
Реферат по темі випускної роботи
Зміст
- Введення
- 1. Актуальність теми
- 2. Мета і завдання дослідження, плановані результати
- 3. Огляд досліджень і розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4 Аналіз існуючих методів пошуку і класифікації інформації
- 4.1 Основні етапи класифікації
- 4.2 Наївний байеовскій класифікатор
- 4.3 Метод опорних векторів
- 4.4 Алгоритм k-найближчих сусідів
- Висновки
- Список джерел
Введення
Одним з напрямків досліджень в області захисту інформації є розробка методів і алгоритмів фільтрації потоку електронної пошти. Останнім часом електронна пошта стала одним з найбільш поширених засобів зв'язку, управління і бізнесу.
Швидке зростання популярності електронних засобів комунікації, в тому числі електронної пошти, а також низька вартість їх використання призводить до збільшується потоку несанкціонованих масових розсилок.
Більшість методів і алгоритмів класифікації фільтрації спаму працюють недостатньо точно на відміну від байєсівського класифікатора. У зв'язку з цьому є необхідність створення фільтра інформації на основі байєсівського класифікатора.
1. Актуальність проблеми
Швидке зростання популярності електронних засобів комунікації, в тому числі електронної пошти, а також низька вартість їх використання призводить до збільшується потоку несанкціонованих масових розсилок. Несанкціоновані розсилки наносять очевидний збиток - це реальні матеріальні втрати компаній і користувачів мережі. Зайве навантаження на мережі та обладнання, витрачений час на сортування і видалення листів, витрачені гроші на оплату трафіку - це неповний перелік проблем, які приносить спам. Часто спам використовується в якості каналу для поширення вірусів.
Проблемою класичної класифікації спаму на основі методу Байєса є те, що вона базується на правилі що одні слова, зустрічаються частіше в спам, а інші в звичайних листах. І цей алгоритм є неефективним, якщо це припущення невірно.
Так як проблема спаму на сьогоднішній день стоїть досить гостро, дослідження і розробка поліпшеного алгоритму класифікації спаму на основі методу Байєса є актуальним.
2. Мета і завдання дослідження, плановані результати
Основною метою роботи є збільшення ефективності роботи класифікатора для спаму на базі методу Байеса.
Основні завдання:
- Аналіз існуючих методів пошуку і класифікації спаму;
- Проектування алгоритму класифікації спаму
- Реалізація алгоритму класифікації спаму на базі методу Байеса
- Оцінка ефективності класифікації спаму.
Новизна полягає в розробці поліпшеного класифікатора спаму на базі методу Байеса.
Планується, що отримані в дисертації результати досліджень можуть бути використані при розробці класифікаторів інформації в Інтернет, що дозволяють виробляти виявлення спам-документів.
3. Огляд досліджень і розробок
Досліджувана тема популярна не тільки в міжнародних, але і в національних наукових спільнотах.
Поряд з цим в даному розділі буде представлений огляд досліджень в області класифікації інформації, зокрема застосування в цих цілях байєсівського класифікатора як американськими, європейськими, китайськими вченими, так і вітчизняними фахівцями.
3.1 Огляд міжнародних джерел
В роботі «Емпіричне дослідження байєсівського класифікатора», Ріш. І. [ 1 ], розглядається розбір характеристик даних, які впливають на ефективність наявного байєсівського методу. У роботі використовується метод Монте-Карло, які дозволяє систематично вивчати точність класифікації для декількох класів згенерованих завдань. Аналізується вплив ентропії розподілу на помилку класифікації, показуючи, що нізкоентропійние розподілу ознак дають хороші характеристики наявного Байеса. ,
У статті «Аналіз байесовских класифікаторів» Іба.В, Томпсона.К. [ 2 ], проводиться аналіз байєсівського класифікатора шляхом обчислення ймовірності того, що алгоритм викличе довільну пару описів понять, потім цей вислів використовується для обчислення правильної класифікації по простору ймовірності примірників. Крім того, автори статті проводять дослідження поведінкового наслідки аналізу, представляючи прогнозовані криві навчання для ряду штучних областей.
