
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Обзор современного состояния проблемы
- 2. Постановка задачи
- 3. ПРоцесс распознавания рукописных символов
- 3.1 Предварительная обработка изображений
- 3.2 Сегментация
- 3.3 Класификация
- 3.4 Процесс обучения нейронной сети
- 4. Повышение качества распознавания
- Выводы
- Список источников
Введение
В настоящее время сканирование и сохранение в памяти компьютера текста с твердого носителя является решенной задачей. Это существенно облегчает задачу хранения рукописных и печатных текстов и предоставления доступа к ним различных пользователей. Задача распознавания рукописного текста имеет множество программных решений, однако получить доступ к имеющимся технологиям не представляется возможным, так как технологии распознавания рукописного текста защищены патентами. Поэтому актуально разработать свое программное обеспечение, которое может стать уникальным.
Задача распознавания машинописного текста носит название оптического распознавания символов. В настоящее время существуют высокоточные системы для распознавания машинописных и рукопечатных текстов (например, ABBYY FineReader). Распознавание же рукописных текстов является гораздо более сложной и на данный момент не решённой задачей.
Задача распознавания рукописных цифр является одной из классических задач распознавания образов и имеет значительную практическую ценность. Одним из первых практических применений методов распознавания рукописных цифр стало создание системы чтения ZIP-кодов почты США. Методы распознавания цифр применяются также для решения таких практических задач, как чтение банковских чеков, автоматизированное чтение анкет и др.
1. Обзор современного состояния проблемы
В данном разделе будут рассмотрены основные научные работы связанные с исследованием возможности использования методов распознавания рукописных цифр:
В работе A desicion-theoretic generalization of on-line learning and an application to boosting
Yoav Freund, Robert E Schapire рассматривается алгоритм AdaBoost. Алгоритм AdaBoost (сокр. от adaptive boosting) – алгоритм машинного обучения, предложенный Йоавом Фройндом (Yoav Freund) и Робертом Шапиром (Robert Schapire). Является мета-алгоритмом, в процессе обучения строит композицию из базовых алгоритмов обучения для улучшения их эффективности. AdaBoost является алгоритмом адаптивного бустинга в том смысле, что каждый следующий классификатор строится по объектам, которые плохо классифицируются предыдущими классификаторами. AdaBoost вызывает слабый классификатор в цикле. После каждого вызова обновляется распределение весов, которые отвечают важности каждого из объектов обучающего множества для классификации. На каждой итерации веса каждого неверно классифицированного объекта возрастают, таким образом новый классификатор фокусирует своё внимание
на этих объектах. Экспоненциальная функция потерь слишком сильно увеличивает веса наиболее трудных объектов, на которых ошибаются многие базовые алгоритмы. Однако именно эти объекты чаще всего оказываются шумовыми выбросами. В результате AdaBoost начинает настраиваться на шум, что ведёт к переобучению[1].
В работе Handwritten digit recognition with a back-propagation network
B Boser Le Cun рассматривается применение сверточной нейронной сети. Сверточная сеть LeNet. Одним из вариантов специализированной нейронной сети для распознавания является архитектура сверточной нейронной сети. Основные принципы построения этой архитектуры заключаются в следующем:
- Сеть в целом является многослойным персептроном с прямыми связями.
- Нейроны в нескольких первых слоях имеют 2-мерные локальные рецептивные поля.
- Нейроны-детекторы признаков формируют 2-мерные карты признаков способом, подобным математической операции свертки (convolution). Над картами признаков выполняется процедура уменьшения пространственной разрешающей способности.
- Входом первого слоя нейронов-детекторов признаков является входное изображение. Входом каждого из следующих слоев детекторов признаков являются карты признаков с уменьшенным пространственным разрешением, сформированные предыдущим слоем детекторов признаков[2].
