
Abstract
- Introduction
- 1. Review of the current state of the problem
- 2. Formulation of the problem
- 3. Stages of recognition of handwritten symbols
- 3.1 Pre-processing images
- 3.2 Segmentation
- 3.3 Classification
- 4. Improving recognition quality
- Conclusion
- References
Introduction
Currently, scanning and storing text from a hard drive in the computer memory is a solved task. This significantly simplifies the task of storing handwritten and printed texts and providing access to them for various users. However, the text received as a result of scanning is stored in the computer's memory in the form of an image, most often a bitmap, which makes it very difficult to work with: orientation is difficult, editing, formatting and text search are almost impossible. To solve these problems, it is necessary to carry out the process of recognizing text on the image with the creation of a file in one or another text format. Translation of images of handwritten, typewritten or printed text into text data is called text recognition.
The task of recognizing typewritten text is called optical character recognition. At present, there are high-precision systems for recognizing typewritten and hand-written texts (for example, ABBYY FineReader). Recognition of the same handwritten texts is much more complicated and at the moment not an accomplished task.
The task of recognizing handwritten digits is one of the classic problems of pattern recognition and has considerable practical value. One of the first practical applications of methods for recognizing handwritten figures was the creation of a system for reading US ZIP codes. Methods for recognizing numbers are also used to solve such practical problems as reading bank checks, automated reading of questionnaires, etc.
1. Review of the current state of the problem
In this section, the main scientific works related to the study of the possibility of using the methods of recognition of handwritten figures will be considered:
Yoav Freund, Robert E Schapire considers the AdaBoost algorithm in their work A desicion-theoretic generalization of on-line learning and an application for boosting
. The algorithm AdaBoost (short for adaptive boosting) is an algorithm of machine learning, proposed by Yoav Freund (Yoav Freund) and Robert Schapier (Robert Schapire). It is a meta-algorithm that builds a composition from the basic learning algorithms in the learning process to improve their effectiveness. AdaBoost is an algorithm of adaptive boosting in the sense that each next classifier is built on objects that are poorly classified by previous classifiers. AdaBoost causes a weak classifier in the loop. After each call, the distribution of weights is updated, which correspond to the importance of each of the objects of the training set for classification. At each iteration, the weights of each incorrectly classified object increase, so the new classifier focuses its attention
on these objects. The exponential loss function too greatly increases the weights of the most difficult objects, on which many basic algorithms are mistaken. However, these objects most often turn out to be noise emissions. As a result, AdaBoost begins to adjust to noise, which leads to retraining[1].
In the work Handwritten digit recognition with a back-propagation network
B Boser Le Cun considers the application of a convolutional neural network. Conveyor network LeNet. One of the variants of a specialized neural network for recognition is the architecture of a convolutional neural network. The basic principles of building this architecture are as follows:
- The network as a whole is a multi-layer perceptron with direct connections.
- Neurons in the first few layers have 2-dimensional local receptive fields.
- Neurons-feature detectors form 2-dimensional signs cards in a way similar to a mathematical convolution operation. Above the feature cards, a procedure for decreasing the spatial resolution is performed.
- The input of the first layer of feature-detecting neurons is the input image. The input of each of the following layers of feature detectors is feature cards with reduced spatial resolution formed by the previous layer of feature detectors[2].
In the LeNet5 network, the first layer consists of 6 neurons with a square receptive field of 5 × 5. The outputs of the neurons of the first layer form the first feature card with a dimension of 6 × 28 × 28. The output of the first layer of feature grouping is a feature card with a dimension of 6 × 14 × 14. The second layer of feature detectors contains 16 neurons and generates a feature map with a dimension of 16 × 10 × 10. The neurons of this layer have receptive fields of 5 × 5 and receive input data from the first characteristic map. The second layer of feature grouping also reduces the size of the feature card by a factor of two, respectively, at its output the second feature card has a dimension of 16 × 5 × 5. This feature card is the input of 100 neurons of the next layer. The last layer has 10 neurons - one for each class, which must be recognized[3].
Chih-Chung Chang, Chih-Jen Lin proposed a method of support vectors in the work LIBSVM: A library for support vector machines
. The support vector machine (SVM) is a set of similar learning algorithms with the teacher used for classification and regression analysis tasks. It belongs to the family of linear classifiers and can also be considered as a special case of Tikhonov regularization. A particular property of the support vector method is a continuous decrease in the empirical classification error and increase in the gap, so the method is also known as the classifier method with the maximum gap[4].
