Особенности контекстного поиска кластеризированных изображений
Автор: Вовк О.Л.
Источник: VII международная конференция «Интеллектуальный анализ информации ИАИ-2007». – Киев, 2007. - с. 22-31.
Работа посвящена выделению особенностей контекстного поиска изображений, основанного на сравнении характеристик отдельных групп пикселей (кластеров, регионов). Приведена математическая модель задачи контекстного поиска кластеризированных изображений. Показаны результаты экспериментов по оценке точности содержательного поиска визуальной информации
Введение
На сегодняшний день компьютер из вычислительной машины превратился в универсальное устройство, которое с равным успехом может служить профессиональным инструментом инженера, бизнесмена, юриста, врача или средством обучения, повседневного общения, развлечения. Для решения с помощью компьютера перечисленных выше задач необходимо соответствующее программное обеспечение, в основе которого различные методы обработки информации. Постоянное накопление электронных данных требует от разработчиков программного обеспечения и научных исследователей создания эффективных методов поиска в архивах информации (текстовой или визуальной). Поиск визуальной информации (изображений) затрудняется отсутствием однозначного текстового описания, по которому можно бы было индексировать изображения. Таким образом, решение задачи контекстного поиска изображений является актуальным.
Цель работы - разработка математической модели контекстного поиска кластеризированных изображений в базах данных; экспериментальная оценка качества системы поиска изображений, основанной на сравнении характеристик выделенных кластеров.
Анализ существующих методов контекстного поиска изображений
Запросы пользователей к коллекциям изображений традиционно классифицируют по трем уровням абстракции [1]: примитивный уровень (поиск по визуальным примитивам: цвету, форме, текстуре - найти изображения, подобные заданному), логический уровень (идентификация представленных объектов - найти изображения Эйфелевой башни), абстрактный уровень (учёт значимости изображённых сцен - найти изображения, отражающие определенные настроения).
Большинство методов поиска изображений в электронных коллекциях осуществляют удовлетворение запросов примитивного уровня абстракции. Рассмотрим базовые группы методов [2].
- Группа методов цветовых гистограмм. Идея метода цветовых гистограмм для индексирования и сравнения изображений сводится к следующему. Все множество цветов анализируемого изображения разбивается на набор непересекающихся, полностью покрывающих его подмножеств. Для изображения формируется гистограмма, отражающая долю каждого подмножества цветов в цветовой гамме изображения. Для сравнения гистограмм вводится понятие расстояния между ними.
- Группа методов поиска по «цветовой планировке». Отличительной чертой этой группы методов является предварительное разбиение изображений на блоки заданного размера или в заданном количестве. Этот этап позволяет учитывать местоположение того или иного цвета за счет сравнения между собой отдельных блоков, а не всего изображения целиком, что делает методы поиска по «цветовой планировке» более совершенными по сравнению с предыдущей группой методов.
- Группа методов, основанных на кластеризации изображений. При поиске изображений методами этой группы сравнение визуальных примитивов осуществляется на уровне отдельных объектов (регионов, областей) изображений, которые автоматически выделяются в процессе кластеризации на основании подобия значений визуальных характеристик внутри одной области.
Необходимо отметить, что корректное удовлетворение запросов возможно только при использовании методов из третьей группы в виду следующих недостатков методов других групп:
- при использовании методов первой группы возможно индексирование изображений только по цветовым характеристикам, при использовании методов второй группы - по цветовым характеристикам и характеристикам местоположения, а в случае применения методов третьей группы возможно выделение большего количества характеристик: цветовых, формы, текстуры и местоположения объектов изображений;
- «чувствительность» к масштабированию, повороту объектов внутри изображений в случае использования группы методов цветовых гистограмм, и к масштабированию - группы методов поиска по «цветовой планировке»;
- зависимость результатов поиска от вариации цвета и освещенности объектов на изображениях (в результате таких модификаций происходит изменение цветовых гистограмм анализируемых изображений).
Методы, в основе которых выделение регионов изображений, позволяют проводить контекстный поиск изображений и на логическом уровне абстракции, так как в их основе - выделение отдельных объектов изображений.
