
МОЖЛИВІ НЕДОЛІКИ ТА СКЛАДНОСТІ ПРИ РОЗРОБЦІ МОДУЛЯ РОЗІЗНАННЯ МОВЛЕННЯ
Зміст
- Вступ
- 1. Актуальність теми
- 2. Основні проблеми при розпізнаванні мови
- 2.1 Проблеми завадостійкості мови
- 2.2 Недоліки інтерфейсу
- 2.3 Зовнішні шуми
- 2.4 Проблеми семантики
- 2.5 Інвестиції та попит
- 3. Заплановані практичні результати
- 3.1 Огляд досліджень та розробок на тему
- 4. Розробка голосового механізму розпізнавання мовлення
- 4.1 Огляд національних джерел
- 4.2 Основні складові системи розпізнавання
- Висновки
- Список джерел
Вступ
В епоху інтернету майже кожній людині доступні його блага такі як: смартфони, планшети, ноутбуки з деяким набором додатків. Дані ПЗ (програмне забезпечення) створюються для розваги, спрощення зв'язку з близькими, допомоги у роботі, навчанні тощо. Їхня основна мета спростити або злегка урізноманітнити життя. Кількість таких програм зростає у геометричній прогресії з кожним днем, але реальна корисність для користувача кожного такого ПЗ у середньому та у загальній статистиці невелике. Загальний високий рівень їхньої марності виникає через переважання програм, у яких основний напрямок – розвага певної аудиторії користувачів, над тими, які створені під вирішення конкретних завдань, таких як управління електронними або цифровими пристроями голосом.
1. Актуальність теми
За минулі десятиліття з'явилося багато програм для розпізнавання голосу, але самий пік точності розпізнавання мови в цілому припав на кінець дев'яностих - початок двохтисячних. Ефективність сучасних систем розрізняти параметри та властивості мови становить приблизно 80 % точності, тоді як в людини цей показник досягає 95% [1].
На сьогоднішній день існує безліч напрямків для розвитку звуко-обробних технологій таких, як: системи автоматичного розпізнавання мовлення (САРР), які використовуються для забезпечення голосового діалогу між людиною та комп'ютером або голосових ключів, що забезпечують голосове розпізнавання особи. Розглянутий напрямок зростання систем обробки мови є дуже перспективним, оскільки крім високої затребуваності у бізнесі та повсякденному житті, може створити симбіоз з іншими проектами-гігантами на ринку інвестицій, ними є системи штучного інтелекту та інтернету речей. Дані можливості дозволяють експоненційно розвиватися в найближчі десять років, завдяки великим інвестиціям і попитом на програми розпізнавання мови [2].
2 Основні проблеми при розпізнаванні мови
2.1 Проблеми завадостійкості мови
Ця проблема полягає насамперед у наявності шумів при записі мови. У кожної людини своя манера ведення діалогу, а також вимови та акцент, все це може погано впливати на якість аналізу голосових даних системою під час запису та розпізнавання мови. Найбільш помітними похибки у випадках, коли існуватиме необхідність у кількох дикторах, тому що при одному систему легше пристосувати до деяких голосових, людських характеристик [3].
Характерною особливістю говірки людини необхідно враховувати злите у неї мовлення, або навпаки роздільне. Перший тип ускладнює розпізнання слів, тому що при такій вимові важче за голосовий додаток розрізняти межі слів диктора. [4] Таким чином, необхідно щоб була дикторо-залежна система змогла точно і з першої спроби «розчути» весь діалог. Отже, для системи необхідно визначити мінімально нижній тимчасовий поріг паузи між словами, при вимові, щоб не була злитою.
2.2 Недоліки інтерфейсу
Додаток, що розробляється, по роботі зі звуком, повинен бути орієнтований, при формуванні інтерфейсу, як на професійного користувача комп'ютером, так і на новачка. Оболонка програми має бути нативною, тобто має бути легкою в освоєнні і зрозумілою з першого разу її використання. Варто також враховувати наявність адаптивної верстки, з тією метою, щоб програму можна було відкрити в будь-якому браузері на будь-якому типі пристроїв, без зміни початкової верстки.
