Вступление
Обычно для визуализации трехмерного объекта необходимо
аппроксимировать его поверхность полигональной сеткой или набором сплайнововых
поверхностей, задать свойства материала, текстуры, расположить источники света,
положение камеры и, например, передать это все в OpenGL для визуализации.
Но если необходимо нарисовать объект сложной геометрии и со сложной текстурой (
например, замысловатый музейный эспонат или дерево с листьями, или
целый лес), то полигональное моделирование потребует очень много затрат, ведь
необходимо создать сетку, которая будет содержать как минимум десятки тысяч
треугольников, потом задать текстурные координаты и т.д. А откуда взять саму
текстуру? Таким образом, процесс моделирования усложняется в несколько раз.
Допустим, он благополучно
завершился и мы имеем полигональную модель. Передав ее в OpenGL, мы
обнаруживаем, что для моделирования всех шероховатостей и неровностей
поверхности, а также всяких мелких выступающих деталей нам потребовалось
намного больше полигонов, чем для создания основой структуры объекта! В
результате - медленная визуализация, при которой большинство исходных
треугольников проецируются в точку на экране, если вообще видны. Конечно,
существуют подходы к решению этой проблемы. Например, LOD (Level Of Details) .
Однако они не только не решают проблему моделирования реальных объектов, а в
некоторых случаях даже усложняют ее.
Существует принципиально
другой путь, под названием Image-Based Modeling and Rendering (далее IMBR).
Основной идеей этого подхода к моделированию и визуализации является работа с
заранее полученными изображениями, например, фотографиями. Самым простым и
примитивным воплощением этой идеи являются текстуры, которые, как известно,
призваны заменить моделирование сложных отражающих свойств материалов объектов.
Однако текстуры не избавляют от необходимости работать со сложными сетками, процесс
получения которых как правило слабо автоматизирован.
Главная идея IBR в том,
чтобы используя набор изображений одного и того же объекта, сделанных с
различных точек, получить вид этого объекта из произвольной точки положения
наблюдателя. Таким образом, значительно упрощается моделирование, а рендеринг
становится качественным по определению, потому что используются изображения
реальных объектов.
В июле 2000г. в лаборатории начался полугодовой проект "Advanced 3D rendering technology" при
поддержке Samsung Advanced Institute of Technology (http://www.sait.samsung.co.kr).
Была поставлена задача провести предварительные исследования в области синтеза изображений по
изображениям (Image-based rendering) для трехмерной графики и анимации.
Проект завершился успешно и получил продолжение в виде годового проекта (с апреля 2001г. по апрель 2002 г.) "Advanced
Methods of 3D Rendering and Animation", посвященного созданию и развитию нескольких форматов данных, основанных на
изображениях и их интеграции в узлы международного стандарта MPEG-4 для расширения новой версии MPEG-4, известного
как Animation Framework eXtension (http://mpeg.telecomitalialab.com/ ).
В результате было разработано семейство трехмерных форматов (в том числе анимационных), объединенных
понятием DIBR (Depth Image-Based Representations -- представления, основанные на изображениях с глубиной),
в настоящее время находящихся на этапе формального принятия в стандарт MPEG-4. Третий проект на эту же
тему начался с июля 2002г.
Модель, представленная в DIBR-виде, является набором изображений ("фотографий") объекта, сделанных с некоторых точек
таким образом, чтобы покрывать видимую поверхность объекта; каждому изображению сопоставлена карта глубины,
т.е. набор расстояний от плоскости камеры до поверхности объекта. Это представление проиллюстрировано ниже на
рисунке. Черно-белые изображения -- карты глубины.

Это базовая идея может быть обобщена различными способами. Например, карты глубины можно сделать многослойными или
преобразовать набор карт глубины в одну древовидную структуру (бинарное
волюметрическое октодерево). Оба варианта были реализованы в наших DIBR-форматах.
Основные текущие результаты проектов:
- основанные на изображениях форматы для статичных и анимированных трехмерных объектов
- Изображения с глубиной (DI - Depth Image), объединение произвольного набора пар 'цвет + глубина'
- Точечная текстура (PT - Point Texture, (многослойная карта глубины с цветом, получаемая после
проецирования объекта на некоторую плоскость (LDI - Layered Depth Image)
- Бинарное объемное октодерево (BVO - Binary Volumetric Octree), которое состоит из представленного
в виде восьмеричного дерева набора карт глубины, вместе с исходными изображениями объекта.
