
Реферат за темою випускної роботи
На момент написання даного реферату магістерська дисертація ще не завершена. Передбачувана дата завершення: травень-червень 2022 р. повний текст роботи, а також матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження
- 3. Сучасна ситуація систем підтримки прийняття рішень
- 4. Застосування математичних методів
- 4.1 Поняття та цілі кластеризації
- 4.2 Метод k-середніх (K-means)
- 4.3 Метод Уорда
- 5. Структурна схема СППР
- 6. Постановка задачі
- Висновок
Вступ
Початкові форми страхування виникли в глибоку давнину. Найдавніші правила страхування, що дійшли до нас, викладені в одній з книг Талмуду. На острові Родос в 916 р. До н. е. був прийнятий ордонанс, в якому представлена система розподілу збитку в разі загальної аварії. Принципи, що застосовуються в цьому документі, збереглися до наших днів [1].
Зі зростанням міст і виникненням великих населених пунктів зростала небезпека загибелі або пошкодження майна від пожеж та інших стихійних лих. Люди стали об'єднуватися для спільних дій щодо запобігання небезпеці, ліквідації наслідків, в тому числі і економічними заходами. Так, в 1310 р. в м. Брюгге (Німеччина) була заснована Страхова палата
, яка проводила операції із захисту майнових інтересів купецтва і ремісничих гільдій.
Початок 90-х років – відродження страхового ринку в країні. Указом президента від 29 січня 1992 р державні та муніципальні страхові підприємства перетворюються в акціонерні страхові товариства (АСО) закритого і відкритого типу і в страхові товариства з обмеженою відповідальністю (ТОО). Закон РФ Про страхування
(від 27 листопада 1992 р.) набув чинності 12 січня 1993 р. у 1996 р. вийшла постанова Уряду Про першочергові заходи щодо розвитку ринку страхування в Російській Федерації
.
Страхова компанія – історично визначена громадська форма функціонування страхового фонду, є відокремлену структуру, здійснює укладання договорів страхування та його обслуговування.
1. Актуальність теми
Попит на страхові послуги зумовлюється тим, що у економічних суб'єктів (юридичних і фізичних осіб) постійно існує загроза настання якихось несприятливих, а то і катастрофічних подій, які призводять до значних фінансових втрат (смерть, хвороба або звільнення з роботи члена сім'ї, робота якого була основним джерелом доходу; загибель майна від пожежі; аварія автомобіля і т.п.). Покрити ці втрати з поточних доходів практично неможливо, накопичувати для цього кошти через депозитні рахунки теж дуже важко. Страхування є найбільш вигідним відшкодуванням таких втрат, оскільки сума його може бути більшою за страхові внески.
Кожна страхова компанія намагається поліпшити концепцію обслуговування клієнтів. Скоротити час обробки анкетування клієнтів. Зробити укладення страхових договорів комфортною і для страхового агента, і для клієнта. Іншою стороною цієї концепції є, природно, прагнення страхової компанії захистити себе від матеріальних втрат у вигляді численних страхових виплат. В результаті виникає необхідність вивчення потенційних клієнтів перед укладенням договорів страхування.
У зв'язку з тим, що в страховій справі з'явилося безліч нюансів і дана область постійно розвивається і часто може вноситися велика кількість змін, рядовий співробітник компанії не завжди зможе врахувати всі нюанси і тонкощі, і також всіх індивідуальних особливостей, які надходять з кожним новим клієнтом. Саме тут приходить на допомогу система, яку планується реалізувати.
2. Мета і задачі дослідження
Метою роботи є підвищення якості обслуговування клієнтів, скорочення часу анкетування і зменшення (скорочення) матеріальних втрат страхової компанії шляхом розробки СППР, що забезпечує кластеризацію клієнтів з урахуванням їх індивідуальних особливостей і характеристик і формування взаємовигідних договорів..
Основні задачі дослідження:
- Визначити критерії для класифікації показників страхових компаній;
- Проаналізувати методи кластеризації стосовно групування показників;
- Розробити тестові питання і виконати їх критеризацію за обраними параметрами;
- Розробити СППР.