В сети LeNet5 первый слой насчитывает 6 нейронов с квадратным рецептивным полем 5×5. Выходы нейронов первого слоя формируют первую карту признаков с размерностью 6×28×28. Выходом первого слоя группировки признаков является карта признаков с размерностью 6×14×14. Второй слой детекторов признаков содержит 16 нейронов и формирует карту признаков с размерностью 16×10×10. Нейроны этого слоя имеют рецептивные поля 5×5 и получают входные данные с первой карты признаков. Второй слой группировки признаков также уменьшает вдвое размер карты признаков, соответственно на его выходе вторая карта признаков имеет размерность 16×5×5. Эта карта признаков является входом 100 нейронов следующего слоя. Последний слой имеет 10 нейронов – по одному на каждый класс, который должен распознаваться[3].
В работе LIBSVM: A library for support vector machines
Chih-Chung Chang, Chih-Jen Lin предложен метод опорных векторов. Метод опорных векторов (англ. SVM, support vector machine) – набор схожих алгоритмов обучения с учителем, использующихся для задач классификации и регрессионного анализа. Принадлежит семейству линейных классификаторов и может также рассматриваться как специальный случай регуляризации по Тихонову. Особым свойством метода опорных векторов является непрерывное уменьшение эмпирической ошибки классификации и увеличение зазора, поэтому метод также известен как метод классификатора с максимальным зазором[4].
Основная идея метода — перевод исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с максимальным зазором в этом пространстве. Две параллельных гиперплоскости строятся по обеим сторонам гиперплоскости, разделяющей классы. Разделяющей гиперплоскостью будет гиперплоскость, максимизирующая расстояние до двух параллельных гиперплоскостей. Алгоритм работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора[5].
В книге Neural Networks and Deep Learning
Майкла Нельсона рассматривается применение нейронной сети «Персептрон». Проектирование входных и выходных слоев нейросети – достаточно просто занятие. Для примера, предположим, что мы пытаемся определить, изображена ли рукописная 9
на изображении или нет. Естественным способом проектирования сети является кодирование интенсивностей пикселей изображения во входные нейроны. Если изображение имеет размер 64х64, то мы имеем 4,096=64х64 входных нейрона. Выходной слой имеет один нейрон, который содержит выходное значение, если оно больше, чем 0.5, то на изображении 9
, иначе нет. В то время как проектирование входных и выходных слоев – достаточно простая задача, выбор архитектуры скрытых слоев – искусство. Исследователи разработали множество эвристик проектирования скрытых слоев, например, такие, которые помогают скомпенсировать количество скрытых слоев против времени обучения сети. До сих пор мы использовали нейронные сети, в которых выход из одного слоя – использовался как сигнал для следующего, такие сети называются прямыми нейронными сетями или сетями прямого распространения(FeedForward). Однако существуют и другие модели нейронных сетей, в которых возможны петли обратной связи. Эти модели называются рекуррентными нейронными сетями(RecurrentNeuralNetwork). Рекуррентные нейронные сети были менее влиятельными, чем сети с прямой связью, отчасти потому, что алгоритмы обучения для рекуррентных сетей (по крайней мере на сегодняшний день) менее эффективны[6].
2. Постановка задачи
Цель магистерской диссертационной работы: исследование и разработка метода распознавания рукописных цифр.
Для достижения поставленной цели необходимо выполнить следующие задачи:
- Проанализировать современное состояние проблемы распознавания рукописных цифр.
- Провести анализ современных методов распознавания рукописных цифр.
- Разработать метод распознавания рукописных цифр на основе сегментации изображения и обученной нейронной сети.
- Предложить модификацию предобработки изображения, которая поможет улучшить распознавание рукописных цифр.
- Разработка программного обеспечения для распознавания рукописных цифр на основе улучшеной предобработки изображения и обученной нейронной сети.
- Проведения анализа эффективности разработанного метода и существующих аналогов распознавания.
3. Процесс распознавания рукописных символов
3.1 Предварительная обработка изображений
На этапе предварительной обработки производится улучшение качества изображения (image enhancement) приведение изображения к виду, наиболее подходящему для дальнейшей автоматической работы с ним. Улучшение качества изображения с целью дальнейшего распознавания текста включает в себя удаление дефектов изображения и отделение текста от фона. Удаление дефектов осуществляется стандартными методами обработки изображений. Наиболее часто для удаления шума используются фильтр Гаусса для подавления высокочастотного шума и медианный фильтр для удаления шума «соль и перец»[7] по формуле (1).

