
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4 Анализ существующих методов поиска и классификации информации
- 4.1 Основные этапы классификации
- 4.2 Наивный байеовский классификатор
- 4.3 Метод опорных векторов
- 4.4 Алгоритм k-ближайших соседей
- Выводы
- Список источников
Введение
Одним из направлений исследований в области защиты информации является разработка методов и алгоритмов фильтрации потока электронной почты. В последнее время электронная почта стала одним из наиболее распространенных средств связи, управления и бизнеса.
Быстрый рост популярности электронных средств коммуникации, в том числе электронной почты, а также низкая стоимость их использования приводит к увеличивающемуся потоку несанкционированных массовых рассылок.
Большинство методов и алгоритмов классификации фильтрации спама работают недостаточно точно в отличии от байесовского классификатор. В связи с этом есть необходимость создание фильтра информации на основе байесовского классификатора.
1. Актуальность проблемы
Быстрый рост популярности электронных средств коммуникации, в том числе электронной почты, а также низкая стоимость их использования приводит к увеличивающемуся потоку несанкционированных массовых рассылок. Несанкционированные рассылки наносят очевидный ущерб - это реальные материальные потери компаний и пользователей сети. Излишняя нагрузка на сети и оборудование, потраченное время на сортировку и удаление писем, потраченные деньги на оплату трафика - это неполный перечень проблем, которые приносит спам. Часто спам используется в качестве канала для распространения вирусов.
Проблемой классической классификации спама на основе метода Байеса является то, что она базируется на правиле что одни слова, встречаются чаще в спаме, а другие в обычных письмах. И данный алгоритм неэффективен, если данное предположение неверно.
Так как проблема спама на сегодняшний день стоит достаточно остро, исследование и разработка улучшенного алгоритма классификации спама на основе метода Байеса является актуальным.
2. Цель и задачи исследования, планируемые результаты
Основной целью работы является увеличение эффективности метода Байеса на примере обнаружения спама.
Основные задачи:
- Анализ существующих вероятностных методов поиска и классификации информации;
- Проектирование алгоритма классификации на основе методов Байеса
- Реализация алгоритма классификации информации на базе метода Байеса
- Оценка эффективности классификации информации.
Новизна заключается в разработке улучшенного классификатора спама на базе метода Байеса.
Планируется, что полученные в диссертации результаты исследований могут быть использованы при разработке классификаторов информации в Интернет, позволяющих производить обнаружения спам-документов.
3. Обзор исследований и разработок
Исследуемая тема популярна не только в международных, но и в национальных научных сообществах.
Наряду с этим в данном разделе будет представлен обзор исследований в области классификации информации, в частности применение в этих целях байесовского классификатора как американскими, европейскими, китайскими учеными, так и отечественными специалистами.
3.1 Обзор международных источников
В работе «Эмпирическое исследование байесовского классификатора», Риш. И.[1],рассматривается разбор характеристик данных, которые влияют на эффективность наивного байесовского метода. В работе используется метод Монте-Карло, которые позволяет систематически изучать точность классификации для нескольких классов сгенерированных задач. Анализируется влияние энтропии распределения на ошибку классификации, показывая, что низкоэнтропийные распределения признаков дают хорошие характеристики наивного Байеса. ,
В статье «Анализ байесовских классификаторов» Иба.В, Томпсона.К.[2], проводится анализ байесовского классификатора путем вычисления вероятности того, что алгоритм вызовет произвольную пару описаний понятий, затем это выражение используется для вычисления правильной классификации по пространству вероятности экземпляров. Кроме того, авторы статьи проводят исследование поведенческого последствия анализа, представляя прогнозируемые кривые обучения для ряда искусственных областей.
3.2 Обзор национальных источников
В работе «Применение в задаче классификации SMS сообщений оптимизированного наивного байесовского классификатора», Бурлакова М. Е.[3], рассматривается процесс оптимизации наивного байесовского классификатора. Также рассмотрен механизм расчета вероятности и процесс построения обучающей таблицы для практического решения задачи классификации SMS сообщений наивным байесовским классификатором.