Общая схема содержательного поиска изображений в электронных коллекциях приведена на рис. 1 [2]. Блок, выделенный пунктирной линией, присутствует только при поиске, основанном на выделении регионов изображений.
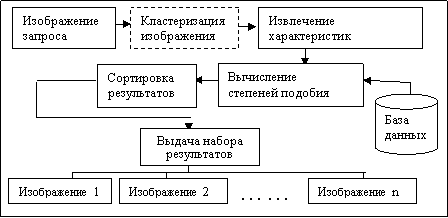
Рис. 1. Общая схема контекстного поиска изображений в базах данных на примитивном уровне абстракции
Также выделяют группу методов поиска на примитивном уровне абстракции, в основу которых положен механизм «обратной связи» [3]. При работе системы поиска с «обратной связью» пользователь должен выбрать одно или несколько изображений (образцов) поиска для того, чтобы инициализировать запрос. Исходя из информации о визуальных характеристиках изображения (ий) поиска, система получает первый запрос, моделирует, и отыскивает первый результат. Затем, в итерационном усовершенствовании обработанный результат может быть улучшен «обратной связью уместности», обеспеченной пользователем. Недостатком данной группы методов является субъективное определение визуального подобия изображений [3].
Существуют некоторые модификации общей схемы, приведенной на рис. 1, которые позволяют проводить поиск на логическом и (или) абстрактном уровне запросов.
Одна из таких модификаций - семантическая классификация изображений [2] в совокупности с методами поиска, основанными на кластеризации. Под семантической классификацией принято понимать разделение множества анализируемых объектов на несколько классов (обычно порядка 20 [2]). К примеру, семантическими классами могут быть: цветы, автомобили, здания и т.д.
Основным недостатком семантических систем принято считать [2] отсутствие корректных методов классификации изображений на группы. Самые распространенные методы семантической классификации делят объекты на два класса: «текстурированные» и «не-текстурированные» или «фотография» и «не-фотография» [2,4].
В качестве другой модификации общей схемы контекстного поиска визуальной информации можно выделить методы, которые дополняют стандартный содержательный поиск (рис. 1) поиском по текстовым описаниям [5]. Однако такой механизм поиска эффективен при поиске изображений, описание которых легко однозначно формализовать (примером может служить поиск изображения в оцифрованной коллекции картин с учетом фамилии автора картины). В других случаях, субъективное описание может только затруднить решение задачи поиска.
Математическая модель задачи контекстного поиска кластеризированных изображений
Пусть имеется база данных T, состоящая из n цифровых изображений ti, т.е. T={t1,t2,…,tn}. Изображение ti имеет размер wi×hi пикселов. Каждому пикселю pijk изображения ti соответствует три цветовых составляющих pijk={rijk, gijk, bijk}, отражающих интенсивности красного, зеленого и синего цветов соответственно, причем j, k соответствуют координатам пикселя изображения (![]() ,
, ![]() Необходимо отметить, что не обязательно три цветовые составляющие соответствуют интенсивностям красного, зеленого и желтого цветов (пространство цветов RGB), они могут также, к примеру, соответствовать цветовому тону, насыщенности и светлоте (пространство цветов HSL). Таким образом, изображение ti можно записать в виде:
Необходимо отметить, что не обязательно три цветовые составляющие соответствуют интенсивностям красного, зеленого и желтого цветов (пространство цветов RGB), они могут также, к примеру, соответствовать цветовому тону, насыщенности и светлоте (пространство цветов HSL). Таким образом, изображение ti можно записать в виде:
ti ={pijk={rijk, gijk, bijk}| |
(1) |
Кроме базы изображений Т, на вход системы контекстного поиска подается изображение образец (шаблон) поиска to:
to ={ |
(2) |
Содержательный поиск изображений в базах данных основывается на сравнении характеристик изображений базы данных Т и характеристик изображения образца поиска to. К характеристикам изображений относят характеристики: цвета, формы, текстуры, местоположения. Следовательно, каждому изображению ti![]() T соответствует вектор характеристик Сi={ci1, ci2, …,ciM} и изображению запроса to соответствует вектор характеристик Со={
T соответствует вектор характеристик Сi={ci1, ci2, …,ciM} и изображению запроса to соответствует вектор характеристик Со={![]() }. Следует отметить, что при реализации системы контекстного поиска изображений параметр М задается априорно и равняется анализируемому в работе числу характеристик изображений.
