
Abstract
Content
- Introduction
- 1.Theme urgency
- 2. Goal and tasks of the research, expected results
- 3. Research and development overview
- 3.1 Review of international sources
- 3.2 Review of national sources
- 3.3 Browse local sources
- 4 Analysis of existing methods for searching and classifying information
- 4.1 The main stages of classification
- 4.2 Naive Baye's Classifier
- 4.3 Support vector machine
- 4.4 K-Nearest Neighbor Algorithm
- Conclusions
- References
Introduction
One of the areas of research in the field of information security is the development of methods and algorithms for filtering e-mail flow. Recently, e-mail has become one of the most common means of communication, management and business.
The rapid growth in popularity of electronic means of communication, including e-mail, as well as the low cost of their use, leads to an increasing flow of unauthorized mass mailings.
Most of the methods and algorithms for classifying spam filtering are not accurate enough in contrast to the Bayesian classifier. In this regard, there is a need to create an information filter based on the Bayesian classifier.
1. Theme urgency
The rapid growth in popularity of electronic means of communication, including e-mail, as well as the low cost of their use, leads to an increasing flow of unauthorized mass mailings. Unauthorized mailings cause obvious damage - this is a real material loss for companies and network users. Excessive load on networks and equipment, time spent sorting and deleting emails, money spent on paying for traffic - this is an incomplete list of problems that spam brings. Spam is often used as a channel for the spread of viruses.
The problem with the classical Bayesian spam classification is that it is based on the rule that some words are more common in spam and others in regular mail. And this algorithm is ineffective if this assumption is incorrect.
Since the problem of spam is quite acute today, research and development of an improved spam classification algorithm based on the Bayesian method is relevant.
2. Goal and tasks of the research, expected results
The main goal of the work is to increase the efficiency of the Bayesian spam classifier.
Main tasks:
- Analysis of existing methods of search and classification of spam;
- Designing a spam classification algorithm
- Implementation of the Bayesian Spam Classification Algorithm
- Evaluating the effectiveness of spam classification.
The novelty lies in the development of an improved Bayesian spam classifier.
It is planned that the research results obtained in the dissertation can be used in the development of classifiers of information on the Internet, allowing detecting spam documents.
3. Research and development overview
The topic under study is popular not only in international, but also in national scientific communities.
Along with this, this section will provide an overview of research in the field of information classification, in particular the application of the Bayesian classifier for this purpose by both American, European, Chinese scientists, and domestic specialists.
3.1 Review of international sources
In An Empirical Study of a Bayesian Classifier
, Risch. I. [1],explores the characteristics of the data that affect the performance of the naive Bayesian method. The work uses the Monte Carlo method, which allows you to systematically study the classification accuracy for several classes of generated problems. The influence of the distribution entropy on the classification error is analyzed, showing that low-entropy feature distributions give good characteristics of naive Bayes.
In the article Analysis of Bayesian Classifiers
Iba W., Thompson.K. [2] analyzes the Bayesian classifier by calculating the probability that the algorithm will cause an arbitrary pair of concept descriptions, then this expression is used to compute the correct classification in terms of the probability space of the instances. In addition, the authors of the article conduct research on the behavioral implications of the analysis by presenting predicted learning curves for a range of artificial domains.
3.2 Review of national sources
In the work Application of the optimized naive Bayesian classifier in the problem of SMS message classification
, Burlakova M. Ye. [3], the process of optimization of the naive Bayesian classifier is considered. The mechanism for calculating the probability and the process of constructing a training table for the practical solution of the problem of classifying SMS messages by a naive Bayesian classifier are also considered.
The article Improving the accuracy of the Bayesian classifier for text documents
, PV Trifonova [4], discusses ways to improve the Bayesian classifier by constructing a given set of documents, which were classified by experts manually, some model that can be used in the future to decide whether documents belong to the specified categories.
In the work Modification of the naive Bayesian classifier
, Lomakina L.S., Lomakina D.V., Subbotina A.N. [5], a modification of the naive Bayesian classification of text information flows is considered. The article also offers a real classifier that allows you to process text streams in real time.
In the article The history of the emergence of spam and ways to counter its spread
Lyutova E.I., Kolomoitseva I.A. [6], the history of the emergence of unwanted mass mailings, as well as known ways to deal with it. Spam filtering software analyzed.
