
Реферат по теме выпускной работы
На момент написания данного реферата магистерская диссертация еще не завершена. Предполагаемая дата завершения: май-июнь 2022 г. Полный текст работы, а также материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Современная ситуация систем поддержки принятия решений
- 4. Применение математических методов
- 4.1 Понятие и цели кластеризации
- 4.2 Метод K-средних (K-means)
- 4.3 Метод Уорда
- 5. Структурная схема СППР
- 6. Постановка задачи
- Выводы
- Список источников
Введение
Первоначальные формы страхования возникли в глубокой древности. Самые древние правила страхования, дошедшие до нас, изложены в одной из книг талмуда. На острове Родос в 916 г. до н.э. был принят ордонанс, в котором представлена система распределения ущерба в случае общей аварии. Принципы, применяемые в этом документе, сохранились до наших дней [1].
С ростом городов и возникновением крупных населенных пунктов возрастала опасность гибели или повреждения имущества от пожаров и других стихийных бедствий. Люди стали объединяться для совместных действий по предотвращению опасности, ликвидации последствий, в том числе и экономическими мерами. Так, в 1310 г. в г. Брюгге (Германия) была учреждена Страховая палата
, которая проводила операции по защите имущественных интересов купечества и ремесленных гильдий.
Значительную роль в развитии страхового дела сыграло постановление Совета Министров СССР от 30 августа 1984 г. О мерах по дальнейшему развитию Государственного страхования и повышению качества работы страховых органов
. Ситуация резко изменилась в связи с легализацией предпринимательства в России, когда коммерческие, финансовые и хозяйственные риски сделались повседневной реальностью для десятков тысяч бизнесменов.
Начало 90-х годов – возрождение страхового рынка в стране. Указом президента от 29 января 1992 г. государственные и муниципальные страховые предприятия преобразуются в акционерные страховые общества (АСО) закрытого и открытого типа и в страховые товарищества с ограниченной ответственностью (ТОО). Закон РФ О страховании
(от 27 ноября 1992 г.) вступил в силу 12 января 1993 г. В 1996 г. вышло постановление правительства О первоочередных мерах по развитию рынка страхования в Российской Федерации
.
Страховая компания – исторически определенная общественная форма функционирования страхового фонда, представляет собой обособленную структуру, осуществляющую заключение договоров страхования и их обслуживание.
1. Актуальность темы
Спрос на страховые услуги предопределяется тем, что у экономических субъектов (юридических и физических лиц) постоянно существует угроза наступления каких-то неблагоприятных, а то и катастрофических событий, которые приводят к значительным финансовым потерям (смерть, болезнь или увольнение с работы члена семьи, работа которого была основным источником дохода; гибель имущества от пожара; авария автомобиля и т.п.). Покрыть эти потери из текущих доходов практически невозможно, накапливать для этого средства через депозитные счета тоже очень тяжело. Страхование является наиболее выгодным возмещением таких потерь, поскольку сумма его может быть больше страховых взносов.
Каждая страховая компания старается улучшить концепцию обслуживания клиентов. Сократить время обработки анкетирования клиентов. Сделать заключение страховых договоров комфортной и для страхового агента, и для клиента. Другой стороной этой концепции является, естественно, стремление страховой компании оградить себя от материальных потерь в виде многочисленных страховых выплат. В результате возникает необходимость изучения потенциальных клиентов перед заключением договоров страхования.
В связи с тем, что в страховом деле появилось множество нюансов и данная область постоянно развивается и часто может вноситься большое количество изменений, рядовой сотрудник компании не всегда сможет учесть все нюансы и тонкости, и также всех индивидуальных особенностей, которые поступают с каждым новым клиентом. Именно здесь приходит на помощь система, которую планируется реализовать.
2. Цель и задачи исследования, планируемые результаты
Целью работы является повышение качества обслуживания клиентов, сокращение времени анкетирования и уменьшение (сокращение) материальных потерь страховой компании путем разработки СППР, обеспечивающей кластеризацию клиентов с учетом их индивидуальных особенностей и характеристик и формирование обоюдовыгодных договоров.
Основные задачи исследования:
- Определить критерии для классификации показателей страховых компаний;
- Проанализировать методы кластеризации применительно к группировке показателей;
- Разработать тестовые вопросы и выполнить их критеризацию по выбранным параметрам;
- Разработать СППР.
3. Современная ситуация систем поддержки принятия решений
Сегодня уровень развития программного обеспечения класса СППР характеризует хорошо развитая теоретическая основа и очень узкая сфера применения.
