

Алейкин Владислав Валерьевич
Специальность: Программное обеспечение автоматизированных систем
Тема выпускной работы: Распределенная система распознавания текстовой информации
Руководитель: доцент, к.т.н. Ладыженский Юрий Валентинович



Автореферат
Распределенная система распознавания текстовой информации
Система распознавания текстовой информации
(анимация: объем — 87 КБ, количество кадров — 10, количество циклов повторения — 7, размер — 500x419)
(анимация: объем — 87 КБ, количество кадров — 10, количество циклов повторения — 7, размер — 500x419)
Содержание
Введение
1 Актуальность темы
2 Научная новизна
3 Планируемые практические результаты
4 Обзор исследований и разработок по теме
5 Основная идея работы
5.1 Описание реализованного алгоритма
5.2 Тестирование и доработка
Результаты работы
Литература
Введение
Современные технологические, производственные и офисные системы в процессе своего функционирования используют информацию о маркировке объектов. Информация о маркировке грузов, вагонов, контейнеров, изделий позволяет рациональным образом организовывать процесс технологической обработки, вести учет и контроль изделий и материалов, прогнозировать потребность в них. В основе процессов использования маркировки лежит технология автоматизированного распознавания структурированных символов. Потребность в такой технологии вызвала необходимость создания методов, моделей и систем распознавания структурированных символов.
В настоящее время такие технологии реализуются тремя методами – структурным, признаковым и шаблонным. Каждый из методов ориентирован на свои условия применения, для которых он является эффективным. Каждый метод обладает недостатками. Наиболее существенные из них – высокая чувствительность к аффинным и проективным искажениям [1, 10].
Технологические условия получения информации о маркировке не позволяют полностью устранить искажения. Поэтому задача разработки методов распознавания структурированных символов, нечувствительных (или слабо чувствительных) к аффинным и проективным искажениям, остается актуальной.
1 Актуальность темы
Существует ряд программных продуктов, которые способны распознавать сканированные документы хорошего качества с текстовой информацией с вероятностью более 90%. Поэтому можно использовать такие программы, как в офисах, при распознавании документов, так и в промышленности, для контроля продукции и маркированных деталей.
При распознавании бумажных документов на практике ошибки в 10 буквах на одном листе не так значимы, как ошибки, получаемые в промышленной сфере. Различные условия окружающей среды при получении снимков деталей (рис. 1), а так же возможные повреждения маркировки (сколы, царапины, пятна и др.) приводят к снижению вероятности корректного распознавания символа на детали. Существующие программные продукты распознавания текстовой информации способны убрать слабые помехи в виде зернистого шума, связанного с низким качеством съемки. Более крупные помехи, имеющиеся программные продукты не способны определить и удалить со снимков [2,5,8].

Рисунок 1 - Пример промышленного изображения
2 Научная новизна
Существующие программные системы показывают низкий процент распознавания на изображениях с повышенным шумом и искажениями.
Научная новизна разрабатываемой системы заключается в применении распределенной обработки изображений с наложенными искажениями.
3 Планируемые практические результаты
После окончания разработки системы будет получен работоспособный программный продукт, предназначенный для эффективного распознавания текстовой информации с повышенным уровнем шума на изображениях.
4 Обзор исследований и разработок по теме
В мире существуют аналогичные программные продукты. Самыми успешным продуктами являются:
1) ABBYY FineReader. Данный продукт способен с высокой эффективностью справляться с офисными документами различного качества, но при применении на изображениях из промышленной сферы показывает низкую эффективность. Компания ABBYY распространяет свои модули распознавания отдельно от продукта FineReader, но стоимость использования модулей достаточно велика.
2) OCRopus – открыто-исходная технология, основанная на программном обеспечении “Tesseract”, решающая задачу индексации отсканированных документов, которые могут содержать любую смесь текста, изображений и посторонних пятен. Система ориентирована только на офисное использование. Применение в промышленной сфере дает низкие результаты.
На национальном уровне похожих систем не существует. Не было найдено никаких данных о планируемой разработке подобной системы.
В ДонНТУ исследованием задачи распознавания символов занимались следующие лица:
1) Исаенко Александра Петровна, «Использование нейронных сетей для решения задач распознавания образов». В разработке не предусматривается реализация удаления шума.
