

Vladislav Aleykin
Speciality: Programming automated systems
Theme of master's work: Distributed system of recognition of textual information
Scientific adviser: associate professor Yuri V. Ladyzhenskii



Abstract
Distributed system of recognition textual information
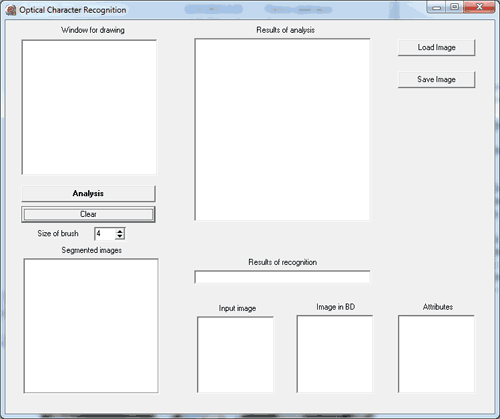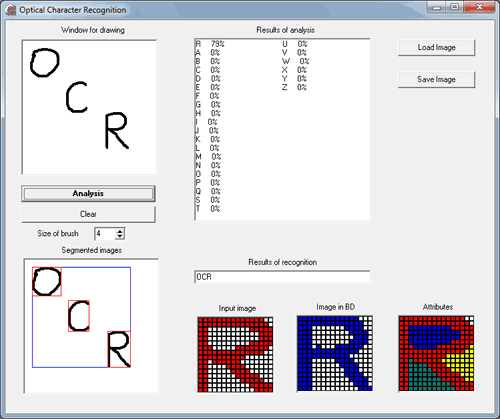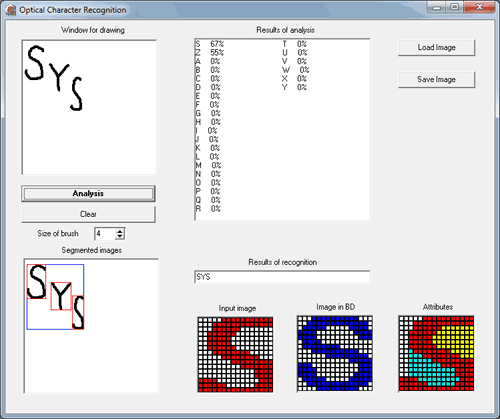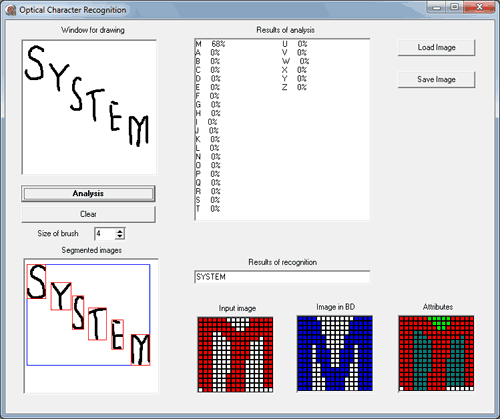
System of recognition textual information
(Animation: volume - 87 KB, number of frames - 10, number of cycles of repetition - 7, size - 500x419)
(Animation: volume - 87 KB, number of frames - 10, number of cycles of repetition - 7, size - 500x419)
Content
Introduction
1 Motivation
2 Scientific novelty
3 Planned practical results
4 Review research
5 Basic idea of work
5.1 Description of the realised algorithm
5.2 Increase accuracy of recognition
Results
Literature
Introduction
Modern technological, industrial and office systems frequently use the information of marking objects. The marks of cargoes, cars, containers, products allows rationally organize image processing during technological cycle, keep account and control of products and materials, predict their requirement. The need for such technology has caused creation of methods, models and systems of recognition of the structured symbols.
1 Motivation
There are many software products which are capable to distinguish the high quality scanned documents with the text information with probability more than 90%. Therefore it is possible to use such programs at offices to recognize documents, and in the industry to control products and mark details.
Existing software products for text recognition are capable to clean weak hindrances in the form of the granular noise connected with poor quality of shooting. Available software products are not capable to define and remove larger hindrances from pictures [2,5,8].