3. Сучасна ситуація систем підтримки прийняття рішень
Сьогодні рівень розвитку програмного забезпечення класу СППР характеризує добре розвинена теоретична основа і дуже вузька сфера застосування.
Сама концепція СППР має на увазі використання значних обсягів даних, однак, при цьому в списку характеристик ідеальної СППР не міститься найважливіша характеристика – взаємозв'язок з постійно поповнюються джерелами даних [2].
СППР використовують для аналізу великого обсягу різнорідних даних, значить, проблема достатності і своєчасності надання даних є однією з найважливіших, оскільки відсутність або неточність даних призводить до спотворення результатів аналізу. Таким чином, вибір в якості стратегії розробки СППР вимагає реалізації безлічі функцій, які хоча і не потрапляють в концепцію СППР, але необхідні для підтримки прийняття рішень. До них відносяться завдання збору, обробки і передачі інформації.
4. Застосування математичних методів
Потенційний клієнт характеризується набiром параметрів, які впливають на вибір типу і варіанту страхування. При цьому необхідно акцентувати увагу на окремі групи цих факторів для раціонального вирішення питання страхування. Тому попередньо необхідно згрупувати дані, для чого і використовуються методи кластеризації.
4.1 Поняття та цілі кластеризації
Кластерний аналіз – це багатовимірна статистична процедура, що виконує збір даних, що містять інформацію про вибірку об'єктів, і потім об'єкти впорядковуються в порівняно однорідні групи (кластери) (Q – кластеризація, або Q – техніка, власне кластерний аналіз). Кластер – група елементів, що характеризуються загальною властивістю . Головна мета кластерного аналізу – знаходження груп схожих об'єктів у вибірці[6].
Завдання кластеризації (або навчання без вчителя) полягає в наступному:
Є навчальна вибірка Xℓ = {x1,. . . , х ℓ} ⊂ Xі – функція відстані між об'єктами ρ (x, x´). Потрібно розбити вибірку на непересічні підмножини, звані кластерами, так, щоб кожен кластер складався з об'єктів, близьких за метрикою ρ, а об'єкти різних кластерів істотно відрізнялися. При цьому кожному об'єкту xi ∈ Xℓ приписується мітка (номер) кластера yi.
Рішення задачі кластеризації принципово неоднозначне, і тому є кілька причин:
- По-перше, не існує однозначно кращого критерію якості кластеризації. Відомий цілий ряд досить розумних критеріїв, а також ряд алгоритмів, які не мають чітко вираженого критерію, але здійснюють досить розумну кластеризацію
з побудови
. Всі вони можуть давати різні результати; - По-друге, число кластерів, як правило, невідомо заздалегідь і встановлюється відповідно до деяких суб'єктивним критерієм;
- По-третє, результат кластеризації істотно залежить від метрики ρ, вибір якої, як правило, також суб'єктивний і визначається експертом.
Цілі кластеризації:
- Розуміння даних шляхом виявлення кластерної структури. Розбивка вибірки на групи схожих об'єктів дозволяє спростити подальшу обробку даних і прийняття рішень, застосовуючи до кожного кластеру свій метод аналізу (стратегія
розділяй і володарюй
); - Стиснення даних. Якщо вихідна вибірка надлишково велика, то можна скоротити її, залишивши по одному найбільш типовому представнику від кожного кластера;
- Виявлення новизни(novelty detection): виділяються нетипові об'єкти, які не вдається приєднати до одного з кластерів (це завдання називають однокласової класифікації).
4.2 Метод k-середніх (K-means)
Алгоритм являє собою версію EM-алгоритму, застосовуваного також для поділу суміші Гауссіан. Розбиває безліч елементів векторного простору на заздалегідь відоме число кластерів k.
Основна ідея полягає в тому, що на кожній ітерації перераховується центр мас для кожного кластера, отриманого на попередньому кроці, потім вектори розбиваються на кластери знову відповідно до того, який з нових центрів виявився ближче за обраною метрикою.