2) Дрига Константин Владиславович, «Распознавание зашумленных и искаженных образов с помощью неокогнитрона». Разработка не включает этапов предобработки изображений, что снижает эффективность работы распознавателя. В моей работе предусмотрен модуль предобработки, который исключает явные помехи на изображениях, и распознаватель выполняет более успешное определение символа.
5 Основная идея работы
Рассмотрим основные подходы для решения задачи распознавания символов: шаблонный, признаковый, структурный.
При шаблонном методе производится сравнение распознаваемого изображения с эталонными образцами из базы данных системы. При сравнении выбирается тот эталон, который будет минимально отличен от анализируемого изображения. Достоинство метода – высокая точность распознавания дефектных символов. Недостаток метода – невозможность распознать шрифт, хоть немного отличающийся от заложенного в систему.
Структурные методы распознавания хранят информацию не о поточечном написании символа, а о его топологии. Эталон содержит информацию о взаимном расположении отдельных составных частей символа. Достоинство метода – устойчивость к сдвигу и повороту символа на небольшой угол, к различным стилевым вариациям шрифтов [2]. Однако, при повороте на угол, больший десяти градусов, данный метод не может быть использован для распознавания символов.
Признаковые методы базируются на том, что изображению ставится в соответствие N-мерный вектор признаков. Распознавание заключается в сравнении вектора признаков с набором эталонных векторов той же размерности. Достоинства метода – простота реализации, хорошая обобщающая способность, высокое быстродействие. Недостаток метода – высокая чувствительность к дефектам изображения [2].
Все указанные методы ограничены в условиях применимости. Необходимо разработать метод распознавания, базирующийся на применении признаков, инвариантных к аффинным и проективным преобразованиям. В качестве таких признаков предлагается использовать топологические особенности символов, которые извлекаются при помощи методов анализа формы изображения [1].
5.1 Описание реализованного алгоритма
Данный метод является комбинацией трех описанных подходов и состоит из двух этапов:
– уточнение – вычисление признаков символа. На данном этапе на вход подается анализируемое изображение, на выходе получается вектор признаков для образа;
– распознавание – применение метода шаблонного сопоставления для распознавания символа. На вход подается анализируемое изображение и вектор признаков для входного образа. Сравнение входного образа происходит только с теми эталонными образами, у которых вектор признаков совпадает с входным вектором для анализируемого образа. На выходе получается результат распознавания.
Первый этап позволяет сократить количество эталонных образов для второго этапа, на котором находится наиболее похожий образ.
Изображения символов имеют характерные, специфические части, которые могут служить признаками. Для символа признаками являются части типа «залив» и «озеро». Наиболее значимыми являются «залив» и «озеро». «Заливы» примыкают одной стороной к символу, а другой – к границе образа. «Озера» не примыкают к границе образа, они находятся внутри символа. Например, у символа ‘B’ существует два «озера» (рис. 2а), а у символа «N» – два «залива» (рис. 2б).

a b
Рисунок 2 - Выделение морфологических признаков
Таких признаков вполне достаточно, чтобы дать предположение об исследуемом символе. Но важно знать? в какой части образа находится признак, а также количество признаков.
Введем вектор Х, содержащий признаки символа. Значение элемента вектора есть количество соответствующих признаков. Например, х[1] – верхний залив, х[2] – правый залив, х[3] – нижний залив, х[4] – левый залив, х5 – озеро, и х[3] = 2 означает, что символ имеет два нижних залива. Для эталонных образов изображения символов можно вычислить вектора признаков.
Для выделения таких признаков, как «залив» и «озеро» необходимо к анализируемому образу применить морфологические операторы [2, 3, 4].
Фундаментальными морфологическими операторами для множеств являются наращение и эрозия, которые определяются следующим образом:
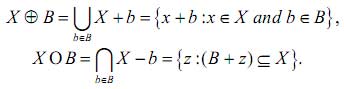
Где: Х – входной образ; х – единичный элемент входного образа; B – структурирующий элемент (СЭ) в виде матрицы; b – единичный элемент структурирующей матрицы; z – временная матрица для обработки.
Оператор наращивания утолщает символ на размер структурирующего элемента B. Эрозия выполняет обратное действие – оператор делает символ тоньше.