Figure 1 - Example of the industrial image
2 Scientific novelty
Existing program systems show low recognition of images with the raised noise and distortions.
Scientific novelty of developed system consists in application of the distributed processing of images with the imposed distortions.
3 Planned practical results
It will be obtained workable software product designed for efficient recognition of textual information with a high level of noise in images.
4 Review research
There are similar software products worldwide. The most successful products are:
1) ABBYY FineReader. This product is capable to deal with office documents of varying quality, but recognizing images from industry shows low efficiency.
2) OCRopus – open-source technology based on software "Tesseract". This recognizer is capable to analyze scanned documents, which may contain any mixture of text, images and extraneous spots.
At the national level similar systems do not exist. There is no data of development similar system in future.
In DonNTU the problem of recognizing characters were tried to solve by:
1) Isayenko Alexandra, "Using neural networks for solving pattern recognition". The application does not provide noise removal implementation.
2) Driga Konstantin Vladimirovich, "Recognition of noisy and distorted images using neocognitron". The application does not include image preprocessing stage, what reduces the efficiency of the recognizer. My work has a preprocessing module, which eliminates the explicit noise in images, and recognizer performs the more successful identification of the symbol.
5 The basic idea
Principal methods for solving the problem of character recognition: template, indicative, structural.
A template method compares recognizable image with the standard samples from the database system. After comparing system chooses one standard, which is minimally different from the analyzed image. The advantage of the method is a high accuracy recognition of defective characters. The disadvantage of the method is a inability to recognize the font a little different from underlying.
Structural recognition methods do not store information about the pointwise writing a character, and character topology is used. The standard provides information on the relative positions of individual components of the symbol. The advantage of the method is a resistance to shear and rotation symbol on a small angle, different stylistic variations of fonts [2]. However, when turning at an angle greater than ten degrees, this method cannot be used for character recognition.
Indicative methods are based on the fact that the image is associated with a N - dimensional vector of attributes. A feature vector is compared with a set of reference vectors of the same dimension. Advantages of the method are: easy implementation, good generalization ability, high speed. The disadvantage of the method is a high sensitivity to image defects [2].
5.1 Description of the realized algorithm
This method is a combination of three methods presented before and consists of two phases:
– Clarification – calculation of the character signs. At this stage the input is analyzed image, the output is a vector of features for the image;
– Detection – the application of the method of pattern matching for character recognition. The input is analyzed and the image feature vector for the input image. Comparison of the input image is only with the reference images whose feature vectors match the input vector for the test image. The output is a result of recognition.
Images of characters are typical of specific parts, which are served as signs. The most important are the "bay" and "lake". "Bays" abut on one side to the character and the other – on the border of the image. "Lakes" do not abut on the border image, they are inside the symbol. For example, the symbol 'B': has two "lakes" (Fig. 2a), while the symbol «N» has two "bays" (Fig. 2b).

a b
Figure 2 – Allocation of morphological character
Introduce the vector X, which contains signs of a character. The value of the element of the vector is the number of relevant signs. For example, x [1] – the upper bay, x [2] – the right bay, x [3] – the lower bay, x [4] – left the bay, x5 – the lake, and x [3] = 2 means that the symbol has two lower bay. For standard pictures symbols can be computed feature vector.
To isolate such features as "bay" and "lake" it is necessary to apply morphological operators to the analyzed image [2, 3, 4].
The fundamental morphological operators for sets are the accretion and erosion, which are defined as follows:
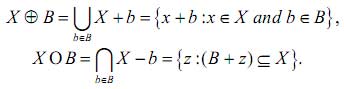
Where: X – input image, x – a single element of the input image; B – structuring element (SE) in the form of a matrix; b – a unit structuring element of the matrix; z – a temporary matrix for processing.
Accretion operator thickens symbol on the size of the structuring element B. Erosion carries the opposite effect – the operator makes the character more subtle.
To identify areas of "bays" and "lakes" are used operators opening and closing:
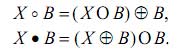
The opening suppresses the sharp edges and cuts through the narrow necks of the image X, while the closing fills the narrow inlets and small holes. Using a combination of these operators can be obtained signs of the image. The original image is transformed into an image that contains the fields "bay" and "lakes" These areas will be located separately from each other [1, 2, 4].
As an example fig. 3 shows the results obtained by the program.

Ха = (0, 0, 0, 1, 1) Хw = (0, 0, 2, 1, 0)

