
Автореферат по теме:
Анализ, исследование и усовершенствование методов реалистической визуализации трехмерных моделей объектов и сцен с применением функционального описания
Составитель:
Иванова Екатеина Владимировна
Научный руководитель:
к.т.н., доцент кафедры ПМиИ Зори Сергей Анатольевич
Автореферат по теме выпускной работы
Введение
Целью данной научной работы является анализ методов и алгоритмов реалистичной визуализации трехмерных сцен по классу трассировки лучей, их общих характеристик, и исследование возможности их использования для сцен с функциональным описанием.
Объектом исследования данной работы является методы реалистической визуализации трехмерных моделей объектов.
Предмет исследования — реализация методов трассировки лучей на параллельных архитектурах графических процессоров.
3D-визуализация — это точное представление различных объектов в объеме. Визуализация объектов — создания с помощью двухмерной или трехмерной графики реалистических (обычно фотореалистичных) графических изображений, которые в точности повторяют все пропорции и детали конечного продукта или здания, с тем, чтобы о нем можно было получить исчерпывающие зрительное представление еще до его реального появления.
Устройства для превращения персональных компьютеров в маленькие суперкомпьютеры известны довольно давно. Ещё в 80-х годах прошлого века на рынке предлагались так называемые транспьютеры, которые вставлялись в распространенные тогда слоты расширения ISA.
В последнее время эстафета параллельных вычислений перешла к массовому рынку, так или иначе связанному с трёхмерными играми. Универсальные устройства с многоядерными процессорами для параллельных векторных вычислений, используемых в 3D-графике, достигают высокой пиковой производительности, которая универсальным процессорам не под силу. Конечно, максимальная скорость достигается лишь в ряде удобных задач и имеет некоторые ограничения, но такие устройства уже начали довольно широко применять в сферах, для которых они изначально и не предназначались. Отличным примером такого параллельного процессора является процессор Cell, разработанный альянсом Sony—Toshiba—IBM и применяемый в игровой приставке Sony PlayStation 3, а также и все современные видеокарты от компаний NVIDIA и AMD.