3.2 Огляд національних джерел
В роботі «Застосування в завданні класифікації SMS повідомлень оптимізованого наївного байєсівського класифікатора», Бурлакова М. Е. [ 3 ], розглядається процес оптимізації наявного байєсівського класифікатора. Також розглянуто механізм розрахунку ймовірності і процес побудови навчальної таблиці для практичного вирішення завдання класифікації SMS повідомлень наївним Байєсова класифікатором.
У статті «Підвищення точності байєсівського класифікатора текстових документів», Трифонова П. В. [ 4 ], розглядаються способи поліпшення байєсівського класифікатора шляхом побудови по заданому набору документів, класифікація яких була виконана експертами вручну, деякою моделі, яка може бути використана в подальшому для прийняття рішення про належність документів до зазначеними категоріями.
В роботі «Модифікація наївного байєсівського класифікатора», Ломакіної Л.С, Ломакіна Д.В., Суботіна А.Н. [ 5 ], розглядається модифікація наївною байєсівської класифікації потоків текстової інформації. Також в статті запропоновано реальний класифікатор, що дозволяє обробляти текстові потоки в режимі реального часу.
У статті «Історія виникнення спаму і способи протидії його поширенню» Лютов Є.І., Коломойцевої І.А. [ 6 ], розглянута історія виникнення небажаної масової розсилки, а також відомі способи боротьби з нею. Проаналізовано програмне забезпечення для фільтрації спаму.
3.3 Огляд локальних джерел
В рефераті Титаренко Михайла Геннадійовича «Дослідження методів класифікації інформації про зовнішньоторговельної діяльності держав в рамках інформаційно-пошукової системи" [ 7 ] проводиться огляд і аналіз алгоритмів бінарної класифікації інформації про зовнішньоторговельної діяльності держав. Також було розглянуто розрахунок метрик для алгоритмів і порівняння результатів роботи класифікаторів класифікації інформації.
В рефераті Власюка Дмитра Олександровича «Дослідження методів вилучення знань з HTML-сторінок мережі Інтернет про спортивні змагання» [ 8 ] був представлений аналіз методів вилучення знань з мережі Інтернет і їх зберігання. Також було проведено розбір моделей баз даних і зберігання інформації про спортивні змагання.
4 Аналіз існуючих методів пошуку і класифікації інформації
4.1 Основні етапи класифікації
Перший етап рішення задачі автоматичної класифікації текстів - це перетворення документів. На цьому етапі документи, що мають вигляд послідовності символів, перетворюються до вигляду, придатного для алгоритмів машинного навчання відповідно до завданням класифікації. Зазвичай алгоритми машинного навчання мають справу з векторами в просторі, званому простором ознак [ 9 ].
Другим етапом є побудова классифицирующей функції Ф` за допомогою навчання на прикладах. Якість класифікації залежить і від того, як документи будуть перетворені в векторне подання, і від алгоритму, який буде застосований на другому етапі. При цьому важливо відзначити, що методи перетворення тексту в вектор специфічні для завдання класифікації текстів таможуть залежати від колекції документів, типу тексту (простий, структурований) і мови документа. Методи машинного навчання, які застосовуються на другому етапі, не є специфічними для завдання класифікації текстів і застосовуються також в інших областях, наприклад, для завдань розпізнавання образів.
Отже, класична задача класифікації може бути розбита на два основних етапи:
- Передобробка / Індексація - відображення тексту документа на його логічне уявлення, наприклад, вектор ваг 𝑑𝑗 ̅, який потім подається на вхід алгоритму класифікації.
- Класифікація / Навчання - етап класифікації документа або навчання на безлічі документів, заснований на логічному уявлення документа. Важливо відзначити, що для класифікації та навчання може бути використаний загальний метод предобработки / індексації текстів.
