


Реферат за темою випускної роботи
Увага! Даний реферат відноситься до ще не завершеної роботи.
Орієнтовна дата завершення: Червень 2018 р. Звертайтеся до автора після зазначеної дати для отримання остаточного варіанту.
Зміст
- Вступ
- 1. Актуальність темі дослідження
- 2. Мета і завдання дослідження, плановані результати
- 3. Сучасний стан проблеми
- 4. Виявлення та розпізнавання символів на зображенні
- 4.1 Передобробка зображення
- 4.2 Детектування рядків на зображенні
- 4.3 Сегментація слів на зображенні
- 4.4 Сегментація символів на зображенні
- 4.4.1 Пошук локальних мінімумів яскравості
- 4.4.2 Видалення помилкових меж
- Висновок
- Список джерел
Вступ
Тема розпізнавання тексту ппідпадає під розділ розпізнавання образів. І для початку коротко про розпізнавання образів. Розпізнавання образів або теорія розпізнавання образів це розділ інформатики та суміжних дисциплін, що розвиває основи і методи класифікації та ідентифікації предметів, явищ, процесів, сигналів, ситуацій і т. п. об'єктів, які характеризуються закінченим набором деяких властивостей і ознак.
Можна виділити два основних напрямки в цій галузі:
- вивчення здібностей до розпізнавання, якими володіють живі істоти, пояснення і моделювання їх;
- розвиток теорії і методів побудови пристроїв, призначених для вирішення окремих завдань в прикладних цілях.
Усім давно відомо, що існують мільйони старих книг, які зберігаються в сховищах суворого режиму, доступ до яких має лише спеціалізований персонал. Використання цих книг заборонено через їх ветшалість і крихкість, так як можливо, що вони можуть розсипатися прямо в руках читача, але знання, які вони зберігають, представляють, безсумнівно, великий скарб для людства і тому оцифрування цих книг дуже важлива. Саме цим зокрема займаються фахівці в області обробки даних.
Наблизимося ще ближче до теми розпізнавання тексту. Слід зауважити, що під розпізнаванням тексту зазвичай розуміють три основних метода:
- порівняння із заздалегідь підготовленим шаблоном;
- розпізнавання з використанням критеріїв, об'єкта що роспізнаєтся;
- розпізнавання за допомогою самонавчальних алгоритмів, в тому числі за допомогою нейронних мереж.
Також слід сказати, що розпізнавання тексту майже завжди йде в купі з виявленням тексту на зображенні.
Дослідження в цій області ведуться вже давно, що принесло чимало плодів. На сьогоднішній день існує безліч алгоритмів розпізнавання друкованого тексту на зображеннях, але все ж стовідсоткова точність ще не досягнута. Крім того, більшість прикладних рішень здатні добре розпізнавати текст англійського алфавіту. Розпізнавання російського алфавіту і слів проходить в два основних етапи. Спочатку відбувається пошук тексту на зображенні і його розпізнавання, а погано розпізнані слова приходять до результату завдяки пошуку схожості в лексикографічних словниках.
1. Актуальність темі дослідження
Більшість розробок в області інформаційних технологій в основному належать зарубіжним вченим в тому числі і досягнення в області розпізнавання тексту на зображеннях. Тому більшість готових програмних рішень орієнтовані на англійську мову і їй подібні, а на російській орфографії відбуваються помилки розпізнавання.
У російській історії існують різні версії орфографії. Так як сучасні розробки насилу або не до кінця розпізнають звичний російський текст, що вже говорити про дореволюційну російську орфографію. Але необхідність в таких розробках все ж існує. У звичайної людини немає доступу до старих рукописним архівів, написаним на старослов'янській мові, але завдяки сучасним технологіям легко можна знайти в мережі відскановані копії цих цінних знань. На жаль пошук необхідної інформації в електронних архівах ускладнений. Щоб знайти потрібну інформацію, необхідно перечитати безліч записів.
Тому і було вирішено розробити програмне забезпечення, здатне розпізнавати дореволюційну російську орфографію. подібний програмний модуль можна вбудувати в пошукову систему, тим самим надати можливість пошуку інформації зі старих архівів. Наприклад, такий пошук може стати в нагоді людині, яка вивчає свій родовід і своє прізвище.
2. Мета і завдання дослідження, плановані результати
Метою магістерської дисертації є розробка програмного забезпечення для розпізнавання друкованого тексту дореволюційної російської орфографії.