Для определения областей «заливов» и «озер» используются операторы размыкание и замыкание:
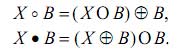
Размыкание подавляет острые выступы и прорезает узкие перешейки на изображении X, тогда как замыкание заполнят узкие заливы и малые отверстия. Используя сочетание таких операторов можно получить признаки образа. Исходное изображение преобразуется в изображение, содержащее области «заливов» и «озер» Полученные области будут располагаться отдельно друг от друга [1, 2, 4].
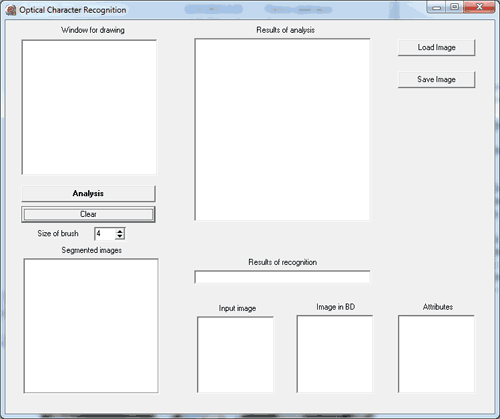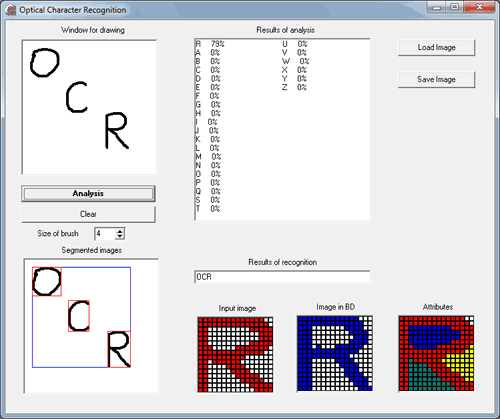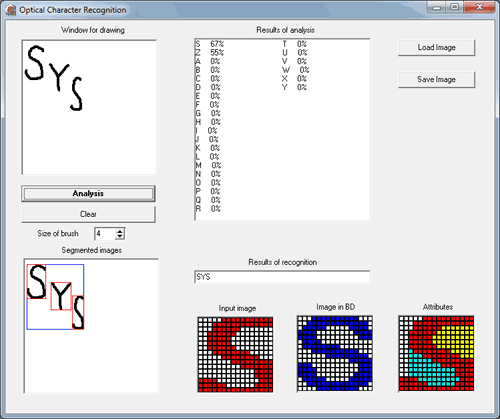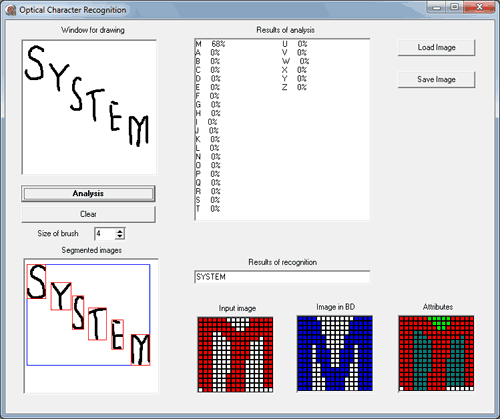
В качестве примера выполнения описанного метода ниже представлены результаты полученные программой (рис. 3). На рисунке слева показан исходный анализируемый символ, а справа результат выделение признаков «озер» и «заливов», снизу приведен вектор, характеризующий символ.

Ха = (0, 0, 0, 1, 1) Хw = (0, 0, 2, 1, 0)

Хz = (1, 1, 0, 0, 0) Хp = (0, 0, 0, 0, 1)
Рисунок 3 – Результат применения операторов выделение признаков
Данный метод хорошо работает на печатных символах. В символах, написанных от руки, применение метода обнаруживает ложные признаки, которые снижают точность распознавания или приводят к полной ошибке распознавания символа.
Экспериментальным путем было определено, что следует считать ложными признаками те области, площадь которых меньше 7 пикселей, если размер всей матрицы анализируемого образа составляет 256 пикселей [5].
После определения вектора признаков следует определить его принадлежность к определенному классу символов. Информацию о классах хранится в базе данных в виде таблицы (табл. 1).