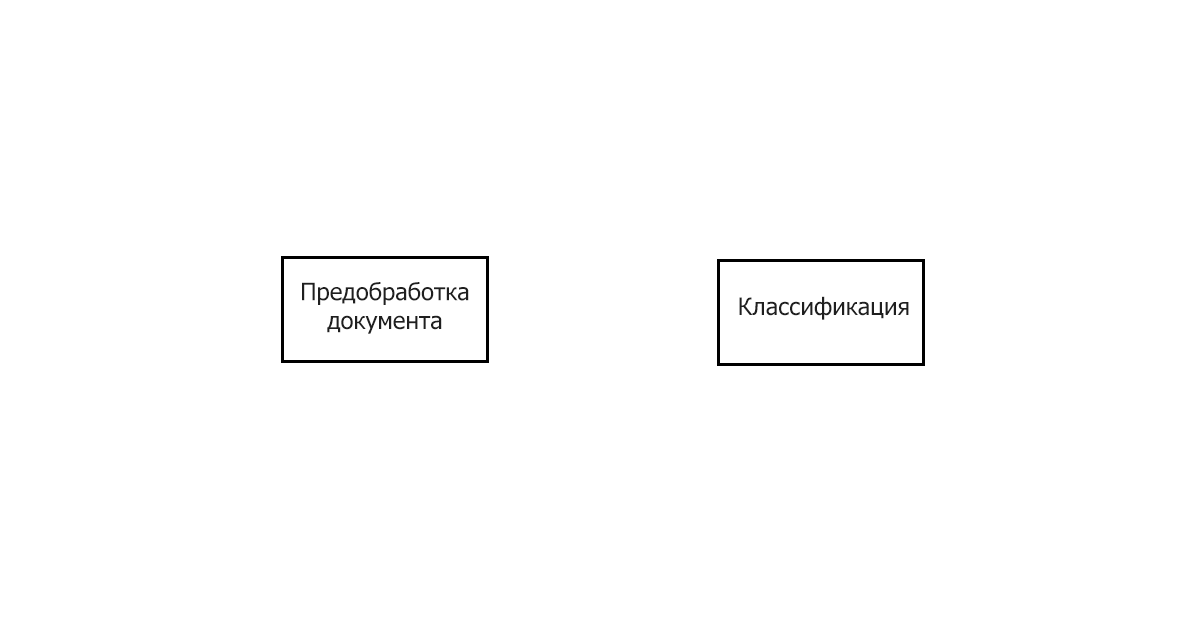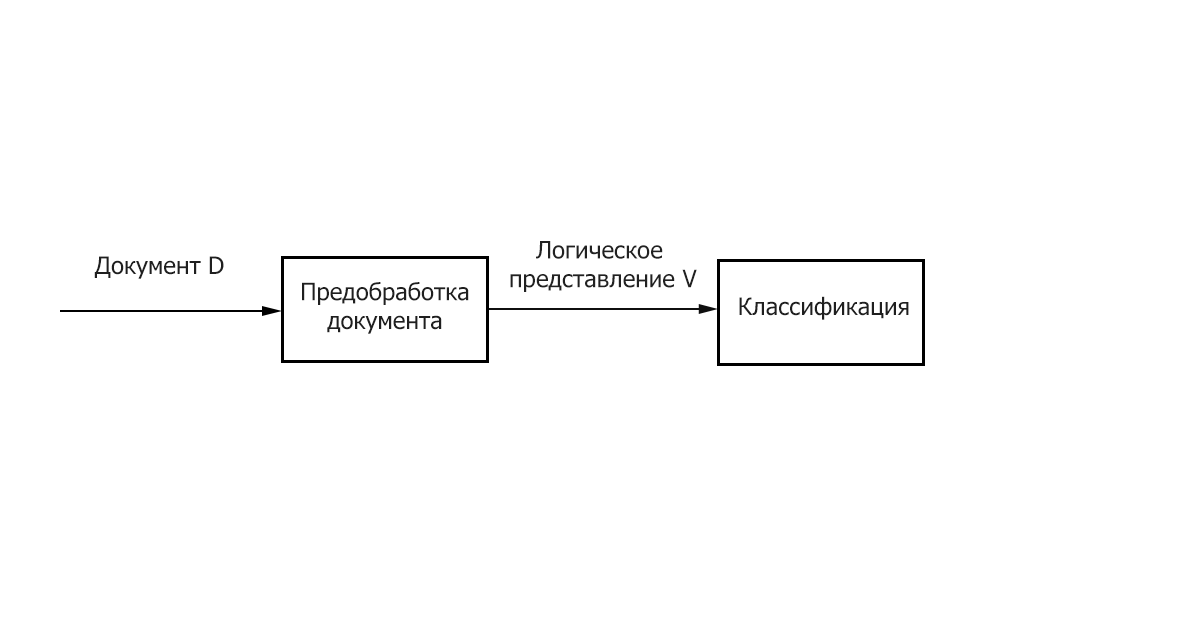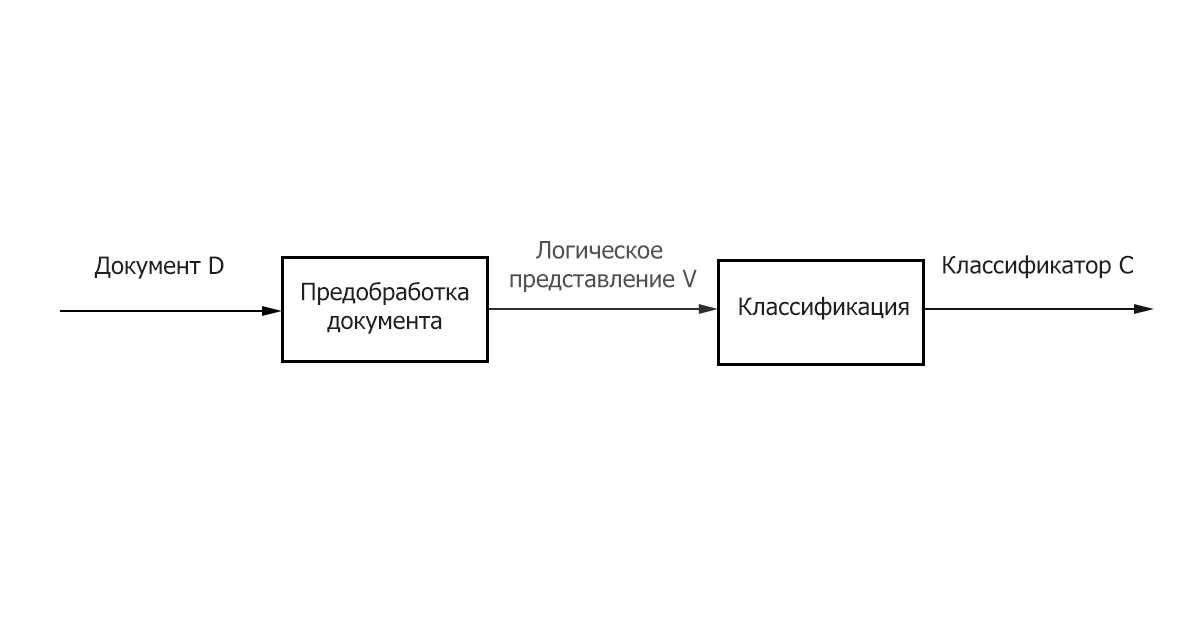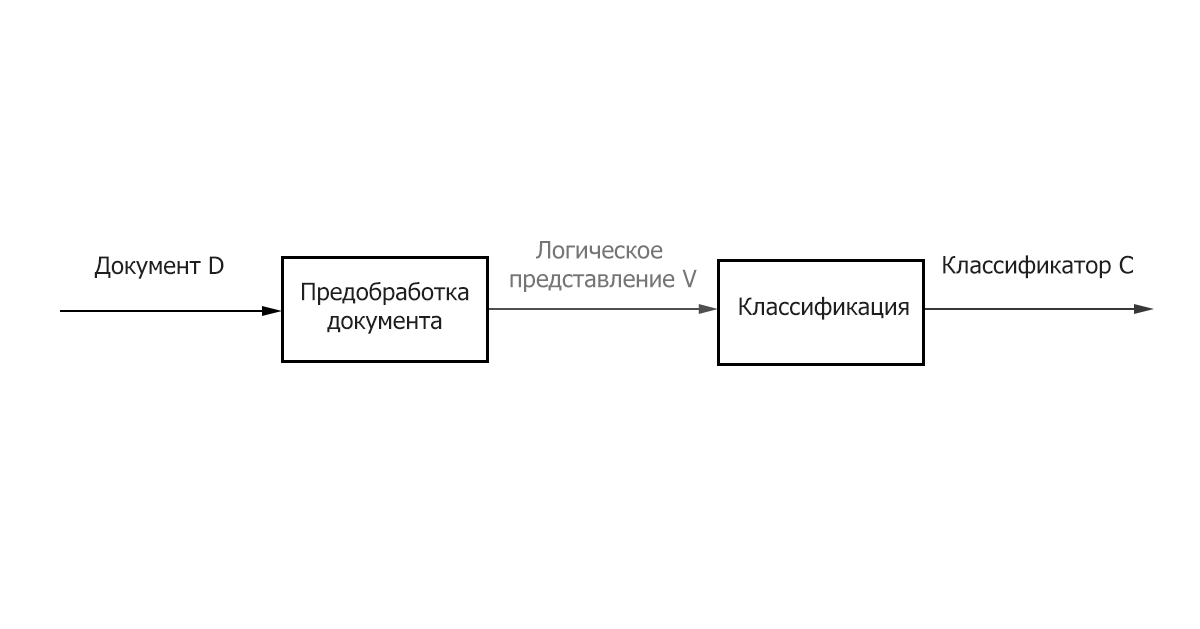
Малюнок 1 – Основні етапи класифікації
(анімація: 10 кадрів,
цикл повторень: 7, розмір: 163 кілобайт)
4.2 Наївний байесовский класифікатор
В основі наївною байєсівської моделі лежить теорема Байеса:
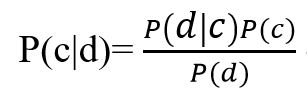
Малюнок 2 – Формула теореми Байеса
де, P (c | d) - ймовірність що документ d належить класу c, саме її нам треба розрахувати; P (d | c) - ймовірність зустріти документ d серед всіх документів класу c; P (c) - безумовна ймовірність зустріти документ класу c в корпусі документів; P (d) - безумовна ймовірність документа d в корпусі документів.
Теорема Байєса дозволяє переставити місцями причину і наслідок. Знаючи з якою ймовірністю, причина призводить до якогось події, ця теорема дозволяє розрахувати ймовірність того що саме ця причина призвела до нинішнього події.