Сама концепция СППР подразумевает использование значительных объемов данных, однако, при этом в списке характеристик идеальной СППР не содержится важнейшая характеристика – взаимосвязь с постоянно пополняющимися источниками данных [2].
СППР используют для анализа большого объема разнородных данных, значит, проблема достаточности и своевременности предоставления данных является одной из важнейших, поскольку отсутствие или неточность данных приводит к искажению результатов анализа. Таким образом, выбор в качестве стратегии разработки СППР требует реализации множества функций, которые хотя и не попадают в концепцию СППР, но необходимы для поддержки принятия решений. К ним относятся задачи сбора, обработки и передачи информации.
4. Применение математических методов
Потенциальный клиент характеризуется набором параметров, которые влияют на выбор типа и варианта страхования. При этом необходимо акцентировать внимание на отдельные группы этих факторов для рационального решения вопроса страхования. Поэтому предварительно необходимо сгруппировать данные, для чего и используются методы кластеризации.
4.1 Понятие и цели кластеризации
Кластерный анализ – это многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем объекты упорядочиваются в сравнительно однородные группы (кластеры) (Q – кластеризация, или Q – техника, собственно кластерный анализ). Кластер – группа элементов, характеризуемых общим свойством. Главная цель кластерного анализа – нахождение групп схожих объектов в выборке [6].
Задача кластеризации (или обучение без учителя) заключается в следующем:
Есть обучающая выборка Xℓ = {x1,. . . , хℓ} ⊂ Xі – функция расстояния между объектами ρ (x, x´). Нужно разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике ρ, а объекты разных кластеров существенно отличались. При этом каждому объекту xi ∈ Xℓ приписывается метка (номер) кластера yi.
Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин:
- Во-первых, не существует однозначно лучшего критерия качества кластеризации. Известен целый ряд достаточно разумных критериев, а также ряд алгоритмов, которые не имеют четко выраженного критерия, но осуществляющих достаточно разумную кластеризацию
по построению
. Все они могут давать разные результаты; - Во-вторых, число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием;
- В-третьих, результат кластеризации существенно зависит от метрики ρ, выбор которой, как правило, также субъективен и определяется экспертом.
Цели кластеризации:
- Понимание данных путем выявления кластерной структуры. Разбивка выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия
разделяй и властвуй
); - Сжатие данных. Если исходная выборка избыточно большая, то можно сократить ее, оставив по одному наиболее типичному представителю от каждого кластера;
- Выявление новизны (novelty detection): выделяются нетипичные объекты, которые не удается присоединить к одному из кластеров (эту задачу называют одноклассовой классификации).
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, то есть, в свою очередь, дробятся еще мельче, и т. д. Такие задачи называются задачами таксономии [7].
4.2 Метод K-средних (K-means)
Алгоритм представляет собой версию EM-алгоритма, применяемого также для разделения смеси Гауссиан. Разбивает множество элементов векторного пространства на заранее известное число кластеров k.
Основная идея заключается в том, что на каждой итерации пересчитывается центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множества конечная, а на каждом шаге суммарное квадратичное отклонение V уменьшается, поэтому зацикливание невозможно [4].
Метод k-средних – наиболее популярный метод кластеризации. Был изобретен в 1950-х годах математиком Штейнгауз и почти одновременно Стюартом Ллойдом. Особую популярность получил после работы Маккуина.
Действие алгоритма такова, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:
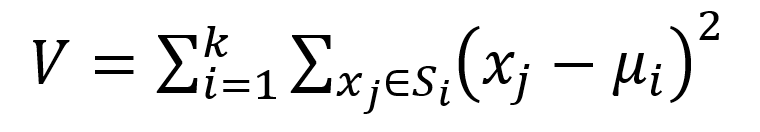
где k – число кластеров, Si – определенные кластеры, i=1,2,…,k и μi – центры масс векторов xj∈Si [5].
По аналогии с методом главных компонент центры кластеров называются также главными точками, сам метод называется методом главных точек и включается в общую теорию главных объектов, обеспечивающих лучшую аппроксимацию данных.
4.3 Метод Уорда
Метод Уорда предполагает, что сначала каждый кластер состоит из одного объекта. Сначала объединяются два ближайших кластера. Для них определяются средние значения каждого признака и рассчитывается сумма квадратов отклонений:
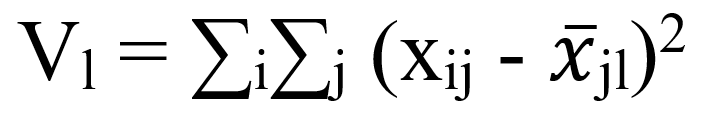
Где l – номер кластера, i – номер объекта (i = 1,2, ..., nl), nl – количество объектов в l-том кластере, j – номер признака (j = 1,2, ..., k), k – количество признаков, характеризующих каждый объект [9].
