
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Огляд сучасного стану проблеми
- 2. Постановка задачі
- 3. Процес розпізнавання рукописних символів
- 3.1 Попередня обробка зображень
- 3.2 Сегментація
- 3.3 Класифікація
- 3.4 Процес навчання нейронної мережі
- 4. Методи оптимізації розпізнавання
- Висновки
- Список літератури
Вступ
В даний час сканування і збереження в пам'яті комп'ютера тексту з твердого носія є вирішеним завданням. Це істотно полегшує завдання зберігання рукописних і друкованих текстів та надання доступу до них різних користувачів. Завдання розпізнавання рукописного тексту має безліч програмних рішень, однак отримати доступ до наявних технологій не представляється можливим, тому що технології розпізнавання рукописного тексту захищені патентами. Тому актуально розробити своє програмне забезпечення, яке може стати унікальним.
Завдання розпізнавання машинописного тексту носить назву оптичного розпізнавання символів. В даний час існують високоточні системи для розпізнавання машинописних і рукопечатних текстів (наприклад, ABBYY FineReader). Розпізнавання ж рукописних текстів є набагато складнішою і на даний момент не вирішеною задачею.
Завдання розпізнавання рукописних цифр є однією з класичних задач розпізнавання образів і має значну практичну цінність. Одним з перших практичних застосувань методів розпізнавання рукописних цифр стало створення системи читання ZIP-кодів пошти США. Методи розпізнавання цифр застосовуються також для вирішення таких практичних завдань, як читання банківських чеків, автоматизоване читання анкет та ін.
1. Огляд сучасного стану проблеми
В даному розділі будуть розглянуті основні наукові роботи пов'язані з дослідженням можливості використання методів розпізнавання рукописних цифр:
У роботі A desicion-theoretic generalization of on-line learning and an application to boosting
Yoav Freund, Robert E Schapire розглядається алгоритм AdaBoost. Алгоритм AdaBoost (скор. Від adaptive boosting) – алгоритм машинного навчання, запропонований Йоав Фройнд (Yoav Freund) і Робертом Шапіро (Robert Schapire). Є мета-алгоритмом, в процесі навчання будує композицію з базових алгоритмів навчання для поліпшення їх ефективності. AdaBoost є алгоритмом адаптивного бустінга в тому сенсі, що кожен наступний класифікатор будується по об'єктах, які погано класифікуються попередніми класифікаторами. AdaBoost викликає слабкий класифікатор в циклі. Після кожного виклику оновлюється розподіл ваг, які відповідають важливості кожного з об'єктів навчальної вибірки для класифікації. На кожній ітерації ваги кожного невірно класифікованого об'єкта зростають, таким чином новий класифікатор «фокусує свою увагу» на цих об'єктах. Експоненціальна функція втрат занадто сильно збільшує ваги найбільш важких об'єктів, на яких помиляються багато базові алгоритми. Однак саме ці об'єкти найчастіше виявляються шумовими викидами. В результаті AdaBoost починає налаштовуватися на шум, що веде до перенавчання [1].
У роботі Handwritten digit recognition with a back-propagation network
B Boser Le Cun розглядається застосування сверточное нейронної мережі. Звурточна мережа LeNet. Одним з варіантів спеціалізованої нейронної мережі для розпізнавання є архітектура зверточної нейронної мережі. Основні принципи побудови цієї архітектури полягають в наступному:
- Мережа в цілому є багатошаровим персептроном з прямими зв'язками.
- Нейрони в декількох перших шарах мають 2-мірні локальні рецептивні поля.
- Нейрони-детектори ознак формують 2-мірні карти ознак способом, подібним математичної операції згортки (convolution). Над картами ознак виконується процедура зменшення просторової роздільної здатності.
- Входом першого шару нейронів-детекторів ознак є вхідне зображення. Входом кожного з наступних шарів детекторів ознак є карти ознак з зменшеним просторовим дозволом, сформовані попереднім шаром детекторів ознак[2].