Мета класифікації полягає в тому щоб зрозуміти до якого класу належить документ, тому необхідно не сама ймовірність, а найбільш ймовірний клас. Байєсівський класифікатор використовує оцінку апостеріорного максимуму (Maximum a posteriori estimation) для визначення найбільш вірогідного класу. Грубо кажучи, це клас з максимальною ймовірністю [ 10 ].
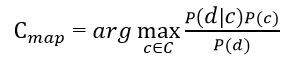
Малюнок 2 – Оцінка апостеріорного максимуму
Необхідно розрахувати ймовірність для всіх класів і вибрати той клас, який володіє максимальною вірогідністю. Варто звернути увагу на те, що знаменник (ймовірність документа) у формулі на малюнку 2 є константою і ніяк не може вплинути на ранжування класів, тому його можна опустити.
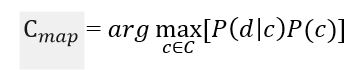
Малюнок 3 – Оцінка апостеріорного максимуму без знаменника
«Наявність» даної моделі класифікатора полягає в тому, що вона використовує наївне припущення, що слова, що входять до тексту документа незалежні один від одного. Виходячи з цього умовна ймовірність документа апроксимується твором умовних ймовірностей всіх слів, що входять в документ.
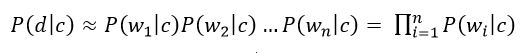
Малюнок 4 – Твір умовних ймовірностей всіх слів, що входять в документ
де w i - кількість разів скільки i-е слово зустрічається в документах класу c
Підставивши отриманий вираз в формулу на малюнку 3 отримаємо:
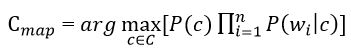
Малюнок 5 & ndash; Оцінка апостеріорного максимуму з логарифмами ймовірностей
У формулі на малюнку 5 найчастіше використовують замість самих ймовірностей використовують логарифм цих ймовірностей. Оскільки логарифм - монотонно зростаюча функція, то клас з з найбільшим значенням логарифма ймовірності залишиться найбільш імовірним. Тоді:
Малюнок 6 & ndash; Оцінка апостеріорного максимуму з умовною ймовірністю документа 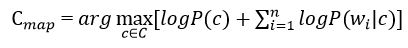
Далі необхідно провести оцінку ймовірності класу і слова в класі. Вони розраховується за формулами:
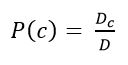
Малюнок 7 – Оцінка ймовірності класу
де D c – кількість документів належать класу з ; D – загальна кількість документів в навчальній вибірці.
