Ueber mich
Praktikum in Deutschland: Ueber IPVS Aufgabenstellung Uber die Arbeit
Effiziente Indexstrukturen zur Auswertung raeumlicher Ereignisse
In der zukunftigen Anwendungen die Gewaehrung von kontextbezogenen Informationen wird genaue Information ueber die Positionen von riesigen Nummer mobiler Objekte fordern. Das bedeutet, dass Locationsysteme, die faehig sind solche grosse hoechstdynamische Datenmengen zu bearbeiten, muessen entstehen. Um effizient aktuelle Information zu bekommen (z.B. alle Objaekte innerhalb einem bestimmten Gebiet), muessen diese Systeme adaequat Indexstrukturen besitzen. In Vergangenheit wurden solche Strukturen nur fuer die geometrische Darstellung der Lokationsinformation erforscht. Dennoch, besonders innerhalb eines Gebaeudes, basieren viele Postitionirungsysteme lediglich auf symbolische Identifikatoren. Um fuer symbolische Daten Gebietanfragen zu ermoeglichen, muessen raeumliche Beziehungen auf der Grundlage eines Lokationmodels modelliert werden. Das Modell, das Inklusionsbeziehungen beschreibt, kann als orientirter acyclischer Graph dargestellt werden. Jeder von seinen Knoten stellt irgendwelches Gebiet dar und jede Kante - die Tatsache, dass der folgende Knoten raeumlich in dem vorhergehenden Knoten liegt. In dem Lokationsmodell, das so dargestellt wird, die Knoten von der niedrigsten Ebene sind die feinste Elemente des Modells. Das heisst, alle mobilen Objekte, die im Modell registriert werden, befinden sich auf dieser Ebene.
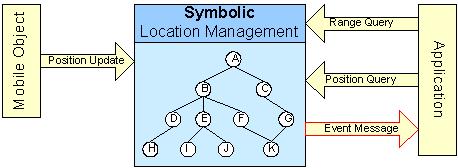
Abb. 1.
Tobias Drosdol in seinem Artikel zeigt zwei Hauptansaetze fuer effiziente Indexierung. Die geben zwei Operationen wieder - Positionsupdate/anfrage und Gebietsanfrage. Die folgende Arbeit behandelt die Auswertung raeumlicher Ereignusse basierend auf der Untersuchungen, die im Artikel durchgefuehrt wurden.
Ein Ereignis, das im Modell registriert wird, muss folgende Information darstellen: Typ des Ereignises (onEnter oder onLeave), ein Gebiet (sein symbolische Darstellung) und Hoerer ID, der eine Benachrichtigung ueber ein Eriegnis bekommen soll. Zwei verschiedene Typen von Ereignissen fuehren zur Erstellung von zwei Maps fuer ihre Speichrung. Es kann auf verschiedenen Weisen realisiert werden. Einerseits, wenn ein Ereignis mit einem Gebiet identifiziert wird, waere es logisch dieses Ereignis unmittelbar im Knoten speichern, der dieses Gebiet vorstellt (weiter - Variante 2). Anderseits, wie es schon frueher gesagt wurde, befinden sich alle mobilen Objekte auf der niedrigsten Ebene. D.h. die moeglichen Ereignisse werden auch aud dieser Ebene stattfinden, was laeest uns die Erignisse in den Blaettern speichern (weiter - Variante 1).
Variante 1
Wenn ein Ereignis in den Knoten gespeichert wird, muessen wir den Baum nach unten bis zur niedrigsten Eben traversieren um alle Kinderknoten vom Gebiet zu finden.