2.3 Зовнішні шуми
Не маловажний чинник точно зрозумілого слова чи цілого речення системою це показник навколишніх звуків мовника, тобто. шумів. Для людини рівень шуму не такий важливий, як пристрою для розпізнавання мови, т.к. людина здатна добре розрізняти слова навіть при показнику 80-90 дБ, що рівнозначно шуму на автобусній зупинці або поряд працюючому мотоциклу. Але з «електронікою» не все так однозначно, тому що вона не здатна навчитися точно розрізняти семантичні особливості будь-якої з відомих мов світу, йдеться про нейромережі (машинне навчання), через недоцільність або неможливість зібрати необхідну, достатню кількість даних для ідентифікації у розмові диктора омофонів. При ігноруванні вищеописаного у півтора рази збільшується ймовірність неправильного визначення слів, що видно на діаграмі 1 [5]. Отже, зменшення витрат на боротьбу із зовнішніми шумами варто їх мінімізувати під час запису промови диктора на її розпізнавання системі.
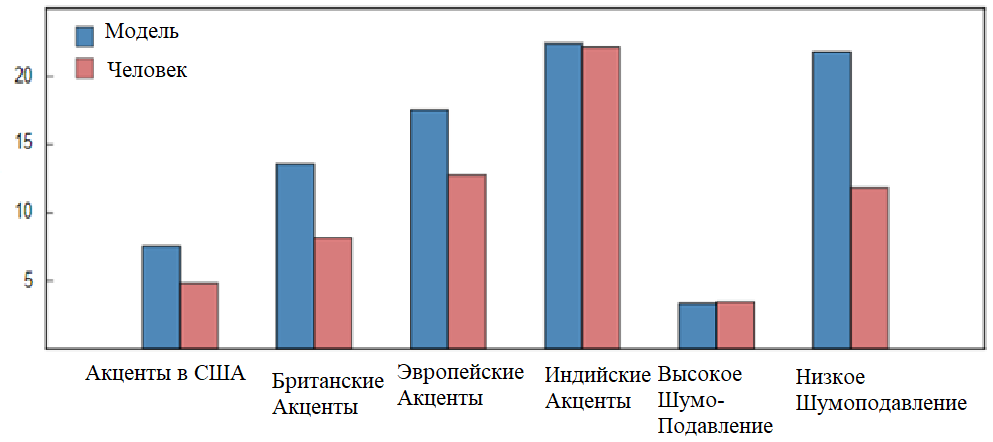
Діаграма 1 – Рівень помилкової вимови слів машини та людини різними мовами.
Також погано впливає якість роботи системи наявність дикторів більше одного. Народ і можуть приймати інформацію з кількох джерел одночасно, на відміну від відповідних пристроїв. Проте можна зробити таку програму, яка була б багато потоковим, т. е. могло сприймати мова кількох людина одночасно. Або можна запрограмувати пристрій, що розпізнає так, щоб запис тексту відбувався тільки при розпізнаванні голосу конкретного диктора. Розпізнавання дикторів можна розділити на ідентифікацію та верифікацію диктора. Ідентифікація диктора – це процес визначення, хто із зареєстрованих дикторів вимовив фразу. Верифікація диктора – це процес прийняття чи відхилення заявленої особи диктора. Більшість додатків, у яких використовується голос, підтверджують особистість диктором, що класифікується верифікацією диктора [6]. Тому необхідно заздалегідь визначитися з тим, що потрібно зробити систему, яка чітко виконує завдання за мінімальних додаткових витрат, або систему, яка зможе виконати все те саме, але в будь-яких умовах і зайвих витратах.
Наступні джерела зовнішніх голосів або їх першопричин можна розділити на такі типи:
- Використання кодеків, які не підходять для усунення всіх можливих шумів
- Недоліки програмного забезпечення, суть яких полягає у відсутності балансу між продуктивністю програми та якістю виконаної нею роботою.
- Наявність реверберації через особливості приміщень, в яких може використовуватися дана система розпізнавання мови, і нездатність вищезазначених кодеків вирішити це завдання (рис.2) [5].