Такое преобразование изображение позволяет в дальнейшем использовать анализ связных компонент, контуров, скелетов и т.д. Наиболее часто использующимся методом отделения текста от фона служит пороговая бинаризация (threshold binarization). Пусть дано изображение, I(i, j) яркость пикселя с координатами (i, j). Пороговой бинаризацией изображения называется попиксельное преобразование f (i, j), рассчитываемое по формуле (2).
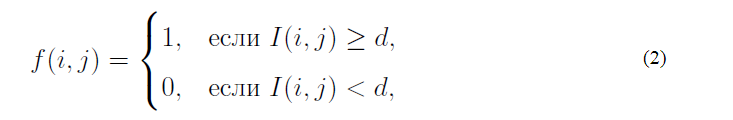
где d называется порогом бинаризации.
Обычно на гистограмме яркости изображения текста наблюдается два пика: высокий пик в области светлых пикселей (соответствует фону, то есть бумаге) и пик пониже в области тёмных (соответствует тексту). Поэтому задача поиска порогового значения яркости, т. е. такого, что пиксели с яркостью выше этого значения (фон) будут считаться чёрными, а ниже (текст) белыми (такое «инвертирование» цвета делается в целях упрощения применения многих алгоритмов в дальнейшем), является задачей поиска оптимального значения между двумя пиками гистограммы. Для решения этой задачи существуют хорошо изученные методы, например, метод Оцу[8] и его вариации. Результатом этапа предварительной обработки изображения является бинарное изображение белых цифр на чёрном фоне, соответствующих исходному изображению.
3.2 Сегментация
На этапе сегментации происходит выделение отдельных цифр на изображении, полученном на этапе предварительной обработки. Результатом этапа сегментации должна быть последовательность изображений отдельных цифр, которые далее поступают на вход процедуре извлечения признаков. Такая стратегия, называемая стратегией явной сегментации, является более предпочтительной в задаче распознавания последовательностей рукописных цифр, чем неявная сегментация, при которой выделение цифр, извлечение признаков и классификация проходят параллельно[9].
Выделение групп цифр. После отделения текста от фона на этапе предварительной обработки для выделения групп цифр становится возможным использование анализа связных компонент. Если рассматривать белые пиксели как вершины графа, а рёбрами соединять вершины, соответствующие соседним пикселям, становится возможным выделять компоненты связности, соответствующие одной или нескольким пересекающимся цифрам. Для выделения связных компонент существуют стандартные и широко известные алгоритмы поиска, например, поиск в глубину и поиск в ширину.
Разделение сцепленных цифр. После выделения компоненты связности на графе изображения требуется принять решение, является ли эта компонента одной или несколькими цифрами, и если несколькими, как следует их разделить. Обычно сегментация компоненты связности на цифры происходит в два этапа: сначала генерируются возможные способы сегментации компоненты связности, а потом из них выбирается наилучший. Построение возможных способов сегментации обычно проводится эвристическими методами. Выбором наилучшего метода сегментации может заниматься как подсистема сегментации (в этом случае на вход подсистеме извлечения признаков и классификации поступает только один набор входных данных), так и подсистема классификации (в этом случае подсистемам извлечения признаков и классификации поступает на вход несколько наборов входных данных, и решение о том, какая сегментация была выполнена правильно, принимается по результатам распознавания). Для построения явной сегментации чаще всего используется два вида представления данных: контур и скелет. Контуром объекта называется множество всех пикселей, принадлежащих объекту и имеющих соседний пиксель, не принадлежащий объекту. Крайне правая и крайне левая точки контура делят его на верхний и нижний контуры (рисунок 1). Область выпуклости контура называется долиной, а область вогнутости холмом.