3.3 Browse local sources
Titarenko Mikhail Gennadievich's abstract Study of methods of classification of information on foreign trade activities of states within the information retrieval system
[7] provides an overview and analysis of binary classification algorithms for information on foreign trade activities of states. The calculation of metrics for algorithms and comparison of the results of the work of classifiers for classifying information was also considered.
In the abstract of Dmitry Aleksandrovich Vlasyuk Research of methods of extracting knowledge from HTML-pages of the Internet about sports competitions
[8] an analysis of methods of extracting knowledge from the Internet and their storage was presented. We also analyzed the database models and stored information about sports.
4 Analysis of existing methods for searching and classifying information
4.1 The main stages of classification
The first step in solving the problem of automatic text classification is document transformation. At this stage, documents in the form of a sequence of characters are converted to a form suitable for machine learning algorithms in accordance with the classification problem. Typically machine learning algorithms deal with vectors in a space called the [9] feature space.
The second stage is the construction of the classifying function Ф` using training by examples. The quality of the classification depends both on how the documents will be converted into vector representation, and on the algorithm that will be applied in the second stage. It is important to note that the methods for converting text into a vector are specific to the text classification problem and may depend on the collection of documents, the type of text (simple, structured) and the document language. The machine learning methods used in the second stage are not specific to the text classification problem and are also used in other areas, for example, for image recognition problems.
So, the classical classification problem can be broken down into two main stages:
- Preprocessing / Indexing - mapping the text of a document to its logical representation, for example, a vector of weights 𝑑𝑗 ̅, which is then fed to the input of the classification algorithm.
- Classification / Learning is the stage of classifying a document or learning across multiple documents based on a logical representation of the document. It is important to note that a general text preprocessing / indexing method can be used for classification and training.
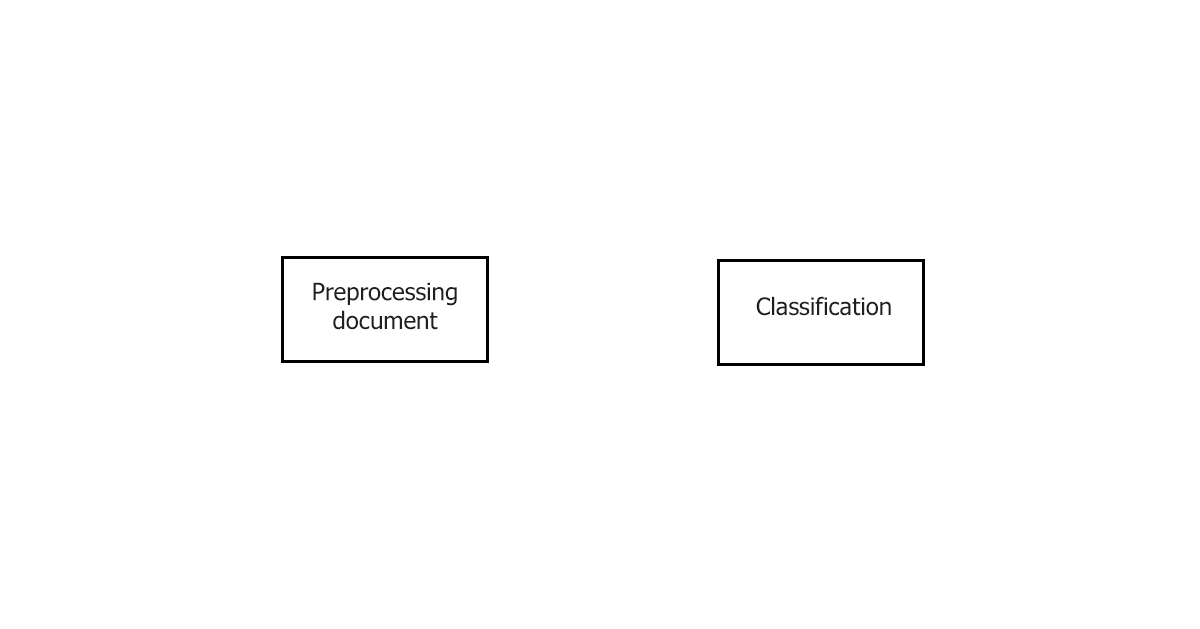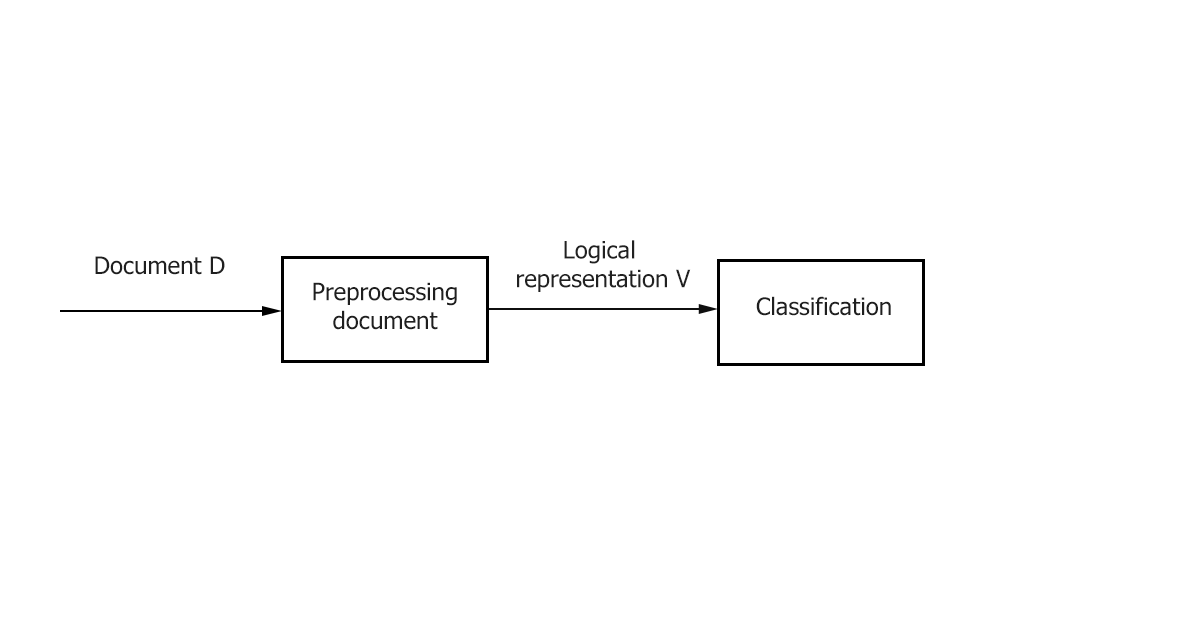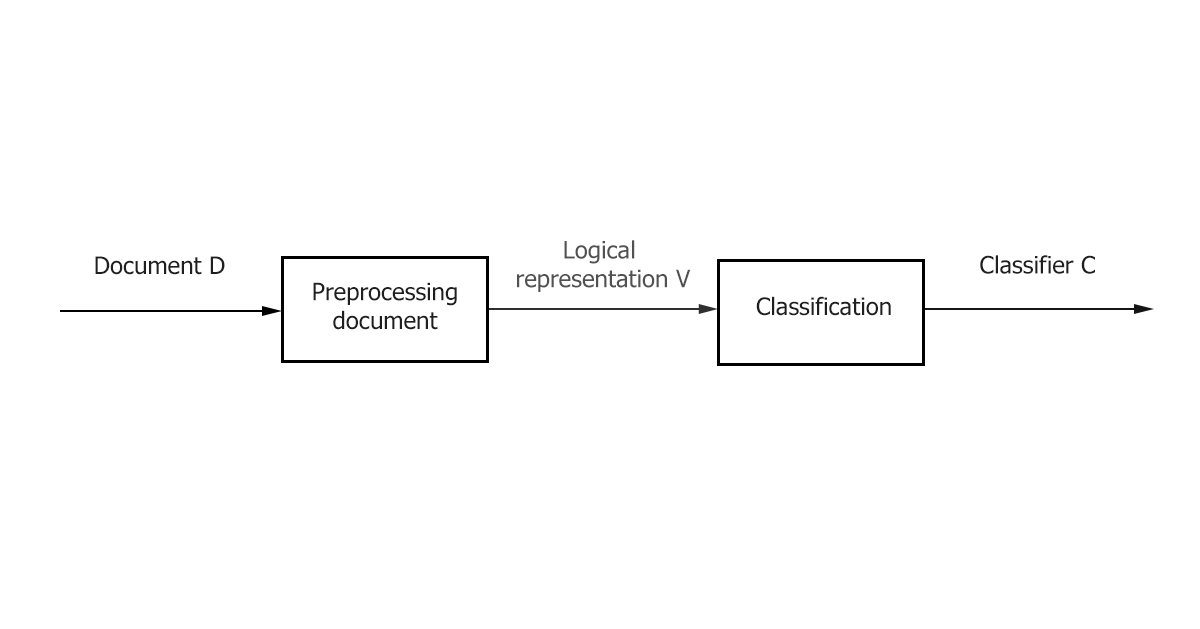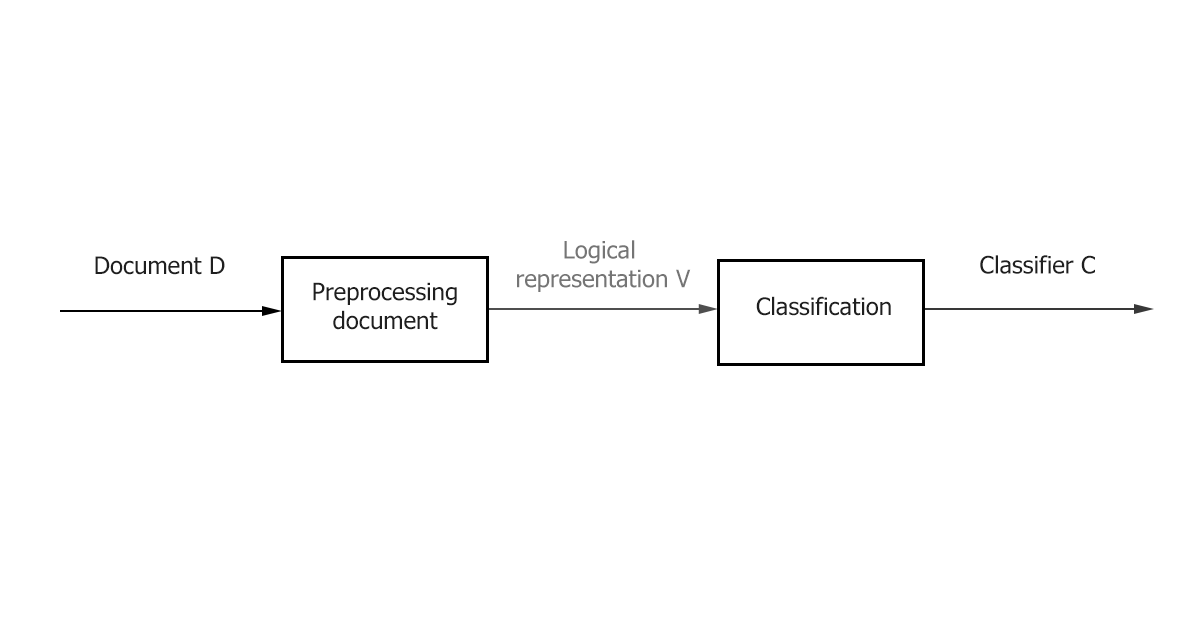
Figure 1–The main stages of classification
(animation: 10 frames,
repetition cycle:7, size: 163 kilobyte)
4.2 Naive Bayesian Classifier
The naive Bayesian model is based on Bayes' theorem:
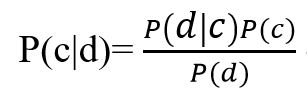
Figure 2– Bayes theorem formula
Where, P (c | d) - the probability that document d belongs to class c, we need to calculate it; P (d | c) - the probability of encountering document d among all documents of class c; P (c) - unconditional probability of encountering a class c document in the corpus of documents; P (d) is the unconditional probability of document d in the corpus of documents.
Bayes' theorem allows you to swap cause and effect. Knowing with what probability, a cause leads to an event, this theorem allows you to calculate the probability that this particular cause led to the observed event.
The purpose of the classification is to understand which class the document belongs to, so it is not the probability itself that is needed, but the most probable class. The Bayesian classifier uses the Maximum a posteriori estimation to determine the most likely class. Roughly speaking, this is the class with the highest probability [10].
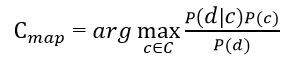
Figure 2 – Estimation of the posterior maximum
It is necessary to calculate the probability for all classes and select the class that has the highest probability. It is worth noting that the denominator (document probability) in the formula in Figure 2 is constant and cannot in any way affect the ranking of classes, so it can be omitted.
