисковую систему, тем самым предоставить возможность поиска информации по старым архивам. К примеру, такой поиск может пригодиться человеку, который изучает свою родословную и происхождение своей фамилии.
2. Цель и задачи исследования, планируемые результаты
Целью магистерской диссертации является разработка программного обеспечение для распознавания печатного текста дореволюционной русской орфографии.
Для достижения поставленной цели, необходимо выполнить следующие задачи:
- проанализировать современное состояние проблемы распознавания текста на изображениях;
- провести анализ и сравнение существующих алгоритмов, методов распознавания текста на изображениях;
- провести анализ и сравнение реализованных программных средств распознавания текста на изображениях;
- разработать алгоритм предобработки изображения с текстом;
- разработать алгоритм детектирования текста и отдельных символов на изображении;
- разработать архитектуру искусственной нейронной сети;
- разработать алгоритм распознавания текста на основе искусственной нейронной сети;
- разработать программное обеспечение, провести тестирование;
- исследовать эффективность разработанного алгоритма.
3. Современное состояние проблемы
На сегодняшний день существует множество различных систем, которые способны распознавать текст на изображениях с высокой эффективностью. Программный продукт ABBYY FineReader является самым популярным в области распознавания текста на изображениях, но в основном применяется для получения текста из pdf-файлов [1]. Конечно данный программный продукт не является идеальным и не распознает 100% всего текста. Высокую эффективность обеспечивает огромный лексикографический словарь, который постоянно пополняется и совершенствуется. Он необходим для слов, которые не распознаются до конца алгоритмами распознавания. Кроме того, документ PDF практически всегда имеет ровные строчки текста, что упрощает детектирование. В таком случае можно применить вычисление среднего значение яркости каждой пиксельной строки для обнаружения строк текста, а потом применить тот же метод, но уже для каждой строки в отдельности для выделения слов и букв.
На изображениях текст не всегда бывает идеально ровным (точнее почти всегда не бывает, особенно если это отсканированный текст), поэтому детектирование существенно усложняется, но все же эта проблема давно решена. Алгоритмы распознавания номерных знаков автомобилей применяют метод вычисление угла поворота текста, чтобы распознать номерной знак на дорожной камере [2]. Таким образом в некоторых странах, при нарушении водителем правил дорожного движения, ему высылается штраф на почту в автоматическом режиме.
При наличии такого множества решений для распознавания текста на изображениях, нет программного продукта, который бы смог распознать дореволюционную русскую орфографию.
4. Обнаружение и распознавание символов на изображении
4.1 Предобработка изображения
Для человека не составляет никакого труда прочесть текст на изображении, независимо от качества изображения и четкости текста, чего нельзя сказать о компьютере. Поэтому для обеспечения корректного распознавания текста необходимо провести ряд преобразований для максимального упрощения задачи детектирования, а в последствии и распознавания текста. Для обработки применяется самый эффективный фильтр для удаления зашумлений на изображении – медианный фильтр [3]. Он очищает изображение от шумов и делает его максимально чистым, удаляя шум и тем самым усиливает полезный сигнал. Пример работы фильтра изображен на рисунке 4.1.
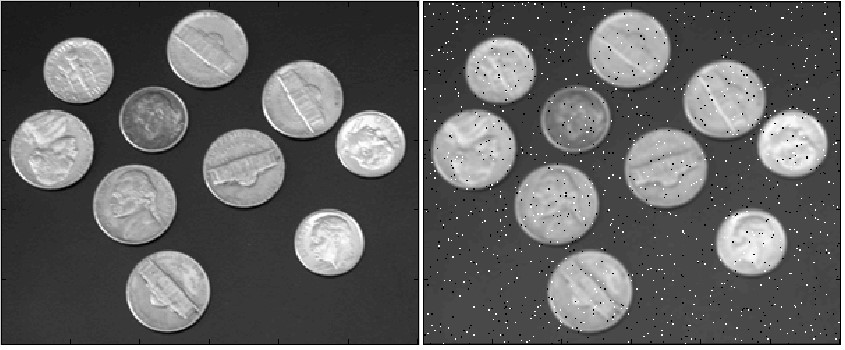
Рисунок 4.1 – Пример работы медианного фильтра (зашумленное изображение и изображение после обработки)
Этап фильтрации очень важен для следующего этапа обработки. ЭВМ обрабатывает информацию в двоичной системе счисления, поэтому обрабатывать двоичную информацию проще всего. На следующем этапе, к изображению применяется монохромный фильтр, который переводит изображение в черно-белый формат, что и является двоичной информацией [3].