DI и BVO имеют анимированные версии. В анимированном DI изображения и карту глубины заменяются
видеопотоками. В анимированном BVO, изображения заменяются видео и вводится дополнительный поток бинарных деревьев.
Общие механизмы MPEG-4 позволяют комбининировать форматы различных типов, позволяя добиваться гибкости
для оптимального представления объекта.
- новый метод сжатия BVO без потерь
- метод основан на адаптивном арифметическом кодировании с использованием контекстного моделирования
- использование ортогональной инвариантоности позволяет сжимать и без того компактное безссылочное
представление восьмеричных деревьев в 1.5 - 2 раза.
- были разработаты простые и эффективные алгоритмы визуализации для DIBR-форматов
- в качестве примитивов визуализации используются сплаты адаптивного выбираемого размера
- визуализация основана на OpenGL API, что позволяет использовать аппаратные ускорители.
- интерактивная скорость визуализации для статичных и анимированных объектов
Описание метода
Существует
достаточно большое число различных методов IBR. Но почти все они либо
накладывают жестские ограничения на входные данные (например, позволяют
перемещаться только между точками из фиксированного набора), либо требуют
большое число изображений на вход, а при недостачном числе резко теряют в
точности. Это проявляется в виде дырок, артефактов и искажений выходного
изображения. Причина понятна: задача построения трехмерных данных из
изображений в общем случае некорректна. Чтобы повысить точность, желательно
использование дополнительных данных о геометрии объекта.
Быстрое развитие в последнее время средств трехмерного сканирования (range scanners) позволяет
получать такого рода информацию в виде карт глубины.
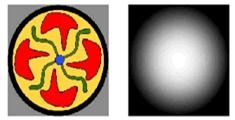
Предположим, что имеется
устройство позволяющее измерять расстояние по нормали от некоторой базовой
плоскости до интересующего нас объекта, выдавая результат в виде
полутонового изображения, яркость в каждой точке которого соответствует
расстоянию до объекта (чем точка дальше, тем она темнее). Также пусть оно умеет
определять цвет каждой точки, выдавая результат в виде изображения,
соответствующего карте глубины (см. рисунок).

Данной информации
достаточно, чтобы воспроизвести трехмерную форму объекта как она будет видна с
произвольной точки. Осталось только разработать соответствующие преобразования.
Будем считать, что
устройство сканирования использует ортогональную камеру для сканирования и,
следовательно, получившиеся рисунки сделаны в ортографической проекции.
Определим (с избыточностью) эту ортогональную камеру (см. рис.) как четверку (C,
a, b, f) .
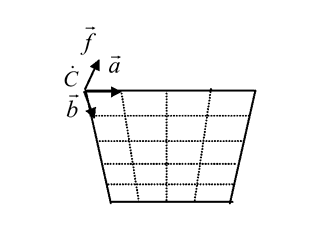
C - положение верхнего левого угла
(соответствует верхнему левому углу изображения).
a, b - векторы, направленные соответственно вправо и вниз.
f - вектор, направлен по направлению взгляда. Все глубины отсчитываются
в сторону вектора f. Он должен быть ортогонален плоскости (C, a,
b)
Пусть пользователь
находится в точке P и обозревает наш объект через перспективную камеру.
Хотя для математической корректности рассуждений следовало бы расписать
параметры камеры, в дальнейшем мы увидим, что нам потребудется только положение
наблюдателя P.
МакМиллан в своей
диссертации [2] показал, как при известных параметрах исходной камеры,
координат точки на базовой плоскости этой камеры, и расстоянии до точки
(глубине) получить координаты этой точки на базовой плоскости произвольной
камеры. Это формула вида xt = f(xs, d, Cs, Cd) Она
позволяет таким образом исказить (warp) исходное изображение, что с данного
положения и при данных параметрах камеры наблюдателя объект будет выглядеть
корректно, с учетом параллакса, перспективного и модельных преобразований. Эта
формула (несмотря на то, что она достаточна проста, приводить я ее здесь не
буду, чтобы не уходить в сторону от темы) называется формулой трехмерного
ворпинга изображений (3-D image-warping equation). Процесс такого
преобразования называется прямой трехмерный ворпинг (forward 3-D image
warp)
В 2000-м году Мартин
Оливейра [1, 3] развил работу МакМиллана, сделав возможным аппаратную поддержку
ворпинга с помощью обычных ускорителей трехмерной графики.