Алгоритм завершується, коли на якійсь ітерації не відбувається зміни кластерів. Це відбувається за кінцеве число ітерацій, так як кількість можливих розбиття кінцевої множини кінцева, а на кожному кроці сумарне квадратичне відхилення V зменшується, тому зациклення неможливе [4].
Метод k – середніх – найбільш популярний метод кластеризації. Був винайдений в 1950-х роках математиком Штейнгауз і майже одночасно Стюартом Ллойдом. Особливу популярність отримав після роботи Маккуїна.
Дія алгоритму така, що він прагне мінімізувати сумарне квадратичне відхилення точок кластерів від центрів цих кластерів:
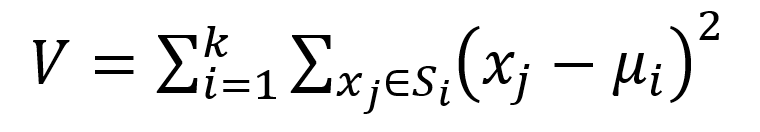
де k – число кластерів, Si – певні кластери, i=1,2,…,k и μi – центри мас векторів xj∈Si [5].
За аналогією з методом головних компонент центри кластерів називаються також головними точками, сам метод називається методом головних точок і включається в загальну теорію головних об'єктів, що забезпечують кращу апроксимацію даних.
4.3 Метод Уорда
Метод Уорда передбачає, що спочатку кожен кластер складається з одного об'єкта. Спочатку об'єднуються два найближчих кластера. Для них визначаються середні значення кожної ознаки і розраховується сума квадратів відхилень:
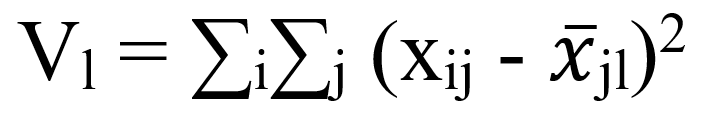
Где l – номер кластера, i – номер об'єкта (i = 1,2, ..., nl), nl – кількість об'єктів в l-тому кластерi, j – номер ознаки (j = 1,2, ..., k), k – кількість ознак, що характеризують кожен об'єкт [9].
Надалі об'єднуються ті об'єкти або кластери, які дають менше прирощення Vl. Для об'єднання двох кластерів застосовуються такі алгоритми:
- Метод найближчого сусіда. Ступінь близькості оцінюється між найбільш близькими об'єктами цих кластерів;
- метод далекого сусіда. Ступінь близькості оцінюється за ступенем близькості між найбільш віддаленими об'єктами кластерів;
- метод середнього зв'язку. Ступінь близькості оцінюється як середня величина ступеня близькості між об'єктами кластерів;
- метод медіанного зв'язку. Відстань між будь-яким кластером S і новим кластером, який вийшов в результаті об'єднання кластерів P і Q, визначається як відстань від центру кластера S до середини відрізка, що з'єднує центри кластерівP i Q.
Крім розглянутих агломеративних методів ієрархічного кластерного аналізу існують методи, протилежні їм за логікою побудови процедур класифікації – ієрархічні дивізимні методи. Основною вихідною посилкою дивізімних методів є те, що спочатку всі об'єкти належать одному кластеру. У процесі класифікації за певними правилами поступово від цього кластера відокремлюються групи схожих між собою об'єктів. Таким чином, на кожному кроці кількість кластерів зростає, а міра відстані між кластерами зменшується [8].
5. Структурна схема СППР
Система підтримки прийняття рішень представляє комплекс програмних засобів, що включає бібліотеку різних алгоритмів підтримки рішень, базу моделей, БД, допоміжні та керуючу програми. Керуюча програма організовує процес прийняття рішень з урахуванням специфіки проблеми.
На малюнку 1 представлена високорівнева структурна схема експертної системи. Як видно з малюнка 1, в системі передбачено використання всіх необхідних блоків, які повинна мати СППР. Для спрощення взаємодії користувача з інструментарієм програмних засобів передбачається формування Користувачем запитів за формами подання вхідної та вихідної інформації блоками відображення та пояснення рішення.