Таблица 1 – Таблица классов символов
| № | Х(L, R, T, B, C) | Класс |
| 1 | 0 0 0 1 1 | A, R |
| 2 | 0 0 0 0 2 | B |
| 3 | 0 1 0 0 0 | C, E, F, G |
| 4 | 0 0 0 0 1 | D, O, P, Q |
| 5 | 0 0 1 1 0 | H |
| 6 | 0 0 0 0 0 | J, I, T, L |
| 7 | 0 1 1 1 0 | K |
| 8 | 0 0 1 2 0 | M |
| 9 | 1 1 0 0 0 | S, Z |
| 10 | 0 0 1 0 0 | U, V, Y |
| 11 | 0 0 2 1 0 | W |
| 12 | 1 1 1 1 0 | X |
Из таблицы 1 видно, что для английского алфавита будет выделено 12 классов, по которым в дальнейшем будет строиться ассоциация распознаваемого символа. Одному вектору признаков может соответствовать несколько символов (рис. 4, 5).
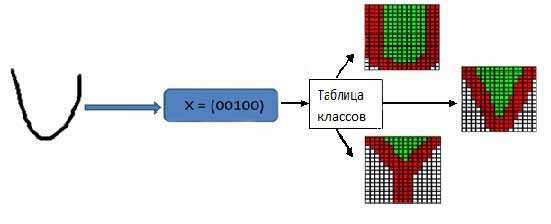
Рисунок 4 – Выделение класса для символа ‘U’
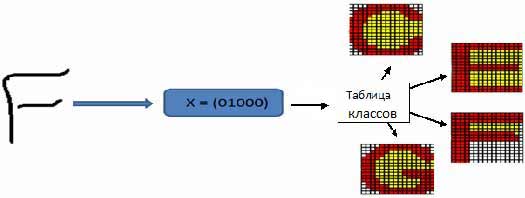
Рисунок 5 – Выделение класса для символа ‘F’
Второй этап алгоритма реализует нахождение наиболее похожего образа символа среди выбранного класса на первом этапе. Наиболее похожим образом является тот, который имеет наименьшее количество отличающихся пикселей от входного изображения:
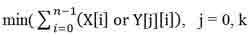
Где X – входной образ, У[j] – эталонный образ, n – размер изображения, k – количество эталонных образов.
Так как символ может быть написан под разным углом, в базу эталонных образов следует внести два дополнительных вектора признаков, которые вычисляются при повороте символа на +15 градусов и -15 градусов [6]. Такой подход позволяет охватить практически все варианты написания символов, но при этом:
1) точность распознавания повышается, за счет расширения эталонных образов;
2) замедляется выполнение программы, так как сравнение происходит с тремя наборами эталонных образов.
5.2 Повышение точности распознавания
При тестировании было выбрано 100 рукопечатных символов. Из них во время тестирования было распознано 87, что составляет 87% распознавания.
Для получения более высокой оценки распознавания было решено расширить множество эталонных образов с одного используемого шрифта до десяти шрифтов различного написания. Теперь каждый символ имеет десять эталонных образов и соответственно 10 различных векторных признаков. Из-за этого происходит пересечение одного класса с другим, что затрудняет распознавание.
Для решения этой проблемы второй этап алгоритма был усовершенствован. Изменение заключается в вычислении среднего арифметического процентов сходства для 10 вариантов написания символа. При этом необходимо пропускать эталонные образы, у которых вектор признаков отличен от анализируемого образа. Такой подход позволяет обработать только те символы, которые не сильно отличаются от анализируемого, что дает более точную оценку. На рисунках 6, 7 приведены результаты применения описанного подхода [1, 7, 9].

