
ВОЗМОЖНЫЕ НЕДОСТАТКИ И СЛОЖНОСТИ ПРИ РАЗРАБОТКЕ МОДУЛЯ РАСПОЗНАВАНИЯ РЕЧИ
Содержание
- Введение
- 1. Актуальность темы
- 2. Основные проблемы при распознавании речи
- 2.1 Проблемы помехоустойчивости речи
- 2.2 Недостатки интерфейса
- 2.3 Внешние шумы
- 2.4 Проблемы семантики
- 2.5 Инвестиции и спрос
- 3. Планируемые практические результаты
- 3.1 Обзор исследований и разработок по теме
- 4. Разработка голосового механизма распознавания речи
- 4.1 Обзор национальных источников
- 4.2 Основный составляющие распознающей системы
- Выводы
- Список источников
В эпоху интернета, почти каждому человеку доступны его блага такие как: смартфоны, планшеты, ноутбуки с некоторым набором в них приложений. Данные ПО (программное обеспечение) создаются для развлечения, упрощения связи с близкими, помощи в работе, учёбе, и т.п. Их основная цель упростить или слегка разнообразить жизнь. Количество таких приложений возрастает в геометрической прогрессии с каждым днём, но реальная полезность для пользователя каждого такого ПО в среднем и в общей статистике небольшое. Общий высокий уровень их бесполезности возникает из-за преобладания программ, у которых основное направление – развлечение некоторой аудитории пользователей, над теми которые созданы под решение конкретных задач, таких как управление электронными или цифровыми устройствами голосом.
За прошедшие десятилетия появилось не мало программ для распознавания голоса, но самый пик точности распознавания речи в целом пришелся на конец девяностых – начало двухтысячных. Эффективность современных систем различать параметры и свойства речи находится на уровне примерно 80 % точности, тогда как у человека этот показатель достигает 95% [1].
На сегодняшний день существует большое множество направлений для развития звуко-обрабатывающих технологий таких, как: системы автоматического распознавания речи (САРР), которые используются для обеспечения голосового диалога между человеком и компьютером или голосовых ключей, обеспечивающих голосовое распознавание личности. Рассмотренное направление роста систем обработки речи является очень перспективным, так как кроме высокой востребованности в бизнесе и повседневной жизни, может создать симбиоз с другими проектами-гигантами на рынке инвестиций, ими являются системы искусственного интеллекта и интернета вещей. Данные возможности позволяют экспоненциально развиваться в ближайшие десять лет, благодаря большим инвестициям и растущим спросом на программы распознавания речи [2].
2 Основные проблемы при распознавании речи
2.1 Проблемы помехоустойчивости речи
Данная проблема заключается в первую очередь в наличии шумов при записи речи. У каждого человека своя манера ведения диалога, а также произношения и акцент, всё это может плохо влиять на качество разбора голосовых данных системой при записи и распознавании речи. Наиболее заметными погрешности в случаях, когда будет существовать необходимость в нескольких дикторах, так как при одном систему легче приспособить к некоторым голосовым, человеческим характеристикам. [3]
Характерной особенностью говора человека необходимо учитывать слитная у него речь, или наоборот раздельная. Первый тип усложняет распознание слов, так как при таком произношении труднее голосовому приложению различать границы слов диктора. [4] Таким образом, необходимо чтобы была дикторо-зависимая система смогла точно и с первой попытки «расслышать» весь диалог. Следовательно, для системы необходимо определить минимально нижний временной порог паузы между словами, при произношении, чтобы речь не была слитной.
Разрабатываемое приложение, по работе со звуком, должно быть ориентировано, при формировании интерфейса, как на профессионального пользователя компьютером, так и на новичка. Оболочка программы должна быть нативной, то есть должна быть легка в освоении и понятна с первого раза её использования. Стоит также учитывать наличие адаптивной вёрстки, с той целью, чтобы приложение возможно было открыть в любом браузере на любом типе устройств, без изменения первоначальной вёрстки.