Исследование возможности применения технологий параллельных вычислений и является целью данной работы.
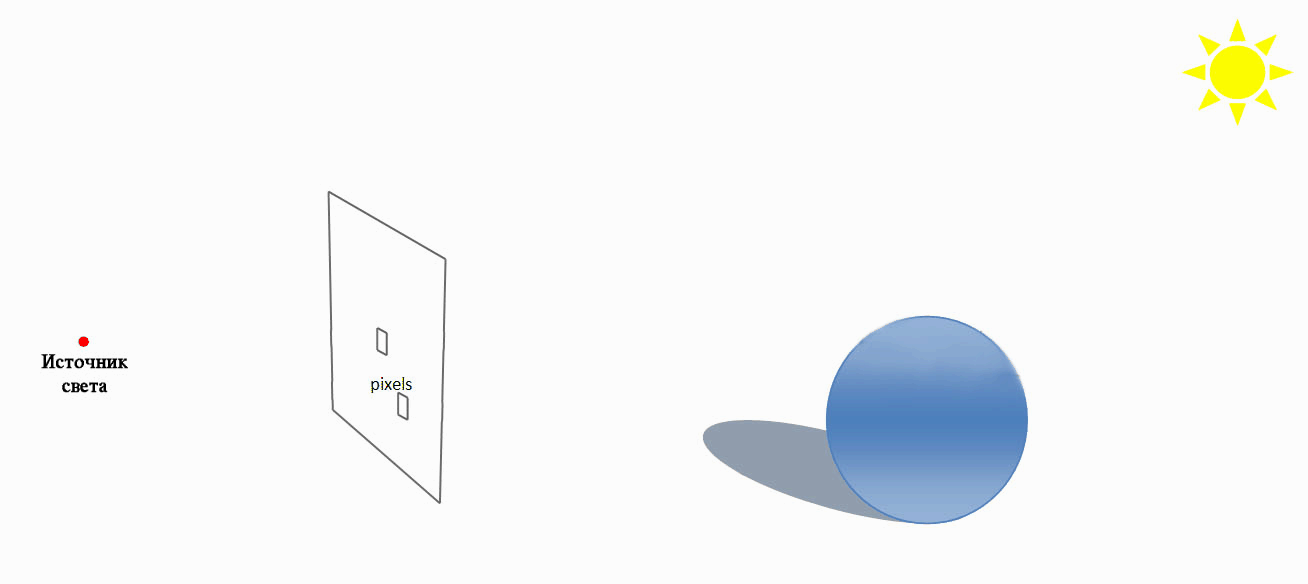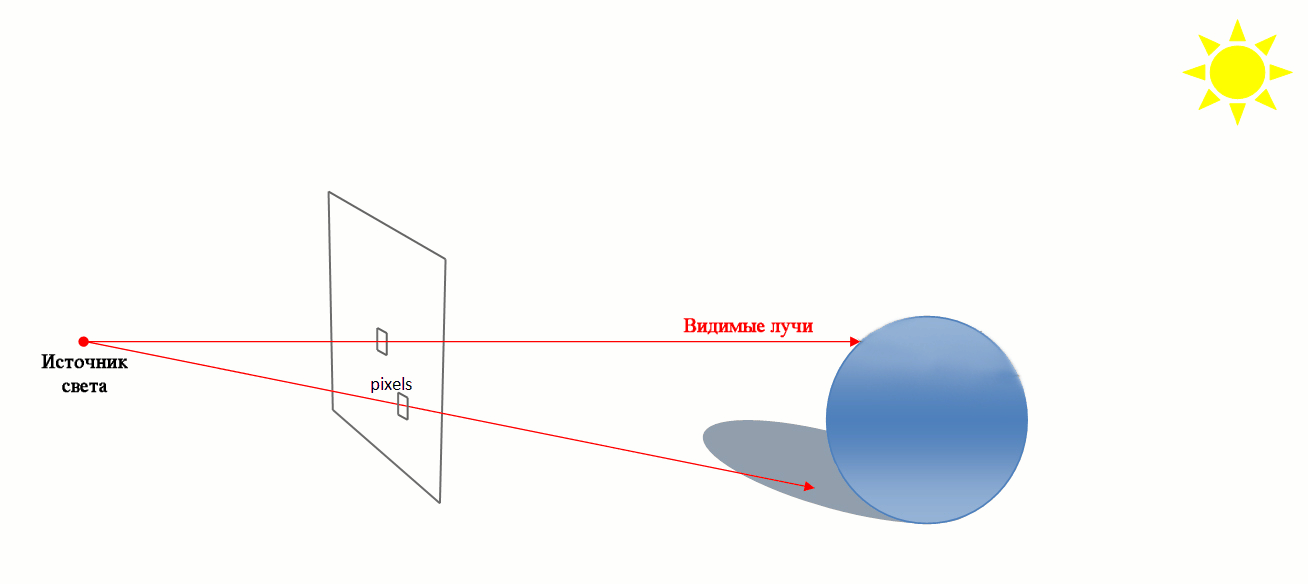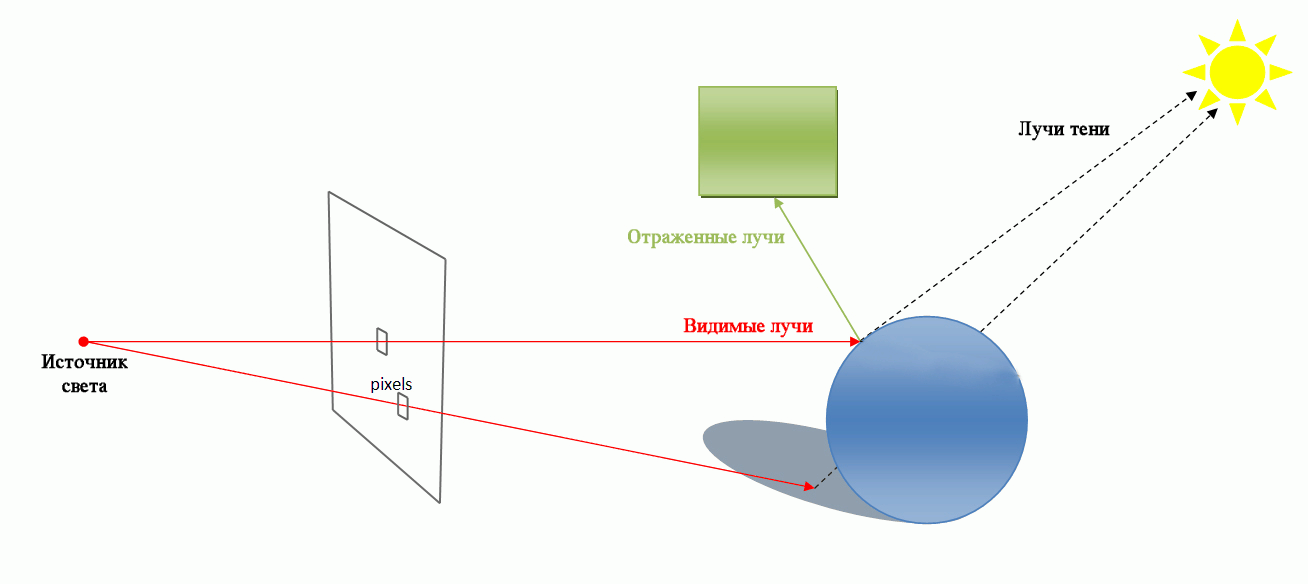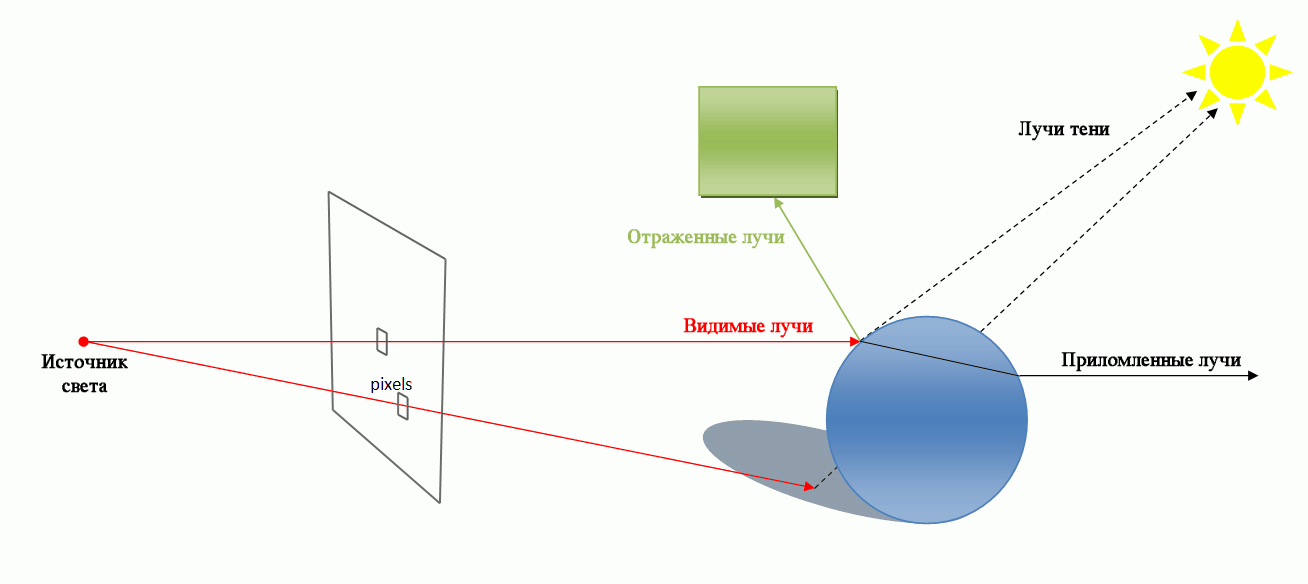
Трассировка лучей (ray tracing) — метод машинной графики, позволяющий создавать фотореалистические изображения любых трехмерных сцен. Трассировка лучей моделирует прохождение лучей света через изображаемую сцену. Фотореализм достигается путем математического моделирования оптических свойств света и его взаимодействия с объектами. Но для получения качественных реалистических изображений требуются значительные временные и вычислительные ресурсы.
Задачу реализации трассировки лучей пытаются решать множество ученых: Horn, D. R., Sugerman, J., Houston, M., and Hanrahan реализовывали алгоритм поиска по kd дереву с коротким стеком и пакетом лучей, Попов С. – алгоритм без применения стека и пакетов лучей.