Рисунок 6 – Распознавание символа ‘U’
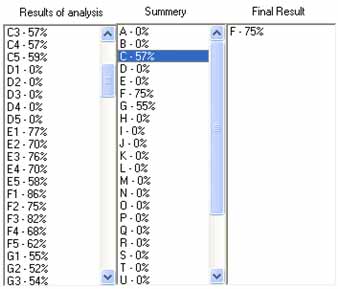
Рисунок 7 – Распознавание символа ‘V’
Для снижения количества проверяемых эталонных образов были введены дополнительные признаки для каждого символа. Вторичный вектор признаков Y состоит из следующих признаков:
– y1 – отношение площадей НЗ к ВЗ, y1=0 при отношении меньшем 0.5, y1=1 при отношении стремящемся к 1, y1=2 при отношении больше 1;
– y2 – отношение площадей ПЗ к О, y2=0 при отношении меньшем 0.5, y2=1 при отношении большем 0.5;
– y3 – отношение площадей НЗ к ЛЗ, y3=0 при отношении меньшем 1, y3=1при отношении большем 1;
– y4 – отношении высоты О к высоте символа, y4=0 при отношении стремящемся к 0.5, y4=1 при отношении стремящемся к 1;
– y5 – количество «заливов» и «озер», после применения операции генерация долин к исходному изображению с использованием СЭ в форме отрезка, длиной равного высоте символа, располагающимися под углами 45 и 135 градусов к оси абсцисс, и проведения логического сложение с результатами выполненной ранее операции генерации долин, y5 принимает значение равное количеству «заливов» и «озер»;
– y6 – отношение в ВЗ количества пикселей серого цвета в 1-ой строке к количеству серых пикселей во 2-ой строке, количества пикселей серого цвета во 2-ой строке к количеству серых пикселей в 3-ей строке, и так далее до последней строки, в которой есть серые пиксели ВЗ, y6=0 при плавном возрастаний отношений, y6=1 при резком скачке в отношениях или почти при равных отношениях;
– y7 – расположение О относительно середины символа, y7=0 при О, располагающемся в верхней части символа, y7=1 при О, располагающемся в нижней части символа.
После применения вторичного вектора признаков количество анализируемых эталонных образов снижается, что значительно ускоряет обработку при распознавании.
После внесения описанных изменений точность распознавания на том же наборе из 100 образов повысилась с 87% до 93%.
Результаты работы
Для решения задачи распознавания символов разработана программная система, основанная на методах морфологического анализа символов.
Использованное в системе сочетание методов позволяет распознавать символы с вероятностью 93%. Распознавание устойчиво к искажениям, полученным аффинным преобразованием масштаба и поворота.
В ходе разработки:
1) Применены морфологические признаки: «залив» и «озеро». Данные признаки описывают структуру символов в виде топологических особенностей, инвариантных к проективным и аффинным преобразованиям;
2) Использованы быстрые морфологические преобразования, позволяющие построить эффективные алгоритмы обработки и коррекции бинарных изображений за счет исключения операции последовательного перебора пикселей внутри анализируемого образа;
3) Получена программная система распознавания символов с искажениями.
Литература
1. Гонсалес Р., Вудс Р. Цифровая обработка изображений. – М.: Техносфера, 2005. – с. 1110 – 1148.
2. Форсайт Д., Понс Д. Компьютерное зрение. Современный подход. – М.: Вильямс, 2004. – с. 603 – 610.
3. Л. Шапиро, Дж. Стокман Компьютерное зрение. Пер. с англ. — М.: БИНОМ. Лаборатория знаний,. 2006.— 752 с.
4. Wood J. Invariant pattern recognition: A review. Pattern Recognition. – 1996 – Vol. 29(1). – P. 1 – 17.
5. Бондаренко А.В., Галактионов В.А., Желтов С.Ю. Исследование подходов к построению систем автоматического считывания символьной информации. – М.: Изд-е ИПМ им. М.В. Келдыша РАН, 2003. – с. 5 – 10.
6. Alexander G. Mamistvalov. N-Dimensional Moment Invariants and Conceptual Mathematical Theory of Recognition n-Dimensional Solids. IEEE Press, – 1998. – Vol. 20. – P. 1 – 9. [Электронный ресурс] / Alexander G. Mamistvalov – Режим доступа: http://portal.acm.org/citation.cfm?id=284985
7. Саймон Хайкин. Нейронные сети. Полный курс». Издание второе (исправленное). Прэнтис Холл, 2006. – с 239 – 298.
8. Ричардс С., Вудс Р. Цифровая обработка изображений. – М.: Техносфера, 2005. – 1072 с.
9. George N. Sazaklis Geometric methods for optical character recognition, New York State University. – 1997. – P. 1 – 19. [Электронный ресурс] / George N. Sazaklis – Режим доступа: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.39.4698
10. Sameer Singh. Shape Detection Using Gradient Features for Handwritten Character Recognition School of Computing, University of Plymouth, 2001. – P. 1 – 13. [Электронный ресурс] / Sameer Singh – Режим доступа: http://www.computer.org/portal/web/csdl/doi/10.1109/ICPR.1996.546811

© Магістр ДонНТУ Алейкин Владислав Валерьевич