Abb. 2.
Die Abbilding zeigt, dass dasselbe Ereignis mehrmals gespeichert werden muss. Mehr wessentlicher Mangel ist zusaetzliche Zeit, die man braucht um den Baum zu traversieren und alle Blaeter zu finden. Dennoch solcher Ansatz erleichtert Positionsupdates. Um ein Ereignis zu registrieren muss man eine alte mit einer neuen Position des Objektes vergleichen. Das Objekt bewegt sich nur auf der niedrigsten Ebene, wo auch Positionen gespeichert werden, d.h. man braucht keine Traversierung des Baums nach oben. Wenn wir auch die Tatsache beruecksichtigen, dass Positionsupdate ziemlich oft vorkommen, spart der untersuche Ansatz die Zeit bedeutend. Hier muss man auch Gebietsinklusionen beruecksichtigen.
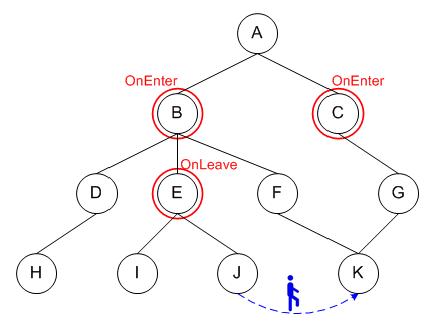
Abb. 3.

Abb. 4.
Variante 2
Weil jedes Ereignis mit einem bestimmten Gebiet assoziiert wird, waere es logisch es unmittelbar bei diesem Gebiet zu speichern, was die Suche nach Nachkommenen ausschliessen wuerde.

Abb. 5.
In diesem Fall ausschliessen wir die Probleme, die beim Einfuegen vom Ereignis in der ersten Variante entstanden haben (dasselbe Ereignis in mehreren Knoten speichern, den Baum zu traversieren). Dennoch erhalten wir neue Maengel bei den Updates und folglich bei den Registrierungen von Ereignissen.
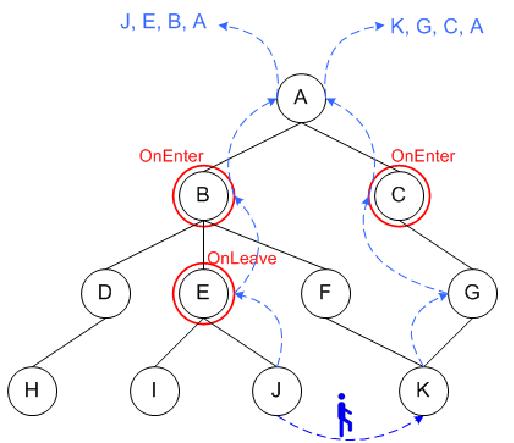
Abb 6.
Betrachten wir die Abbildung 6. Ein mobiles Objekt bewegt sich aus dem Gebiet J ins Gebiet K. Rote Kreise bezeichnen die Knoten mit den eingefuegten Ereignissen. Moegliche onEnter Ereignisse koennen im Knoten K oder in einem seiner Eltern stattfinden, onLeave - im K oder in einem seiner Eltern. Auf diese Weise braucht man eine traversierung des Baums im Suche nach den Eltern von beiden Knoten. Die Suche gibt folgende Ergebnisse: Eltern(J) = {J, E, B, A}, Eltern(K) = {K, G, C, A}. Auf dieser Etappe muss man Gebietsinklusionen beruecksichtigen. Die Anwesenheit von Knoten A in beiden Datenmengen bedeutet, dass das Objekt das Gebite nicht betreten und nicht verlassen hat, also das Ereignis konnte nicht stattfinden. D.h. man muss nicht der Knote A betrachten, was laesst Knoten J, E, B fuer die Analyse des onLeave Ereignises und K, G, C - onEnter. Die endgueltige Analyse stellt onLeave Eregnis im E und onEnter im C fest.
Das Beispiel, das betrachtet wurde, zeigt, dass die zweite Variate kompliziert Updates. Wenn man auch die Tatsache beruecksichtigt, dass solche Updates viel oefter als Einfuegen stattfinden, dann bei kleinem Anzahl von Gebietsanfragen, kann der Ansatz sehr aufwendig werden.
Ein andere Moeglichkeit ist die Kombination von beiden Varianten, d.h. das Benutzen von einem Threshold, das das Modell in zwei Teile teilt. Einer von den wird als die erste Variante betrachtet und der anderen - als die zweite.