Для 3D видеоускорителей ещё несколько лет назад появились первые технологии неграфических расчётов общего назначения GPGPU (General-Purpose computation on GPUs). Ведь современные видеочипы содержат сотни математических исполнительных блоков, и эта мощь может использоваться для значительного ускорения множества вычислительно интенсивных приложений. Разработчики задумали сделать так, чтобы GPU рассчитывали не только изображение в 3D-приложениях, но и применялись в других параллельных расчётах.
Трассировка лучей (Ray tracing)

Технология CUDA
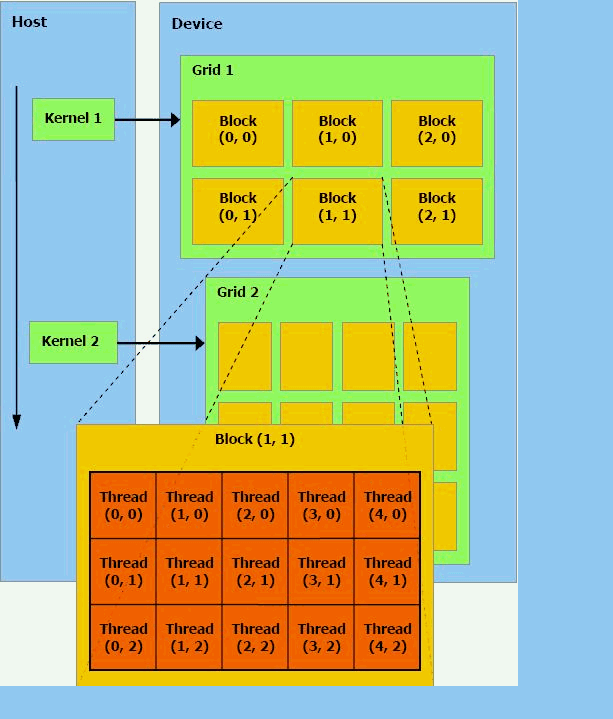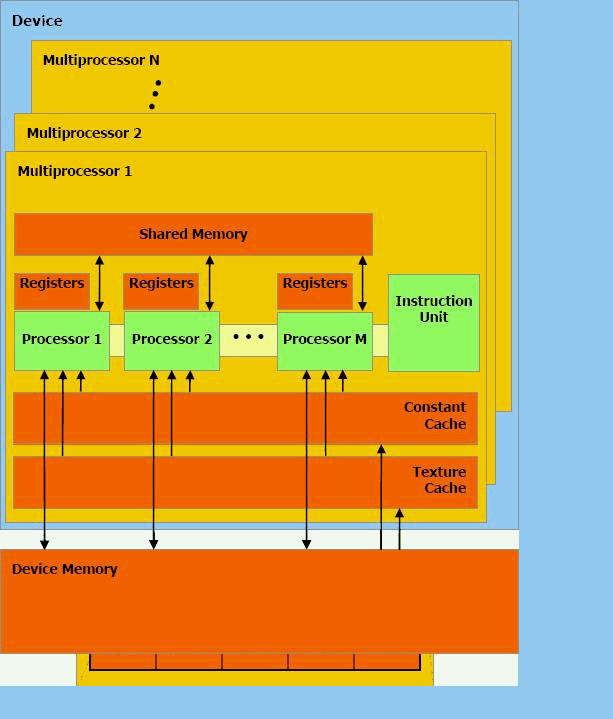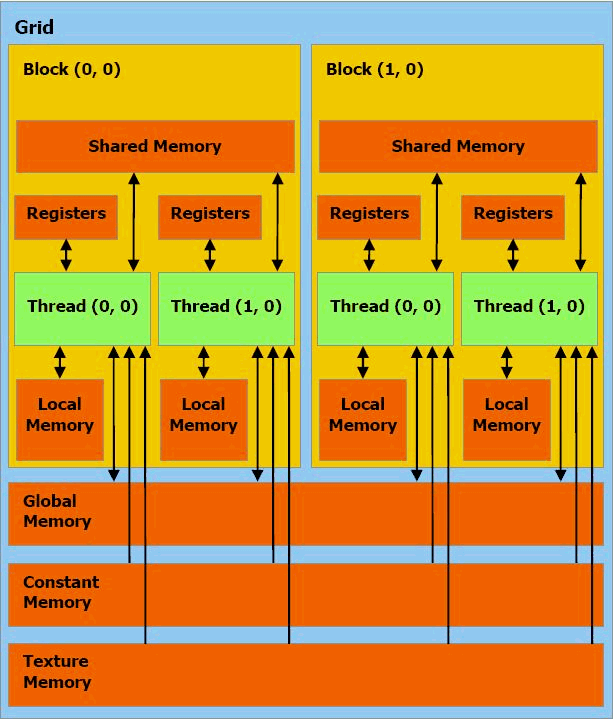
Анимация выполнена с помощью программы mp_gif_animator, имеет объем 149Кб, состоит из 5 кадров и длится 35 секунд
Вычисления на GPU развивались и развиваются очень быстро. Компанией NVIDIA, являющейся одной из основных производителей видеочипов, была разработана платформы под названием CUDA (Compute Unified Device Architecture). Платформа CUDA — C-подобный язык программирования со своим компилятором и библиотеками для вычислений на GPU. Данная модель программирования GPU выполнена с учётом прямого доступа к аппаратным возможностям видеокарт.
Технология CUDA активно развивается, вводятся новые дополнительные компоненты и возможности для разработчиков. Специалисты разрабатывают различные трехмерные сцены с применением разнообразных текстур, а так же активно занимаются написанием вычислительных программ на графических процессорах.
Таким образом, задача исследования и усовершенствование методов реалистической визуализации трехмерных моделей объектов и сцен с использованием параллельных вычислений на GPU видеокарт является актуальной.
Рост частот универсальных процессоров упёрся в физические ограничения и высокое энергопотребление, и увеличение их производительности всё чаще происходит за счёт размещения нескольких ядер в одном чипе. Продаваемые сейчас процессоры содержат лишь до четырёх ядер (дальнейший рост не будет быстрым) и они предназначены для обычных приложений, используют MIMD — множественный поток команд и данных. Каждое ядро работает отдельно от остальных, исполняя разные инструкции для разных процессов.