В статье «Повышение точности байесовского классификатора текстовых документов», Трифонова П. В. [4], рассматриваются способы улучшения байесовского классификатора путем построения по заданному набору документов, классификация которых была выполнена экспертами вручную, некоторой модели, которая может быть использована в дальнейшем для принятия решения о принадлежности документов к указанными категориям.
В работе «Модификация наивного байесовского классификатора», Ломакиной Л.С, Ломакина Д.В., Субботина А.Н.[5], рассматривается модификация наивной байесовской классификации потоков текстовой информации. Также в статье предложен реальный классификатор, позволяющий обрабатывать текстовые потоки в режиме реального времени.
В статье «История возникновения спама и способы противодействия его распространению» Лютовой Е.И., Коломойцевой И.А.[6], рассмотрена история возникновения нежелательной массовой рассылке, а также известные способы борьбы с ней. Проанализированы программное обеспечения для фильтрации спама.
3.3 Обзор локальных источников
В реферате Титаренко Михаила Геннадиевича «Исследование методов классификации информации о внешнеторговой деятельности государств в рамках информационно-поисковой системы»[7] проводится обзор и анализ алгоритмов бинарной классификации информации о внешнеторговой деятельности государств. Также был рассмотрен расчет метрик для алгоритмов и сравнение результатов работы классификаторов классификации информации.
В реферате Власюка Дмитрия Александровича «Исследование методов извлечения знаний из HTML-страниц сети Интернет о спортивных соревнованиях»[8] был представлен анализ методов извлечения знаний из сети Интернет и их хранение. Также был проведен разбор моделей баз данных и хранение информации о спортивных состязаниях.
4 Анализ существующих методов поиска и классификации информации
4.1 Основные этапы классификации
Первый этап решения задачи автоматической классификации текстов – это преобразование документов. На этом этапе документы, имеющие вид последовательности символов, преобразуются к виду, пригодному для алгоритмов машинного обучения в соответствии с задачей классификации. Обычно алгоритмы машинного обучения имеют дело с векторами в пространстве, называемом пространством признаков[9].
Вторым этапом является построение классифицирующей функции Ф` при помощи обучения на примерах. Качество классификации зависит и от того, как документы будут преобразованы в векторное представление, и от алгоритма, который будет применен на втором этапе. При этом важно отметить, что методы преобразования текста в вектор специфичны для задачи классификации текстов и могут зависеть от коллекции документов, типа текста (простой, структурированный) и языка документа. Методы машинного обучения, применяемые на втором этапе, не являются специфичными для задачи классификации текстов и применяются также в других областях, например, для задач распознавания образов.
Итак, классическая задача классификации может быть разбита на два основных этапа:
- Предобработка/Индексация – отображение текста документа на его логическое представление, например, вектор весов 𝑑𝑗 ̅, который затем подается на вход алгоритму классификации.
- Классификация/Обучение – этап классификации документа или обучения на множестве документов, основанный на логическом представление документа. Важно отметить, что для классификации и обучения может быть использован общий метод предобработки/индексации текстов.
