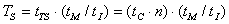Тема работы: "Исследование
способов организации обмена данными при параллельном
моделировании и разработка программного обеспечения
приёма и передачи данных для системы Simulink".
Cовременный мир требует от человечества решения сверхсложных
задач. Человек уже давно не может решать многие технические
задачи самостоятельно и прибегает к помощи электронных
вычислительных машин (ЭВМ). Но сложность задач, например
в микробиологии, прогнозе погоды, оптимизации сложных
систем, космической отрасли, растёт несоизмеримо быстрее,
чем производительность отдельной
ЭВМ, что наталкивает
на мысль использования "одновременных" (параллельных)
расчётов на нескольких ЭВМ или ЭВМ со сложной многопроцессорной
структурой. Проиллюстрировать различие выполнения программы
на одном и нескольких процессах можно с помощью железнодорожных
перевозок (рисунок 1). Представим, что локомотив с
вагонами -- поток команд, станция назначения -- процессор,
время, прошедшее с момента старта состава и до момента
захода последнего вагона в станцию -- время выполнения
программы. Очевидно, что программа на N процессорах
будет выполняться в N раз быстрее. Однако это возможно
только при отсутствии последовательной части программы
и на 100% сбалансированной загрузки процессоров. На
практике всемя выполнения параллельной программы можно
оценить с помощью закона Амдала (рисунок 1, параллельное
выполнение программы), где Тп - время выполнения последовательной
части, f - доля последовательной части в общем количестве
вычислений, N - количество процессоров.
Рис. 1 -- Иллюстрация выполнения параллельной и последовательной
программ.
Не следует также забывать о знаменитом примере с землекопами:
если один землекоп выкопает яму за 1 час, то два таких
же землекопа это сделают за 30 мин, но 60 землекоповне
сделают эту работу за 1 минуту! Начиная
с некоторого момента
они будут просто мешать друг другу, замедляя
процесс, т.е. если задача слишком
мала, то система будет дольше заниматься распределением
работы, синхронизацией процессов, сборкой результатов
и т.д., нежели непосредственно вычислительной работой.
Критическим местом в параллельной вычислительной машине
является не само вычисление, а обмен данными (как
исходными, так и результатами) между вычислительными
узлами системы. В данной работе на первом этапе рассматривается
один из способов обмена данными: с помощью библиотеки
MPI. Параллельно студентом Бурбой Виктором разрабатывается
модель обмена данными по протоколу
Целью данной работы является исследование различных
подходов к обмену данными между процессорами с
для повышения быстродействия,
а также разработка соответствующего ПО и применение
этих способов обмена.
Достижение поставленной задачи выполняется путем:
- исследования сложного динамического объекта с распределенными параметрами;
- исследования способов обмена данными;
-
исследования организации суперЭВМ и слабосвязанных
кластеров;
- исследования предложенной системы моделирования Simulink;
- разработка с учетом вышеперечисленных пунктов ПО обмена данными для системы
моделирования Simulink.
В первой части работы в качестве высокопроизводительной
вычислительной системы использовался слабосвязанный
кластер -- несколько
высокопроизводительных узлов, объединенных вместе скоростными
каналами передачи данных.
Реализация параллельных моделей
Для проведения модельных экспериментов требуется комплекс аппаратно-программных средств, который можно назвать моделирующей средой или средой моделирования. Эти термины обозначают одно и то же, рассматриваемое с различных точек зрения. В тех случаях, когда при описании или изучении большее внимание уделяется активному аспекту аппаратно-программного комплекса, используется название «моделирующая среда». В тех же случаях, когда важнее сама модель, а системе, обеспечивающей функционирование этой модели отводится второстепенная роль – эта система называется средой моделирования.