Например, в видеочипах NVIDIA основной блок — это мультипроцессор с восемью - десятью ядрами и сотнями ALU в целом, несколькими тысячами регистров и небольшим количеством разделяемой общей памяти. Кроме того, видеокарта содержит быструю глобальную память с доступом к ней всех мультипроцессоров, локальную память в каждом мультипроцессоре, а также специальную память для констант.
Ядра CPU созданы для исполнения одного потока последовательных инструкций с максимальной производительностью, а GPU проектируются для быстрого исполнения большого числа параллельно выполняемых потоков инструкций. Универсальные процессоры оптимизированы для достижения высокой производительности единственного потока команд, обрабатывающего и целые числа и числа с плавающей точкой. При этом доступ к памяти случайный.
У видеочипов работа простая и распараллеленная изначально. Видеочип принимает на входе группу полигонов, проводит все необходимые операции, и на выходе выдаёт пиксели. Обработка полигонов и пикселей независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому, из-за изначально параллельной организации работы в GPU используется большое количество исполнительных блоков, которые легко загрузить, в отличие от последовательного потока инструкций для CPU. Кроме того, современные GPU также могут исполнять больше одной инструкции за такт (dual issue).
Разработка программных продуктов с применением технологии CUDA позволит более эффективно осуществлять решение задач, связанных с высокой степенью параллелизма, поскольку основой вычислительной архитектуры CUDA является концепция: одна команда на множество данных – SIMD (Single Instruction Multiple Data).
Это позволяет эффективно решать задачи с большой вычислительной сложностью, например, известные задачи реалистичной 3D-графики — трассировки лучей в реальном времени, 3D-моделирования, визуализации трёхмерных сцен с расчётом физически-реалистичного освещения и сложными материалами, а также повышать эффективность существующих методов работы с графикой.