Для досягнення поставленої мети, необхідно виконати наступні задачі:
- проаналізувати сучасний стан проблеми розпізнавання тексту на зображеннях;
- провести аналіз і порівняння існуючих алгоритмів, методів розпізнавання тексту на зображеннях;
- провести аналіз і порівняння реалізованих програмних засобів розпізнавання тексту на зображеннях;
- розробити алгоритм попередньої обробки зображення з текстом;
- розробити алгоритм детектування тексту і окремих символів на зображенні;
- розробити архітектуру штучної нейронної мережі;
- розробити алгоритм розпізнавання тексту на основі штучної нейронної мережі;
- розробити програмне забезпечення, провести тестування;
- дослідити ефективність розробленого алгоритму.
3. Сучасний стан проблеми
На сьогоднішній день існує безліч різних систем, які здатні розпізнавати текст на зображеннях з високою ефективністю. Програмний продукт ABBYY FineReader є найпопулярнішим в області розпізнавання тексту на зображеннях, але в основному застосовується для отримання тексту з pdf-файлів [1] . Звичайно даний програмний продукт не є ідеальним і не розпізнає 100% всього тексту. Високу ефективність забезпечує величезний лексикографічний словник, який постійно поповнюється і вдосконалюється. Він необхідний для слів, які не розпізнаються до кінця алгоритмами розпізнавання. Крім того, документ PDF практично завжди має рівні рядки тексту, що спрощує детектування. В такому випадку можна застосувати обчислення середнього значення яскравості кожного піксельного рядку для виявлення рядків тексту, а потім застосувати той же метод, але вже для кожного рядка окремо для виділення слів і букв.
На зображеннях текст не завжди буває ідеально рівним (точніше майже завжди не буває, особливо якщо це відсканований текст), тому детектування значно ускладнюється, але все ж ця проблема давно вирішена. Алгоритми розпізнавання номерних знаків автомобілів застосовуе метод обчислення кута повороту тексту, щоб розпізнати номерний знак на дорожній камері [2] . Таким чином в деяких країнах, при порушенні водієм правил дорожнього руху, йому надсилається штраф на пошту в автоматичному режимі.
При наявності такої великої кількості рішень для розпізнавання тексту на зображеннях, немає програмного продукту, який би зміг розпізнати дореволюційну російську орфографію.
4. Виявлення та розпізнавання символів на зображенні
4.1 Передобробка зображення
Для людини не складає ніяких труднощів прочитати текст на зображенні, незалежно від якості зображення і чіткості тексту, чого не можна сказати про комп'ютер. Тому для забезпечення коректного розпізнавання тексту необхідно провести ряд перетворень для максимального спрощення задачі детектування, а в наслідку і розпізнавання тексту. Для обробки застосовується найефективніший фільтр для видалення зашумлення на зображенні - медіанний фільтр [3] . Він очищає зображення від шумів і робить його максимально чистим, видаляючи шум і тим самим підсилює корисний сигнал. Приклад роботи фільтра зображений на малюнку 4.1.
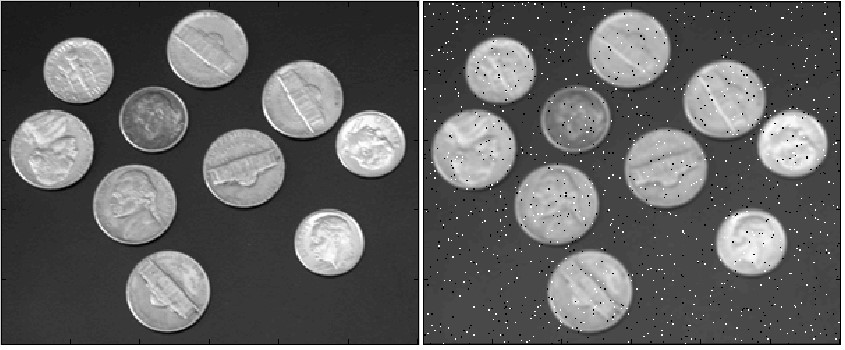
Малюнок 4.1 - Приклад роботи медіанного фільтра (зашумлене зображення і зображення після обробки)
Етап фільтрації дуже важливий для наступного етапу обробки. ЕОМ обробляє інформацію в двійковій системі счислення, тому обробляти двійкову інформацію найпростіше. На наступному етапі, до зображення застосовується монохромний фільтр, який переводе зображення в чорно-білий формат, що і є двійковою інформацією [3] .
Монохромний фільтр переводить зображення в чорно-біле, виділяючи текст на зображенні. При обробці відбувається обчислення яскравості кожного пікселя на зображенні і установка його в чорний або білий кольори в залежності від загального рівня яскравості зображення. Після обробки, зображення з текстом має вигляд як на малюнку 4.2.