Хz = (1, 1, 0, 0, 0) Хp = (0, 0, 0, 0, 1)
Figure 3 - The result of feature extraction operators
This method works well on the printed symbols. If the characters are written by hand, the method detects false signs that reduce the accuracy of recognition or lead to a error detection.
Experimentally it was determined that false signs have areas less than 7 pixels if the size of the entire matrix of the analyzed image is 256 pixels [5].
After determining the feature vector we should define its membership to a certain class of characters. For information about classes is stored in a database in tabular form (Table 1).
Table 1 – Table of character classes
| № | Х(L, R, T, B, C) | Class |
| 1 | 0 0 0 1 1 | A, R |
| 2 | 0 0 0 0 2 | B |
| 3 | 0 1 0 0 0 | C, E, F, G |
| 4 | 0 0 0 0 1 | D, O, P, Q |
| 5 | 0 0 1 1 0 | H |
| 6 | 0 0 0 0 0 | J, I, T, L |
| 7 | 0 1 1 1 0 | K |
| 8 | 0 0 1 2 0 | M |
| 9 | 1 1 0 0 0 | S, Z |
| 10 | 0 0 1 0 0 | U, V, Y |
| 11 | 0 0 2 1 0 | W |
| 12 | 1 1 1 1 0 | X |
Table 1 shows that for the English alphabet will be 12 classes, which will further build the association recognizable symbol. One feature vectors may correspond to multiple characters (Fig. 4, 5).
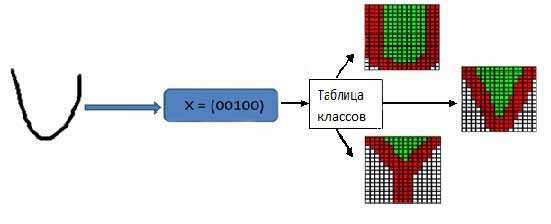
Figure 4 - Allocation of class for the symbol 'U'
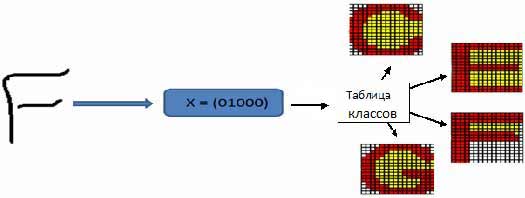
Figure 5 - Allocation of class for the symbol 'F'
The second phase of the algorithm implements finding the most similar image of a character among the selected class on the first stage. Most similar way is the one that has the least number of different pixels of the input image:
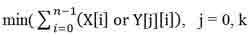
Where X – the input image, Y [j] – a reference image, n – the size of the image, k – the number of reference images.
Since the character could be written from different perspectives, in the database of reference images should be made to two additional feature vector, which are calculated after turning the symbol on the +15 degrees and -15 degrees [6]. This approach allows to cover almost all the spellings of characters, but at the same time:
1) the recognition accuracy is increased by expanding the reference images;
2) slows down the program, as the comparison is with the three sets of reference images.
5.2 Increase accuracy of recognition
For testing were chosen 100 handwritten characters. During testing it was recognized 87 characters, representing 87% of recognition.
The second phase of the algorithm has been improved: the change is to calculate the arithmetic mean of percent similarity for the 10 spellings of character. It is necessary to pass the reference images whose feature vector is different from the analyzed image. This approach allows you to process only those characters that do not differ greatly from the test that gives a more accurate estimate. Figures 7 and 8 shows the results of this approach [1, 7, 9].

Figure 6 - Recognition of the character 'U'
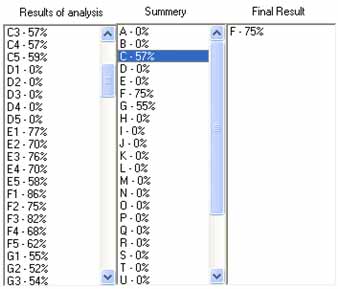
Figure 7 - Recognition of the character 'F'
To reduce the number of scanned images it was introduced additional features for each character.
After applying a secondary feature vector the number of analyzed reference images is reduced, which speeds up processing during recognition.
After making the described changes recognition accuracy on the same set of 100 images increased from 87% to 93%.
Results
To solve the problem of character recognition it was developed software system based on morphological analysis of the characters.
Applying combination of methods enables to identify the characters with a probability of 93%. Recognition is resistant to distortion obtained affine transformation of scale and rotation.
In the course of development:
– Apply a morphological characters: "bay" and "lake". These signs describe the structure of symbols in the form of topological features that are invariant to projective and affine transformations;
– Use rapid morphological transformations that allow to construct efficient algorithms for processing and correcting binary images by eliminating the sequential iteration of pixels inside the analyzed image;
Literature
1. Gonzalez R., Woods R. Digital image processing. - M.: Technosphere, 2005. – c. 1110–1148.
2. Forsyth DA, Ponce J. Computer Vision. Modern Approach. - M.: Williams, 2004. – c. 603–610.
3. Shapiro, G. Stockman Computer vision. Per. from English. - M.: BINOM. Laboratory of knowledge. 2006.— 752 с.
4. Wood J. Invariant pattern recognition: A review. Pattern Recognition. – 1996 – Vol. 29(1). – P. 1–17.
5. Bondarenko AV, Galaktionov VA, Zheltov SY The study of approaches to the construction of automatic reading of the character information. - M.: e IPM them. MV Applied Mathematics RAS, 2003. – c. 5 – 10.
6. Alexander G. Mamistvalov. N-Dimensional Moment Invariants and Conceptual Mathematical Theory of Recognition n-Dimensional Solids”. IEEE Press, – 1998. – Vol. 20. – P. 1 – 9. [Электронный ресурс] / Alexander G. Mamistvalov – Режим доступа: http://portal.acm.org/citation.cfm?id=284985
7. Simon Chaikin. Neural networks. Full course. Second edition (as amended). Prentis Hall 2006. – c 239–298.
8. Richards, R., Woods R. processing images. - M.: Technosphere, 2006. - 1072 p.
9. George N. Sazaklis Geometric methods for optical character recognition, New York State University. – 1997. – P. 1–19. [Электронный ресурс] / George N. Sazaklis – Режим доступа: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.39.4698
10. Sameer Singh. Shape Detection Using Gradient Features for Handwritten Character Recognition” School of Computing, University of Plymouth, 2001. – P. 1-13. [Электронный ресурс] / Sameer Singh – Режим доступа: http://www.computer.org/portal/web/csdl/doi/10.1109/ICPR.1996.546811

© DonNTU master Vladislav Aleykin, 2010