2.3 Внешние шумы
Не маловажный фактор точно понятого слова или целого предложения системой это показатель окружающих звуков вещателя, т.е. шумов. Для человека уровень шума не так важен, как устройству для распознавания речи, т.к. человек способен хорошо различать слова даже при показателе 80-90 дБ что равнозначно шуму на автобусной остановке или рядом работающему мотоциклу. Но с рассматриваемой «электроникой» не всё так однозначно, потому что она не способна научиться точно различать семантические особенности любого из известных языков мира, речь идёт об нейросетях (машинном обучении), из-за нецелесообразности или невозможности собрать необходимое, достаточное количество данных для идентификации в разговоре диктора омофонов. При игнорировании вышеописанного в полтора раза увеличивается вероятность неверного определения слов, что видно на диаграмме 1 [5]. Следовательно, для уменьшения затрат на борьбу с внешними шумами стоит их минимизировать при записи речи диктора для её распознавания системе.
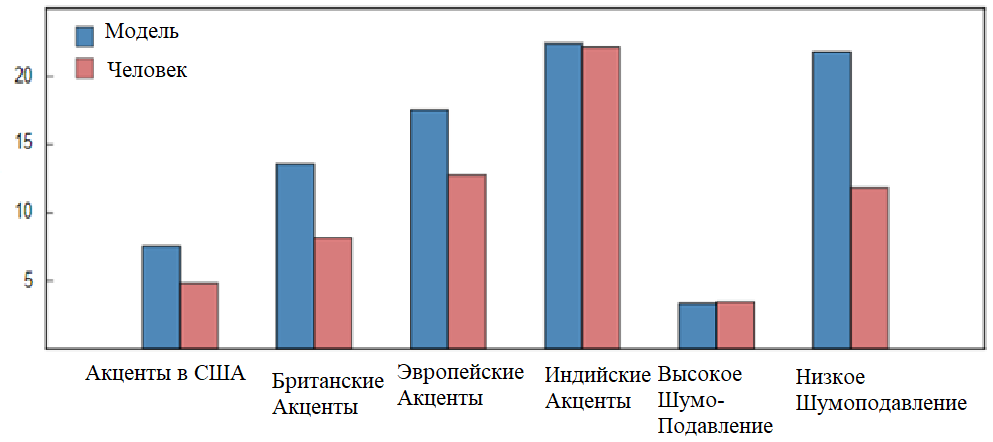
Диаграмма 1 – Уровень ошибочного произношения слов машины и человека, на разных языках.
Также плохо влияет на качество работы системы наличие дикторов более одного. Люд и могут воспринимать информацию из нескольких источников одновременно, в отличии от соответствующих устройств. Однако возможно сделать такое приложение, которое было бы много потоковым, т. е. могло воспринимать речь нескольких человек одновременно. Или можно запрограммировать распознающее устройство так, чтобы запись текста происходила бы только при распознавании голоса конкретного диктора. Распознавание дикторов может быть разделено на идентификацию и верификацию диктора. Идентификация диктора – это процесс определения, кто из зарегистрированных дикторов произнес фразу. Верификация диктора – это процесс принятия или отклонения заявленной личности диктора. Большинство приложений, в которых используется голос подтверждают личность диктором, классифицируемым верификацией диктора [6]. Поэтому необходимо заранее определиться с тем, что нужно сделать систему, которая четко выполняет задачи при минимальных дополнительных затратах, или систему, которая сможет выполнить всё то же, но в любых условиях и при излишних затратах.
Следующие источники внешних голосов или их первопричины можно разделить на такие типы:
- Использование кодеков не подходящих для устранения всех возможных шумов
- Недостатки программного обеспечения, суть которых заключается в отсутствии баланса между производительностью приложения и качеством выполненной ею работой.
- Наличие реверберации из-за особенностей помещений, в которых может использоваться данная система распознавания речи, и неспособность вышеописанных кодеков решить данную задачу (рис.2)[5].