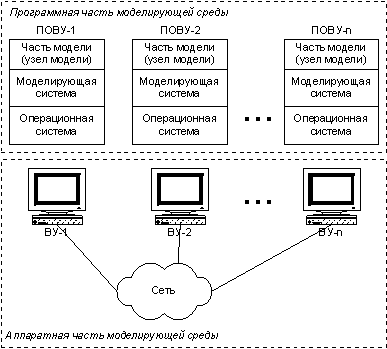
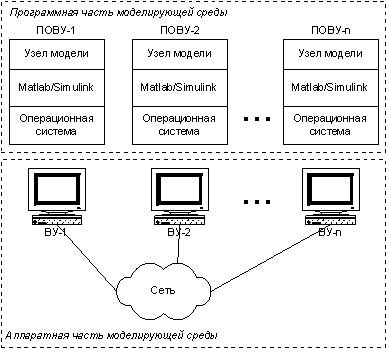
В моделирующей среде (рис. 1.1) можно выделить две основные части – аппаратную и программную. Аппаратная часть в общем случае представляет собой MIMD-компьютер, т.е. систему взаимодействующих вычислительных узлов (ВУ), каждый из которых способен обрабатывать отдельный набор данных по своей собственной программе с помощью соответствующего программного обеспечения – ПОВУ (программное обеспечение вычислительного узла). Это программное обеспечение включает в себя операционную систему, моделирующую систему и часть модели, выполняющуюся в данном узле.
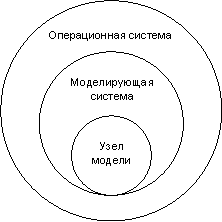
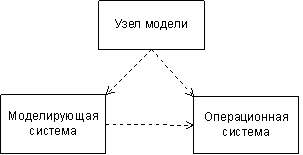
В данном случае под моделью понимается программное обеспечение, которое используется для имитации поведения некоторой физической или технической системы. Часть модели, выполняющуюся в одном вычислительном узле, назовём узлом модели. Каждый узел модели функционирует и взаимодействует с другими узлами посредством моделирующей системы, которая в свою очередь реализуется в операционной системе. Под моделирующей системой в данном случае понимается ПО, специально предназначенное для создания узлов модели и проведения модельных экспериментов. Примером моделирующей системы может служить Simulink. Соотношения и взаимоотношения между компонентами ПОВУ показаны на рис. 1.2 и 1.3 соответственно. Рис. 1.2 иллюстрирует тот факт, что узел модели может выполнять свои функции только внутри моделирующей системы, которая, в свою очередь, может функционировать только внутри операционной системы. Соприкасающиеся окружности узла модели и моделирующей системы указывают на то, что узел модели не ограничен целиком моделирующей системой, но может обращаться и к операционной системе непосредственно. Рис. 1.3 раскрывает далее эти соотношения между тремя компонентами, показывая связывающие их взаимоотношения использования. Узел модели использует функции как моделирующей системы, так и операционной системы, а моделирующая система использует только функции операционной системы.
Рис. 1.1. Моделирующая среда
Рис. 1.2. Соотношения между компонентами ПОВУ
Рис. 1.3. Взаимоотношения между компонентами ПОВУ
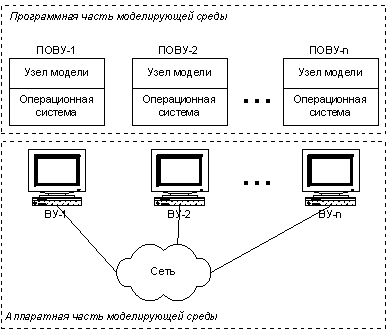
Можно предложить два подхода к реализации ПО вычислительных узлов. Первый подход заключается в запуске системы Simulink одновременно на нескольких узлах сети, при этом каждый экземпляр Simulink выполняет свою часть модели, периодически обмениваясь промежуточными результатами с другими экземплярами (рис. 1.4). Второй подход предполагает использование возможности Simulink преобразовывать блок-схему модели в исходный код на языке С, который затем может транслироваться в исполняемый код определённой параллельной ЭВМ (рис. 1.5).