Монохромный фильтр переводит изображение в черно-белое, выделяя текст на изображении. При обработке происходит вычисление яркости каждого пиксела на изображении и установка его в черный или белый цвета в зависимости от общего уровня яркости изображения. После обработки, изображение с текстом имеет вид как на рисунке 4.2.

Рисунок 4.2 – Обработанное изображение
4.2 Детектирование строк на изображении
Для обнаружения текста на изображении происходит вычисление среднего значения яркости каждой пиксельной строки по формуле:
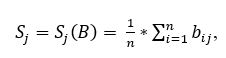
где Sj – среднее значение яркости пиксельной строки, n – ширина распознаваемой картинки, bij – яркость пиксела.
После чего, происходит вычисление среднего значения яркости всего изображения по формуле:
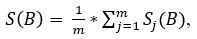
где S(B) – среднее значение яркости всего изображения, m – высота распознаваемой картинки, Sj(B) – среднее значение яркости пиксельной строки.
Средняя яркость в межстрочных промежутках текста должна быть невелика (в идеальном случае она равна нулю) [4]. Поэтому яркость верхней границы текстовой строки можно выразить через среднюю яркость изображения по формуле:
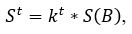
где 0< kt<1 – коэффициент.
Аналогично яркость нижней границы текстовой строки, также может быть выражена через среднюю яркость всего изображения по формуле:
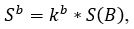
где 0< kb <1 – коэффициент.
Работа алгоритма сегментации строк заключается в последовательном просмотре массива средних значений (s1,...,sm) и выявлении множества пар индексов (sit,sib) пиксельных строк, соответствующих верхней sit и нижней sib граням изображения строки номер i, удовлетворяющих следующим условиям:
1. Условия верхней границы текстовой строки.
Начало текстовой строки или области устойчивого повышения яркости фиксируется, если выполняется следующий комплекс условий:
- яркость текущей пиксельной строки превышает границу st;
- яркость двух предыдущих пиксельных строк ниже этой границы;
- яркость трех последующих строк выше границы sb.
Это означает что в пиксельной строке с номером i начинается изображение текстовой строки если,
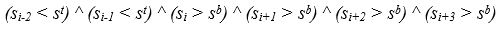
2. Условия нижней границы текстовой строки.
Конец области устойчивого повышения яркости определяется, если выполняется следующие условия:
- было зафиксировано начало области;
- яркость текущей пиксельной строки превышает границу st;
- яркость последующей пиксельной строки ниже границы sb.
Или:
- было зафиксировано начало области;
- яркость трех последующих строк ниже границы sb.
Это означает что в пиксельной строке с номером i заканчивается изображение текстовой строки, если ранее было определено, что строка началась, и выполняется условие,
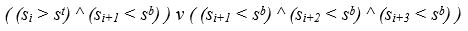
В результате формируется множество пар индексов верхних и нижних граней строк. Разность между этими индексами дает высоты текстовых строк. Однако такой алгоритм находит среднюю высоту каждой текстовой строки и «срезает» символы, выступающие по высоте за эту среднюю высоту.
Чтобы избежать этого, необходимо расширить найденные границы. Можно предложить следующий алгоритм расширения границ. Среди найденных текстовых строк определяется строка с минимальной высотой Hmin и, затем все границы с каждой стороны расширяются на величину 0.3 * Hmin. Это не приводит к слиянию строк, т.к. межстрочные интервалы текста, как правило, больше чем высота строки [5]. Пример обработанной картинки изображен на рисунке 4.3.

Рисунок 4.3 – Выделение границ строк
Таким образом, в результате работы алгоритма на исходном изображении отмечается положение всех текстовых строк.
4.3 Сегментация слов на изображении
На втором этапе решения задачи сегментации изображения текста, из изображений строк. Входом для алгоритма сегментации слов служит изображение, какой-либо одной текстовой строки, которое получается из исходного изображения документа после применения к нему алгоритма сегментации строк (см.рис. 4.4).
Рисунок 4.4 – Выделенное изображение строки
Для улучшения качества работы алгоритма выделения слов из строки вначале его работы выполняются два преобразования входного изображения.