У мережі LeNet5 перший шар налічує 6 нейронів з квадратним рецептивних полем 5 × 5. Виходи нейронів першого шару формують першу карту ознак з розмірністю 6 × 28 × 28. Виходом першого шару угруповання ознак є карта ознак з розмірністю 6 × 14 × 14. Другий шар детекторів ознак містить 16 нейронів і формує карту ознак з розмірністю 16 × 10 × 10. Нейрони цього шару мають рецептивні поля 5 × 5 і отримують вхідні дані з першої карти ознак. Другий шар угруповання ознак також зменшує вдвічі розмір карти ознак, відповідно на його виході друга карта ознак має розмірність 16 × 5 × 5. Ця карта ознак є входом 100 нейронів наступного шару. Останній шар має 10 нейронів - по одному на кожен клас, який повинен розпізнаватися[3].
У роботі «LIBSVM: A library for support vector machines» Chih-Chung Chang, Chih-Jen Lin запропонований метод опорних векторів. Метод опорних векторів (англ. SVM, support vector machine) – набір схожих алгоритмів навчання з учителем, що використовуються для задач класифікації та регресійного аналізу. Належить сімейству лінійних класифікаторів і може також розглядатися як спеціальний випадок регуляризації по Тихонову. Особливою властивістю методу опорних векторів є невпинне зменшення емпіричної помилки класифікації і збільшення зазору, тому метод також відомий як метод класифікатора з максимальним зазором[4].
Основна ідея методу – переклад вихідних векторів в простір більш високої розмірності і пошук розділяє гиперплоскости з максимальним зазором в цьому просторі. Дві паралельні гіперплощини будуються по обидва боки гіперплощини, що розділяє класи. Розділяє гиперплоскостью буде гіперплоскость, максимізує відстань до двох паралельних гіперплоскостей. Алгоритм працює в припущенні, що чим більша різниця або відстань між цими паралельними гіперплоскостямі, тим менше буде середня помилка класифікатора[5].
У книзі Neural Networks and Deep Learning
Майкла Нельсона розглядається застосування нейронної мережі Персептрон
. Проектування вхідних і вихідних шарів нейромережі – досить просто заняття. Для прикладу, припустимо, що ми намагаємося визначити, зображена чи рукописна 9
на зображенні чи ні. Природним способом проектування мережі є кодування інтенсивностей пікселів зображення у вхідні нейрони. Якщо зображення має розмір 64х64, то ми маємо 4,096 = 64х64 вхідних нейрона. Вихідний шар має один нейрон, який містить вихідне значення, якщо воно більше, ніж 0.5, то на зображенні 9
, інакше немає. У той час як проектування вхідних і вихідних шарів – досить просте завдання, вибір архітектури прихованих шарів - мистецтво. Дослідники розробили безліч евристик проектування прихованих шарів, наприклад, такі, які допомагають компенсувати кількість прихованих шарів проти часу навчання мережі. До сих пір ми використовували нейронні мережі, в яких вихід з одного шару – використовувався як сигнал для наступного, такі мережі називаються прямими нейронними мережами або мережами прямого поширення (FeedForward). Однак існують і інші моделі нейронних мереж, в яких можливі петлі зворотного зв'язку. Ці моделі називаються рекурентними нейронними мережами (RecurrentNeuralNetwork). Рекурентні нейронні мережі були менш впливовими, ніж мережі з прямим зв'язком, почасти тому, що алгоритми навчання для рекурентних мереж (принаймні на сьогоднішній день) менш ефективні[6].
2. Постановка задачі
Мета магістерської дисертаційної роботи: дослідження і розробка методу розпізнавання рукописних цифр.
Для досягнення поставленої мети необхідно виконати наступні завдання:
- Проаналізувати сучасний стан проблеми розпізнавання рукописних цифр.
- Провести аналіз сучасних методів розпізнавання рукописних цифр.
- Розробити метод розпізнавання рукописних цифр на основі сегментації зображення і навченої нейронної мережі.
- Запропонувати модифікацію предобработки зображення, яка допоможе поліпшити розпізнавання рукописних цифр.
- Розробка програмного забезпечення для розпізнавання рукописних цифр на основі сегментації зображення і навченої нейронної мережі.
- Проведення аналізу ефективності розробленого методу і існуючих аналогів розпізнавання.