Рис. 1.4. Первый вариант реализации ПОВУ
Преимущество первого подхода состоит в относительной простоте, так как в этом случае не требуется никаких других действий, кроме создания блок-схемы модели. Однако этот подход имеет и существенные недостатки – зависимость от операционной системы (известны версии Matlab/Simulink только для операционных систем семейства UNIX, Macintosh и Microsoft Windows) и относительно низкая скорость проведения модельного эксперимента. Первый подход можно использовать на этапе отладки модели.
Рис. 1.5. Второй вариант реализации ПОВУ
Второй подход, хотя и требует дополнительных этапов трансляции, однако при этом он свободен от указанных недостатков первого подхода, так как на основе исходного текста на языке С можно получить исполняемый код практически для любой современной операционной системы.
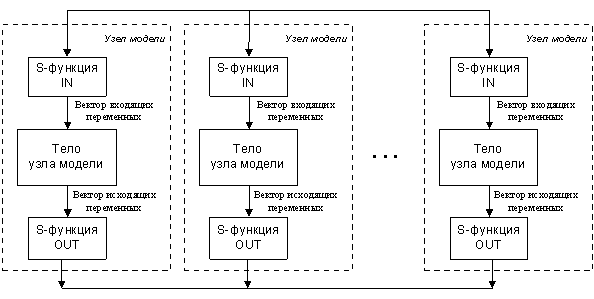
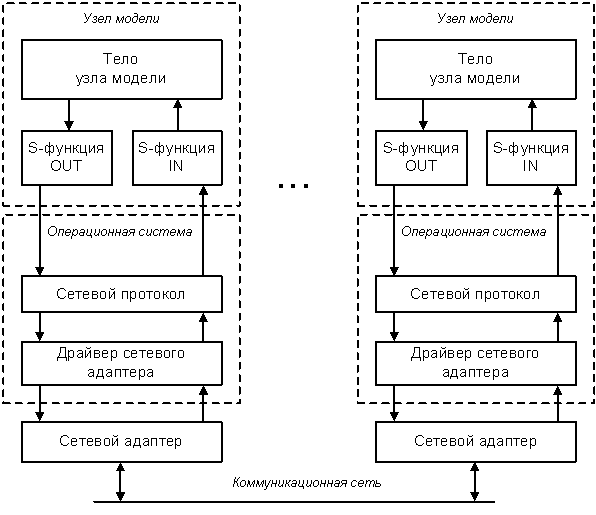
Как при первом, так и при втором подходе необходимо обеспечить связь между частями модели, независимо от того, выполняется ли она в Simulink или непосредственно в виде двоичного кода. Используя имеющуюся в Simulink возможность создания новых функциональных блоков (так называемые S-функции) разрабатываются специальные коммуникационные блоки (КБ) для обмена данными между отдельными частями модели (рис. 1.6). Эти блоки должны подключаться в тех точках блок-схем, в которых требуется обмен результатами вычислений. Обмен подразумевает приём и передачу данных, таким образом, должно быть два типа коммуникационных блоков – передающий и принимающий. В Simulink есть понятие подсистемы, т.е. относительно независимой части модели. Это понятие используется для обеспечения наглядности и обозримости сложных моделей, состоящих из большого количества блоков. Подсистемы Simulink соединяются друг с другом посредством специальных связных блоков, обозначаемых IN и OUT. Эти стандартные блоки обеспечивают передачу данных между подсистемами только в пределах одного экземпляра Simulink. Предлагается расширить возможности связи между подсистемами введя новые типы коммуникационных блоков, реализующих обмен данными между различными экземплярами Simulink (рис 1.7).
Детали реализации и эффективность новых коммуникационных блоков существенно зависит от сетевых протоколов, используемых для связи между узлами моделирующей среды.