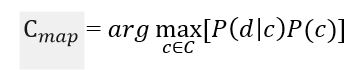
Figure 3 – Estimation of the posterior maximum without denominator
The "naivety" of this classifier model lies in the fact that it uses the naive assumption that the words included in the text of the document are independent of each other. Based on this, the conditional probability of a document is approximated by the product of the conditional probabilities of all words included in the document.
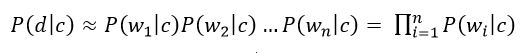
Figure 4 – Product of conditional probabilities of all words included in the document
where wi –number of times how many i-th word occurs in documents of class c
Substituting the resulting expression into the formula in Figure 3, we get:
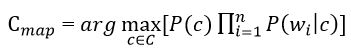
Figure 5 – Estimation of the posterior maximum with logarithms of probabilities
In the formula in Figure 5, the logarithm of these probabilities is most often used instead of the probabilities themselves. Since the logarithm is a monotonically increasing function, the class with with the highest value of the logarithm of the probability remains the most probable. Then:
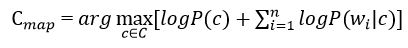
Figure 6 – Estimating the posterior maximum with conditional document probability
Next, you need to assess the probability of the class and the word in the class. They are calculated by the formulas:
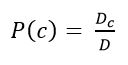
Figure 7 – Grade Probability Assessment
where Dc – number of documents belonging to the class с; D – the total number of documents in the training sample.
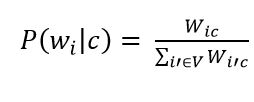
Рисунок 8 – Оценка вероятности слова в классе
where V is the dictionary of the corpus of documents (a list of all unique words)
The next step is to apply additive smoothing (Laplace smoothing). This is necessary so that words that did not occur at the stage of training the classifier do not have a zero probability. Therefore, it is necessary to add one to the frequency of each word.
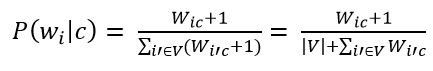
Figure 9 – Estimating the probability of a word in a class with the addition of one
Substituting all the obtained estimates of probabilities (formulas in Figures 7 and 9), we obtain the final formula for the naive Bayesian classifier model.
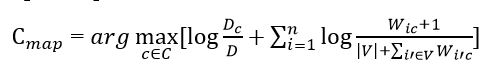
Figure 10 – Naive Bayesian Classifier Formula
Bayesian Method is used to identify unauthorized email marketing campaigns (spam). At the same time, the training base is considered - two arrays of e-mails, one of which is composed of spam, and the other - of ordinary letters. For each of the corpuses, the frequency of use of each word is calculated, after which a weight score (from 0 to 1) is calculated, which characterizes the conditional probability that a message with this word is spam. Weight values close to 0.5 are not taken into account in integrated counting, therefore words with such weights are ignored and removed from the dictionaries. [11]
The advantages of this approach to spam filtering are:
- The naive Bayesian classifier method is easy to use
- Highly effective in filtering out spam
- High speed of work
- A large number of modern spam filters have been built using this method (Mozilla Thunderbird 0.8, BayesIt! 0.6.0, SpamAssassin 3.0.0 rc3). [12]
However, the method also has a fundamental drawback: it is based on the assumption that some words are more common in spam, and others in regular emails, and is ineffective if this assumption is incorrect. However, as practice shows, even a person is not able to identify such spam "by eye" - only after reading the letter and understanding its meaning. There are also algorithms that allow you to add a lot of extra text, sometimes carefully chosen to "trick" the filter.
Another, not fundamental, disadvantage associated with the implementation - the method works only with text. Knowing this limitation, you can put advertising information into the picture, but the text in the letter is either absent or does not make sense. Against this, you have to use either text recognition tools or the old filtering methods - blacklists and regular expressions (since such letters often have a stereotyped form).
4.3 Support vector machine
Support Vector Mashine (SVM) belongs to the group of boundary classification methods. It determines which objects belong to classes using area boundaries. We will consider only binary classification, that is, classification only in two categories c and c1 , taking into account that this approach can be extended to any finite number of categories. Suppose each classification object is a vector in N-dimensional space. Each coordinate of the vector is a certain feature, quantitatively the greater, the more this feature is expressed in a given object. Method advantages:
- One of the most qualitative methods;
- Ability to work with a small set of training data;
- Reducibility to a convex optimization problem with a unique solution.