В дальнейшем объединяются те объекты или кластеры, которые дают меньше приращение Vl. Для объединения двух кластеров применяются следующие алгоритмы:
- Метод ближайшего соседа. Степень близости оценивается между наиболее близкими объектами этих кластеров;
- метод дальнего соседа. Степень близости оценивается по степени близости между наиболее удаленными объектами кластеров;
- метод средней связи. Степень близости оценивается как средняя величина степени близости между объектами кластеров;
- метод медианной связи. Расстояние между любым кластером S и новым кластером, который получился в результате объединения кластеров P и Q, определяется как расстояние от центра кластера S к середине отрезка, соединяющего центры кластеров P и Q.
Кроме рассмотренных агломеративних методов иерархического кластерного анализа существуют методы, противоположные им по логике построения процедур классификации – иерархические дивизимные методы. Основной исходной посылкой дивизимных методов является то, что сначала все объекты принадлежат одному кластеру. В процессе классификации по определенным правилам постепенно от этого кластера отделяются группы схожих между собой объектов. Таким образом, на каждом шаге количество кластеров растет, а мера расстояния между кластерами уменьшается [8].
5. Структурная схема СППР
Система поддержки принятия решений представляет комплекс программных средств, включающий библиотеку различных алгоритмов поддержки решений, базу моделей, БД, вспомогательные и управляющую программы. Управляющая программа организует процесс принятия решений с учетом специфики проблемы.
На рисунке 1 представлена высокоуровневая структурная схема экспертной системы. Как видно из рисунка 1, в системе предусмотрено использование всех необходимых блоков, которые должна иметь СППР. Для упрощения взаимодействия пользователя с инструментарием программных средств предусматривается формирование пользователем запросов по формам представления входной и выходной информации блоками отображения и объяснения решения.
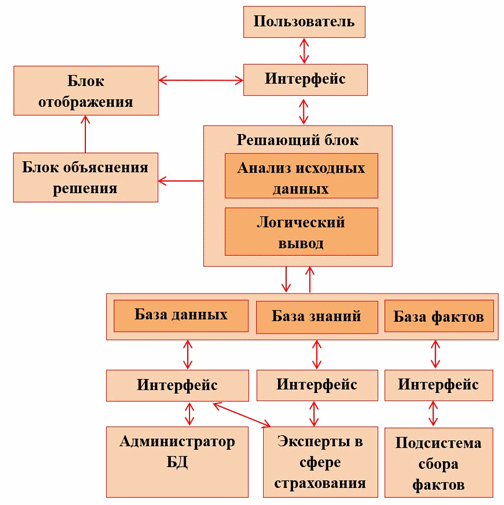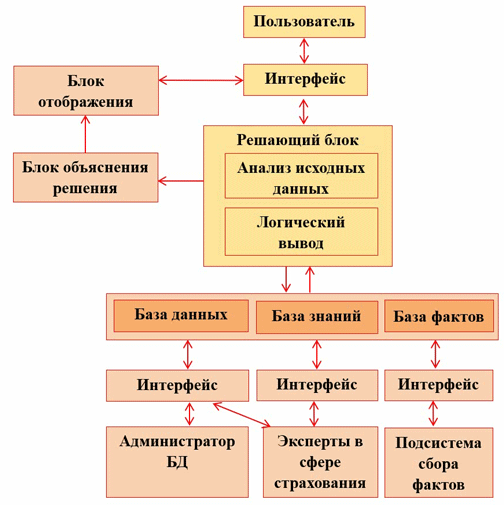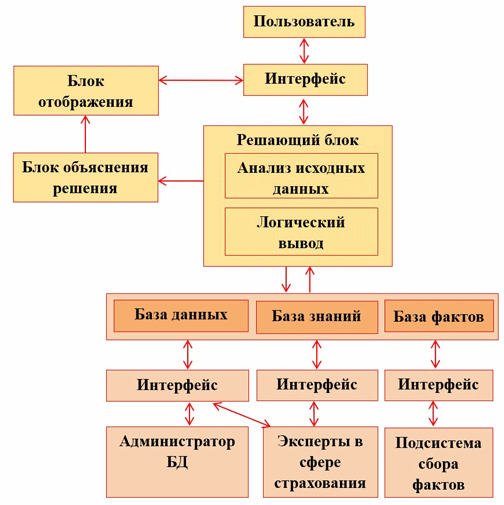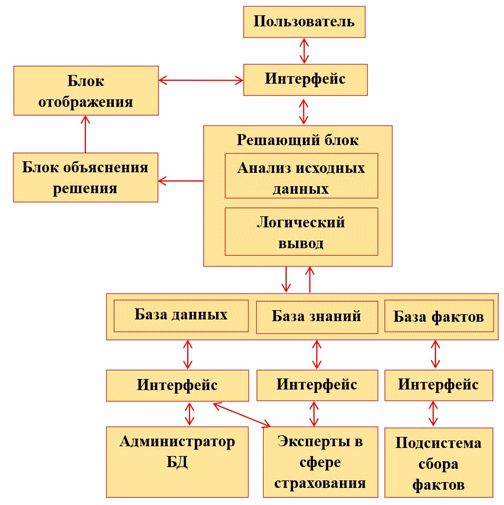
Рисунок 1 – Структурная схема СППР
Анимация: 9 кадров, 5 циклов повторения, 90 килобайт
Блок анализа входных данных выполняет кластеризацию клиента по сгруппированному набору факторов. Внутри каждого кластера тем самым определяются границы значений факторов, применяются алгоритмы пересчета с использованием весовых коэффициентов значимости каждого фактора и проводится дальнейшая обработка полученных значений нечеткими методами.