3. Процес розпізнавання рукописних символів
3.1 Попередня обробка зображень
На етапі попередньої обробки проводиться поліпшення якості зображення (image enhancement) приведення зображення до виду, найбільш підходящому для подальшої автоматичної роботи з ним. Поліпшення якості зображення з метою подальшого розпізнавання тексту включає в себе видалення дефектів зображення і відділення тексту від фону. Видалення дефектів здійснюється стандартними методами обробки зображень. Найбільш часто для видалення шуму використовуються фільтр Гаусса для придушення високочастотного шуму і медіанний фільтр для видалення шуму сіль і перець
[7] за формулою (1).

Таке перетворення зображення дозволяє в подальшому використовувати аналіз зв'язкових компонент, контурів, скелетів і т.д. Найбільш часто використовується методом відділення тексту від фону служить порогова бінаризація (threshold binarization). Нехай дано зображення, I (i, j) яскравість пікселя з координатами (i, j). Порогової бінаризація зображення називається попіксельне перетворення f (i, j), яка розраховується за формулою (2).
де d називається порогом бінарізації.
Зазвичай на гістограмі яскравості зображення тексту спостерігається два піки: високий пік в області світлих пікселів (відповідає фону, тобто папері) і пік нижче в області темних (відповідає тексту). Тому завдання пошуку порогового значення яскравості, т. Е. Такого, що пікселі з яскравістю вище цього значення (фон) будуть вважатися чорними, а нижче (текст) білими (таке «інвертування» кольору робиться з метою спрощення застосування багатьох алгоритмів в подальшому), є завданням пошуку оптимального значення між двома піками гістограми. Для вирішення цього завдання існують добре вивчені методи, наприклад, метод Оцу[8] і його варіації. Результатом етапу попередньої обробки зображення є бінарне зображення білих цифр на чорному тлі, відповідних вихідного зображення.
3.2 Сегментація
На етапі сегментації відбувається виділення окремих цифр на зображенні, отриманому на етапі попередньої обробки. Результатом етапу сегментації повинна бути послідовність зображень окремих цифр, які далі надходять на вхід процедурі вилучення ознак. Така стратегія, звана стратегією явною сегментації, є більш кращою в задачі розпізнавання послідовностей рукописних цифр, ніж неявна сегментація, при якій виділення цифр, витяг ознак і класифікація проходять паралельно[9].
Виділення груп цифр. Після відділення тексту від фону на етапі попередньої обробки для виділення груп цифр стає можливим використання аналізу зв'язкових компонент. Якщо розглядати білі пікселі як вершини графа, а ребрами з'єднувати вершини, відповідні сусіднім пікселям, стає можливим виділяти компоненти зв'язності, відповідні одній або декільком пересічних цифрам. Для виділення зв'язкових компонент існують стандартні і широко відомі алгоритми пошуку, наприклад, пошук в глибину і пошук в ширину.
Поділ зчеплених цифр. Після виділення компоненти зв'язності на графі зображення потрібно прийняти рішення, чи є ця компонента однією або декількома цифрами, і якщо кількома, як слід їх розділити. Зазвичай сегментація компоненти зв'язності на цифри відбувається в два етапи: спочатку генеруються можливі способи сегментації компоненти зв'язності, а потім з них вибирається найкращий. Побудова можливих способів сегментації зазвичай проводиться евристичними методами. Вибором найкращого методу сегментації може займатися як підсистема сегментації (в цьому випадку на вхід підсистемі вилучення ознак і класифікації надходить тільки один набір вхідних даних), так і підсистема класифікації (в цьому випадку підсистем вилучення ознак і класифікації надходить на вхід кілька наборів вхідних даних, і рішення про те, яка сегментація була виконана правильно, приймається за результатами розпізнавання). Для побудови явною сегментації найчастіше використовується два види подання даних: контур і скелет. Контуром об'єкта називається безліч всіх пікселів, що належать об'єкту і мають сусідній піксель, що не належить об'єкту. Крайня права і вкрай ліва точки контуру ділять його на верхній і нижній контури (малюнок 1). Область опуклості контуру називається долиною, а область угнутості пагорбом.