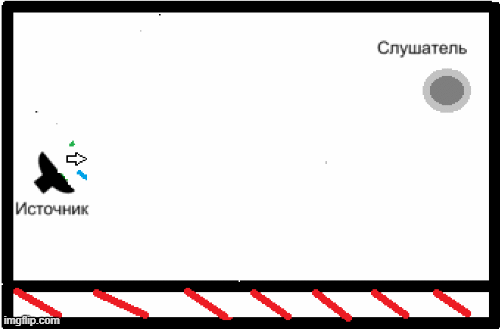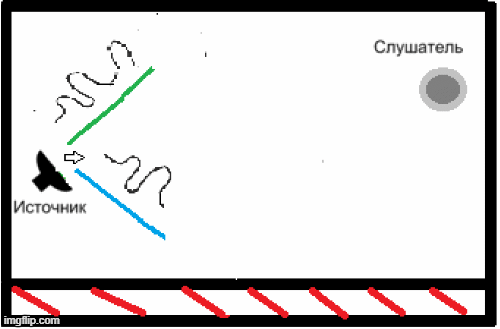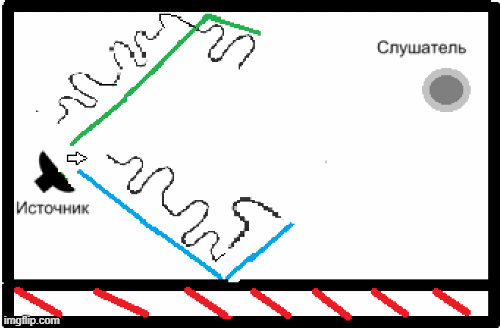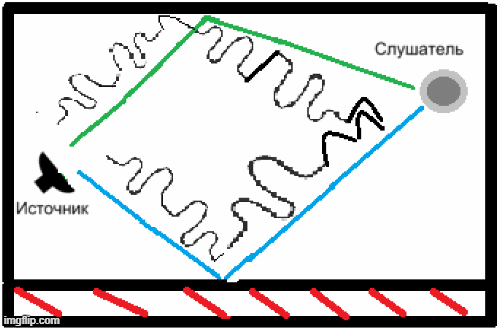
Рисунок 2 – Приклад появи реверберації у закритому приміщенні.
2.4 Проблеми семантики
У повсякденному мовленні кожної людини відбуваються лексичні, стилістичні, фразеологічні та інші вимовні помилки. Варто також відзначити присутність у розмові омографів і омофонів, що дуже негативно позначиться на якості роботи системи, що розпізнає, тому що омофони воно може переплутати, але це легко виправити повторенням неправильно сказаної фрази, а омограф - це помилка, яка закладена в коді або пам'яті системи і вирішити проблему такого роду можливо за допомогою розробника цієї програми або технічної підтримки.
2.5 Інвестиції та попит
Для старту створення серйозного будь-якого додатка, інтернет-або локального-необхідне грошове фінансування. Його наявність потрібна для мотивації персоналу, різні технічні закупівлі, для досліджень споживчого ринку та інших видів витрат. Дослідження запитів ринку потенційних та фактичних споживачів сприяє створенню чіткого та вдалого плану розробки та реалізації проекту. Без досліджень існуючого попиту споживачів складніше передбачити подальший, а це збільшує ризики краху майже будь-якого «стартапа», оскільки виробництво товару має догоджати чиїмось потребам. Прикладом може послужити розробка програми-алгоритму з видалення шумів з аудіо при спілкуванні в режимі онлайн, яка була створена для програм, що сприймають мову, як аналог і стала готова до використання. Але для неї не знайшлося покупця, оскільки великим виробникам вона не привнесла б відчутних змін у роботу систем, що вже зарекомендували.
Варто зазначити, що за відсутності інвесторів може бути первинний капітал у керівника проекту, що для самого проекту буде рівнозначним інвестиціям. Але інвестор заощадить годину, витрачену на збір свого капіталу, може допомогти просуванню стартапу, за умови, що вже є працездатна модель або прототип кінцевого продукту, що очікується. У протилежному випадку, якщо немає капіталу, ні інвестиції, то зменшуватимуться шанси на наявність необхідного набору персоналу (команда розробників), а також не буде можливості провести комплексне дослідження ринку споживачів, що зменшить шанс на успіх.