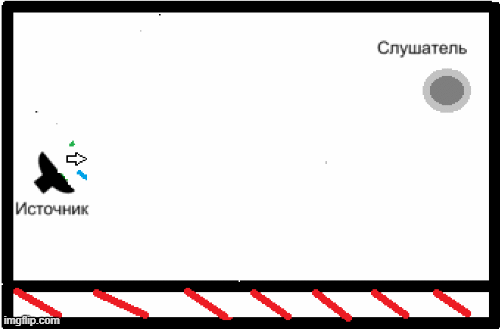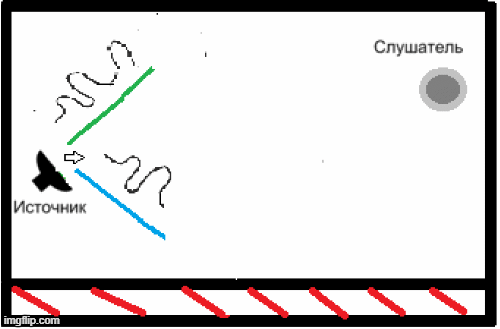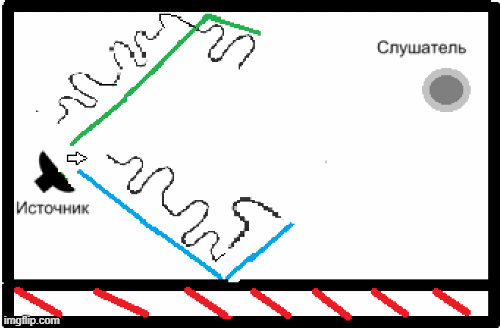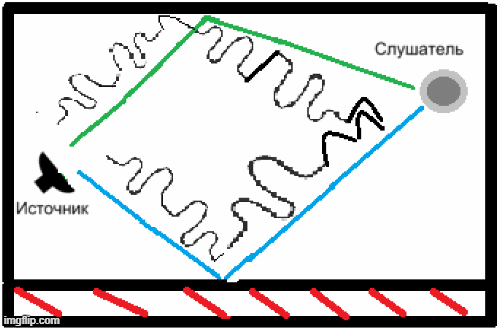
Рисунок 2 – Пример появления реверберации в закрытом помещении.
В повседневной речи каждого человека происходят лексические, стилистические, фразеологические и другие произносительные ошибки. Стоит также отметить присутствие в разговоре омографов и омофонов, что очень отрицательно скажется на качестве работы распознающей системы так как омофоны оно может перепутать, но это легко исправить повторением неправильно сказанной фразы, а омограф – это ошибка, которая заложена в коде или памяти системы и решить проблему такого рода возможно с помощью разработчика этого приложения или технической поддержки.
2.5 Инвестиции и спрос
Для старта создания серьёзного любого приложения, интернет- или локального-, необходимо денежное финансирование. Его наличие необходимо для мотивации персонала, различные технические закупки, для исследований потребительского рынка и иных видов затрат. Исследования запросов рынка потенциальных и фактических потребителей способствует созданию четкого и удачного плана разработки и реализации проекта. Без исследований существующего спроса потребителей сложнее предугадать дальнейший, а в итоге это увеличивает риски краха почти любого «стартапа», потому что создание продукта должно угождать чьим-либо потребностям. Примером может послужить разработка программы-алгоритма по удалению шумов из аудио при общении в режиме онлайн, которая была создана для поспринимающих речь приложений как аналог и стала готова к использованию. Но для неё не нашлось покупателя, так как крупным производителям она не привнесла бы ощутимые изменения в работу зарекомендовавших уже систем.
Стоит отметить, что при отсутствии инвесторов может быть первичный капитал у руководителя проекта, что для самого проекта будет равносильно инвестициям. Но инвестор сэкономит время, потраченное на сбор своего капитала, может помочь продвижению стартапа, при условии, что уже есть работоспособная модель или прототип конечного продукта, ожидаемого в итоге. В обратном случае, если нет ни капитала, ни инвестиции, то уменьшатся шансы на наличие необходимого набора персонала (команда разработчиков), а также не будет возможности провести комплексное исследование рынка потребителей, что снизит шанс на успех.