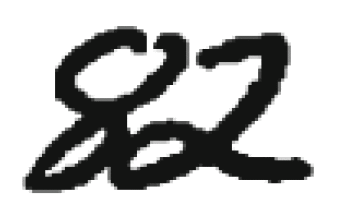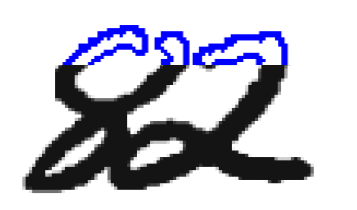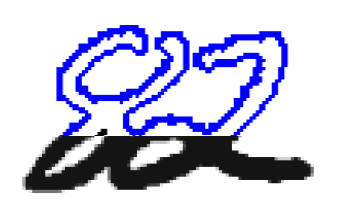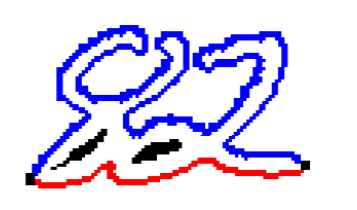
Малюнок 1 – Компонента зв'язності
(анімація: 3 кадрb, 7 циклів повторення, 31 кілобайт)
Компонента зв'язності, що складається з двох пересічних цифр і її контуру. Синім виділено верхній контур, червоним нижній. Методи сегментації на основі аналізу контурів раніше виділених компонент зв'язності наводяться в роботах[10, 11, 12]. У цих методах на контурах компонент зв'язності, виходячи з деяких міркувань, вибираються потенційні точки розрізу, через які потім проводяться лінії розрізу, що задовольняють певним умовам. В роботі[10] можливі точки розрізу ставляться там, де відстань між верхнім і нижнім контурами перевершує поріг, а найкращий розріз вибирається як найкоротший шлях в графі з вершинами на можливих точках розрізу. В роботі[11] точки можливого розрізу вибираються евристичний як точки, в яких контур робить найбільший поворот направо при обході проти годинникової стрілки.
3.3 Класифікація
В існуючих системах OCR (Optical Character Recognition) використовуються різноманітні алгоритми класифікації, тобто віднесення ознак до різних класів. Вони істотно розрізняються в залежності від прийнятих наборів ознак і застосовуваної по відношенню до них стратегії класифікації.
Для признаковой класифікації символів необхідно, в першу чергу, сформувати набір еталонних векторів ознак по кожному з розпізнаються символів. Для цього на стадії навчання оператор або розробник вводить в систему OCR велику кількість зразків накреслення символів, супроводжуваних зазначенням значення символу. Для кожного зразка система виділяє ознаки і зберігає їх у вигляді відповідного вектора ознак вектора ознак. Набір векторів ознак, що описують символ, називається класом, або кластером.
Завданням власне процедури класифікації або розпізнавання, виконуваної в момент пред'явлення системі тестового зображення символу, є визначення того, до якого з раніше сформованих класів належить вектор ознак, отриманий для даного символу. Алгоритми класифікації засновані на визначенні ступеня близькості набору ознак розглянутого символу до кожного з класів. Правдоподібність одержуваного результату залежить від обраної метрики простору ознак. Найбільш відомою метрикою простору ознак є традиційне Евклідова відстань, яка розраховується за формулою (3).

де FLji – i-й признак з j-го еталонного вектору; Fli – i-й ознак тестованого зображення символу.
При класифікації за методом найближчого сусіда символ буде віднесений до класу, вектор ознак якого найбільш близький до вектору ознак тестованого символу. Слід враховувати, що витрати на обчислення в таких системах зростають зі збільшенням кількості використовуваних ознак і класів[13].
3.4 Процес навчання нейронної мережі
Навчання нейронної мережі – це процес, в якому параметри нейронної мережі настроюються за допомогою моделювання середовища, в яку ця мережа вбудована. Тип навчання визначається способом підстроювання параметрів. Розрізняють алгоритми навчання з вчителем і без вчителя.
Процес навчання з учителем є пред'явлення мережі вибірки навчальних прикладів. Кожен зразок подається на входи мережі, потім проходить обробку всередині структури НС, обчислюється вихідний сигнал мережі, який порівнюється з відповідним значенням цільового вектора, що представляє собою необхідний вихід мережі.
Для того, щоб нейронна мережі була здатна виконати поставлене завдання, її необхідно навчити. Процес навчання нейронної мережі зображений на малюнку 2.