В отличие от современных универсальных CPU, видеочипы предназначены для параллельных вычислений с большим количеством арифметических операций. И значительно большее число транзисторов GPU работает по прямому назначению — обработке массивов данных, а не управляет исполнением (flow control) немногочисленных последовательных вычислительных потоков. Это схема того, сколько места в CPU и GPU занимает разнообразная логика:
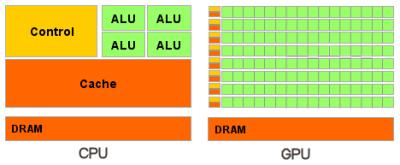
В итоге, основой для эффективного использования мощи GPU в научных и иных неграфических расчётах является распараллеливание алгоритмов на сотни исполнительных блоков, имеющихся в видеочипах. К примеру, множество приложений по молекулярному моделированию отлично приспособлено для расчётов на видеочипах, они требуют больших вычислительных мощностей и поэтому удобны для параллельных вычислений. А использование нескольких GPU даёт ещё больше вычислительных мощностей для решения подобных задач.
Выполнение расчётов на GPU показывает отличные результаты в алгоритмах, использующих параллельную обработку данных. То есть, когда одну и ту же последовательность математических операций применяют к большому объёму данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико. Это предъявляет меньшие требования к управлению исполнением (flow control), а высокая плотность математики и большой объём данных отменяет необходимость в больших кэшах, как на CPU.
В результате всех описанных выше отличий, теоретическая производительность видеочипов значительно превосходит производительность CPU. Компания NVIDIA приводит такой график роста производительности CPU и GPU за последние несколько лет:
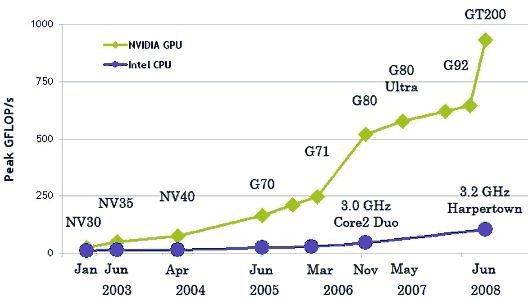
Применение технологии CUDA позволяет распараллелить вычисления, что позволит повысить скорость выполнения методов обработки трехмерных объектов и сцен позволит более качественно и эффективно реализовывать реализм создаваемых сцен, предоставит возможности для более детального расчета сцен и объектов, применив дополнительные алгоритмы работы с объектами, например, более качественная прорисовка отражения и теней, представление объектов нетрадиционными способами, как, например, функциональное описание.
Так же немаловажное значение имеет тот факт, что операции вычисления производятся на тех же процессорах, что и их дальнейшая прорисовка, что так же сокращает время выполнения операции и повышает точность, поскольку результатами вычислений являются числа с плавающей точкой (уже анонсируется выход нового продукта iray, который позволит просчитывать проекты средствами mental ray 3.8, задействовав при этом не центральный процессор, который, по сути, для такого рода расчетов не предназначен, а GPU NVIDIA).
Таким образом, практической значимостью работы следует считать повышение производительности известных методов 3D-графики, и, следовательно, повышение качества и реализма синтезируемых сцен, удешевление аппаратуры для систем 3D-графики.
Самые первые попытки такого применения были крайне примитивными и ограничивались использованием некоторых аппаратных функций, таких, как растеризация и Z-буферизация.
В среднем, при переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Основные приложения, в которых сейчас применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
- 1. Анализ методов и алгоритмов реалистической визуализации трехмерных сцен по классу трассировки лучей, уменьшения вычислительной сложности создаваемых приложений применением технологий параллельного программирования.
- 2. Разработать эффективную реализацию задачи трассировки лучей для реалистической визуализации трехмерных сцен при помощи технологии CUDA.
- 3. Оценить эффективность реализации средствами компьютерного моделирования для сцен с функциональным описанием.
Метод трассировки лучей позволяет создавать качественные, красочные трехмерные сцены, к тому же он хорошо поддается распараллеливанию, что позволит получить хорошую его реализацию применив технологию CUDA.
Представленная компанией NVIDIA программно-аппаратная архитектура для расчётов на видеочипах CUDA хорошо подходит для решения широкого круга задач с высоким параллелизмом. CUDA работает на большом количестве видеочипов NVIDIA, и улучшает модель программирования GPU, значительно упрощая её и добавляя большое количество возможностей, таких как разделяемая память, возможность синхронизации потоков, вычисления с двойной точностью и целочисленные операции.