Малюнок 4.2 - Оброблене зображення
4.2 Детектування рядків на зображенні
Для виявлення тексту на зображенні відбувається обчислення середнього значення яскравості кожного піксельного рядку за формулою:
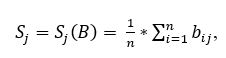
де S j - середнє значення яскравості піксельного рядку, n - ширина картинки що розпізнається, b ij - яскравість пікселя.
Після чого, відбувається обчислення середнього значення яскравості всього зображення за формулою:
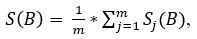
де S (B) - середнє значення яскравочті всього зображення, m - висота картинки що розпізнається, S j (B) - середнє значення яскравості піксельного рядку.
Середня яскравість в міжрядкових проміжках тексту повинна бути невелика (в ідеальному випадку вона дорівнює нулю) [4] . Тому яскравість верхньої межі текстового рядку можна виразити через середню яскравість зображення за формулою:
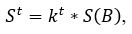
де 0
Аналогічно яскравість нижньої межі текстового рядка, також може бути виражена через середню яскравість всього зображення за формулою:
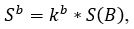
де 0
Робота алгоритму сегментації рядків полягає в послідовному перегляді масиву середніх значень (s 1 , ..., s m ) і виявленні безлічі пар індексів (s i t , s i b ) піксельних рядків, що відповідають верхній s i t і нижній s i b межам зображення рядка номер i, що задовольняють наступним умовам:
1. Умови верхньої межі текстового рядка.
Початок текстового рядка або області сталого підвищення яскравості фіксується, якщо виконується наступний комплекс умов:
- яскравість поточної піксельної рядки перевищує межу s t ;
- яскравість двох попередніх піксельних рядків нижче цієї межі;
- яскравість трьох наступних рядків вище кордону s b .
Це означає що в піксельної рядку з номером i починається зображення текстового рядка якщо,
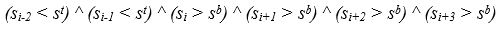
2. Умови нижньої межі текстового рядка.
Кінець області стійкого підвищення яскравості визначається, якщо виконується наступні умови:
- було зафіксовано початок області;
- яскравість поточної піксельного рядку перевищує межу s t ;
- яскравість подальшої піксельного рядку нижче межі s b .
Або:
- було зафіксовано початок області;
- яскравість трьох наступних рядків нижче межі s b .
Це означає що в піксельному рядку з номером i закінчується зображення текстового рядку, якщо раніше було визначено, що рядок почався, і виконується умова,
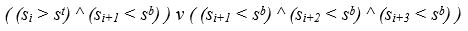
В результаті формується безліч пар індексів верхніх і нижніх граней рядків. Різниця між цими індексами дає висоти текстових рядків. Однак такий алгоритм знаходить середню висоту кожного текстового рядку і «зрізає» символи, які виступають по висоті за цю середню висоту.
Щоб уникнути цього, необхідно розширити знайдені межі. Можна запропонувати наступний алгоритм розширення меж. Серед знайдених текстових рядків визначається рядок з мінімальною висотою H min і, потім всі межі з кожного боку розширюються на величину 0.3 * H min . Це не призводить до злиття рядків, тому що інтервали між рядками тексту, як правило, більше ніж висота рядку [5] . Приклад обробленої картинки зображений на малюнку 4.3.

Малюнок 4.3 - Виділення меж рядків
Таким чином, в результаті роботи алгоритму на оригінальному документі зазначається положення всіх текстових рядків.
4.3 Сегментація слів на зображенні
На другому етапі рішення задачі сегментації зображення тексту, із зображень рядків. Входом для алгоритму сегментації слів служить зображення, будь-якого одного текстового рядку, яке виходить із оригінального зображення документа після застосування до нього алгоритму сегментації рядків (див.рис. 4.4).
Малюнок 4.4 - Виділене зображення рядку
Для поліпшення якості роботи алгоритму виділення слів з рядка спочатку його роботи виконуються два перетворення вхідного зображення.
Граничний фільтр підвищення контрастності за такою формулою:
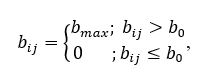
де i = 1 ... n; j = 1 ... m; b 0 - поріг яскравості.
Таке перетворення, при правильно обраному порозі b 0 , допомагає знизити рівень шуму, тобто прибрати значну кількість зайвих крапок. Результат роботи порогового фільтра показаний на малюнку 4.5.