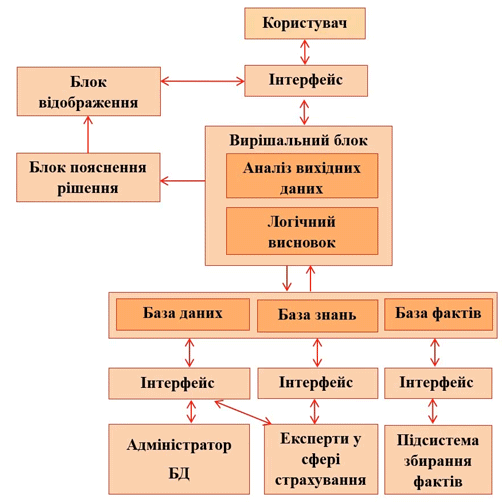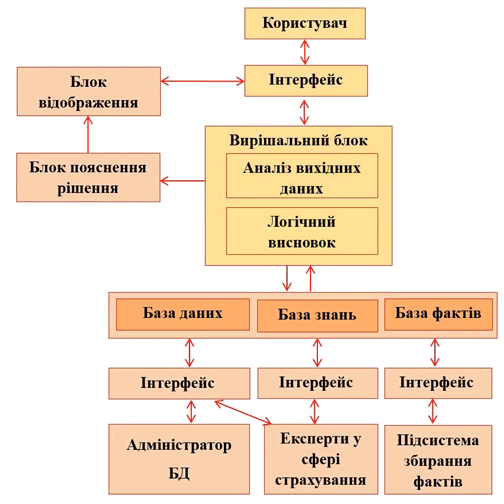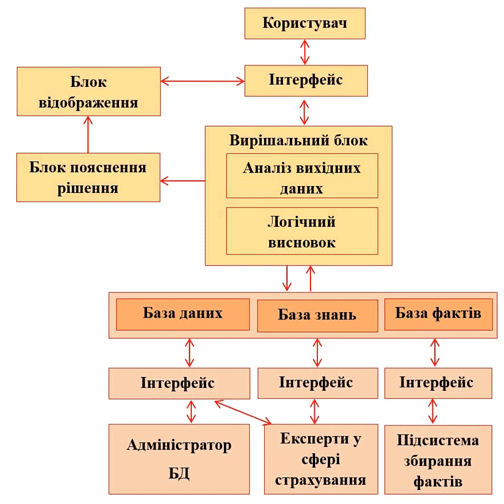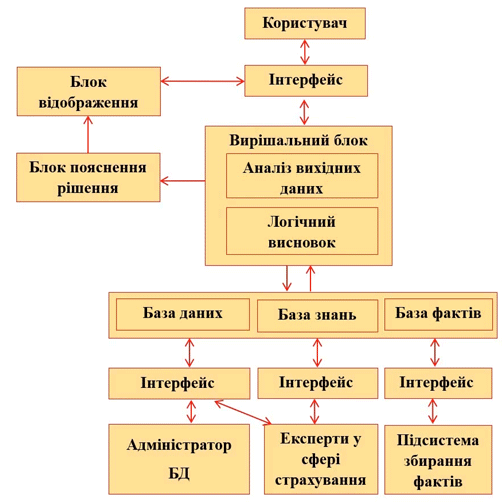
Малюнок 1 – Структурна схема СППР
Анімація: 9 кадрів, 5 циклів повторення, 88 кілобайт
Блок аналізу вхідних даних виконує кластеризацію Клієнта за згрупованим набором факторів. Усередині кожного кластера тим самим визначаються межі значень факторів, застосовуються алгоритми перерахунку з використанням вагових коефіцієнтів значущості кожного фактора і проводиться подальша обробка отриманих значень нечіткими методами.
У блок логічного висновку надходять дані про проведений аналіз з поясненням, на якій підставі були прийняті рішення.
На виході аналітичного блоку системи необхідно отримати ступінь ризику, який може представляти окремий клієнт для страхової компанії. Залежно від цього результату система повинна також враховувати відповіді на питання тесту і в підсумку на підставі бази правил надавати раду страховому агенту, які дії слід зробити [2-3].