3 Планируемые практические результаты
Итогом разработки системы распознавания речи планируется приложение, которое должно «воспринимать» обычный слитный диалог диктора. При имеющихся ресурсах следует достигнуть результата минимальной паузы между словами рядового пользователя около семисот миллисекунд. При этой планке, минимального времени, качество распознавания слов должно быть хорошим и в тоже время точным (с минимальным количеством погрешности). Данное приложение не должно мешать работе других процессов устройств, на которых оно будет установлено, а также не занимать свободное место оперативной памяти, сверх того что будет указано в рекомендуемых системных требованиях.
3.1 Обзор исследований и разработок по теме
В пределах ДонНТУ были проведены исследования по темам схожими с данной такие как: алгоритмы сегментации звука, в котором следовало упомянуть поиски границ согласных звуков с разделением на шипящие, звонкие и глухие, а также чистого голосового сигнала. В вышеуказанной работе была произведена подробная классификация звуков и фонем, что в итоге позволило более точно распознать глухие взрывные в конце сигнала, тем самым предоставляя возможность выделить их из участка тишины[7]].
Также стоит обратить внимание на ещё одну работу по интеграция визуального и речевого способов управления процессом ввода и редактирования текстовой информации методом нечёткого сопоставления и нечёткого DTW-сопоставления речевых образов. Речевой сигнал представляется в виде двумерного спектрального временного образа на основании чего возможно проводить сравнения методов распознавания речевых команд, что в дальнейшем поможет развитию DTW-сопоставлению звуковых команд [8].
В мировом масштабе можно выделить разработку звукового кодека для подавления внешних шумов компанией «2Hz». Целью разработки было достижение необходимого уровня удаления шумов, при передаче речи на устройство обработки звуков, за время, которое не достигло ни одно похожее время при минимальных затратах системной мощности устройства пользователя. Решением данной проблемы должна была заниматься созданная нейросеть, работающая со звуками на частотах 8 и 16 кГц для телефонов и VoIP-приложений соответственно. В итоге поставленные основные задачи были выполнены, а название кодек получил «Krisp» [9].
4 Разработка голосового механизма распознавания речи
4.1 Основный составляющие распознающей системы
Создание приложения по распознаванию речи подразумевает создание системы, при разработке которой необходимо учитывать ряд факторов, непосредственно влияющих на качество и работоспособность ожидаемого продукта в итоге. К таким факторам можно отнести наличие меток - начала разговора, использование специализированного ПО, дикторозависимость и т.д.
Метки, по которым устройство будет способно понимать, когда следует начинать записывать речь, т.е. некие «старт-слова». При произнесении этой метки должна происходить запись разговора, при этом пользователь заранее выбирает сколько будет происходить запись, к примеру пять секунд (если будут произноситься зарезервированные системой команды) или примерно минуту и более (для распознавания речи и преобразовать в текст или для схожих задач), при необходимости возможно добавить «стоп-слово» для остановки записи.
Также система должна содержать программы преобразующие данные звуковых сигналов, составляющие речь, называемые кодеками. Их задача будет состоять в устранении недостатков речи человека: плохая дикция, редкие разговорные акценты и т.д., таким образом эти программы должны будут убирать лишние шумы в ранее описанных ситуациях.
Следующей важной составляющей речевой системы является дикторозависимость, приложение может быть дикторозависимым или дикторонезависимым. Предлагаемая система будет ориентирована для пользователя на дикторонезависимость, для минимизации рисков неудавшейся записи его голоса. Это может произойти из-за физиологических свойств организма, таких как: подростковая мутация голоса, изменения тона при респираторных и подобных заболеваниях носоглотки человека и т.п. Также это ускорит работу приложения, потому что будет сокращено количество процессов по распознаванию голоса и речи, а следовательно, и время работы самого устройства. Такие системы не нужно обучать и подстраивать под определённого диктора, что сократит размер всего приложения в итоге. При этом может появится уязвимость в виде возможности постороннему воспользоваться устройством путём управления голосом, но этого можно избежать, к примеру установив блокировку доступа к нему.
4.2 Метод распознавания речи
Что бы упростить и ускорить процесс обработки данных голоса диктора необходимо разделить речь на элементарные составляющие – фонемы. Это простейшая единица языка, которая несёт минимальное необходимое количество смысловой информации достаточной для определения сказанного слова пользователем приложения. Таким образом получается построить модель по которой система может воспринимать вышеописанные данные, она строится от наименьшей единицы – фонемы, которая переходит к слову, а из слов уже получаются предложения и т.д.