В блок логического вывода поступают данные о проведенном анализе с объяснением, на каком основании были приняты решения.
На выходе аналитического блока системы необходимо получить степень риска, который может представлять отдельный клиент для страховой компании. В зависимости от этого результата система должна также учитывать ответы на вопросы теста и в итоге на основании базы правил предоставлять совет страховому агенту, какие действия следует предпринять [2-3].
Главная задача страховых компаний – минимизировать выплаты по страховым случаям. При этом из индивидуальных данных клиента, по результатам многовековых статистических исследований, можно сделать вывод о том, какой риск может представлять конкретный клиент, и стоит ли опустить некоторые пункты в будущем договоре страхования. Принятие во внимание ряда, на первый взгляд, не связанных между собой фактов может сэкономить миллионы страховым компаниям. Выявлением этих закономерностей и связей между значениями атрибутов клиентов занимаются специальные аналитики страховых компаний.
Итак, достичь минимизации расходов по выплатам страховым компаниям может помочь минимизация рисков, которые может представлять новый клиент для компании. При этом необходимо получить личные данные способом, удобным для клиента. Часто практика страховой деятельности показывает, если человек знает, что сотрудник страховой компании будет лично проверять анкету, то клиент может дать ложные данные о своей личности по различным психологическим аспектам. Прохождение анкетирования на компьютере, может повысить индекс истинности персональных данных клиента и одновременно даст возможность сразу же проводить аналитику клиента и получать результаты и советы для специалиста, который занимается подписанием договоров страхования.
6. Постановка задачи
Объектом компьютеризации является процесс заключения страховых договоров и анализ рисков, которые представляет клиент для страховой компании. Правовой базой страхования является федеральный закон от 27.11.1992 г. № 4015-1 О страховании
, в котором раскрывается и экономическая сущность страхования.
Согласно данному Закону страхование представляет собой отношения по защите имущественных интересов физических и юридических лиц при наступлении определенных событий (страховых случаев) за счет денежных фондов, формируемых из уплачиваемых ими страховых взносов (страховых премий).
Предметом деятельности страховой компании могут быть следующие виды финансовых услуг:
- Страхование;
- перестрахование;
- финансовая деятельность, связанная с формированием, размещением страховых резервов и их управлением.
Показатели могут быть сгруппированы в 3 базовые группы:
- CONTRACT;
- FINANCE;
- HEALTH.
Группа факторов FINANCE определяет информационные параметры, характеризующие финансовое благополучие клиента:
- Зарплата;
- количество автомобилей;
- общая сумма кредитов;
- наличие собственной недвижимости (или доли);
- находится ли клиент в браке;
- количество детей;
- возможность оплаты ежегодного страхового обязательства (ежегодная клиентская плата).
Группа HEALTH определяет уровень текущего физического здоровья, а также безопасна ли текущая деятельность клиента и имеют ли место опасные для жизни хобби:
- Наличие ВИЧ у клиента;
- количество перенесенных операций;
- количество выкуренных в день сигарет;
- употребление алкоголя;
- паспортный возраст;
- физический возраст;
- профессия, связанная с риском для жизни;
- есть опасные хобби (альпинизм, мотогонки и т.д.).
Группа CONTRACT определяет атрибуты договора страхования:
- Страховая сумма;
- количество лет страхования;
- тип страховки;
- покрываемые страховые случаи.