Головне завдання страхових компаній – мінімізувати виплати за страховими випадками. При цьому з індивідуальних даних Клієнта, за результатами багатовікових статистичних досліджень, можна зробити висновок про те, який ризик може представляти конкретний клієнт, і чи варто опустити деякі пункти в майбутньому договорі страхування. Прийняття до уваги ряду, на перший погляд, не пов'язаних між собою фактів може заощадити мільйони страховим компаніям. Виявленням цих закономірностей і зв'язків між значеннями атрибутів клієнтів займаються спеціальні аналітики страхових компаній.
Отже, досягти мінімізації витрат по виплатах страховим компаніям може допомогти мінімізація ризиків, які може представляти новий клієнт для компанії. При цьому необхідно отримати особисті дані способом, зручним для клієнта. Часто практика страхової діяльності показує, якщо людина знає, що співробітник страхової компанії буде особисто перевіряти анкету, то клієнт може дати неправдиві дані про свою особистість з різних психологічних аспектів. Проходження анкетування на комп'ютері, може підвищити Індекс істинності персональних даних клієнта і одночасно дасть можливість відразу ж проводити аналітику клієнта і отримувати результати і поради для фахівця, який займається підписанням договорів страхування.
6. Постановка задачі
Об'єктом комп'ютеризації є процес укладання страхових договорів та аналіз ризиків, які представляє клієнт для страхової компанії. Правовою базою страхування є Федеральний закон від 27.11.1992 р № 4015-1 Про страхування
, в якому розкривається і економічна сутність страхування.
Згідно з цим Законом страхування являє собою відносини щодо захисту майнових інтересів фізичних і юридичних осіб при настанні певних подій (страхових випадків) за рахунок грошових фондів, що формуються з сплачуваних ними страхових внесків (страхових премій).
Ппредметом діяльності страхової компанії можуть бути наступні види фінансових послуг:
- Страхування;
- перестрахування;
- фінансова діяльність, пов'язана з формуванням, розміщенням страхових резервів та їх управлінням.
Показники можуть бути згруповані в 3 базові групи:
- CONTRACT;
- FINANCE;
- HEALTH.
Група факторів FINANCE визначає інформаційні параметри, що характеризують фінансове благополуччя клієнта:
- Зарплата;
- кількість автомобілів;
- загальна сума кредитів;
- наявність власної нерухомості (або частки);
- чи перебуває клієнт у шлюбі;
- кількість дітей;
- Можливість оплати щорічного страхового зобов'язання (щорічна клієнтська плата).
Група HEALTH визначає рівень поточного фізичного здоров'я, а також чи безпечна поточна діяльність клієнта і чи мають місце небезпечні для життя хобі:
- наявність ВІЛ у клієнта;
- кількість перенесених операцій;
- кількість викурених в день сигарет;
- вживання алкоголю;
- паспортний вік;
- фізичний вік;
- професія, пов'язана з ризиком для життя;
- є небезпечні хобі (Альпінізм, мотогонки і т.д.).
Група CONTRACT визначає атрибути договору страхування:
- страхова сума;
- кількість років страхування;
- тип страховки;
- покриваються страхові випадки.
Кожна з базових груп має вагу, а також кожен атрибут всередині групи має ваговий коефіцієнт значущості, в залежності від якого можна судити на скільки той чи інший фактор впливає на загальну картину оцінки клієнта в цілому. Інтелектуальна обробка згрупованих даних дозволить оцінити ступінь ризику кожного клієнта &ndash RISK. При низькому рівні ризику, можна більш гнучко приймати рішення, і можливо розширити страховий контракт.
Параметри характеристик клієнта представимо у вигляді вектора RISK = {FINANCE, HEALTH, CONTRACT}.
Кожен елемент вектора RISK також є вектором:
FINANCE = {salary, count_auto, count_credits, count_houses, is_married, count_children, Annual_Client_payment};
HEALTH = {is_aids +, count_operations, count_cigarets, count_alco, passport_age, fithness_age, risk_profession, risk_hobby, driving_experience};
CONTRACT = {SUM, YEARS, TYPE, insured_losses}.