3 Заплановані практичні результати
Підсумком розробки системи розпізнавання мови планується додаток, який має сприймати звичайний злитий діалог диктора. При наявних ресурсах слід досягти результату мінімальної паузи між словами рядового користувача близько семисот мілісекунд. При цій планці, мінімальної години, якість розпізнавання слів має бути хорошим і водночас точним (з мінімальною кількістю помилки). Ця програма не повинна заважати роботі інших процесів пристроїв, на яких вона буде встановлена, а також не займати вільне місце оперативної пам'яті, крім того, що буде зазначено у рекомендованих системних вимогах.
3.1 Огляд досліджень та розробок на тему
У межах ДонНТУ були проведені дослідження за темами схожими на такі: алгоритми сегментації звуку, в якому слід згадати пошуки меж приголосних звуків з поділом на шиплячі, дзвінкі та глухі, а також чистого голосового сигналу. У вищезгаданій роботі була проведена докладна класифікація звуків і фонем, що в результаті дозволило більш точно розпізнати глухі вибухові наприкінці сигналу, тим самим надаючи можливість виділити їх з ділянки тиші [7].
Також варто звернути увагу на ще одну роботу з інтеграції візуального та мовного методів управління процесом введення та редагування текстової інформації шляхом нечіткого зіставлення та нечіткого DTW-порівняння мовних образів. Мовний сигнал представляється як двомірного спектрального тимчасового образу на підставі чого можна проводити порівняння способів розпізнавання мовних команд, що надалі допоможе розвитку DTW-порівнянню звукових команд [8].
У світовому масштабі можна назвати розробку звукового кодека для придушення зовнішніх шумів компанією «2Hz». Метою розробки було досягнення необхідного рівня видалення шумів, при передачі мови на пристрій обробки звуків, за час, який не досяг жодного схожого часу при мінімальних витратах системної потужності пристрою користувача. Вирішенням цієї проблеми мала займатися створена нейромережа, що працює зі звуками на частотах 8 і 16 кГц для телефонів і VoIP-додатків відповідно. У результаті поставлені основні завдання були виконані, а кодек отримав назву «Krisp» [9].
4 Розробка голосового механізму розпізнавання мовлення
4.1 Основні складові системи розпізнавання
Створення докладання з розпізнавання мови передбачає створення системи, розробки якої необхідно враховувати ряд чинників, безпосередньо які впливають якість і працездатність очікуваного товару у результаті. До таких факторів можна віднести наявність міток – початку розмови, використання спеціалізованого ПЗ, дикторозалежність тощо.
Мітки, якими пристрій здатний розуміти, коли слід починати записувати мова, тобто. Деякі «старт-слова». При виголошенні цієї мітки повинен відбуватися запис розмови, у своїй користувач заздалегідь вибирає скільки відбуватиметься запис, наприклад п'ять секунд (якщо вимовлятися зарезервовані системою команди) чи приблизно хвилину і більше (для розпізнавання мови і перетворити на текст чи подібних завдань), при необхідності можна додати "стоп-слово" для зупинки запису.
Також система повинна містити програми, що перетворюють дані звукових сигналів, що складають мову, звані кодеками. Їхнє завдання полягатиме в усуненні недоліків мови людини: погана дикція, рідкісні розмовні акценти і т.д., таким чином ці програми повинні будуть прибирати зайві шуми в раніше описаних ситуаціях.
Наступною важливою складовою мовної системи є диктозалежність, додаток може бути диктозалежним або диктонезалежним. Пропонована система буде орієнтована для користувача на диктонезалежність, для мінімізації ризиків невдалого запису його голосу. Це може статися через фізіологічні властивості організму, такі як: підліткова мутація голосу, зміни тону при респіраторних та подібних захворюваннях носоглотки людини тощо. Також це прискорить роботу програми, тому що буде скорочено кількість процесів розпізнавання голосу і мови, а отже, і час роботи самого пристрою. Такі системи не потрібно навчати і підлаштовувати під певного диктора, що скоротить розмір усієї програми в результаті. При цьому може з'явитися вразливість як можливість сторонньому скористатися пристроєм шляхом керування голосом, але цього можна уникнути, наприклад встановивши блокування доступу до нього.
4.2 Метод розпізнавання промови
Щоб спростити і прискорити процес обробки даних голосу диктора необхідно розділити промову на елементарні складові – фонеми. Це найпростіша одиниця мови, яка несе мінімальну необхідну кількість смислової інформації, достатньої для визначення сказаного слова користувачем програми. Таким чином виходить побудувати модель за якою система може сприймати вищеописані дані, вона будується від найменшої одиниці – фонеми, яка переходить до слова, та якщо з слів вже виходять речення і т.д.