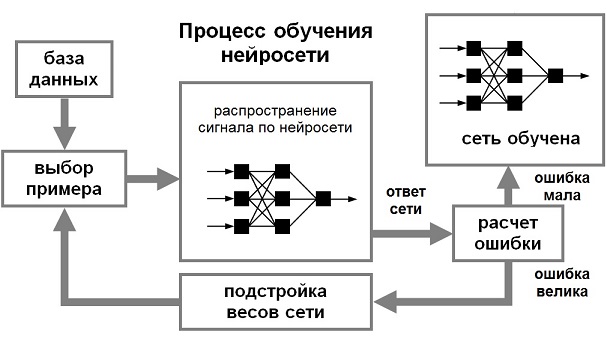
Малюнок 2 – Процес навчання нейронної мережі
Розрізняють алгоритми навчання з вчителем і без вчителя. Процес навчання з учителем є пред'явлення мережі вибірки навчальних прикладів. Кожен зразок подається на входи мережі, потім проходить обробку всередині структури НС, обчислюється вихідний сигнал мережі, який порівнюється з відповідним значенням цільового вектора, що представляє собою необхідний вихід мережі. Потім за певним правилом обчислюється помилка, і відбувається зміна вагових коефіцієнтів зв'язків всередині мережі в залежності від обраного алгоритму. Вектори навчальної множини пред'являються послідовно, обчислюються помилки і ваги підлаштовуються для кожного вектора до тих пір, поки помилка по всьому навчальному масиву не досягне прийнятного рівня.
При навчанні без учителя навчальну множину складається лише з вхідних векторів. Навчальний алгоритм підлаштовує ваги мережі так, щоб виходили узгоджені вихідні вектори, тобто щоб пред'явлення досить близьких вхідних векторів давало однакові виходи. Процес навчання, отже, виділяє статистичні властивості навчальної множини і групує подібні вектори в класи. Пред'явлення на вхід вектора з даного класу дасть певний вихідний вектор, але до навчання неможливо передбачити, який вихід буде проводитися даним класом вхідних векторів. Отже, виходи подібної мережі повинні трансформуватися в деяку зрозумілу форму, зумовлену процесом навчання. Це не є серйозною проблемою. Зазвичай не складно ідентифікувати зв'язок між входом і виходом, встановлену мережею. Для навчання нейронних мереж без вчителя застосовуються сигнальні метод навчання Хебба та Ойа[14].
Загальний алгоритм розпізнавання рукописних символів виглядає наступним чином і представлений на малюнку 3.
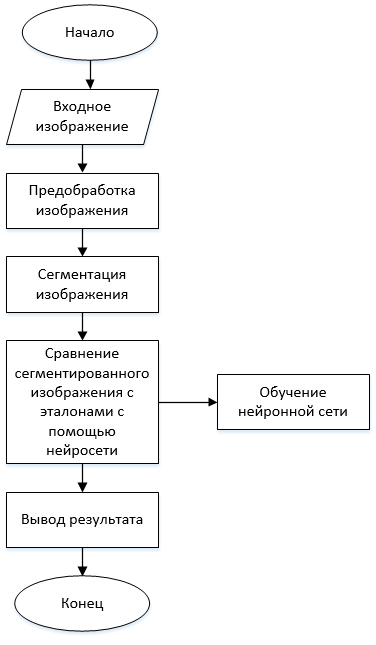
Малюнок 3 – Загальний алгоритм розпізнавання
4. Підвищення якості розпізнавання
Для підвищення якості розпізнавання застосовуються різні методи попередньої обробки зображень з текстом, наприклад, шумозаглушення[15]. Джерелами шумів на зображенні можуть бути:
- аналоговий шум:
- бруд, пил;
- подряпини;
- цифровий шум:
- тепловий шум матриці;
- шум переносу заряду;
- шум квантування АЦП.
При цифровій обробці зображень застосовується просторове шумозаглушення. Виділяють наступні методи:
- адаптивна фільтрація - лінійне усереднення пікселів по сусідніх;
- медіанна фільтрація;
- математична морфологія;
- розмиття по Гаусу;
- методи на основі дискретного вейвлет-перетворення;
- метод головних компонент;
- анізотропна дифузія;
- фільтри Вінера.