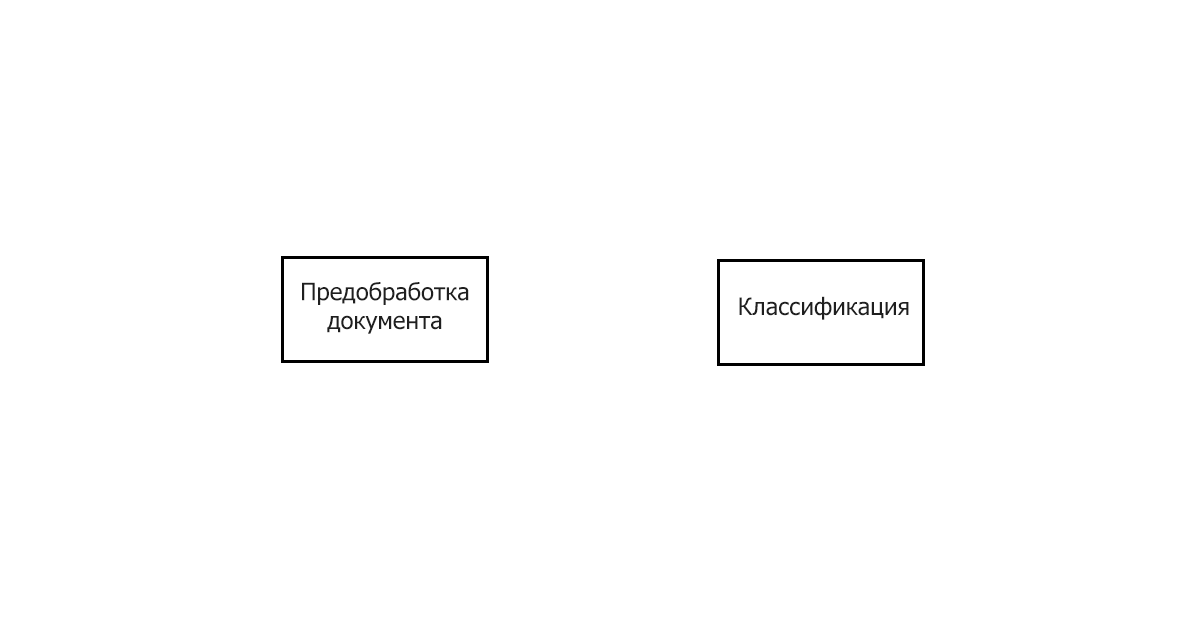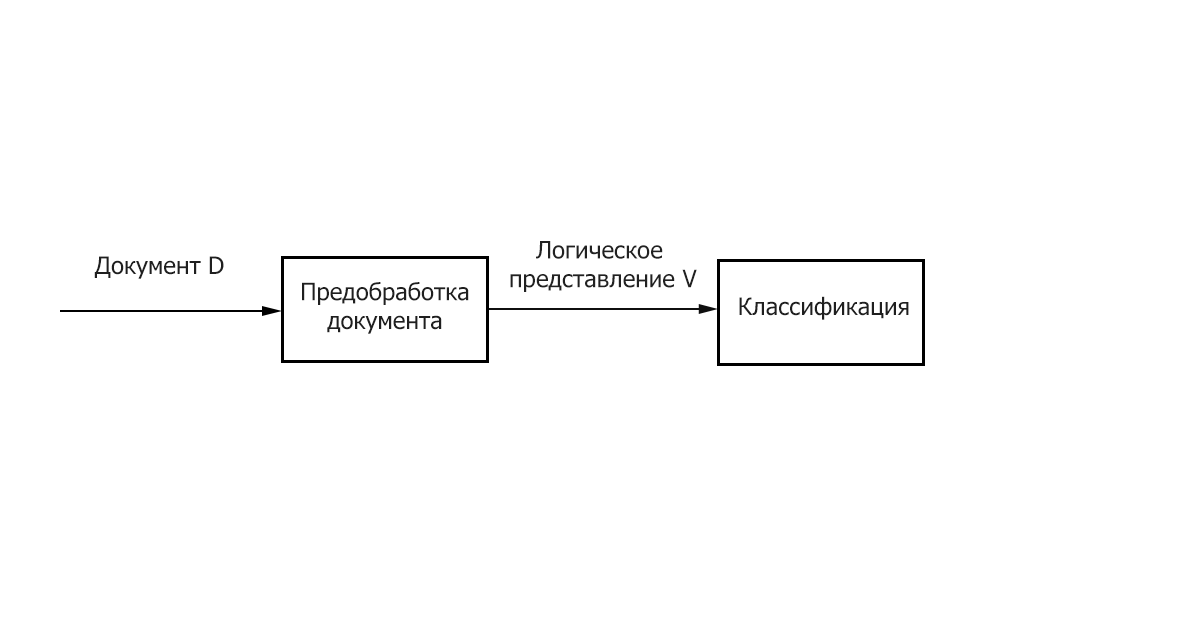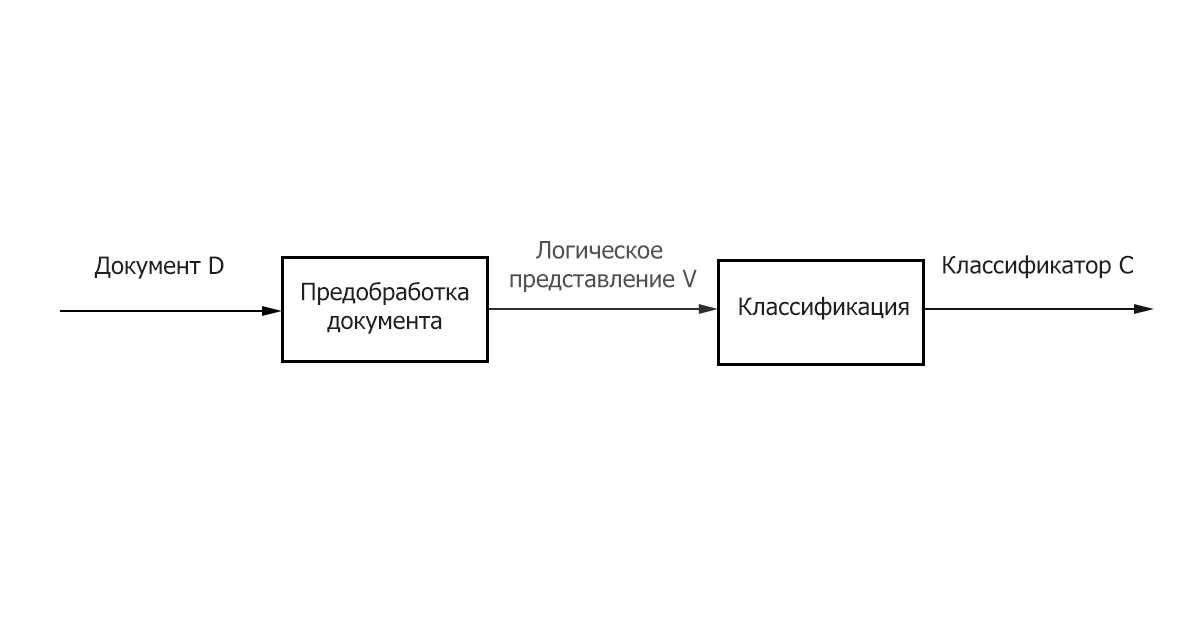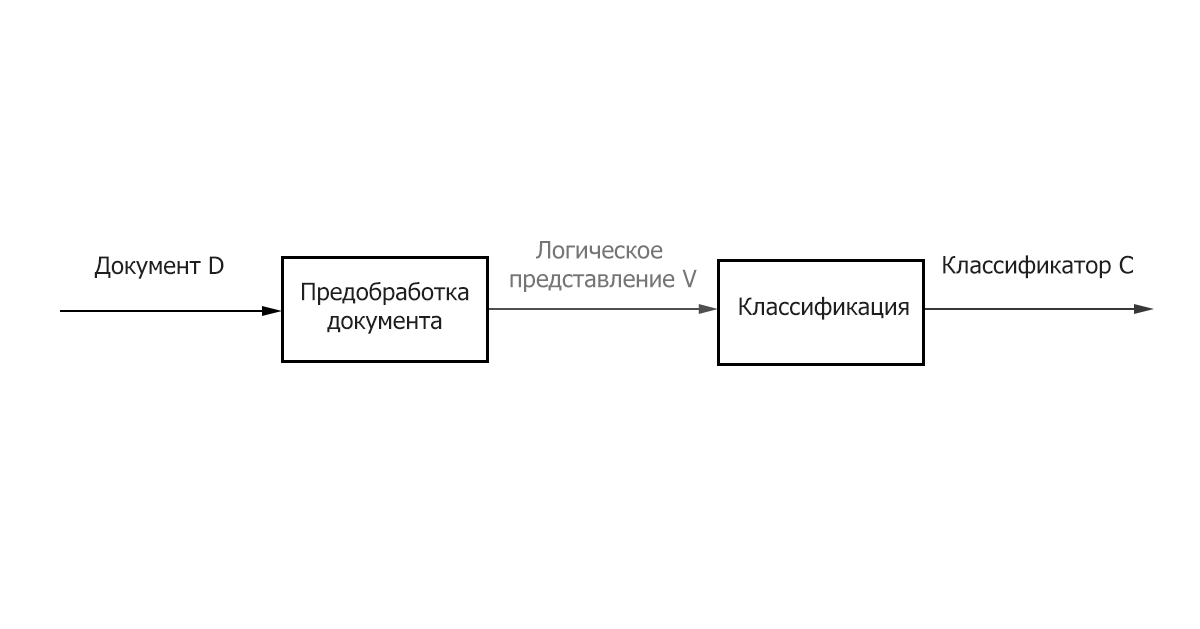
Рисунок 1 – Основные этапы классификации
(анимация: 10 кадров,
цикл повторений:7, размер: 163 килобайт)
4.2 Наивный байесовский классификатор
В основе наивной байесовской модели лежит теорема Байеса:
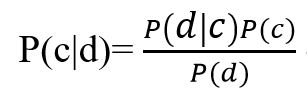
Рисунок 2 – Формула теоремы Байеса
где, P(c|d) — вероятность что документ d принадлежит классу c, именно её нам надо рассчитать; P(d|c) — вероятность встретить документ d среди всех документов класса c; P(c) — безусловная вероятность встретить документ класса c в корпусе документов; P(d) — безусловная вероятность документа d в корпусе документов.
Теорема Байеса позволяет переставить местами причину и следствие. Зная с какой вероятностью, причина приводит к некоему событию, эта теорема позволяет рассчитать вероятность того что именно эта причина привела к наблюдаемому событию.