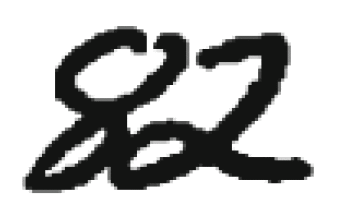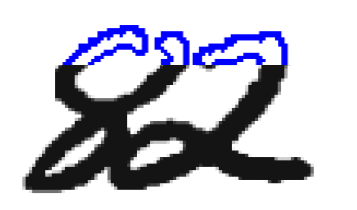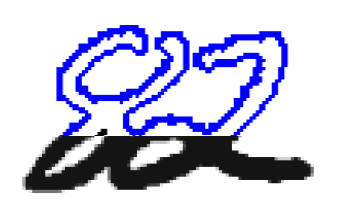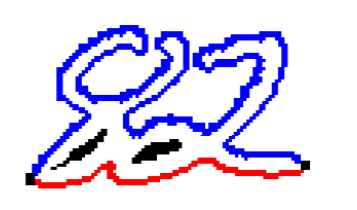
Рисунок 1 – Компонента связности
(анимация: 3 кадра, 7 циклов повторения, 31 килобайт)
Компонента связности, состоящая из двух пересекающихся цифр и её контур. Синим выделен верхний контур, красным нижний. Методы сегментации на основе анализа контуров ранее выделенных компонент связности приводятся в работах [10, 11, 12]. В этих методах на контурах компонент связности, исходя из некоторых соображений, выбираются потенциальные точки разреза, через которые затем проводятся линии разреза, удовлетворяющие определённым условиям. В работе [10] возможные точки разреза ставятся там, где расстояние между верхним и нижним контурами превосходит порог, а наилучший разрез выбирается как кратчайший путь в графе с вершинами на возможных точках разреза. В работе [11] точки возможного разреза выбираются эвристически как точки, в которых контур делает наибольший поворот направо при обходе против часовой стрелки.
3.3 Классификация
В существующих системах OCR (Optical Character Recognition) используются разнообразные алгоритмы классификации, то есть отнесения признаков к различным классам. Они существенно различаются в зависимости от принятых наборов признаков и применяемой по отношению к ним стратегии классификации.
Для признаковой классификации символов необходимо, в первую очередь, сформировать набор эталонных векторов признаков по каждому из распознаваемых символов. Для этого на стадии обучения оператор или разработчик вводит в систему OCR большое количество образцов начертания символов, сопровождаемых указанием значения символа. Для каждого образца система выделяет признаки и сохраняет их в виде соответствующего вектора признаков вектора признаков. Набор векторов признаков, описывающих символ, называется классом, или кластером.
Задачей собственно процедуры классификации или распознавания, выполняемой в момент предъявления системе тестового изображения символа, является определение того, к какому из ранее сформированных классов принадлежит вектор признаков, полученный для данного символа. Алгоритмы классификации основаны на определении степени близости набора признаков рассматриваемого символа к каждому из классов. Правдоподобие получаемого результата зависит от выбранной метрики пространства признаков. Наиболее известной метрикой признакового пространства является традиционное Евклидово расстояние, рассчитываемое по формуле (3).

где FLji – i-й признак из j-го эталонного вектора; Fli – i-й признак тестируемого изображения символа.
При классификации по методу ближайшего соседа символ будет отнесен к классу, вектор признаков которого наиболее близок к вектору признаков тестируемого символа. Следует учитывать, что затраты на вычисления в таких системах возрастают с увеличением количества используемых признаков и классов[13].
3.4 Процесс обучения нейронной сети
Обучение нейронной сети – это процесс, в котором параметры нейронной сети настраиваются посредством моделирования среды, в которую эта сеть встроена. Тип обучения определяется способом подстройки параметров. Различают алгоритмы обучения с учителем и без учителя.
Процесс обучения с учителем представляет собой предъявление сети выборки обучающих примеров. Каждый образец подается на входы сети, затем проходит обработку внутри структуры НС, вычисляется выходной сигнал сети, который сравнивается с соответствующим значением целевого вектора, представляющего собой требуемый выход сети.