The main idea of the method is the translation of the initial vectors into a space of higher dimension and the search for a separating hyperplane with the maximum gap in this space. Two parallel hyperplanes are constructed on both sides of the hyperplane that separates the classes. The separating hyperplane is a hyperplane that maximizes the distance to two parallel hyperplanes. The algorithm works under the assumption that the greater the difference or the distance between these parallel hyperplanes, the less is the average classifier error[5].
Michael Nelson's Neural Networks and Deep Learning
discusses the use of the Perceptron neural network. Designing input and output layers of a neural network is quite easy. For example, suppose that we are trying to determine whether the handwritten 9
is depicted in the image or not. A natural way to design a network is to encode the pixel intensities of the image into input neurons. If the image has a size of 64x64, then we have 4,096 = 64 × 64 input neurons. The output layer has one neuron that contains the output value, if it is greater than 0.5, then on the image 9
, otherwise it does not. While designing input and output layers is a fairly simple task, choosing an architecture for hidden layers is an art. Researchers have developed many heuristics of designing hidden layers, for example, those that help to compensate for the number of hidden layers versus the time of learning the network. Until now, we have used neural networks in which the output from one layer - used as a signal for the next one, such networks are called direct neural networks or direct-distribution networks (FeedForward). However, there are other models of neural networks in which feedback loops are possible. These models are called recurrent neural networks. Recurrent neural networks were less influential than direct-linked networks, in part because training algorithms for recurrent networks (at least to date) are less effective[6].
2. Formulation of the problem
The purpose of the master's thesis work: research and development of the method of recognition of handwritten figures.
To achieve this goal, you must perform the following tasks:
- Analyze the current state of the problem of recognition of handwritten figures.
- Conduct an analysis of modern methods for recognizing handwritten figures.
- Develop a method for recognizing handwritten figures based on image segmentation and the Hopfield neural network.
- Offer a modification that will help improve the recognition of handwritten figures.
- Development of software for recognition of handwritten figures based on image segmentation and neural network.
- Conducting analysis of the effectiveness of the developed method and existing analogues of recognition.
3. Stages of recognition of handwritten symbols
3.1 Image pre-processing
At the preprocessing stage, image enhancement is performed to bring the image to the kind most suitable for further automatic work with it[2]. Improving image quality for further text recognition involves removing image defects and separating text from the background[3]. Removal of defects is carried out by standard methods of image processing. The most common method for removing noise is using a Gauss filter to suppress high-frequency noise and a median filter to remove the salt and pepper
noise[7] using formula (1).

Such an image transformation allows further analysis of connected components, contours, skeletons, etc. The most commonly used method of separating text from the background is threshold binarization. Let the image be given, I (i, j) the brightness of the pixel with the coordinates (i, j). The threshold binarization of an image is a pixel-by-pixel transformation f (i, j), calculated from formula (2).
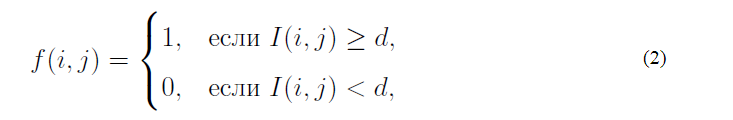
where d is called the binarization threshold.
Usually on the histogram of the brightness of the text image there are two peaks: a high peak in the area of light pixels (corresponds to the background, that is, paper) and a peak lower in the dark area (corresponds to the text). Therefore, the task of finding the luminance threshold value, that is, such that pixels with brightness above this value (background) will be considered black, and below (text) white (this "color inverting" is done to simplify the application of many algorithms in the future) is the task of finding the optimal value between two peaks of the histogram. To solve this problem, there are well-studied methods, for example, the Otsu method[8] and his variations. The result of the preliminary image processing step is a binary image of white numbers on a black background corresponding to the original image.
3.2 Segmentation
At the segmentation stage, individual digits are extracted in the image obtained in the preprocessing step. The result of the segmentation step should be a sequence of images of individual digits, which are then fed to the procedure for retrieving the characteristics. Such a strategy, called the explicit segmentation strategy, is more preferable in the task of recognizing sequences of handwritten digits than implicit segmentation, in which the selection of digits, extraction of features and classification pass in parallel[9].
Selecting groups of numbers. After separating the text from the background in the preprocessing step, it is possible to use analysis of the connected components to select groups of digits. If we consider white pixels as the vertices of a graph, and connect vertices corresponding to neighboring pixels with edges, it becomes possible to isolate the connectivity components corresponding to one or more intersecting digits. To isolate connected components, there are standard and widely known search algorithms, for example, depth search and wide-width search.