Цель классификации состоит в том чтобы понять к какому классу принадлежит документ, поэтому необходимо не сама вероятность, а наиболее вероятный класс. Байесовский классификатор использует оценку апостериорного максимума (Maximum a posteriori estimation) для определения наиболее вероятного класса. Грубо говоря, это класс с максимальной вероятностью[10].
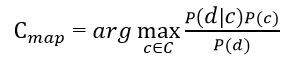
Рисунок 2 – Оценка апостериорного максимума
Необходимо рассчитать вероятность для всех классов и выбрать тот класс, который обладает максимальной вероятностью. Стоит обратить внимание на то, что знаменатель (вероятность документа) в формуле на рисунке 2 является константой и никак не может повлиять на ранжирование классов, поэтому его можно опустить.
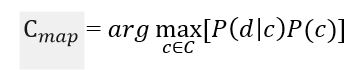
Рисунок 3 – Оценка апостериорного максимума без знаменателя
«Наивность» данной модели классификатора заключается в том, что она использует наивное допущение, что слова, входящие в текст документа независимы друг от друга. Исходя из этого условная вероятность документа аппроксимируется произведением условных вероятностей всех слов, входящих в документ.
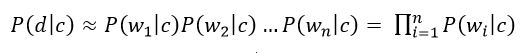
Рисунок 4 – Произведение условных вероятностей всех слов, входящих в документ
где wi – количество раз сколько i–ое слово встречается в документах класса c
Подставив полученное выражение в формулу на рисунке 3 получим:
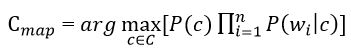
Рисунок 5 – Оценка апостериорного максимума с логарифмами вероятностей
В формуле на рисунке 5 чаще всего используют вместо самих вероятностей используют логарифм этих вероятностей. Поскольку логарифм – монотонно возрастающая функция, то класс с с наибольшим значением логарифма вероятности останется наиболее вероятным. Тогда:
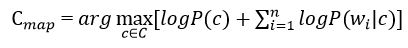
Рисунок 6 – Оценка апостериорного максимума с условной вероятностью документа
Далее необходимо провести оценку вероятности класса и слова в классе. Они рассчитывается по формулам:
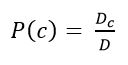
Рисунок 7 – Оценка вероятности класса
где Dc – количество документов принадлежащих классу с; D – общее количество документов в обучающей выборке.