Для того, чтобы нейронная сети была способна выполнить поставленную задачу, ее необходимо обучить. Процесс обучения нейронной сети изображен на рисунке 2.
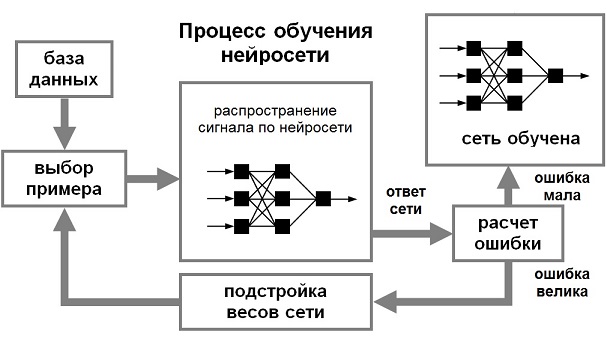
Рисунок 2 – Процесс обучения нейронной сети
Различают алгоритмы обучения с учителем и без учителя. Процесс обучения с учителем представляет собой предъявление сети выборки обучающих примеров. Каждый образец подается на входы сети, затем проходит обработку внутри структуры НС, вычисляется выходной сигнал сети, который сравнивается с соответствующим значением целевого вектора, представляющего собой требуемый выход сети. Затем по определенному правилу вычисляется ошибка, и происходит изменение весовых коэффициентов связей внутри сети в зависимости от выбранного алгоритма. Векторы обучающего множества предъявляются последовательно, вычисляются ошибки и веса подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня.
При обучении без учителя обучающее множество состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса сети так, чтобы получались согласованные выходные векторы, т.е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы. Процесс обучения, следовательно, выделяет статистические свойства обучающего множества и группирует сходные векторы в классы. Предъявление на вход вектора из данного класса даст определенный выходной вектор, но до обучения невозможно предсказать, какой выход будет производиться данным классом входных векторов. Следовательно, выходы подобной сети должны трансформироваться в некоторую понятную форму, обусловленную процессом обучения. Это не является серьезной проблемой. Обычно не сложно идентифицировать связь между входом и выходом, установленную сетью. Для обучения нейронных сетей без учителя применяются сигнальные метод обучения Хебба и Ойа[14].
Общий алгоритм распознавания рукописных символов выглядит следующим образом и представлен на рисунке 3.
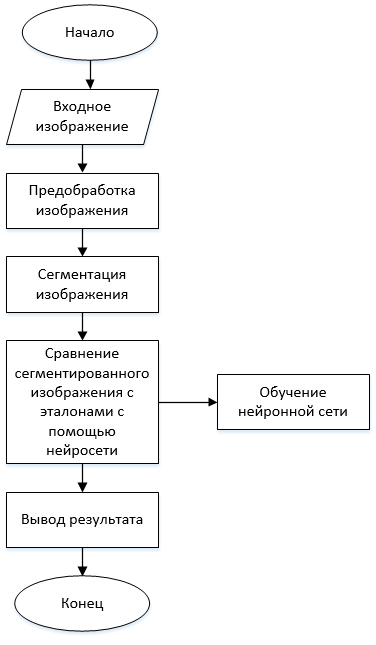
Рисунок 3 – Общий алгоритм распознавания
4. Повышение качества распознавания
Для повышения качества распознавания применяются различные методы предобработки изображений с текстом, например, шумоподавление [15]. Источниками шумов на изображении могут быть:
- аналоговый шум:
- грязь, пыль;
- царапины;
- цифровой шум:
- тепловой шум матрицы;
- шум переноса заряда;
- шум квантования АЦП.
При цифровой обработке изображений применяется пространственное шумоподавление. Выделяют следующие методы:
- адаптивная фильтрация – линейное усреднение пикселей по соседним;
- медианная фильтрация;
- математическая морфология;
- размытие по Гауссу;
- методы на основе дискретного вейвлет-преобразования;
- метод главных компонент;
- анизотропная диффузия;
- фильтры Винера.