Пороговый фильтр повышения контрастности по следующей формуле:
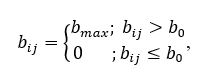
где i=1... n ; j=1... m ; b0 - порог яркости.
Такое преобразование, при правильно выбранном пороге b0, помогает снизить уровень шума, т.е. убрать значительное количество лишних точек. Результат работы порогового фильтра показан на рисунке 4.5.
Рисунок 4.5 – Результат работы порогового фильтра
«Размазывающий» фильтр – для каждой яркой (чёрной) точки исходного изображения закрашиваем соседние точки.
В результате такого преобразования близкие точки объединяются в непрерывную область и вместо множества маленьких точек получаем картинку, состоящую из нескольких сплошных пятен с достаточно чёткой границей как на рисунке 4.6.

Рисунок 4.6 – Результат работы «размазывающего» фильтра
Работа алгоритма сегментации слов очень схожа с сегментацией строк, только в случае слов происходит вычисление яркостей пиксельных столбцов и поиск вертикальных границ слов, в остальном алгоритм идентичен [5].
В результате работы, изображение принимает вид как на рисунке 4.7.
Рисунок 4.7 – Изображение строки с выделенными словами
4.4 Сегментация символов на изображении
В большинстве изображений слов символы расположены близко друг к другу и межсимвольные интервалы не так ярко выражены, как в случае межстрочных или межсловных интервалов. Поэтому алгоритм сегментации символов сложнее и не так очевиден, как рассмотренные ранее алгоритмы сегментации строк и слов [6].
Входом для алгоритма сегментации символов служит изображение, какого-либо слова, которое получается из изображения текстовой строки после применения к нему алгоритма сегментации слов.
Алгоритм сегментации символов основывается на том, что средняя яркость в межсимвольных интервалах, по крайней мере, ниже средней яркости в изображениях символов. Его (алгоритма сегментации) общая схема состоит из двух основных частей:
- поиск всех индексы столбцов, соответствующие локальным минимумам средней яркости столбцов;
- выявление и удаление из этого списка индексов ложных границ символов.
Конечная цель работы – найти индексы столбцов-границ между символами.
4.4.1 Поиск локальных минимумов яркости
Поиск локальных минимумов средней яркости столбцов ci происходит на смежных интервалах изменения индекса столбца [6]. Размер интервала выбирается исходя из высоты строки. Для большинства шрифтов отношение ширины символа к его высоте не превышает величину 0.3. Поэтому размер интервала выбран как dj = 0.3 * m, где m – высота слова в пикселах.
Поиск минимумов работает следующим образом:
Сначала для всех пиксельных столбцов исходного изображения находим их средние значения яркости по формуле:
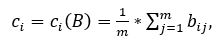
где m - высота слова в пикселах.
Среди значений ci первый минимум ищем на отрезке i=1,...,dj.
Предположим, что он нашелся для индекса i1min.
Следующий минимум ищем на отрезке i=(i1min+1),...,(i1min+1+dj).
Процедура поиска повторяется, до достижения границы (i=n ) изображения слова.
Все значения индекса ijmin, соответствующих локальным минимумам, сохраняются в списке W0. Результат показан на рисунке 4.8.
Рисунок 4.8 – Изображение слова с локальными минимумами средней яркости столбцов
4.4.2 Удаление ложных границ
Удаление ложных межсимвольных границ происходит в несколько этапов перечисленных ниже.
1. Локальный минимум яркости в столбце номер i является «кандидатом» на принадлежность к межсимвольному интервалу, если значение средней яркости ci в этом столбце меньше определённой границы яркости cb и при этом значение средней яркости в столбцах, отстоящих от данного локального минимума на 2 пикселя слева или справа больше границы яркости. Границу яркости можно определить через среднюю яркость картинки по формуле (4.7).
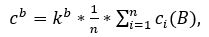
где 0< kb <1 – коэффициент, n - ширина изображения слова в пикселах.
Первое условие межсимвольных границы можно записать в следующем виде
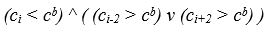
В результате из списка индексов локальных минимумов W0 удаляются индексы столбцов, средняя яркость которых не удовлетворяет этому условию, формируется второй список W1 индексов-«кандидатов» в межсимвольные границы как на рисунке 4.9.