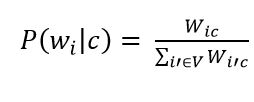
Рисунок 8 – Оценка вероятности слова в классе
где V - словарь корпуса документов (список всех уникальных слов)
Следующим шагом необходимо применить аддитивное сглаживание (сглаживание Лапласа). Это нужно для того чтобы слова, которые не встречались на этапе обучения классификатора не имели нулевую вероятность. Следовательно, необходимо прибавить единицу к частоте каждого слова.
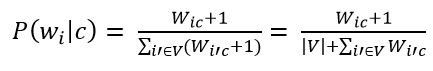
Рисунок 9 – Оценка вероятности слова в классе с прибавлением единицы
Подставив все полученные оценки вероятностей (формулы на рисунках 7 и 9) получим окончательную формулу модели наивного байесовского классификатора.
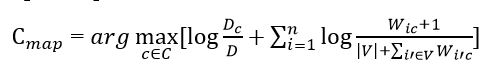
Рисунок 10 – Формула наивного байесовского классификатора
Метод Байеса используется для определения несанкционированных рекламных рассылок по электронной почте (спама). При этом рассматривается учебная база — два массива электронных писем, один из которых составлен из спама, а другой — из обычных писем. Для каждого из корпусов подсчитывается частота использования каждого слова, после чего вычисляется весовая оценка (от 0 до 1), которая характеризует условную вероятность того, что сообщение с этим словом является спамом. Значение веса, близкое к 0.5, не учитываются при интегрированном подсчете, поэтому слова с такими весами игнорируются и изымаются из словарей. [11]
Плюсами данного подхода к фильтрации спама являются:
- Метод наивного байесовского классификатора прост в использовании
- Обладает высокой эффективностью в отсеивании спама
- Высокая скорость работы
- Hа данном методе простроены большое количество современных спам-фильтров ( Mozilla Thunderbird 0.8, BayesIt! 0.6.0, SpamAssassin 3.0.0 rc3). [12]
Впрочем, у метода есть и принципиальный недостаток: он базируется на предположении, что одни слова чаще встречаются в спаме, а другие — в обычных письмах, и неэффективен, если данное предположение неверно. Впрочем, как показывает практика, такой спам даже человек не в состоянии определить «на глаз» — только прочтя письмо и поняв его смысл. Существует также алгоритмы, позволяющие добавить много лишнего текста, иногда тщательно подобранного, чтобы «обмануть» фильтр.
Еще один, не принципиальный, недостаток, связанный с реализацией — метод работает только с текстом. Зная об этом ограничении, можно вкладывать рекламную информацию в картинку, текст же в письме либо отсутствует, либо не несет смысла. Против этого приходится пользоваться либо средствами распознавания текста, либо старыми методами фильтрации — «черные списки» и регулярные выражения (так как такие письма часто имеют стереотипную форму).
4.3 Метод опорных векторов
Метод опорных векторов (Support Vector Mashine, SVM) относится к группе граничных методов классификации. Он определяет принадлежность объектов к классам с помощью границ областей. Будем рассматривать только бинарную классификацию, т. е. классификацию только по двум категориям c и c1, принимая во внимание то, что этот подход может быть расширен на любое конечное количество категорий. Предположим, что каждый объект классификации является вектором в N-мерном пространстве. Каждая координата вектора — это некоторый признак, количественно тем больший, чем больше этот признак выражен в данном объекте. Преимущества метода:
- Один из наиболее качественных методов;
- Возможность работы с небольшим набором данных для обучения;
- Сводимость к задаче выпуклой оптимизации, имеющей единственное решение.