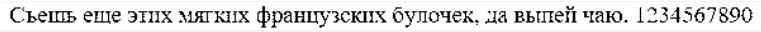
Малюнок 4.5 - Результат роботи порогового фільтра
«Розмазуючий» фільтр - для кожної яскравою (чорної) точки вихідного зображення зафарбовує сусідні точки.
В результаті такого перетворення близькі точки об'єднуються в безперервну область і замість безлічі маленьких точок отримуємо картинку, що складається з декількох суцільних плям з досить чіткою межою як на малюнку 4.6.

Малюнок 4.6 - Результат роботи «розмазуючого» фільтра
Робота алгоритму сегментації слів дуже схожа з сегментацією рядків, тільки в разі слів відбувається обчислення яркостей піксельних стовпців і пошук вертикальних кордонів слів, в іншому алгоритм ідентичний [5] .
В результаті роботи, зображення набуває вигляду як на малюнку 4.7.
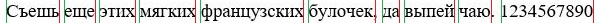
Малюнок 4.7 - Зображення рядка з виділеними словами
4.4 Сегментація символів на зображенні
У більшості зображень слів символи розташовані близько один до одного і міжсимвольні інтервали не так яскраво виражені, як у випадку міжрядкових або міжслівних інтервалів. Тому алгоритм сегментації символів складніше і не такий очевидний, як розглянуті раніше алгоритми сегментації рядків і слів [6] .
Входом для алгоритму сегментації символів служить зображення, будь-якого слова, яке виходить із зображення текстового рядка після застосування до нього алгоритму сегментації слів.
Алгоритм сегментації символів грунтується на тому, що середня яскравість в міжсимвольних інтервалах, принаймны, нижче середньої яскравості в зображеннях символів. Його (алгоритму сегментації) загальна схема складається з двох основних частин:
- пошук всіх індексыв стовпців, що відповідають локальним мінімумам середньої яскравості стовпців;
- виявлення і видалення з цього списку індексів помилкових меж символів.
Кінцева мета роботи - знайти індекси стовпців-меж між символами.
4.4.1 Пошук локальних мінімумів яскравості
Пошук локальних мінімумів середньої яскравості стовпців c i відбувається на суміжних інтервалах зміни індексу стовпця [6] . Розмір інтервалу вибирається виходячи з висоти рядка. Для більшості шрифтів відношення ширини символу до його висоті не перевищує величину 0.3. Тому розмір інтервалу обраний як d j = 0.3 * m, де m - висота слова в пікселах.
Пошук мінімумів працює наступним чином:
Спочатку для всіх піксельних стовпців початкового зображення знаходимо їх середні значення яскравості за формулою:
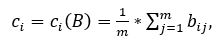
де m - висота слова в пікселах.
Серед значень c i перший мінімум шукаємо на відрізку i = 1, ..., d j .
Припустимо, що він знайшовся для індексу i 1 min .
Наступний мінімум шукаємо на відрізку i = (i 1 min +1), ..., (i 1 min + 1 + d j ).
Процедура пошуку повторюється, до досягнення межі (i = n) зображення слова.
Всі значення індексу i j min , відповідних локальних мінімумів, зберігаються в списку W 0 . Результат показаний на малюнку 4.8.
Малюнок 4.8 - Зображення слова з локальними мінімумами середньої яскравості стовпців
4.4.2 Видалення помилкових меж
Видалення помилкових міжсимвольних кордонів відбувається в кілька етапів перерахованих нижче.
1. Локальний мінімум яскравості в стовпці номер i є «кандидатом» на приналежність до міжсимвольні інтервалу, якщо значення середньої яскравості c i в цьому стовпці менше певної межі яскравості cb і при цьому значення середньої яскравості в стовпцях, віддалених від даного локального мінімуму на 2 пікселя зліва чи справа більше межі яскравості. Межу яскравості можна виразити через середню яскравість картинки за формулою (4.7).
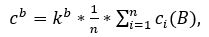
де 0
Перша умова міжсимвольних кордону можна записати в наступному вигляді
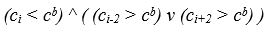
В результаті зі списку індексів локальних мінімумів W 0 видаляються індекси стовпців, середня яскравість яких не задовольняє цій умові, формується другий список W 1 індексів- «кандидатів» в міжсимвольні межі як на малюнку 4.9.