Применение данных методов повышает качество распознавания изображения и повышает вероятность правильного определения символов.
Выводы
Была рассмотрена основная задача оффлайн-распознавания рукописных цифр. Выделены основные проблемы при распознавании, также рассмотрена разница между распознаванием рукописных символов и рукописных цифр. Были описаны существующие методы оффлайн-распознавания и выделены 3 самых известных алгоритма. У каждого из алгоритмов описана основная структура работы, выделены достоинства и недостатки. Автоматическое зрительное восприятие на сегодняшний день не достигает совершенства человеческого восприятия текста. Главная причина этого заключается в неумении строить достаточно полные и семантически выразительные компьютерные модели предметной области. Также были рассмотрены и выделены основные методы оптимизации для улучшения качества распознавания.
Проанализировав существующие методы распознавания рукописных цифр, можно сделать вывод, что лучше всего использовать метод распознавания эталонов с помощью нейронной сети, так как он объединяет в себе достоинства многих методов и благодаря этому является достаточно гибким чтобы применить его при распознавании рукописных цифр.
Список источников
- Yoav Freund и Robert E Schapire. «A desicion-theoretic generalization of on-line learning and an application to boosting». В: Computational learning theory. Springer. / Yoav Freund. – 1995. – p. 23-37.
- B Boser Le Cun и др. «Handwritten digit recognition with a back-propagation network». В: Advances in neural information processing systems. Citeseer. 1990.
- Chih-Chung Chang и Chih-Jen Lin. «LIBSVM: A library for support vector machines». В: ACM Transactions on Intelligent Systems and Technology 2 (3 2011).
- Машина опорных векторов – [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/index.php?title=SVM
- Использование нейронных сетей для распознавания рукописных цифр – [Электронный ресурс]. – Режим доступа: https://ai-science.ru/iz-pesochnicy-ispolzovanie-nejronnyx-setej-dlya-raspoznavaniya-rukopisnyx-cifr-chast-1/
- R´ejean Plamondon и Sargur N Srihari. «Online and off-line handwriting recognition: a comprehensive survey». В: Pattern Analysis and Machine Intelligence / R´ejean Plamondon. – IEEE Transactions, – 2000. – p. 63-84.
- Л Шапиро и Дж Стокман. «Компьютерное зрение». // В: М.: Бином. – 2006. – с. 8.
- Nobuyuki Otsu. «A threshold selection method from gray-level histograms». / Nobuyuki Otsu. – 1975. – p. 23-27.
- Felipe C Ribas и др. «Handwritten digit segmentation: a comparative study». В: International Journal on Document Analysis and Recognition (IJDAR) 16.2 / Felipe C Ribas. – 2013. – p. 127-137.
- Hiromichi Fujisawa, Yasuaki Nakano и Kiyomichi Kurino. «Segmentation methods for character recognition: from segmentation to document structure analysis». В: Proceedings of the IEEE 80.7 (1992), p. 1079-1092.
- Zhixin Shi и Venu Govindaraju. «Segmentation and recognition of connected handwritten numeral strings». В: Pattern Recognition 30.9 1997. – p. 1501-1504.
- R Fenrich и S Krishnamoorthy. «Segmenting diverse quality handwritten digit strings in near real-time». R Fenrich. – 1990. – p. 523-537.
- Оптическое распознавание символов – [Электронный ресурс]. – Режим доступа: http://wiki.technicalvision.ru/index.php/Оптическое_ распознавание_символов_(OCR)
- Обучение нейронной сети – [Электронный ресурс]. – Режим досутпа: http://neuronus.com/theory/240-algoritmy-obucheniya-iskusstvennykh-nejronnykh-setej
- Шлезингер М., Главач В. Структурное распознавание / М. Шлезингер В. Главач. – Киев: Наукова думка. – 2006. – 300 с.
Важное замечание
На момент написания данного реферата магистерская работа еще является не завершенной. Предполагаемая дата завершения: май 2017 г., ввиду чего полный текст работы, а также материалы по теме могут быть получены у автора или его руководителя только после указанной даты.