Чтобы прояснить ситуацию,
рассмотрим визуальные эффекты, которые создают эффект трехмерности объекта.
Это:
- параллакс (взаимное изменение положение частей
объекта, с возможным перекрытием)
- аффинное преобразования (смещение, поворот,
изменение размера)
- перспективное преобразование
Формула
трехмерного ворпинга учитывает все три эффекта. Однако мы знаем, что трехмерные
аффинное и перспективное преобразования делаются с помощью OpenGL, правда, для
многоугольников, а не для точек из карты глубины. С другой стороны, эффект
параллакса имеет двухмерную природу и фактически представляет из себя работу с
изображениями. Изображения можно рассматривать как текстуры, а текстуры можно
накладывать на объекты. Можно ли использовать этот факт и переложить часть ворпинга
на OpenGL (и, следовательно, аппаратуру)?
Оливейра показал, что
можно. Это делается путем факторизации формулы трехмерного ворпинга на две
части (так называемый serial warp - последовательный ворпинг), одна из которых
отвечает за параллакс, а другая - за аффинное и перспективное преобразования.
Первая часть выполняется программно и называется формула пре-ворпинга
(pre-warping) (как мы потом увидим, она одномерна, т.е. очень простая), вторая
же часть представляет из себя обычное текстурирование и делается с помощью
OpenGL.
В реализации этого метода и
состоит суть задания.
Простейший алгоритм такой:
P <-- Текущее положение наблюдателя (up, vp) <-- центр проекции на базовую плоскость Производим обход всех точек изображений Icolor, Idepth в правильном порядке(up,vp) для каждой точки (us,vs, Idepth(us, vs), Icolor(us, vs))> (ut, vt) = формула пре-ворпинга записываем точку в новое (целевое) изображение Itarg(ut, vt) <-- Icolor(us, vs) Устанавливаем в OpenGl положение наблюдателя P и параметры камеры Передаем в OpenGL базовую плоскость с полученным изображением как текстуру
Другими словами, все что нужно сделать, это ко всем точкам исходной пары
изображений цвет+глубина применить формулу, которая преобразует x,y,depth
--> x',y' и записать в пиксель x', y' нового изображения цвет исходного из
точки с координатами x,y. Затем это новое изображение накладывается как
текстура на базовую плоскость, представленную четырехугольником и передается в
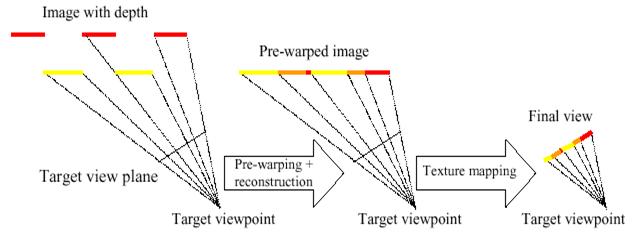
OpenGL для визуализации. Эта схема показана на рисунке ниже. (так же там
показана разница между forward 3-D image warp и комбинации pre-warp + texture
mapping)
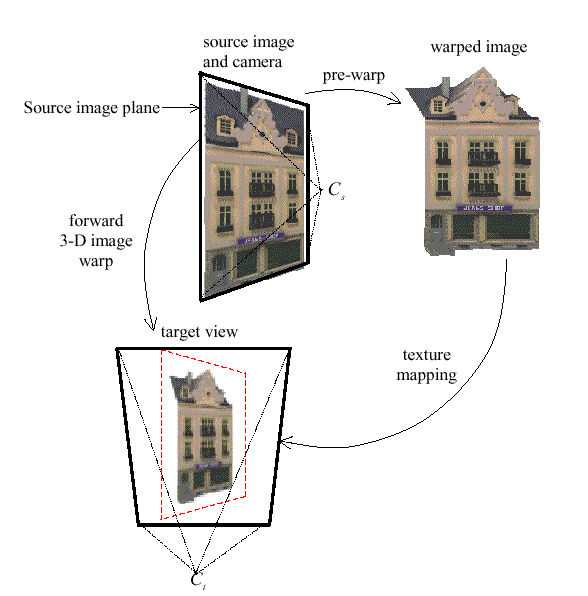
Вид этого процесса в
2D-проекции. Информацию про реконструкцию (reconstruction) можно найти в
разделе Продвинутые вопросы: интерполирование и сплаттинг
Определение текущего положения наблюдателя
Обычно в
определении положения наблюдателя нет никакой проблемы. Это, как нетрудно
догадаться, первые три параметра, которые вы передаете в gluLookAt(...). Однако
если для вращения объекта используется рекомендуемый модуль trackball, который
работает на уровне матриц, могут возникнуть сложности.