Рис. 1.6. Обмен данными между узлами модели
Рис. 1.7. Реализация обмена данными между узлами модели
Организация обмена данными между узлами модели
Организация обмена данными между узлами модели зависит от аппаратной части моделирующей среды. Если в качестве аппаратной части используется группа независимых компьютеров, подключённых к общей сети (кластер), то обмен данными между элементами такого кластера возможен с помощью стандартных сетевых протоколов, например, TCP/IP (рис. 1.8).
Рис. 1.8. Обмен данными в кластере независимых ЭВМ
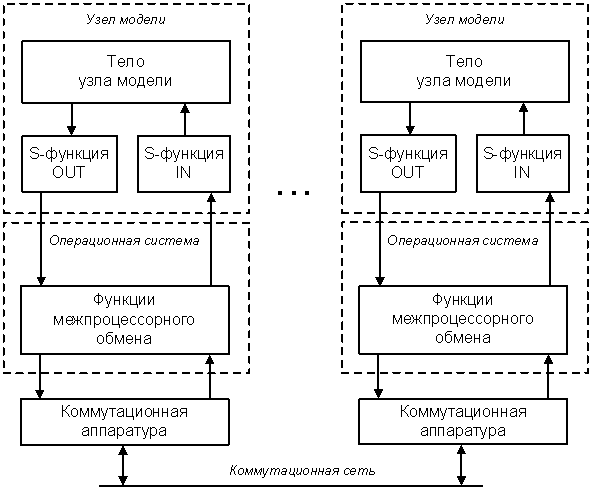
Если же аппаратная часть представляет собой специализированную параллельную ЭВМ MIMD-структуры, то обмен данными будет осуществляться на аппаратном уровне через коммутационную сеть этой ЭВМ, а на программном уровне – средствами операционной системы (рис. 1.9). В этом случае можно также применять и стандартные сетевые протоколы, но обмен в этом случае будет менее эффективным по сравнению со специализированными средствами ОС параллельной ЭВМ.
Как в первом (кластер), так и во втором случае (параллельная ЭВМ) передача данных может быть организована как в виде широковещательных сообщений, так и в виде индивидуализированных посылок. При широковещательной передаче каждый узел модели передаёт данные всем остальным узлам, независимо от того, требуется ли адресатам эта информация или нет. При индивидуализированных посылках каждый узел модели отправляет свои данные только тем узлам, которым действительно нужна эта информация для продолжения вычислений.
Рис. 1.9. Обмен данными в параллельной MIMD-ЭВМ
Широковещательный способ обмена более прост в реализации, но менее эффективен, так как с ростом количества узлов модели резко возрастает объём принимаемой и обрабатываемой каждым узлом информации и, следовательно, требования к быстродействию сетевой аппаратуры и самих узлов.
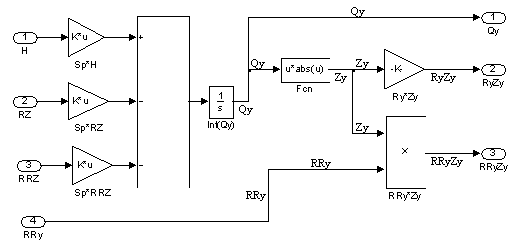
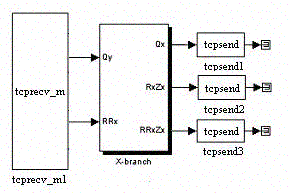
Узел модели, рассчитывающий ветвь аэродинамического объекта Y может выглядеть следующим образом (рис. 1.10). Центральный блок Y1 представляет собой подсистему, моделирующую ветвь Y. Структура этой подсистемы показана на рис. 1.11. Блоки tcprecv_m и tcpsend – S-функции, выполняющие соответственно приём и передачу данных по протоколу TCP. Входными данными для этого узла модели являются: депрессия вентилятора H, значения RZ и RRZ, вычисленные в других узлах модели, а также величина регулируемого аэродинамического сопротивления данной ветви RRy. Выходными данными являются: расход воздуха в данной ветви Qy, величины RyZy и RRyZy для данной ветви.