Малюнок 4.9 - Зображення слова після видалення частини помилкових меж
2. Виявлення зв'язків між стовпцями пікселів. На цьому кроці алгоритму сегментації будемо аналізувати зв'язність зображень символів і прибирати зі списку W 1 помилкові межі, які розрізають символ на частини. Це може відбуватися з широкими слабо зв'язаними символами, наприклад, символи російського алфавіту П, Н, Ц. Причому, символ може бути пов'язаний, або у верхній (П), або в середній (Н), або в нижній частині (Ц) піксельних стовпців. Щоб уникнути неправильної класифікації зв'язності, розділимо зображення на три рівні по вертикалі і будемо аналізувати ці рівні окремо один від одного [7] . Поділ зображення символу на частини відбувається в наступній пропорції: верхній рівень - 30% від висоти символу, середній рівень - 40% від висоти символу, нижній рівень - 30% від висоти символу.
Сформулюємо умови зв'язності двох сусідніх піксельних стовпців k і k + 1:
- для максимумів яскравості трьох рівнів b kh1 , b km1 , b kl1 стовпця k і максимумів яскравості трьох рівнів b (k +1) h2 , b (k + 1) m2 , b (k + 1) l2
стовпчика k + 1 повинно виконуватися умова
(h1 = h2) v (m1 = m2) v (l1 = l2); - середня яскравість стовпця k повинна бути менше максимуму яскравості сусіднього стовпчика k + 1, c (k) < c max (k + 1);
- максимум яскравості в стовпці k повинен бути більше подвоєного абсолютного значення різниці між значеннями максимумів яскравості
стовпчика k і сусіднього стовпчика k + 1,
c max (k)> 2 * | c max (k) - c max (k + 1) |.
Якщо для даного стовпця виконуються всі умови зв'язності з сусідами зліва і справа то межа видаляється як помилкова, в іншому випадку виконується ще одна перевірка [8] . Відстань до попередньої (лівої) межі dk має бути більше допустимого мінімуму d min .
d k > d min .
d min = 0.4 * n.
де n - висота зображення слова
В результаті зі списку індексів "кандидатів" W 1 видаляються індекси стовпців, які мають зв'язок з сусідами зліва і справа, формується кінцевий список індексів кордонів W 2 . Графічно це представлено на малюнку 4.10.
Малюнок 4.10 - Зображення слова після обробки
Таким чином, з будь-якої картинки можна отримати набір картинок-символів, які можна розпізнавати за допомогою штучної нейронної мережі. Загальна послідовність кроків алгоритму приведена нижче.

Малюнок 1 - Кроки алгоритму виділення символів
(Анімація: Розмір: 104Кб; Кадрів: 9; Повторів: 15; Затримка: 2сек.)
Висновок
В роботі розглянуті і проаналізовані існуючі методи і програмні засоби для розпізнавання тексту на зображеннях. Також виділені переваги та недоліки методів.
Наведено алгоритм детектування і сегментування тексту на зображеннях. За допомогою наведеного методу, можна виявити текст на зображенні і сегментувати його аж до одного символу. Після чого, кожен символ відправляється на вхід штучної нейронної мережі, яка виступає в якості засобу розв'язання.
Вибір штучної нейронної мережі в якості засобу розв'язання тексту, обумовлений її універсальністю, високою ефективністю і можливістю доповнення іншими орфографіями [9] .
Список джерел
- Как это работает: FineReader – [Электронный ресурс]. – Режим доступа: https://www.ixbt.com/soft/finereader.shtml
- Распознавание автомобильных номеров в деталях – [Электронный ресурс]. – Режим доступа: https://habrahabr.ru/company/recognitor/blog/225913/
- S. Milyaev, O. Barinova and T. Novikova.
Image binarization for end-to-end text understanding in natural images
. // ICDAR. – 2013. – p. 230 – 238. - J. Mata, O. Chum, M. Urban and T. Pajdl
Robust wide baseline stereo from maximally stable extremal regions
. // British Machine Vision Conference. – 2002. – p. 384–393. - X.C. Yin and K. Huang
Robust text detection in natural scene images
. – CoRR. – 2013. – p. 189–196. - H. Chen, S. Tsai, G.Schroth, D. M. Chen, R. Grzeszczuk and B. Girod
Robust text detection in natural images with edge-enhanced maximally stable extremal regions
. // IEEE International Conference on Image Processing – 2011. – p. 332–340. - L. Gomez, D. Karatzas.
Multi-script text extraction from natural scenes
. // ICDAR – 2013. – p. 123–131. - Новиков Ф.А.
Дискретная математика для программистов
. // СПб.: Питер. – 2000. – 304 с. - Хайкин Саймон.
Нейронные сети: полный курс. Второе издание
. – [пер. с англ.]. // М.: Вильямс. – 2006. – 1014 с