Недостатки метода: сложная интерпретируемость параметров алгоритма и неустойчивость по отношению к выбросам в исходных данных.[13]
4.4 Алгоритм k-ближайших соседей
Метод близлежащих соседей — простой метрический классификатор, базирующийся в оценивании сходства объектов. Классифицируемый объект принадлежит к тому классу, которому относятся близкие к нему объекты обучающей подборки. один из простых алгоритмов систематизации, по этой причине в настоящих задачах он нередко оказывается малоэффективным. Кроме точности систематизации, вопросом данного классификатора считается темп систематизации: в случае если в учащей выборке N объектов, в тестовом выборе M объектов, но размерность пространства — K, в таком случае число действий с целью систематизации испытательной подборки может быть оценено равно как O(K*M*N). Данный метод при идентификации спама не достигает высокой точности, что делает его достаточно неэффективным при фильтрации не нужной информации. [14]
Преимущества метода:
- Возможность обновления обучающей выборки без переобучения классификатора;
- Устойчивость алгоритма к аномальным выбросам в исходных данных относительно простая программная реализация алгоритма;
- Легкая интерпретируемость результатов работы алгоритма;
- Хорошее обучение в случае с линейно неразделимыми выборками.
Недостатки метода:
- Репрезентативность набора данных, используемого для алгоритма
- Высокая зависимость результатов классификации от выбранной метрики
- Большая длительность работы из-за необходимости полного перебора обучающей выборки
- Невозможность решения задач большой размерности по количеству классов и документов.
5. Выводы
В ходе выполнения данной работы проанализированы алгоритмы и классификации для идентификации информации. После детального изучения, были выявлены недостатки и плюсы рассмотренных подходов. Как результат проделанного обзора можно отметить следующие направления исследований:
- Подробное исследование байесовского классификатора
- Разработка комбинированных способов
В частности, интерес представляет метод байесовского классификатора, так как он обладает более высокой достоверностью и достаточно прост в реализации. Перспективами исследования являются разработка собственного алгоритма классификации спама на основе наивного байесовского классификатора.
Список источников
- Irina Rish, An Empirical Study of the Naïve Bayes Classifier, T.J. Watson Research Center, 2001, Режим доступа: [Ссылка]
- Wayne Iba, Kevin Thompson, An Analysis of Bayesian Classifiers, NASA Ames Research Center, 1992, Режим доступа: [Ссылка]
- Бурлаков М. Е., Применение в задаче классификации SMS сообщений оптимизированного наивного байесовского классификатора, Самарский национальный исследовательский университет им. С.П. Королёва, 2016 Режим доступа: [Ссылка]
- Трифонов П. В., Повышение точности байесовского классификатора текстовых документов, Научно-технические ведомости СПбГТУ 1' 2010, 2019 Режим доступа: [Ссылка]
- Lomakina L.S.Lomakin D.V.Subbotin A.N., Naïve Bayes modification for text Streams classification, Nizhny Novgorod State Technical University n.a. R.E. Alekseev, 2016 Режим доступа: [Ссылка]
- Лютова Е.И., Коломойцева И.А., История возникновения спама и способы противодействия его распространению, Донецкий национальный технический университет, 2020, Режим доступа: [Ссылка на сборник]
- Титаренко М.Г., Исследование методов классификации информации о внешнеторговой деятельности государств в рамках информационно-поисковой системы, Донецкий национальный технический университет, 2018 Режим доступа: [Ссылка]
- Власюк Д. А., Исследование методов извлечения знаний из HTML-страниц сети Интернет о спортивных соревнованиях, Донецкий национальный технический университет, 2018 Режим доступа: [Ссылка]
- Агеев М С. Методы автоматической рубрикации текстов, основанные на машинном обучении и знаниях экспертов// Московский Государственный Университет им. М.В. Ломоносова Режим доступа: [Ссылка]
- Наивный байесовский классификатор [электронный ресурс] Режим доступа: [Ссылка]
- Ландэ Д.В., Снарский А.А., Безсуднов И.В. Интернетика:Навигация в сложных сетях: модели и алгоритмы. Книжный дом «Либроком», 2009. – 88-89 с.
- Применимость байесовского классификатора для задачи определения спама [электронный ресурс] Режим доступа: [Ссылка]
- Метод опорных векторов [электронный ресурс] Режим доступа: [Ссылка]
- Метод ближайших соседей [электронный ресурс] Режим доступа: [Ссылка]