}. Следует отметить, что при реализации системы контекстного поиска изображений параметр М задается априорно и равняется анализируемому в работе числу характеристик изображений.
При вычислении векторов характеристик изображений Ci (или Co) учитываются характеристики цвета и геометрические характеристики местоположения пикселов pijk ( или![]() ).
).
В основе сравнения изображений по характеристикам [2] - расстояние di ![]() D (D={d1, d2, …, dn}) между характеристиками Сi={ci1, ci2, …,ciM} каждого из изображений ti
D (D={d1, d2, …, dn}) между характеристиками Сi={ci1, ci2, …,ciM} каждого из изображений ti![]() T и характеристиками изображения образца Со={
T и характеристиками изображения образца Со={![]() }. Для вычисления di наиболее часто используют среднее Евклидово расстояние [2]:
}. Для вычисления di наиболее часто используют среднее Евклидово расстояние [2]:
(3) |
Набор расстояний D упорядочивается по возрастанию. Результатом контекстного поиска является набор изображений R={ti | ![]() }, где L - заданное пользователем системы количество результатов контекстного поиска. Отметим, что каждому изображению ti соответствует расстояние di. Результатами поиска будут изображения ti базы данных, которые соответствуют меньшим значениям di, в количестве L. В случае, если в базе данных Т присутствует точная копия изображения образца to, то удовлетворяется условие:
}, где L - заданное пользователем системы количество результатов контекстного поиска. Отметим, что каждому изображению ti соответствует расстояние di. Результатами поиска будут изображения ti базы данных, которые соответствуют меньшим значениям di, в количестве L. В случае, если в базе данных Т присутствует точная копия изображения образца to, то удовлетворяется условие:
(4) |
Существует два основных способа вычисления характеристик изображения Ci(Co): вычисление характеристик всего изображения и вычисление характеристик отдельных групп пикселов (регионов, кластеров).
Рассмотрим более подробно второй из приведенных случаев (т.к. в предыдущем разделе обоснован выбор именно этого направления в качестве наиболее перспективного для исследований), математическая модель которого имеет следующие отличия.
Для пикселов pijk анализируемого изображения ti предварительно производится их группировка в отдельные кластеры aif, f![]() [1,Cli],
[1,Cli], ![]() причем Cli, в зависимости от используемых методов кластеризации, может, как задаваться априорно, так и вычисляться в процессе кластеризации. Таким образом, изображение представляется в виде:
причем Cli, в зависимости от используемых методов кластеризации, может, как задаваться априорно, так и вычисляться в процессе кластеризации. Таким образом, изображение представляется в виде:
(5) |
Также необходимо отметить, что выделенные подмножества пикселов aif должны не пересекаться (не иметь общих пикселов), т.е.:
(6) |
где y![]() [1, Cli], z
[1, Cli], z![]() [1, Cli], y≠z,
[1, Cli], y≠z, ![]()
В случае кластеризации изображения образца поиска to процедура выделения кластеров будет аналогичной описанной выше.
В данном случае, для сравнения изображений (нахождения расстояний между ними) формула (3) будет модифицирована за счет нахождения расстояний не между изображениями, а между отдельными группами пикселов анализируемых изображений. Для анализа близости изображения ti и изображения toрасстояние между ними можно определить по формулам [2]:
(7) |
гдеClo - количество кластеров изображения образца to, Cli - количество кластеров i-го изображения базы данных T, ![]() - степень различия u-го кластера изображения образца to и соответствующего кластера i-го изображения ti базы данных Т,
- степень различия u-го кластера изображения образца to и соответствующего кластера i-го изображения ti базы данных Т, ![]() - расстояние между и-м кластером изображения образца и b-м кластером изображения базы данных ti , Сb={cb1, cb2, …,cbM} - вектор характеристик b-ого кластера изображения базы данных ti, Сu={
- расстояние между и-м кластером изображения образца и b-м кластером изображения базы данных ti , Сb={cb1, cb2, …,cbM} - вектор характеристик b-ого кластера изображения базы данных ti, Сu={![]() } - вектор характеристик u-го кластера изображения образца поиска to.