Disadvantages of the method: complex interpretability of the algorithm parameters and instability with respect to outliers in the initial data. [13]
4.4 K-Nearest Neighbor Algorithm
Nearest Neighbor Method is a simple metric classifier based on assessing the similarity of objects. The classified object belongs to the class to which the objects of the training set are related to it. one of the simple systematization algorithms, for this reason in real problems it often turns out to be ineffective. In addition to the accuracy of systematization, the issue of this classifier is the rate of systematization: if there are N objects in the training sample, there are M objects in the test selection, but the dimension of the space is K, in this case the number of actions to systematize the test set can be estimated as O (K * M * N). This method does not achieve high accuracy when identifying spam, which makes it rather ineffective in filtering unnecessary information. [14]
Преимущества метода:
- Ability to update the training sample without retraining the classifier;
- The stability of the algorithm to abnormal outliers in the initial data is a relatively simple software implementation of the algorithm;
- Easy interpretability of the results of the algorithm;
- Good learning in the case of linearly inseparable samples.
Disadvantages of the method:
- Representativeness of the dataset used for the algorithm
- High dependence of classification results on the selected metric
- Long duration of work due to the need for a complete enumeration of the training sample
- Impossibility of solving large-scale problems by the number of classes and documents.
5. Conclusions
In the course of this work, algorithms and classifications for identifying information have been analyzed. After a detailed study, the disadvantages and advantages of the considered approaches were identified. As a result of this review, the following areas of research can be noted:
- Exploring a Bayesian Classifier in Detail
- Development of combined methods
In particular, the Bayesian classifier method is of interest, since it has a higher reliability and is quite simple to implement. Research prospects are the development of our own spam classification algorithm based on a naive Bayesian classifier.
References
- Irina Rish, An Empirical Study of the Naïve Bayes Classifier, T.J. Watson Research Center, 2001, Режим доступа: [Ссылка]
- Wayne Iba, Kevin Thompson, An Analysis of Bayesian Classifiers, NASA Ames Research Center, 1992, Режим доступа: [Ссылка]
- Бурлаков М. Е., Применение в задаче классификации SMS сообщений оптимизированного наивного байесовского классификатора, Самарский национальный исследовательский университет им. С.П. Королёва, 2016 Режим доступа: [Ссылка]
- Трифонов П. В., Повышение точности байесовского классификатора текстовых документов, Научно-технические ведомости СПбГТУ 1' 2010, 2019 Режим доступа: [Ссылка]
- Lomakina L.S.Lomakin D.V.Subbotin A.N., Naïve Bayes modification for text Streams classification, Nizhny Novgorod State Technical University n.a. R.E. Alekseev, 2016 Режим доступа: [Ссылка]
- Лютова Е.И., Коломойцева И.А., История возникновения спама и способы противодействия его распространению, Донецкий национальный технический университет, 2020, Режим доступа: [Ссылка на сборник]
- Титаренко М.Г., Исследование методов классификации информации о внешнеторговой деятельности государств в рамках информационно-поисковой системы, Донецкий национальный технический университет, 2018 Режим доступа: [Ссылка]
- Власюк Д. А., Исследование методов извлечения знаний из HTML-страниц сети Интернет о спортивных соревнованиях, Донецкий национальный технический университет, 2018 Режим доступа: [Ссылка]
- Агеев М С. Методы автоматической рубрикации текстов, основанные на машинном обучении и знаниях экспертов// Московский Государственный Университет им. М.В. Ломоносова Режим доступа: [Ссылка]
- Наивный байесовский классификатор [электронный ресурс] Режим доступа: [Ссылка]
- Ландэ Д.В., Снарский А.А., Безсуднов И.В. Интернетика:Навигация в сложных сетях: модели и алгоритмы. Книжный дом «Либроком», 2009. – 88-89 с.
- Применимость байесовского классификатора для задачи определения спама [электронный ресурс] Режим доступа: [Ссылка]
- Метод опорных векторов [электронный ресурс] Режим доступа: [Ссылка]
- Метод ближайших соседей [электронный ресурс] Режим доступа: [Ссылка]