Рис. 1.10. Узел модели, рассчитывающий ветвь Y
Рис. 1.11. Структура подсистемы Y
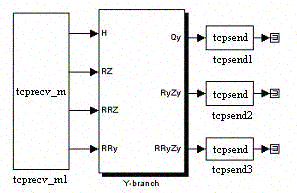
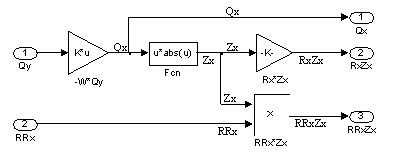
Узел модели, рассчитывающий ветвь X (рис. 1.12), принимает два входных значения – расходы воздуха Qy в ветвях Y и регулируемое аэродинамическое сопротивление данной ветви RRx. Выходными значениями блока являются: расход воздуха в данной ветви Qx, величины RxZx и RRxZx.
Рис. 1.12. Узел модели, рассчитывающий ветвь X
Рис. 1.13. Структура подсистемы X
Матрицы W, Sп, R и K заполняются на этапе инициализации модели. В подсистемах X и Y указывается один параметр – номер ветви. По этому номеру блоки подсистем выбирают соответствующие строки матриц W и Sp, а также значения постоянных аэродинамических сопротивлений R. Модели регуляторов сопротивлений и вентиляторов работают на отдельных вычислительных узлах и передают рассчитанные значения всем узлам X и Y.
Важным вопросом, влияющим на надежность и скорость обмена данными, является выбор сетевого протокола, используемого связными блоками для приёма и передачи результатов вычислений. Существуют протоколы, ориентированные на установление логического соединения и гарантирующие доставку данных (TCP, SPX), и более быстродействующие дейтаграмные протоколы, не гарантирующие доставку данных (UDP, IPX). В данном случае подразумевается, что связь между узлами модели на аппаратном уровне должна быть достаточно быстрой, иначе затраты времени на обмен данными существенно снизят эффективность параллельной модели. Исходя из этого, в качестве транспортного протокола был выбран протокол TCP, как более надежный, чем UDP или IPX и более распространённый в различных операционных системах, чем SPX. Для реализации передачи и приёма данных использовались функции библиотеки Windows Sockets, совместимые со спецификацией сокетов BSD Unix, что позволяет реализовать модель в широком диапазоне современных операционных систем, в том числе и в ОС реального времени. Связные блоки, использующие протокол TCP, предназначены, прежде всего, для параллельных ЭВМ, реализованных в виде кластера. Более универсальный вариант связных блоков основан на функциях библиотеки MPI. При использовании специализированных MIMD-ЭВМ этот вариант будет и более быстродействующим, чем вариант на основе TCP, так как реализации MPI для MIMD-ЭВМ используют соответствующие средства быстрого межпроцессорного обмена данными.
Алгоритм создания параллельной модели
Процесс создания параллельной модели состоит из следующих этапов:
Генерация узлов модели и файлов инициализации.
Трансляция узлов модели и компоновка исполняемых модулей.
Загрузка узлов модели в вычислительные узлы параллельной ЭВМ.
Для выполнения первого этапа необходимы данные о топологии сети и параметрах ветвей, кроме того, нужно знать количество имеющихся вычислительных узлов и их адреса. Топологические данные (матрица инциденций, матрица контуров и параметры ветвей) содержатся в файлах, сформированных топологическим анализатором [8]: taba.dat, tabs.dat, tabr.dat, tabh.dat, tabk.dat, tabnm.dat. Адреса вычислительных узлов должны быть указаны в файле hosts.ini. Имея все перечисленные исходные файлы, программа генерации узлов модели создаёт файлы в формате моделей Simulink (файлы MDL) и файлы инициализации (INI). Файлы инициализации используются связными блоками модели и содержат информацию об адресах вычислительных узлов.