} - вектор характеристик u-го кластера изображения образца поиска to.
Экспериментальная оценка характеристики точности контесктного поиска кластеризированных изображений
На основе предложенной в предыдущем разделе математической модели контекстного поиска изображений была построена экспериментальная программная система, в которой:- в качестве метода кластеризации использовался статистический иерархический агломеративный метод [6],
- в качестве цветовых характеристик - усредненные для кластера показатели для трех цветовых компонент пространства RGB,
- в качестве характеристик формы - первый момент инвариации [7],
- в качестве характеристик местоположения - векторы долей регионов в каждой из четырех основных частей изображений [8].
Автором работы предлагается модифицировать формулу (3) для расчета расстояния между анализируемыми изображениями путем введения приоритетов анализируемых характеристик для возможности удовлетворения большего числа запросов пользователей:
 |
(8) |
Числовые значения коэффициентов приоритетов предлагается рассчитывать как:
(9)

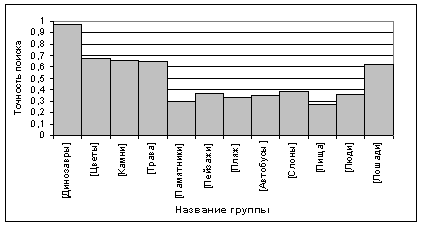
Рис.2. Результаты экспериментов по оценке точности контекстного поиска кластеризированных изображений
Заключение
В работе рассматриваются вопросы построения эффективных механизмов контекстного поиска в базах данных изображений. Проведен теоретический анализ основных существующих групп методов содержательного поиска изображений. В качестве наиболее перспективных предлагаются методы контекстного поиска изображений, основанные на сравнении характеристик отдельных групп пикселей. Построена математическая модель задачи контекстного поиска кластеризированных изображений. На базе предложенной математической модели разработана экспериментальная программная система, с помощью которой проведана оценка характеристики точности контекстного поиска изображений.Литература
- Eakins J.P., Graham M.E. A report to the JISC Technology Applications Programme. – NewCastle: Institute for Image Data Research, 1999. – 54 p.
- Wang J. Z., Li J. Wiederhold G. SIMPLIcity: Semantics-Sensitive Integrated Matching for Picture Libraries // IEEE Transactions on Pat-tern Analysis and Machine Intelligence. – 2001. – vol. 23, №9. – P. 947-963.
- Aslandogan Y.A, Yu C.T.. Automatic Feedback for Content Based Im-age Retrieval on the Web // IEEE ICME’02. - 2002. - vol.1. - P. 221 - 224.
- Li J., Wang J.Z., Wiederhold G.. Classification of Textured and Non-Textured Images using Region Segmentation // Proc. IEEE Interna-tional Conference on Image Processing (ICIP). – Vancouver, Canada. – vol. 3. – 2000. - P. 754 –757.
- Barnard K., Forsyth D. Learning the Semantics of Words and Pic-tures// International Conference on Computer Vision. – 2001. – P. 408-415.
- Башков Е.А., Вовк О.Л. Оценка эффективности нового статистиче-ского иерархического агломеративного алгоритма кластеризации для распознавания регионов изображений // Системні дослідження та інформаційні технології. – Інститут прикладного системного аналізу НАН України, Київ. – 2005. – №2. – с. 117-130.
- Вовк О.Л. Характеристики формы регионов изображений для кон-текстного поиска // Інформаційні технології та комп’ютерна інже-нерія. – 2005. – №1. – с. 104-108.
- Stanchev P.L. Content-Based Image Retrieval System // CompSysTech’2001. – Sofia, Bulgaria. – 2001. – P. 69-77.