Separation of linked figures. After separating the connectivity component on the graph of the image, you need to decide whether this component is one or more digits, and if several, how to separate them. Typically, the segmentation of the connectivity component into numbers occurs in two stages: first, possible ways of segmentation of the connectivity component are generated, and then the best one is selected from them. The construction of possible methods of segmentation is usually carried out by heuristic methods. The choice of the best method of segmentation can be done by the subsystem of segmentation (in this case only one set of input data enters the input subsystem of the extraction of characteristics and classifications) and the classification subsystem (in this case several subsets of input data enter the subsystems for extracting characteristics and classification, and the decision as to which segmentation was performed correctly is taken based on the recognition results). For the construction of explicit segmentation, two types of data representation are most often used: a contour and a skeleton. An object's contour is the set of all pixels belonging to an object and having an adjacent pixel not belonging to the object. The extreme right and extreme left points of the contour divide it into the upper and lower contours (Figure 1). The region of convexity of the contour is called the valley, and the region of concavity is the hill.
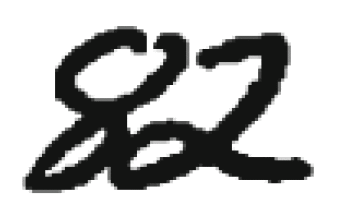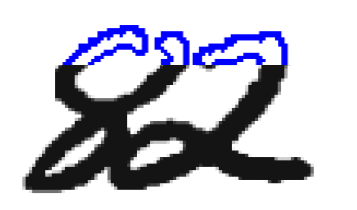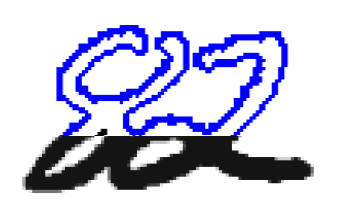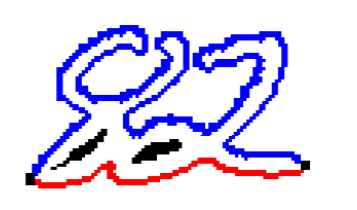
Figure 1 – The connectivity component
(animation: 3 frames, 7 loops, 31 kbytes)
A connected component consisting of two intersecting digits and its contour. The blue outline is highlighted in blue, the lower one is red. Segmentation methods based on the analysis of the contours of previously isolated connectivity components are given in [10, 11, 12]. In these methods, on the contours of the connectivity components, starting from some considerations, potential points of the cut are selected, through which the cut lines that satisfy certain conditions are then drawn. In work[10], possible cut points are set where the distance between the upper and lower contours exceeds the threshold, and the best cut is selected as the shortest path in the graph with vertices at possible points of the cut. In work[11], the points of a possible cut are chosen heuristically as the points at which the contour makes the greatest rightward turn when going counterclockwise.
3.3 Classification
In existing OCR (Optical Character Recognition) systems, various classification algorithms are used, that is, assigning characteristics to different classes. They differ significantly depending on the accepted sets of characteristics and the classification strategy applied to them.
For a character classification of symbols, it is first necessary to form a set of reference characteristic vectors for each of the recognizable symbols. To do this, at the training stage, the operator or developer enters into the OCR system a large number of character traits accompanied by specifying a symbol value. For each sample, the system selects the characteristics and saves them in the form of a corresponding vector of characteristics of the feature vector. A set of characteristic vectors that describe a symbol is called a class, or cluster.
The task of the actual classification or recognition procedure performed at the time the symbol image is presented to the system is to determine which of the previously formed classes belongs to the feature vector obtained for the symbol. Classification algorithms are based on determining the degree of proximity of the set of characteristics of the symbol in question to each of the classes. The likelihood of the result depends on the chosen metric of the feature space. The most well-known metric of a characteristic space is the traditional Euclidean distance, calculated from formula (3).

where FLji is the i-th characteristic from the j-th reference vector; Fli is the i-th sign of the symbol being tested.
When classifying by the method of the nearest neighbor, the symbol will be assigned to a class whose characteristic vector is closest to the vector of characteristics of the symbol being tested. It should be borne in mind that the cost of computing in such systems increases with the increase in the number of features and classes used [13].
The general algorithm for recognizing handwritten characters is as follows and is shown in Figure 2.