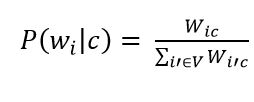
Малюнок 8 – Оцінка ймовірності слова в класі
де V - словник корпусу документів (список всіх унікальних слів)
Наступним кроком необхідно застосувати аддитивное згладжування (згладжування Лапласа). Це потрібно для того щоб слова, які не зустрічалися на етапі навчання класифікатора не мали нульову ймовірність. Отже, необхідно додати одиницю до частоти кожного слова.
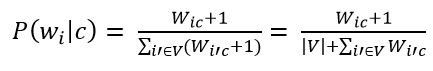
Малюнок 9 – Оцінка ймовірності слова в класі з додатком одиниці
Підставивши всі отримані оцінки ймовірностей (формули на малюнках 7 і 9) отримаємо остаточну формулу моделі наївного байєсівського класифікатора.
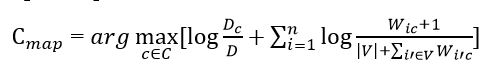
Малюнок 10 – Формула наївного байєсівського класифікатора
Метод Байєса використовується для визначення несанкціонованих рекламних розсилок по електронній пошті (спаму). При цьому розглядається навчальна база - два масиви електронних листів, один з яких складено з спаму, а інший - зі звичайних листів. Для кожного з корпусів підраховується частота використання кожного слова, після чого обчислюється вагова оцінка (від 0 до 1), яка характеризує умовну ймовірність того, що повідомлення з цим словом є спамом. Значення ваги, близьке до 0.5, не враховуються при інтегрованому підрахунку, тому слова з такими вагами ігноруються і вилучаються зі словників. [ 11 ]
Плюсами даного підходу до фільтрації спаму є:
- Метод наївного байєсівського класифікатора простий у використанні
- Має високу ефективність в відсівання спаму
- Висока швидкість роботи
- Hа цьому методі збудувати велику кількість сучасних спам-фільтрів (Mozilla Thunderbird 0.8, BayesIt! 0.6.0, SpamAssassin 3.0.0 rc3). [ 12 ]
Втім, у методу є і принциповий недолік: він базується на припущенні, що одні слова частіше зустрічаються в спам, а інші - в звичайних листах, і неефективний, якщо це припущення невірно. Втім, як показує практика, такий спам навіть людина не в змозі визначити «на око» - тільки прочитавши лист і зрозумівши його зміст. Існує також алгоритми, що дозволяють додати багато зайвого тексту, іноді ретельно підібраного, щоб «обдурити» фільтр.
Ще один, не принципове, недолік, пов'язаний з реалізацією - метод працює тільки з текстом. Знаючи про це обмеження, можна вкладати рекламну інформацію в картинку, текст ж в листі або відсутня, або не несе сенсу. Проти цього доводиться користуватися або засобами розпізнавання тексту, або старими методами фільтрації - «чорні списки» і регулярні вирази (так як такі листи часто мають стереотипну форму).
4.3 Метод опорних векторів
Метод опорних векторів (Support Vector Mashine, SVM) відноситься до групи граничних методів класифікації. Він визначає приналежність об'єктів до класів за допомогою кордонів областей. Будемо розглядати тільки бінарну класифікацію, т. Е. Класифікацію тільки за двома категоріями c і c1 , беручи до уваги те, що цей підхід може бути розширений на будь-яке кінцеве кількість категорій. Припустимо, що кожен об'єкт класифікації є вектором в N-вимірному просторі. Кожна координата вектора - це деяка ознака, кількісно тим більший, чим більше ця ознака виражений в даному об'єкті. Переваги методу:
- Один з найбільш якісних методів;
- Можливість роботи з невеликим набором даних для навчання;
- зводяться до задачі опуклою оптимізації, що має єдине рішення.