Вот код, получающий
координаты камеры из текущей модельной матрицы OpenGL:
double x_cam, y_cam, z_cam; double m[16]; // matrix glGetDoublev(GL_MODELVIEW_MATRIX, m); x_cam = -m[12] * m[0] - m[13] * m[1] - m[14] * m[2]; y_cam = -m[12] * m[4] - m[13] * m[5] - m[14] * m[6]; z_cam = -m[12] * m[8] - m[13] * m[9] - m[14] * m[10];
В качестве
дополнительного упражнения предлагается получить эту формулу самостоятельно.
Определение центра проекции
Знание
центра ортогональной проекции точки положения наблюдателя на базовую плоскость
необходимо для получения корректного порядка обхода изображения (см. ниже)
Центр проекции вычисляется
следующим очевидным образом:
c = P - С
up =c a
vp = c b
, где
P - положение наблюдателя
С - верхний левый угол базовой плоскости
up,vp - координаты точки проекции
Порядок обхода точек изображения
Для того,
чтобы в результирующей текстуре невидимые пиксели не перекрывали видимые, при
обходе исходного изображение необходимо использовать специальный порядок.
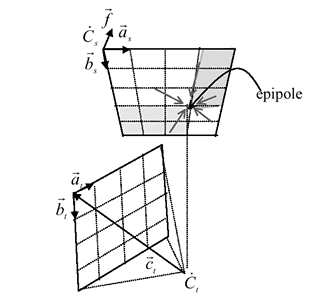
Обход делается так (см.
рисунок):
Изображение разбивается центром проекции up, vp (epipole на рисунке) максимум на четыре части. Для каждой части пиксели ворпируются в порядке от границы к центру проекции.
Существует
теорема, которая говорит о том, что при таком обходе исходного изображение
всегда получается правильный порядок пикселей в результирующем изображении,
т.е. более близкие к наблюдателю закрывают более дальние.
Формула пре-ворпинга
>Формула
прямого одномерного пре-ворпинга является ключевым моментом всего метода. Она
приведена ниже:
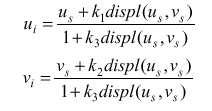 , где , где
us = 0..width - 1
vs = 0..height -1
displ(us,vs) = Idepth(us, vs)
Коэффициенты k1, k2 и k3
рассчитываются по следующим формулам (c = P - С)

Заметим, что преобразование
по каждой из координат является одномерным, т.е. не зависит от другой
координаты, а коэффициенты ki (i=1..3) не зависят от координат пикселя и
постоянны для данного положения наблюдателя P
Работа с OpenGL
Все что в
рамках данного задания нужно от OpenGL - это вывод одного текстурированного
полигона, соответствующего базовой плоскости. Его координаты можно легко
вычислить по следующей простейшей формуле:
p1 = C
p2 = C + a * width + b * height
, где
p1 - левый верхний угол
p2 - правый нижний угол
! Обратите внимание, что в
OpenGL началом отсчета для координат изображения считается левый нижний
угол
Оптимизация
Процесс
пре-ворпинга занимает больше всего времени при визуализации этим методом. Если
текстурирвание выполняется аппаратурой, то соотношение время пре-ворпинга /
время текстурирования достигает 10/1. Однако эти формулы, прежде всего из-за
своей простоты, дают много возможностей для оптимизации. Творческий подход
позволяет намного ускорить обработку изображения.