Застосування даних методів підвищує якість розпізнавання зображення і підвищує ймовірність правильного визначення символів.
Висновки
Була розглянута основна задача оффлайн-розпізнавання рукописних цифр. Виділено основні проблеми при розпізнаванні, також розглянута різниця між розпізнаванням рукописних символів і рукописних цифр. Були описані існуючі методи оффлайн-розпізнавання і виділені 3 найвідоміших алгоритму. У кожного з алгоритмів описана основна структура роботи, виділені переваги і недоліки. Автоматичне зорове сприйняття на сьогоднішній день не досягає досконалості людського сприйняття тексту. Головна причина цього полягає в невмінні будувати досить повні і семантично виразні комп'ютерні моделі предметної області. Також були розглянуті та виділені основні методи оптимізації для поліпшення якості розпізнавання.
Проаналізувавши існуючі методи розпізнавання рукописних цифр, можна зробити висновок, що найкраще використовувати метод розпізнавання еталонів за допомогою нейронної мережі, так як він об'єднує в собі переваги багатьох методів і завдяки цьому є достатньо гнучким щоб застосувати його при розпізнаванні рукописних цифр.
Список літератури
- Yoav Freund и Robert E Schapire. «A desicion-theoretic generalization of on-line learning and an application to boosting». В: Computational learning theory. Springer. / Yoav Freund. – 1995. – p. 23-37.
- B Boser Le Cun и др. «Handwritten digit recognition with a back-propagation network». В: Advances in neural information processing systems. Citeseer. 1990.
- Chih-Chung Chang и Chih-Jen Lin. «LIBSVM: A library for support vector machines». В: ACM Transactions on Intelligent Systems and Technology 2 (3 2011).
- Машина опорных векторов – [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/index.php?title=SVM
- Использование нейронных сетей для распознавания рукописных цифр – [Электронный ресурс]. – Режим доступа: https://ai-science.ru/iz-pesochnicy-ispolzovanie-nejronnyx-setej-dlya-raspoznavaniya-rukopisnyx-cifr-chast-1/
- R´ejean Plamondon и Sargur N Srihari. «Online and off-line handwriting recognition: a comprehensive survey». В: Pattern Analysis and Machine Intelligence / R´ejean Plamondon. – IEEE Transactions, – 2000. – p. 63-84.
- Л Шапиро и Дж Стокман. «Компьютерное зрение». // В: М.: Бином. – 2006. – с. 8.
- Nobuyuki Otsu. «A threshold selection method from gray-level histograms». / Nobuyuki Otsu. – 1975. – p. 23-27.
- Felipe C Ribas и др. «Handwritten digit segmentation: a comparative study». В: International Journal on Document Analysis and Recognition (IJDAR) 16.2 / Felipe C Ribas. – 2013. – p. 127-137.
- Hiromichi Fujisawa, Yasuaki Nakano и Kiyomichi Kurino. «Segmentation methods for character recognition: from segmentation to document structure analysis». В: Proceedings of the IEEE 80.7 (1992), p. 1079-1092.
- Zhixin Shi и Venu Govindaraju. «Segmentation and recognition of connected handwritten numeral strings». В: Pattern Recognition 30.9 1997. – p. 1501-1504.
- R Fenrich и S Krishnamoorthy. «Segmenting diverse quality handwritten digit strings in near real-time». R Fenrich. – 1990. – p. 523-537.
- Оптическое распознавание символов – [Электронный ресурс]. – Режим доступа: http://wiki.technicalvision.ru/index.php/Оптическое_ распознавание_символов_(OCR)
- Обучение нейронной сети – [Электронный ресурс]. – Режим досутпа: http://neuronus.com/theory/240-algoritmy-obucheniya-iskusstvennykh-nejronnykh-setej
- Шлезингер М., Главач В. Структурное распознавание / М. Шлезингер В. Главач. – Киев: Наукова думка. – 2006. – 300 с.
Важливе зауваження
На момент написання даного реферату магістерська робота ще не є завершеною. Передбачувана дата завершення: травень 2017 р., Через що повний текст роботи, а також матеріали по темі можуть бути отримані у автора або його керівника тільки після зазначеної дати.