Такая модель хорошо подходит для использования нейронных сетей по самоорганизующейся карте признаков. По этим признакам следует статистическим методом усреднить данные, что позволит решить проблему изменчивости речи [10]. Но более подходящими являются генетические нейронные алгоритмы, они превосходят предыдущие гибкостью изменений своей архитектуры. Её простота заключается в использовании правил отбора, которые определяют уровень качества работы нейронный сетей за один отбор и задают настройки и изменения для последующих отборов [10].
ВЫВОДЫ
В ходе работы были рассмотрены основные проблемы и сложности, которые необходимо предусмотреть и не допустить при разработке модуля распознавания речи. Основная сложность создания такой системы это невозможность подстроить её работу под особенности речи каждого человека, из-за большого диапазона речевых характеристик пользователей данного приложения, так как у каждого свой акцент, своя манера произношения или диалект. Поэтому ведение разработок подобных алгоритмов, систем и иного программного ПО, направленных на повышения уровня качества и усовершенствование существующих наработок распознавания речи, будет актуальным ещё очень долго.
СПИСОК ИСТОЧНИКОВ
- Создание систем распознавания речи. [Электронная библиотека студента] // Библиофонд. — Режим доступа: href="https://www.bibliofond.ru/view.aspx?id=871454 (дата обращения: 17.09.2021).
- Системы автоматического распознавания речи. [Электронный ресурс] // КомпьютерПресс. — Режим доступа: https://compress.ru/article.aspx?id=11331 (дата обращения: 25.09.2021).
- Хеин Мин Зо. Современное состояние проблемы обработки, анализа и синтеза речевых сигналов. [Электронный ресурс] // Сyberleninka. — Режим доступа:https://cyberleninka.ru/article/n/sovremennoe-sostoyanie-problemy-obrabotki-analiza-i-sinteza-rechevyh-signalov/viewer (дата обращения: 07.10.2021).
- Федосин С.А., Еремин А. Ю. Классификация систем распознавания речи. // Мордовский государственный университет им. Н. П. Огарева. — Режим доступа: http://fetmag.mrsu.ru/2010-2/pdf/SpeechRecognition.pdf (дата обращения: 10.10.2021).
- Проблемы распознавания речи: что еще предстоит решить. [Электронный ресурс] // AppTractor. — Режим доступа: https://apptractor.ru/info/articles/problemyi-raspoznavaniya-rechi-chto-eshhe-predstoit-reshit.html (дата обращения: (10.10.2021).
- Кулибаба О.В. Распознавание диктора. // Донецкий Национальный Технический Университет. — Режим доступа:http://masters.donntu.ru/2010/fknt/kulibaba/library/article8.htm (дата обращения: 12.10.2021).
- Костенко А.В. Новые подходы к проблемам конца речевого сигнала . // Донецкий Национальный Технический Университет. — Режим доступа:http://masters.donntu.ru/2012/iii/kostenko/diss/index.htm#p6 (дата обращения: 12.10.2021).
- Бондаренко И.Ю. Интеграция визуального и речевого способов управления процессом ввода и редактирования текстовой информации. // Донецкий Национальный Технический Университет. — Режим доступа: http://masters.donntu.ru/2006/fvti/bondarenko/diss/index.htm#Chapter41 (дата обращения: 12.10.2021).
- Математики из Армении создали сервис, который убирает посторонние звуки во время звонков. [Электронный ресурс] // VC. — Режим доступа:https://vc.ru/services/56580-matematiki-iz-armenii-sozdali-servis-kotoryy-ubiraet-postoronnie-zvuki-vo-vremya-zvonkov (дата обращения: 17.10.2021).
- Харченко В. А. Разработка модели голосового управления автомобилем на основе субполосного анализа. // Белгородский Государственный Национальный исследовательский университет. — Режим доступа:http://dspace.bsu.edu.ru/bitstream/123456789/28033/1/Kharchenko_Razrabotka_17%20%281%29.pdf (дата обращения: 27.10.2021).