Рисунок 4.9 – Изображение слова после удаления части ложных границ
2. Выявление связей между столбцами пикселей. На этом шаге алгоритма сегментации будем анализировать связность изображений символов и убирать из списка W1 ложные границы, которые разрезают символ на части. Это может происходить с широкими слабосвязанными символами, например, символы русского алфавита П, Н, Ц. Причём, символ может быть связан, либо в верхней (П), либо в средней (Н), либо в нижней части (Ц) пиксельных столбцов. Чтобы избежать неправильной классификации связности, разделим изображение на три уровня по вертикали и будем анализировать эти уровни отдельно друг от друга [7]. Разделение изображения символа на части происходит в следующей пропорции: верхний уровень - 30% от высоты символа, средний уровень - 40% от высоты символа, нижний уровень - 30% от высоты символа.
Сформулируем условия связности двух соседних пиксельных столбцов k и k+1:
- для максимумов яркости трех уровней bkh1,bkm1,bkl1 столбца k и максимумов яркости трех уровней b(k+1) h2,b(k+1) m2,b(k+1) l2
столбца k+1 должно выполняться условие
( h1= h2 ) v ( m1 = m2 ) v ( l1 = l2 ); - средняя яркость столбца k должна быть меньше максимума яркости соседнего столбца k+1, c(k) < cmax(k+1);
- максимум яркости в столбце k должен быть больше удвоенного абсолютного значения разности между значениями максимумов яркости
столбца k и соседнего столбца k+1,
cmax(k) > 2 * | cmax(k) - cmax(k+1) |.
Если для данного столбца выполняются все условия связности с соседями слева и справа то граница удаляется как ложная, в противном случае выполняется ещё одна проверка [8]. Расстояние до предыдущей (левой) границы dk должно быть больше допустимого минимума dmin.
dk > dmin.
dmin= 0.4 * n.
где n - высота изображения слова
В результате из списка индексов "кандидатов" W1 удаляются индексы столбцов, которые имеют связь с соседями слева и справа, формируется конечный список индексов границ W2. Графически это представлено на рисунке 4.10.
Рисунок 4.10 – Изображение слова после обработки
Таким образом, из любой картинки можно получить набор картинок-символов, которые можно распознавать с помощью искусственной нейронной сети. Общая последовательность шагов алгоритма приведена ниже.

Рисунок 1 – Шаги алгоритма выделения символов
(Анимация: Размер: 104Кб; Кадров: 9; Повторов: 15; Задержка: 2сек.)
Выводы
В работе рассмотрены и проанализированы существующие методы и программные средства для распознавания текста на изображениях. Также выделены преимущества и недостатки методов.
Приведен алгоритм детектирования и сегментирования текста на изображениях. С помощью приведенного метода, можно обнаружить текст на изображении и сегментировать его вплоть до одного символа. После чего, каждый символ отправляется на вход искусственной нейронной сети, которая выступает в качестве распознавателя.
Выбор искусственной нейронной сети в качестве распознавателя текста, обусловлен ее универсальностью, высокой эффективностью и возможность дополнения других орфографий [9].
Список источников
- Как это работает: FineReader – [Электронный ресурс]. – Режим доступа: https://www.ixbt.com/soft/finereader.shtml
- Распознавание автомобильных номеров в деталях – [Электронный ресурс]. – Режим доступа: https://habrahabr.ru/company/recognitor/blog/225913/
- S. Milyaev, O. Barinova and T. Novikova.
Image binarization for end-to-end text understanding in natural images
. // ICDAR. – 2013. – p. 230 – 238. - J. Mata, O. Chum, M. Urban and T. Pajdl
Robust wide baseline stereo from maximally stable extremal regions
. // British Machine Vision Conference. – 2002. – p. 384–393. - X.C. Yin and K. Huang
Robust text detection in natural scene images
. – CoRR. – 2013. – p. 189–196. - H. Chen, S. Tsai, G.Schroth, D. M. Chen, R. Grzeszczuk and B. Girod
Robust text detection in natural images with edge-enhanced maximally stable extremal regions
. // IEEE International Conference on Image Processing – 2011. – p. 332–340. - L. Gomez, D. Karatzas.
Multi-script text extraction from natural scenes
. // ICDAR – 2013. – p. 123–131. - Новиков Ф.А.
Дискретная математика для программистов
. // СПб.: Питер. – 2000. – 304 с. - Хайкин Саймон.
Нейронные сети: полный курс. Второе издание
. – [пер. с англ.]. // М.: Вильямс. – 2006. – 1014 с