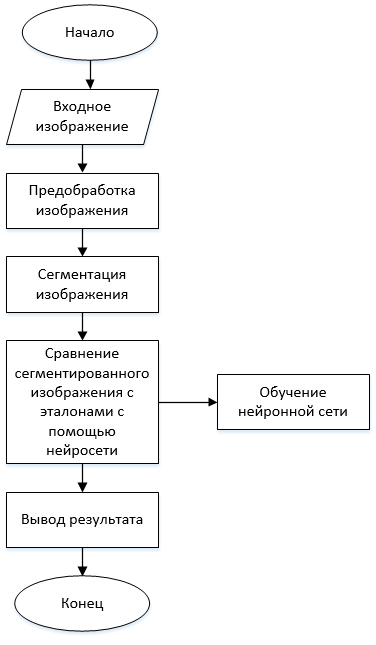
Figure 2 – The general algorithm for recognizing
4. Improving recognition quality
To improve the quality of recognition, various methods are used for preprocessing images with text, for example, noise reduction [14]. Sources of noise in the image can be:
- analog noise:
- dirt, dust;
- scratches;
- digital noise:
- thermal noise of the matrix;
- noise of charge transfer;
- noise quantization of the ADC.
Digital image processing uses spatial noise reduction. Allocate the following methods:
- adaptive filtering - linear averaging of pixels along neighboring ones;
- median filtering;
- mathematical morphology;
- Gaussian blur;
- methods based on discrete wavelet transform;
- the principal component method;
- anisotropic diffusion;
- Wiener filters.
Conclusion
The main task of offline recognition of handwritten figures was considered. The main problems in recognition are highlighted, as well as the difference between the recognition of handwritten symbols and handwritten figures. The existing methods of offline recognition have been described and three most famous algorithms have been identified. Each of the algorithms describes the basic structure of the work, the advantages and disadvantages are highlighted. Automatic visual perception to date does not reach the perfection of human perception of the text. The main reason for this is the inability to build sufficiently complete and semantically expressive computer models of the domain. Also, the main optimization methods for improving the quality of recognition were examined and highlighted.
Analyzing the existing methods for recognizing handwritten digits, we can conclude that it is best to use the method of pattern recognition with the help of a neural network, since it combines the virtues of many methods and because of this is flexible enough to apply it when recognizing handwritten digits.
References
- Yoav Freund и Robert E Schapire. «A desicion-theoretic generalization of on-line learning and an application to boosting». В: Computational learning theory. Springer. / Yoav Freund. – 1995. – p. 23-37.
- B Boser Le Cun и др. «Handwritten digit recognition with a back-propagation network». В: Advances in neural information processing systems. Citeseer. 1990.
- Chih-Chung Chang и Chih-Jen Lin. «LIBSVM: A library for support vector machines». В: ACM Transactions on Intelligent Systems and Technology 2 (3 2011).
- Машина опорных векторов – [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/index.php?title=SVM
- Использование нейронных сетей для распознавания рукописных цифр – [Электронный ресурс]. – Режим доступа: https://ai-science.ru/iz-pesochnicy-ispolzovanie-nejronnyx-setej-dlya-raspoznavaniya-rukopisnyx-cifr-chast-1/
- R´ejean Plamondon и Sargur N Srihari. «Online and off-line handwriting recognition: a comprehensive survey». В: Pattern Analysis and Machine Intelligence / R´ejean Plamondon. – IEEE Transactions, – 2000. – p. 63-84.
- Л Шапиро и Дж Стокман. «Компьютерное зрение». // В: М.: Бином. – 2006. – с. 8.
- Nobuyuki Otsu. «A threshold selection method from gray-level histograms». / Nobuyuki Otsu. – 1975. – p. 23-27.
- Felipe C Ribas и др. «Handwritten digit segmentation: a comparative study». В: International Journal on Document Analysis and Recognition (IJDAR) 16.2 / Felipe C Ribas. – 2013. – p. 127-137.
- Hiromichi Fujisawa, Yasuaki Nakano и Kiyomichi Kurino. «Segmentation methods for character recognition: from segmentation to document structure analysis». В: Proceedings of the IEEE 80.7 (1992), p. 1079-1092.
- Zhixin Shi и Venu Govindaraju. «Segmentation and recognition of connected handwritten numeral strings». В: Pattern Recognition 30.9 1997. – p. 1501-1504.
- R Fenrich и S Krishnamoorthy. «Segmenting diverse quality handwritten digit strings in near real-time». R Fenrich. – 1990. – p. 523-537.
- Оптическое распознавание символов – [Электронный ресурс]. – Режим доступа: http://wiki.technicalvision.ru/index.php/Оптическое_ распознавание_символов_(OCR)
- Шлезингер М., Главач В. Структурное распознавание / М. Шлезингер В. Главач. – Киев: Наукова думка. – 2006. – 300 с.
Important
At the time of writing this essay is to master the job is not complete. Estimated date of completion: May 2017, as a consequence of the full text, as well as materials on the subject may be obtained from the author or his head only after the specified date.