Така модель добре підходить для використання нейронних мереж за самоорганізованою картою ознак. За цими ознаками слід статистичним методом усереднити дані, що дозволить вирішити проблему мінливості мови [10]. Але найбільш підходять генетичні нейронні алгоритми, вони перевершують попередні гнучкістю змін своєї архітектури. Її простота полягає у використанні правил відбору, які визначають рівень якості роботи нейронних мереж за один відбір та задають налаштування та зміни для подальших відборів [10].
ВИСНОВКИ
У ході роботи були розглянуті основні проблеми та складності, які необхідно передбачити та не допустити при розробці модуля розпізнавання мови. Основна складність створення такої системи це неможливість підлаштувати її роботу під особливості промови кожної людини, через великий діапазон мовних характеристик користувачів даної програми, так як у кожного свій акцент, своя манера вимови чи діалект. Тому ведення розробок подібних алгоритмів, систем та іншого програмного ПЗ, спрямованих на підвищення рівня якості та удосконалення існуючих напрацювань розпізнавання мови, буде актуальним ще дуже довго.
СПИСОК ДЖЕРЕЛ
-
<
- Создание систем распознавания речи. [Электронная библиотека студента] // Библиофонд. — Режим доступа: href="https://www.bibliofond.ru/view.aspx?id=871454 (дата обращения: 17.09.2021).
- Системы автоматического распознавания речи. [Электронный ресурс] // КомпьютерПресс. — Режим доступа: https://compress.ru/article.aspx?id=11331 (дата обращения: 25.09.2021).
- Хеин Мин Зо. Современное состояние проблемы обработки, анализа и синтеза речевых сигналов. [Электронный ресурс] // Сyberleninka. — Режим доступа:https://cyberleninka.ru/article/n/sovremennoe-sostoyanie-problemy-obrabotki-analiza-i-sinteza-rechevyh-signalov/viewer (дата обращения: 07.10.2021).
- Федосин С.А., Еремин А. Ю. Классификация систем распознавания речи. // Мордовский государственный университет им. Н. П. Огарева. — Режим доступа: http://fetmag.mrsu.ru/2010-2/pdf/SpeechRecognition.pdf (дата обращения: 10.10.2021).
- Проблемы распознавания речи: что еще предстоит решить. [Электронный ресурс] // AppTractor. — Режим доступа: https://apptractor.ru/info/articles/problemyi-raspoznavaniya-rechi-chto-eshhe-predstoit-reshit.html (дата обращения: (10.10.2021).
- Кулибаба О.В. Распознавание диктора. // Донецкий Национальный Технический Университет. — Режим доступа:http://masters.donntu.ru/2010/fknt/kulibaba/library/article8.htm (дата обращения: 12.10.2021).
- Костенко А.В. Новые подходы к проблемам конца речевого сигнала . // Донецкий Национальный Технический Университет. — Режим доступа:http://masters.donntu.ru/2012/iii/kostenko/diss/index.htm#p6 (дата обращения: 12.10.2021).
- Бондаренко И.Ю. Интеграция визуального и речевого способов управления процессом ввода и редактирования текстовой информации. // Донецкий Национальный Технический Университет. — Режим доступа: http://masters.donntu.ru/2006/fvti/bondarenko/diss/index.htm#Chapter41 (дата обращения: 12.10.2021).
- Математики из Армении создали сервис, который убирает посторонние звуки во время звонков. [Электронный ресурс] // VC. — Режим доступа:https://vc.ru/services/56580-matematiki-iz-armenii-sozdali-servis-kotoryy-ubiraet-postoronnie-zvuki-vo-vremya-zvonkov (дата обращения: 17.10.2021).
- Харченко В. А. Разработка модели голосового управления автомобилем на основе субполосного анализа. // Белгородский Государственный Национальный исследовательский университет. — Режим доступа:http://dspace.bsu.edu.ru/bitstream/123456789/28033/1/Kharchenko_Razrabotka_17%20%281%29.pdf (дата обращения: 27.10.2021).