Вполне вероятно, что в силу широкого распространения видеокарт в мире, развитие параллельных вычислений на GPU сильно повлияет на индустрию высокопроизводительных вычислений.
Универсальные процессоры развиваются довольно медленно, у них нет таких скачков производительности. По сути, пусть это и звучит слишком громко, все нуждающиеся в быстрых вычислителях теперь могут получить недорогой персональный суперкомпьютер на своём столе, иногда даже не вкладывая дополнительных средств, так как видеокарты NVIDIA широко распространены. Не говоря уже об увеличении эффективности в терминах GFLOPS/$ и GFLOPS/Вт, которые так нравятся производителям GPU.
Будущее множества вычислений явно за параллельными алгоритмами, почти все новые решения и инициативы направлены в эту сторону.
Но, конечно, GPU не заменят CPU. В их нынешнем виде они и не предназначены для этого. Сейчас что видеочипы движутся постепенно в сторону CPU, становясь всё более универсальными (расчёты с плавающей точкой одинарной и двойной точности, целочисленные вычисления), так и CPU становятся всё более «параллельными», обзаводясь большим количеством ядер, технологиями многопоточности, не говоря про появление блоков SIMD и проектов гетерогенных процессоров. Скорее всего, GPU и CPU в будущем просто сольются. Известно, что многие компании, в том числе Intel и AMD работают над подобными проектами. И неважно, будут ли GPU поглощены CPU, или наоборот.
Один из немногочисленных недостатков CUDA — слабая переносимость. Эта архитектура работает только на видеочипах этой компании, да ещё и не на всех, а начиная с серии GeForce 8 и 9 и соответствующих Quadro и Tesla. Да, таких решений в мире очень много, NVIDIA приводит цифру в 90 миллионов CUDA-совместимых видеочипов. Это просто отлично, но ведь конкуренты предлагают свои решения, отличные от CUDA.
Применение технологии CUDA для работы с трехмерной графикой позволит эффективно решать задачи с большой вычислительной сложностью, например, известные задачи реалистичной 3D-графики — трассировки лучей в реальном времени, 3D-моделирования, визуализации трёхмерных сцен с расчётом физически-реалистичного освещения и сложными материалами, а также повышать эффективность существующих методов работы с графикой, повысить качество и реализм синтезируемых сцен, удешевить аппаратуру для систем 3D-графики.
- 1. Берилло А. NVIDIA CUDA — Неграфические вычисления на графических процессорах / iXBT, 23.09.2008, http://ixbt.com/video3/cuda-1.shtml
- 2. Демченко Л. Механика виртуальности: RayTracing / КомпьютерраOnline, 17.11.2004, — http://www.computerra.ru/hitech/36685/
- 3. Ray-traycing.ru / Лаборатория компьютерной графики, — http://ray-tracing.ru
- 4. CUDA Zone / сайт NVIDIA, — http://www.nvidia.ru/object/cuda_home_new_ru.html
- 5. Профессиональные решения NVIDIA для ускорения работы с трехмерной графикой / archi.ru, 22.12.2009, — http://archi.ru/tech/news_21081.html
- 6. Куликов А.И., Овчинникова Т.Э. Метод трассировки лучей / Интернет университет информационных технологий intuit.ru, — http://www.intuit.ru/department/graphics/graphalg/6/5.html
- 7. CUDA идёт Прогресс. Рендеринг на видеокартах NVIDIA Quadro и Tesla / Server News, 25.05.2009, — http://server-news.ru/.../224-cuda-idyot-progress-rendering-na-videokartax.html
- 8. Технология CUDA от NVIDIA / CadStudio, 16.11.2009, — http://cadstudio.ru/news/news-about-world/311-cuda-nvidia.html
- 9. Сидоров B. Что такое NVIDIA CUDA? / Netler.ru, — http://netler.ru/pc/cuda.htm
- 10. Фролов В., Игнатенко А. Интерактивная трассировка лучей и фотонные карты на GPU / Труды конференции ГрафиКон'2009, Москва, Россия, стр. 255-262. PDF, — .../97_Paper.pdf