Каждая из базовых групп имеет вес, а также каждый атрибут внутри группы имеет весовой коэффициент значимости, в зависимости от которого можно судить на сколько тот или иной фактор влияет на общую картину оценки клиента в целом. Интеллектуальная обработка сгруппированных данных позволит оценить степень риска каждого клиента – RISK. При низком уровне риска, можно более гибко принимать решения, и возможно расширить страховой контракт.
Параметры характеристик клиента представим в виде вектора RISK = {FINANCE, HEALTH, CONTRACT}.
Каждый элемент вектора RISK также является вектором:
FINANCE = {salary, count_auto, count_credits, count_houses, is_married, count_children, Annual_Client_payment};
HEALTH = {is_aids +, count_operations, count_cigarets, count_alco, passport_age, fithness_age, risk_profession, risk_hobby, driving_experience};
CONTRACT = {SUM, YEARS, TYPE, insured_losses}.
На основании правил базы знаний происходит процесс подсчета важности влияния каждого фактора, входного вектора данных и формируется вектор indx_Risk[].
Целевая функция:
Ограничения по переменным:
- 0 ≤ AGE ≤ 60.
- Если FINANCE.Annual_Client_payment ≥ (0.1 * FINANCE.Salary), то увеличить TOTAL_RISK.
Для каждой группы в рамках определенного вида страхования, существует набор весовых коэффициентов. Внутри каждой группы определяется суммарный индекс, в соответствии с базой правил. Далее умножается на групповой индекс и суммируется для получения итогового значения:
где subgroupW [j] – значение внутригруппового весового коэффициента j фактора, определяется из базы правил в зависимости от значения j фактора при анкетировании клиента.
Выводы
В результате проведенного анализа целей и методов кластеризации и построения систем поддержки принятия решений установлено, что:
- Для первичной кластеризации по сгруппированой выборке факторов наиболее приемлемый метод Уорда, поэтому внутри кластеров оптимизируется минимальная дисперсия, в результате создаются кластеры приблизительно равных размеров. Метод Уорда наиболее удачный для анализа социологических данных. В качестве меры различия лучше применять квадратичное евклидовое расстояние, которое способствует увеличению контрастности кластеров;
- Для проверки адекватности формирования кластеров предлагается итеративно использовать метод k-means, как наиболее простой и при этом он дает достаточно достоверные результаты. При этом если сравниваемые классификации групп имеют долю совпадений более 70%, то кластерное решение принимается;
- Для модели СППР были избраны: модель представления знаний – продукционная модель, метод вывода – прямой нечеткий вывод;
- Также использование нечеткой логики и нечеткого вывода позволит приблизить компьютерную модель к логике действующих на данный момент бизнес-процессов страховой компании.
Список источников
- Развитие страхования в России – Страхование сегодня. История страхования [Электронный ресурс] / В. Г. Ларионов, М. Н. Скрыпникова – Электрон. текст. – [Россия, 2000]. – Режим доступа: https://www.insur-info.ru/history/press/d2451762.
- Глухова, Н. В. Теория принятия решений: учебное пособие /Глухова Н. В. – Ульяновск: Ульяновский государственный педагогический университет имени И.Н. Ульянова, 2017. – 50 c. – Электронно-библиотечная система IPR BOOKS: [сайт]. – URL: https://www.iprbookshop.ru/86329.html. – Режим доступа: для авторизир. пользователей.
- Доррер, Г. А. Методы и системы принятия решений: учебное пособие / Г. А. Доррер. – Красноярск: Сибирский федеральный университет, 2016. – 210 c. – Электронно-библиотечная система IPR BOOKS: [сайт]. – URL: https://www.iprbookshop.ru/84240.html.
- Кластеризация: алгоритмы k-means и c-means [Электронный ресурс] – 2009 – Режим доступа: http://habrahabr.ru/post/67078/.
- Реализация алгоритма k-means на С# (с обобщенной метрикой) [Электронный ресурс] – 2012 – Режим доступа: http://habrahabr.ru/post/146556/.
- Наследов А. IBM SPSS Statistics 20 и AMOS: профессиональный статистический анализ данных. – [Россия, Санкт-Петербург, 2013]. – Глава 21. Кластерный анализ.
- Кластерный анализ [Электронный ресурс] – StatSoft: Электронный учебник по статистике – Режим доступа: http://www.statsoft.ru/home/textbook/modules/stcluan.html
- Иерархическая кластеризация [Электронный ресурс]: Режим доступа: https://ranalytics.github.io/data-mining/102-H-Clustering.html
- Кластерный анализ – Википедия [Электронный ресурс]: Режим доступа: http://ru.wikipedia.org/wiki/Кластерный_анализ