На підставі правил бази знань відбувається процес підрахунку важливості впливу кожного фактора, вхідного вектора даних і формується вектор indx_Risk[].
Цільова функція:
Обмеження по змінним:
- 0 ≤ AGE ≤ 60.
- Якщо FINANCE.Annual_Client_payment ≥ (0.1 * FINANCE.Salary), то збільшити TOTAL_RISK.
Для кожної групи в рамках певного виду страхування, існує набір вагових коефіцієнтів. Усередині кожної групи визначається сумарний індекс, відповідно до бази правил. Далі множиться на груповий індекс і підсумовується для отримання підсумкового значення:
де subgroupW [j] – значення внутрішньогрупового вагового коефіцієнта j фактора, визначається з бази правил в залежності від значення j фактора при анкетуванні клієнта.
Висновок
В результаті проведеного аналізу цілей і методів кластеризації та побудови систем підтримки прийняття рішень встановлено, що:
- Для первинної кластеризації за згрупованою вибіркою факторів найбільш прийнятний метод Уорда, тому всередині кластерів оптимізується мінімальна дисперсія, в результаті створюються кластери приблизно рівних розмірів. Метод Уорда найбільш вдалий для аналізу соціологічних даних. В якості міри відмінності краще застосовувати квадратичне евклідова відстань, яке сприяє збільшенню контрастності кластерів;
- для перевірки адекватності формування кластерів пропонується ітеративно використовувати метод k-means, як найбільш простий і при цьому він дає досить достовірні результати. При цьому якщо порівнювані класифікації груп мають частку збігів більше 70%, то кластерне рішення приймається;
- для моделі СППР були обрані: модель представлення знань – продукційна модель, метод виведення – прямий нечіткий висновок;
- також використання нечіткої логіки і нечіткого виведення дозволить наблизити комп'ютерну модель до логіки діючих на даний момент бізнес-процесів страхової компанії.
Перелік посилань
- Развитие страхования в России – Страхование сегодня. История страхования [Електронний ресурс] / В. Г. Ларионов, М. Н. Скрыпникова – Електрон. текст. – [Росія, 2000]. – Режим доступу: https://www.insur-info.ru/history/press/d2451762.
- Глухова, Н. В. Теория принятия решений: учебное пособие /Глухова Н. В. – Ульяновск: Ульяновский государственный педагогический университет имени И.Н. Ульянова, 2017. – 50 c. – Электронно-библиотечная система IPR BOOKS: [сайт]. – URL: https://www.iprbookshop.ru/86329.html. – Режим доступу: для авторизир. користувачів.
- Доррер, Г. А. Методы и системы принятия решений: учебное пособие / Г. А. Доррер. – Красноярск: Сибирский федеральный университет, 2016. – 210 c. – Электронно-библиотечная система IPR BOOKS: [сайт]. – URL: https://www.iprbookshop.ru/84240.html.
- Кластеризация: алгоритмы k-means и c-means [Електронний ресурс] – 2009 – Режим доступу: http://habrahabr.ru/post/67078/.
- Реализация алгоритма k-means на С# (с обобщенной метрикой) [Електронний ресурс] – 2012 – Режим доступу: http://habrahabr.ru/post/146556/.
- Наследов А. IBM SPSS Statistics 20 и AMOS: профессиональный статистический анализ данных. – [Росія, Санкт-Петербург, 2013]. – Глава 21. Кластерный анализ.
- Кластерный анализ [Електронний ресурс] – StatSoft: Электронный учебник по статистике – Режим доступу: http://www.statsoft.ru/home/textbook/modules/stcluan.html
- Иерархическая кластеризация [Електронний ресурс]: Режим доступу: https://ranalytics.github.io/data-mining/102-H-Clustering.html
- Кластерный анализ – Википедия [Електронний ресурс]: Режим доступу: http://ru.wikipedia.org/wiki/Кластерный_анализ