На втором этапе узлы модели в формате Simulink транслируются в исполняемый двоичный код с помощью подсистемы Real Time Workshop. На третьем этапе эти исполняемые файлы загружаются в вычислительные узлы параллельной ЭВМ.
Оценка эффективности обмена данными
Пусть имеется n узлов модели, каждому из которых требуется tС с для выполнения вычислений, tR с для приёма данных и tS с для передачи данных. В худшем случае на каждый такт моделирования будет затрачено
tTP = tC + tR + tS с. Общая продолжительность параллельного моделирования TP зависит от шага интегрирования tI и от модельного времени tM :
(1.1)
Если считать, что время приёма tR и передачи tS зависит только от параметров аппаратуры и программного обеспечения и не зависит от объёма передаваемых данных, то длительность такта моделирования при параллельном выполнении модели не зависит от количества узлов модели.
При последовательном моделировании на однопроцессорной ЭВМ длительность такта моделирования можно выразить следующей формулой:
,
(1.2)
где tTS – длительность такта моделирования, tC – длительность вычислений одной X- или Y-цепочки, а n – количество ветвей графа сети. Общая продолжительность последовательного моделирования определяется следующей формулой:
(1.3)
Из формулы (1.3) следует, что общее время последовательного моделирования TS пропорционально количеству ветвей графа сети, и при достаточно большой разветвлённости графа моделирование на параллельной ЭВМ будет требовать меньше времени, чем на последовательной.
Заключение
В этой работе было выполнено исследование способов организации обмена данными в параллельных моделях. Также на основе предыдущего опыта моделирования сложных динамических объектов, исследования языков параллельного моделирования и основных архитектур параллельных ЭВМ было создано программное обеспечение моделирования сложного динамического объекта для системы Simulink.
В этой модели используется библиотека MPI для обеспечения передачи данных между узлами модели.
Литература
Бенькович Е.С., Колесов Ю.Б., Сениченков Ю.Б. Практическое моделирование динамических систем – СПб.: БХВ-Петербург, 2002. – 464 с.
Святный В.А. Подсистема аналого цифровых моделей САПР САУ и АСУ ТП. – В кн. Труды МВТУ №407. Автоматизированное проектирование систем управления. Межвузовский сборник. Вып. 2. – М.: МВТУ, 1984. – с. 137-145.
Braunl T. Parallele Programmierung: eine Einfuhrung. Mit Geleitwort von A. Reuter. – Braunschweig, Wiesbaden : Vieweg, 1993, 277 S.
Svatnyj V., Anoprienko A., Braunl T., Reuter A., Zeitz M. Massiv parallele Simulationsumgebung fur dynamische Systeme mit konzentrierten und verteilten Parametern. Simulationstechnik. 9. Symposium in Stuttgart, Oktober 1994, Vieweg, 1994, S. 183-188.
Using Simulink. The MathWorks Inc., 1998.
Kalman R., Mathematical Description of Linear Systems, RIAS Techn. Rep., p. 62–81, 1962
Lauber R. Proze?automatisierung. IAS der Universitat Stuttgart.
Перерва А.А. Топологический анализатор параллельной модели сетевого объекта. – Информатика, кибернетика и вычислительная техника (ИКВТ-99). Сборник научных трудов Донецкого государственного технического университета. Донецк, 1999, с.73-78.
Перерва А.А. Генератор и решатель уравнений проблемно-ориентированной параллельной моделирующей среды для сетевых объектов с сосредоточенными параметрами. – Проблемы моделирования и автоматизированного проектирования динамических систем. Сборник научных трудов. Донецкий государственный технический университет. Донецк, 1999, с.164-169.
Святный В.А., Молдованова О.В. Генератор уравнений параллельных моделей сетевых объектов с распределёнными параметрами. – Проблемы моделирования и автоматизированного проектирования динамических систем. Сборник научных трудов. Донецкий государственный технический университет. Донецк, 1999, с.135-141.

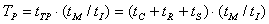
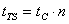 ,
,