Прежде всего важно число
операций на одну точку исходного изображения. Это число можно уменьшить,
воспользовавшись тем, что в постановке задачи фигурирует дискретная глубина.
Число значений ограничено 255. При этом коэффициенты k1, k2 и k3 не зависят от
координат и глубины конкретных пикселей.
Можно при изменении
положения наблюдателя строить таблицы для каждого из коффициентов, умноженных
на глубину. Таким образом можно избавиться от двух умножений и деления, заменив
их на 2 индексации и умножение:
const int MAX_DEPTH = 255;double k1pr[MAX_DEPTH]; double k2pr[MAX_DEPTH]; double k3pr[MAX_DEPTH]; k1pr[i] = k1 * i; k2pr[i] = k2 * i; k3pr[i] = 1.0 / (1 + k3 * i);
Тогда
формула будет иметь следующий вид:
ud = (us + k1pr[d]) * k3pr[d]; vd = (vs + k2pr[d]) * k3pr[d];
Также важно
оптимизировать сам цикл обхода. Существует очень много различных техник
оптимизации на самых разных уровнях.
Продвинутые вопросы: интерполирование и сплаттинг
При
реализации подобных image-based алгоритмов неизбежно возникают проблемы дырок,
т.е. пиксели, которые должны были быть залитыми, оказываются прозрачными.
Главная причина появления
дырок - это сама природа алгоритмов визуализации, основанных на изображениях.
Дырки является следствием недостатка информации, ведь мы не можем заглянуть
"между пикселями" исходных изображений, а иногда это требуется.
Причины появления дырок
более подробно:
- Недостаточность информации. Карты глубины по
определению могут содержать информацию только видимую с некоторой камеры.
Если пользователь при просмотре значительно отклонится от этого положения
(в нашем случае если направление взгляда пользователя будет сильно
отличаться от нормали к базовой плоскости), но он может
"увидеть" места, которые были не видны изначально и информации о
которых нет.
- Точки в исходном изображении обладают конечным
размеров. По сути, это не точки, а сэмплы. Их можно представить
маленьким элементом поверхности с конечной площадью. После преобразований
пре-ворпинга и текстурирования размер сэмпла изменяется. Если по-прежнему
рисовать его одной точкой, то возникают дырки. Исходные данные не
содержает какой-либо информации о связанности, поэтому мы не можем просто
заполнить пустое место, аппроксимировав поверхность треугольником.
Варианты
решения проблемы
1) Сплаттинг. Принимая во
внимание, что сэмпл обладает конечным размером, можно аппроксимировать размер
точки в конечном изображении, заменяя ее так называемым сплатом.
Разработано множество эвристик для такого процесса, однако в рамках данного
задания предлагается поэксперементировать только с размером сплата. Неплохих
результатов можно достичь, просто заменяя каждую точки на квадрат 2x2 или 3x3.
2) Интерполяция. В работах
Оливейры [1,3] предлагается другой метод, основанный чисто на работе с
изображениями. Процесс пре-ворпинга разбивается на два этапа. На первом
делается только горизонтальный (или вертикальный) проход, т.е. ко всем точкам
применяется только горизонтальное (вертикальное) смещение. На втором проходе
применяются оставшиеся преобразования, но при этом вычисляются расстояние в
целевом изображении между текущим и предыдущим ворпированным пикселем и если
оно больше 1, то промежуток заполняется интерполированными значениями цвета.
Рекомендуется попробовать этот метод, тем более что он хорошо описан в
предгалагаемой литературе. (особенно [1])
Литература
[1] Oliveira, M. et al. Relief Texture Mapping.
Siggraph'2000 conference proceedings.
[2] McMillan, L. An
Image-Based Approach to Three-Dimensional Computer Graphics. Ph.D.
Dissertation. UNC Computer Science Technical Report TR97-013, University
of North Carolina, April 1997.
[3] Oliveira, M. Relief Texture Mapping.
Ph.D. Dissertation. UNC Computer Science Technical Report TR00-009. 2000.
|