Недоліки методу: складна интерпретируемость параметрів алгоритму і нестійкість по відношенню до викидів у вихідних даних. [ 13 ]
4.4 Алгоритм k-найближчих сусідів
Метод прилеглих сусідів - простий метричний класифікатор, який базується в оцінюванні подібності об'єктів. Класифікується об'єкт належить до того класу, якому належать близькі до нього об'єкти навчальної вибірки. один з простих алгоритмів систематизації, з цієї причини в справжніх завданнях він нерідко виявляється малоефективним. Крім точності систематизації, питанням даного класифікатора вважається темп систематизації: в разі якщо в учащей вибірці N об'єктів, в тестовому виборі M об'єктів, але розмірність простору - K, в такому випадку число дій з метою систематизації випробувальної добірки може бути оцінений так само як O (K * M * N). Даний метод при ідентифікації спаму не досягає високої точності, що робить його досить неефективним при фільтрації не потрібної інформації. [ 14 ]
Переваги методу:
- Можливість поновлення навчальної вибірки без перенавчання класифікатора;
- Стійкість алгоритму до аномальних викидів у вихідних даних щодо проста програмна реалізація алгоритму;
- Легка интерпретируемость результатів роботи алгоритму;
- Гарне навчання у випадку з лінійно нероздільними вибірками.
Недоліки методу:
- Репрезентативність набору даних, що використовується для алгоритму
- Висока залежність результатів класифікації від обраної метрики
- Велика тривалість роботи через необхідність повного перебору навчальної вибірки
- Неможливість розв'язання задач великої розмірності за кількістю класів та документів.
5. Висновки
В ході виконання даної роботи проаналізовано алгоритми і класифікації для ідентифікації інформації. Після детального вивчення, були виявлені недоліки та плюси розглянутих підходів. Як результат зробленого огляду можна відзначити наступні напрямки досліджень:
- Докладне дослідження байєсівського класифікатора
- Розробка комбінованих способів
Зокрема, інтерес представляє метод байєсівського класифікатора, так як він володіє більш високою вірогідністю і досить простий в реалізації. Перспективами дослідження є розробка власного алгоритму класифікації спаму на основі наявного байєсівського класифікатора.
Список джерел
- Irina Rish, An Empirical Study of the Naïve Bayes Classifier, T.J. Watson Research Center, 2001, Режим доступа: [Ссылка]
- Wayne Iba, Kevin Thompson, An Analysis of Bayesian Classifiers, NASA Ames Research Center, 1992, Режим доступа: [Ссылка]
- Бурлаков М. Е., Применение в задаче классификации SMS сообщений оптимизированного наивного байесовского классификатора, Самарский национальный исследовательский университет им. С.П. Королёва, 2016 Режим доступа: [Ссылка]
- Трифонов П. В., Повышение точности байесовского классификатора текстовых документов, Научно-технические ведомости СПбГТУ 1' 2010, 2019 Режим доступа: [Ссылка]
- Lomakina L.S.Lomakin D.V.Subbotin A.N., Naïve Bayes modification for text Streams classification, Nizhny Novgorod State Technical University n.a. R.E. Alekseev, 2016 Режим доступа: [Ссылка]
- Лютова Е.И., Коломойцева И.А., История возникновения спама и способы противодействия его распространению, Донецкий национальный технический университет, 2020, Режим доступа: [Ссылка на сборник]
- Титаренко М.Г., Исследование методов классификации информации о внешнеторговой деятельности государств в рамках информационно-поисковой системы, Донецкий национальный технический университет, 2018 Режим доступа: [Ссылка]
- Власюк Д. А., Исследование методов извлечения знаний из HTML-страниц сети Интернет о спортивных соревнованиях, Донецкий национальный технический университет, 2018 Режим доступа: [Ссылка]
- Агеев М С. Методы автоматической рубрикации текстов, основанные на машинном обучении и знаниях экспертов// Московский Государственный Университет им. М.В. Ломоносова Режим доступа: [Ссылка]
- Наивный байесовский классификатор [электронный ресурс] Режим доступа: [Ссылка]
- Ландэ Д.В., Снарский А.А., Безсуднов И.В. Интернетика:Навигация в сложных сетях: модели и алгоритмы. Книжный дом «Либроком», 2009. – 88-89 с.
- Применимость байесовского классификатора для задачи определения спама [электронный ресурс] Режим доступа: [Ссылка]
- Метод опорных векторов [электронный ресурс] Режим доступа: [Ссылка]
- Метод ближайших соседей [электронный ресурс] Режим доступа: [Ссылка]